Membuat cluster Dataproc menggunakan library klien
Kode contoh yang tercantum di bawah menunjukkan cara menggunakan Library Klien Cloud untuk membuat cluster Dataproc, menjalankan tugas di cluster, lalu menghapus cluster.
Anda juga dapat melakukan tugas ini menggunakan:
- Permintaan REST API di Panduan Mulai Cepat Menggunakan API Explorer
- konsol Google Cloud di Membuat cluster Dataproc menggunakan konsol Google Cloud
- Google Cloud CLI di Membuat cluster Dataproc menggunakan Google Cloud CLI
Sebelum memulai
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Make sure that billing is enabled for your Google Cloud project.
-
Enable the Dataproc API.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Make sure that billing is enabled for your Google Cloud project.
-
Enable the Dataproc API.
Menjalankan Kode
Coba panduan: Klik Buka di Cloud Shell untuk menjalankan panduan Library Klien Cloud Python yang membuat cluster, menjalankan tugas PySpark, lalu menghapus cluster.
Go
- Instal library klien Untuk informasi selengkapnya, lihat Menyiapkan lingkungan pengembangan.
- Menyiapkan autentikasi
- Clone dan jalankan contoh kode GitHub.
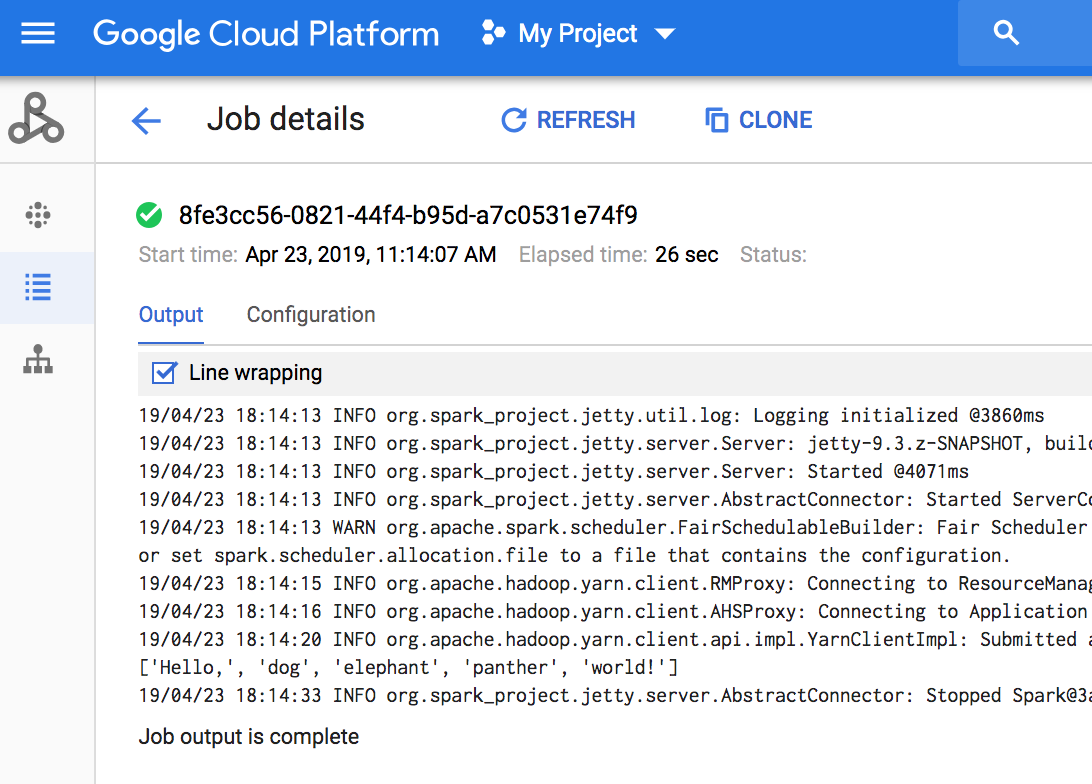
- Lihat outputnya. Kode ini menghasilkan log driver tugas ke bucket staging Dataproc default di Cloud Storage. Anda dapat melihat output driver tugas dari konsol Google Cloud di bagian Jobs Dataproc project Anda. Klik ID Tugas untuk melihat output tugas di
halaman Detail tugas.
Java
- Instal library klien Untuk informasi selengkapnya, lihat Menyiapkan Lingkungan Pengembangan Java.
- Menyiapkan autentikasi
- Clone dan jalankan contoh kode GitHub.
- Lihat outputnya. Kode ini menghasilkan log driver tugas ke bucket staging Dataproc default di Cloud Storage. Anda dapat melihat output driver tugas dari konsol Google Cloud di bagian Jobs Dataproc project Anda. Klik ID Tugas untuk melihat output tugas di
halaman Detail tugas.
Node.js
- Instal library klien Untuk informasi selengkapnya, lihat Menyiapkan lingkungan pengembangan Node.js.
- Menyiapkan autentikasi
- Clone dan jalankan contoh kode GitHub.
- Lihat output. Kode ini menghasilkan log driver tugas ke bucket staging Dataproc default di Cloud Storage. Anda dapat melihat output driver tugas dari konsol Google Cloud di bagian Jobs Dataproc project Anda. Klik ID Tugas untuk melihat output tugas di
halaman Detail tugas.
Python
- Instal library klien Untuk informasi selengkapnya, lihat Menyiapkan Lingkungan Pengembangan Python.
- Menyiapkan autentikasi
- Clone dan jalankan contoh kode GitHub.
- Lihat output. Kode ini menghasilkan log driver tugas ke bucket staging Dataproc default di Cloud Storage. Anda dapat melihat output driver tugas dari konsol Google Cloud di bagian Jobs Dataproc project Anda. Klik ID Tugas untuk melihat output tugas di
halaman Detail tugas.
Langkah selanjutnya
- Lihat Referensi tambahan Library Klien Cloud Dataproc.