Puoi inviare un job a un cluster Dataproc esistente tramite una richiesta HTTP o programmatica jobs.submit dell'API Dataproc, utilizzando lo strumento a riga di comando gcloud Google Cloud CLI in una finestra del terminale locale o in Cloud Shell oppure dalla Google Cloud console aperta in un browser locale. Puoi
anche accedere tramite SSH all'istanza master
nel cluster, quindi eseguire un job direttamente dall'istanza senza
utilizzare il servizio Dataproc.
Come inviare un job
Console
Apri la pagina Dataproc Invia un job nella console Google Cloud nel browser.
Esempio di job Spark
Per inviare un job Spark di esempio, compila i campi nella pagina Invia un job nel seguente modo:
- Seleziona il nome del tuo cluster dall'elenco dei cluster.
- Imposta Tipo di job su
Spark. - Imposta Classe principale o jar su
org.apache.spark.examples.SparkPi. - Imposta Argomenti sull'unico argomento
1000. - Aggiungi
file:///usr/lib/spark/examples/jars/spark-examples.jara File jar:file:///indica uno schema Hadoop LocalFileSystem. Dataproc ha installato/usr/lib/spark/examples/jars/spark-examples.jarsul nodo master del cluster durante la creazione del cluster.- In alternativa, puoi specificare un percorso Cloud Storage
(
gs://your-bucket/your-jarfile.jar) o un percorso Hadoop Distributed File System (hdfs://path-to-jar.jar) a uno dei tuoi file JAR.
Fai clic su Invia per avviare il job. Una volta avviato, il job viene aggiunto all'elenco Job.
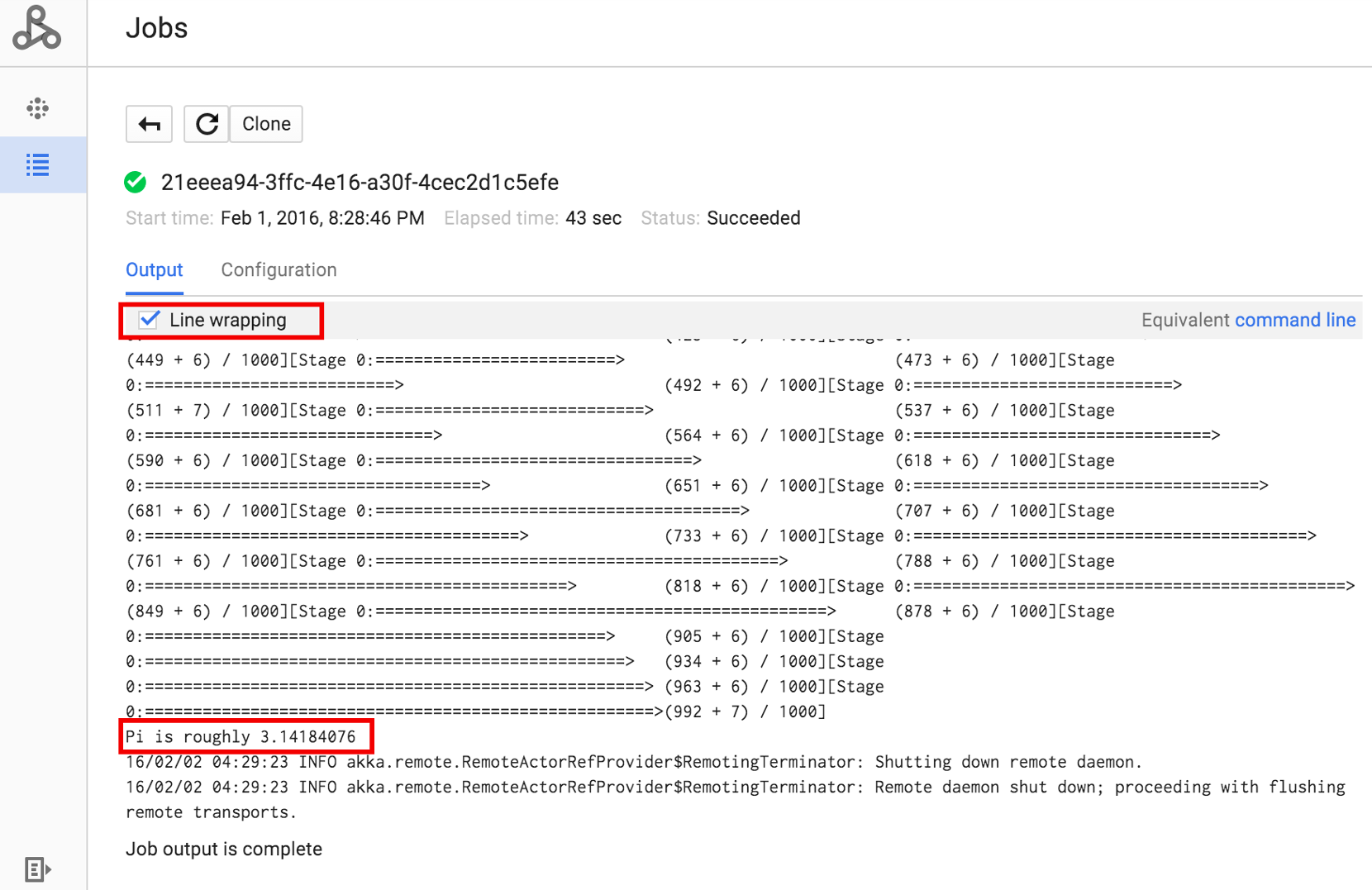
Fai clic sull'ID job per aprire la pagina Job, dove puoi visualizzare l'output del driver del job. Poiché questo job produce righe di output lunghe che
superano la larghezza della finestra del browser, puoi selezionare la casella A capo per visualizzare tutto
il testo di output e mostrare il risultato calcolato per pi.
Puoi visualizzare l'output del driver del job dalla riga di comando utilizzando il comando
gcloud dataproc jobs wait
mostrato di seguito (per maggiori informazioni, vedi
Visualizzare l'output del job - COMANDO GCLOUD).
Copia e incolla l'ID progetto come valore del flag --project e l'ID job (mostrato nell'elenco Job) come argomento finale.
gcloud dataproc jobs wait job-id \ --project=project-id \ --region=region
