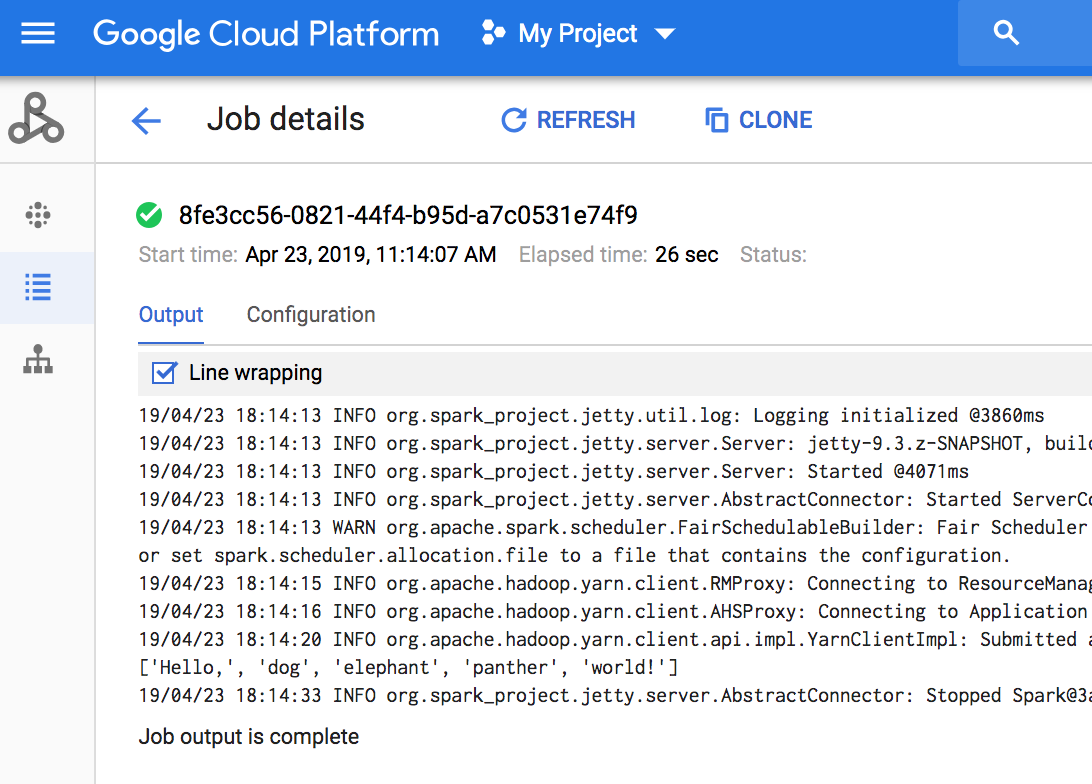
// This quickstart shows how you can use the Dataproc Client library to create a
// Dataproc cluster, submit a PySpark job to the cluster, wait for the job to finish
// and finally delete the cluster.
//
// Usage:
//
// go build
// ./quickstart --project_id <PROJECT_ID> --region <REGION> \
// --cluster_name <CLUSTER_NAME> --job_file_path <GCS_JOB_FILE_PATH>
package main
import (
"context"
"flag"
"fmt"
"io"
"log"
"regexp"
dataproc "cloud.google.com/go/dataproc/apiv1"
"cloud.google.com/go/dataproc/apiv1/dataprocpb"
"cloud.google.com/go/storage"
"google.golang.org/api/option"
)
func main() {
var projectID, clusterName, region, jobFilePath string
flag.StringVar(&projectID, "project_id", "", "Cloud Project ID, used for creating resources.")
flag.StringVar(®ion, "region", "", "Region that resources should be created in.")
flag.StringVar(&clusterName, "cluster_name", "", "Name of Cloud Dataproc cluster to create.")
flag.StringVar(&jobFilePath, "job_file_path", "", "Path to job file in GCS.")
flag.Parse()
ctx := context.Background()
// Create the cluster client.
endpoint := fmt.Sprintf("%s-dataproc.googleapis.com:443", region)
clusterClient, err := dataproc.NewClusterControllerClient(ctx, option.WithEndpoint(endpoint))
if err != nil {
log.Fatalf("error creating the cluster client: %s\n", err)
}
// Create the cluster config.
createReq := &dataprocpb.CreateClusterRequest{
ProjectId: projectID,
Region: region,
Cluster: &dataprocpb.Cluster{
ProjectId: projectID,
ClusterName: clusterName,
Config: &dataprocpb.ClusterConfig{
MasterConfig: &dataprocpb.InstanceGroupConfig{
NumInstances: 1,
MachineTypeUri: "n1-standard-2",
},
WorkerConfig: &dataprocpb.InstanceGroupConfig{
NumInstances: 2,
MachineTypeUri: "n1-standard-2",
},
},
},
}
// Create the cluster.
createOp, err := clusterClient.CreateCluster(ctx, createReq)
if err != nil {
log.Fatalf("error submitting the cluster creation request: %v\n", err)
}
createResp, err := createOp.Wait(ctx)
if err != nil {
log.Fatalf("error creating the cluster: %v\n", err)
}
// Defer cluster deletion.
defer func() {
dReq := &dataprocpb.DeleteClusterRequest{
ProjectId: projectID,
Region: region,
ClusterName: clusterName,
}
deleteOp, err := clusterClient.DeleteCluster(ctx, dReq)
deleteOp.Wait(ctx)
if err != nil {
fmt.Printf("error deleting cluster %q: %v\n", clusterName, err)
return
}
fmt.Printf("Cluster %q successfully deleted\n", clusterName)
}()
// Output a success message.
fmt.Printf("Cluster created successfully: %q\n", createResp.ClusterName)
// Create the job client.
jobClient, err := dataproc.NewJobControllerClient(ctx, option.WithEndpoint(endpoint))
// Create the job config.
submitJobReq := &dataprocpb.SubmitJobRequest{
ProjectId: projectID,
Region: region,
Job: &dataprocpb.Job{
Placement: &dataprocpb.JobPlacement{
ClusterName: clusterName,
},
TypeJob: &dataprocpb.Job_PysparkJob{
PysparkJob: &dataprocpb.PySparkJob{
MainPythonFileUri: jobFilePath,
},
},
},
}
submitJobOp, err := jobClient.SubmitJobAsOperation(ctx, submitJobReq)
if err != nil {
fmt.Printf("error with request to submitting job: %v\n", err)
return
}
submitJobResp, err := submitJobOp.Wait(ctx)
if err != nil {
fmt.Printf("error submitting job: %v\n", err)
return
}
re := regexp.MustCompile("gs://(.+?)/(.+)")
matches := re.FindStringSubmatch(submitJobResp.DriverOutputResourceUri)
if len(matches) < 3 {
fmt.Printf("regex error: %s\n", submitJobResp.DriverOutputResourceUri)
return
}
// Dataproc job outget gets saved to a GCS bucket allocated to it.
storageClient, err := storage.NewClient(ctx)
if err != nil {
fmt.Printf("error creating storage client: %v\n", err)
return
}
obj := fmt.Sprintf("%s.000000000", matches[2])
reader, err := storageClient.Bucket(matches[1]).Object(obj).NewReader(ctx)
if err != nil {
fmt.Printf("error reading job output: %v\n", err)
return
}
defer reader.Close()
body, err := io.ReadAll(reader)
if err != nil {
fmt.Printf("could not read output from Dataproc Job: %v\n", err)
return
}
fmt.Printf("Job finished successfully: %s", body)
}