Ecco alcuni snippet dell'output del driver per il job SparkPi
di esempio inviato sopra:
... 2015-06-25 23:27:23,810 INFO [dag-scheduler-event-loop] scheduler.DAGScheduler (Logging.scala:logInfo(59)) - Stage 0 (reduce at SparkPi.scala:35) finished in 21.169 s 2015-06-25 23:27:23,810 INFO [task-result-getter-3] cluster.YarnScheduler (Logging.scala:logInfo(59)) - Removed TaskSet 0.0, whose tasks have all completed, from pool 2015-06-25 23:27:23,819 INFO [main] scheduler.DAGScheduler (Logging.scala:logInfo(59)) - Job 0 finished: reduce at SparkPi.scala:35, took 21.674931 s Pi is roughly 3.14189648 ... Job [c556b47a-4b46-4a94-9ba2-2dcee31167b2] finished successfully. driverOutputUri: gs://sample-staging-bucket/google-cloud-dataproc-metainfo/cfeaa033-749e-48b9-... ...
gcloud
Per inviare un job a un cluster Dataproc, esegui il comando gcloud CLI gcloud dataproc jobs submit localmente in una finestra del terminale o in Cloud Shell.
gcloud dataproc jobs submit job-command \ --cluster=cluster-name \ --region=region \ other dataproc-flags \ -- job-args
- Elenca i
hello-world.pyaccessibili pubblicamente che si trovano in Cloud Storage.gcloud storage cat gs://dataproc-examples/pyspark/hello-world/hello-world.py
#!/usr/bin/python import pyspark sc = pyspark.SparkContext() rdd = sc.parallelize(['Hello,', 'world!']) words = sorted(rdd.collect()) print(words)
- Invia il job Pyspark a Dataproc.
gcloud dataproc jobs submit pyspark \ gs://dataproc-examples/pyspark/hello-world/hello-world.py \ --cluster=cluster-name \ --region=region
Waiting for job output... … ['Hello,', 'world!'] Job finished successfully.
- Esegui l'esempio SparkPi preinstallato sul nodo master del cluster Dataproc.
gcloud dataproc jobs submit spark \ --cluster=cluster-name \ --region=region \ --class=org.apache.spark.examples.SparkPi \ --jars=file:///usr/lib/spark/examples/jars/spark-examples.jar \ -- 1000
Job [54825071-ae28-4c5b-85a5-58fae6a597d6] submitted. Waiting for job output… … Pi is roughly 3.14177148 … Job finished successfully. …
REST
Questa sezione mostra come inviare un job Spark per calcolare il valore approssimativo
di pi utilizzando l'API Dataproc
jobs.submit.
Prima di utilizzare i dati della richiesta, apporta le seguenti sostituzioni:
- project-id: Google Cloud ID progetto
- region: regione del cluster
- clusterName: nome del cluster
Metodo HTTP e URL:
POST https://dataproc.googleapis.com/v1/projects/project-id/regions/region/jobs:submit
Corpo JSON della richiesta:
{
"job": {
"placement": {
"clusterName": "cluster-name"
},
"sparkJob": {
"args": [
"1000"
],
"mainClass": "org.apache.spark.examples.SparkPi",
"jarFileUris": [
"file:///usr/lib/spark/examples/jars/spark-examples.jar"
]
}
}
}
Per inviare la richiesta, espandi una di queste opzioni:
Dovresti ricevere una risposta JSON simile alla seguente:
{
"reference": {
"projectId": "project-id",
"jobId": "job-id"
},
"placement": {
"clusterName": "cluster-name",
"clusterUuid": "cluster-Uuid"
},
"sparkJob": {
"mainClass": "org.apache.spark.examples.SparkPi",
"args": [
"1000"
],
"jarFileUris": [
"file:///usr/lib/spark/examples/jars/spark-examples.jar"
]
},
"status": {
"state": "PENDING",
"stateStartTime": "2020-10-07T20:16:21.759Z"
},
"jobUuid": "job-Uuid"
}
Java
Python
Go
Node.js
Inviare un job direttamente sul cluster
Se vuoi eseguire un job direttamente sul cluster senza utilizzare il servizio Dataproc, connettiti tramite SSH al nodo master del cluster, quindi esegui il job sul nodo master.
Dopo aver stabilito una connessione SSH all'istanza master VM, esegui i comandi in una finestra del terminale sul nodo master del cluster per:
- Apri una shell Spark.
- Esegui un semplice job Spark per contare il numero di righe in un file Python "hello-world" di sette righe che si trova in un file Cloud Storage accessibile pubblicamente.
Esci dalla shell.
user@cluster-name-m:~$ spark-shell ... scala> sc.textFile("gs://dataproc-examples" + "/pyspark/hello-world/hello-world.py").count ... res0: Long = 7 scala> :quit
Esegui job bash su Dataproc
Potresti voler eseguire uno script bash come job Dataproc, perché i
motori che utilizzi non sono supportati come tipo di job Dataproc di primo livello o perché
devi eseguire configurazioni o calcoli aggiuntivi degli argomenti prima di avviare un
job utilizzando hadoop o spark-submit dallo script.
Esempio di Pig
Supponiamo di aver copiato uno script bash hello.sh in Cloud Storage:
gcloud storage cp hello.sh gs://${BUCKET}/hello.shPoiché il comando pig fs utilizza i percorsi Hadoop, copia lo script da
Cloud Storage in una destinazione specificata come file:/// per assicurarti
che si trovi nel file system locale anziché in HDFS. I comandi sh successivi
fanno riferimento automaticamente al file system locale e non richiedono il prefisso file:///.
gcloud dataproc jobs submit pig --cluster=${CLUSTER} --region=${REGION} \
-e='fs -cp -f gs://${BUCKET}/hello.sh file:///tmp/hello.sh; sh chmod 750 /tmp/hello.sh; sh /tmp/hello.sh'In alternativa, poiché le fasi dell'argomento --jars dei job Dataproc trasferiscono un file
in una directory temporanea creata per la durata del job, puoi specificare
lo script shell di Cloud Storage come argomento --jars:
gcloud dataproc jobs submit pig --cluster=${CLUSTER} --region=${REGION} \
--jars=gs://${BUCKET}/hello.sh \
-e='sh chmod 750 ${PWD}/hello.sh; sh ${PWD}/hello.sh'Tieni presente che l'argomento --jars può fare riferimento anche a uno script locale:
gcloud dataproc jobs submit pig --cluster=${CLUSTER} --region=${REGION} \
--jars=hello.sh \
-e='sh chmod 750 ${PWD}/hello.sh; sh ${PWD}/hello.sh'