Übersicht
Eine Dataproc-NodeGroup-Ressource ist eine Gruppe von Dataproc-Clusterknoten, die eine zugewiesene Rolle ausführen. Auf dieser Seite wird die Treiberknotengruppe beschrieben. Das ist eine Gruppe von Compute Engine-VMs, denen die Rolle Driver zugewiesen ist, um Job-Treiber im Dataproc-Cluster auszuführen.
Wann sollten Treiberknotengruppen verwendet werden?
- Verwenden Sie Treiberknotengruppen nur, wenn Sie viele gleichzeitige Jobs in einem freigegebenen Cluster ausführen müssen.
- Erhöhen Sie die Ressourcen des Masterknotens, bevor Sie Treiberknotengruppen verwenden, um Einschränkungen für Treiberknotengruppen zu vermeiden.
So helfen Treiberknoten bei der Ausführung paralleler Jobs
Dataproc startet für jeden Job einen Job-Treiberprozess auf einem Dataproc-Cluster-Masterknoten. Der Treiberprozess führt wiederum einen Anwendungstreiber wie spark-submit als untergeordneten Prozess aus.
Die Anzahl der gleichzeitig auf dem Master ausgeführten Jobs wird jedoch durch die auf dem Masterknoten verfügbaren Ressourcen begrenzt. Da Dataproc-Masterknoten nicht skaliert werden können, kann ein Job fehlschlagen oder gedrosselt werden, wenn die Ressourcen des Masterknotens nicht ausreichen, um einen Job auszuführen.
Treiberknotengruppen sind spezielle Knotengruppen, die von YARN verwaltet werden. Daher ist die Job-Parallelität nicht durch Masterknotenressourcen begrenzt. In Clustern mit einer Treiberknotengruppe werden Anwendungstreiber auf Treiberknoten ausgeführt. Auf jedem Treiberknoten können mehrere Anwendungstreiber ausgeführt werden, sofern der Knoten über ausreichende Ressourcen verfügt.
Vorteile
Wenn Sie einen Dataproc-Cluster mit einer Treiberknotengruppe verwenden, haben Sie folgende Möglichkeiten:
- Ressourcen von Job-Treibern horizontal skalieren, um mehr Jobs gleichzeitig auszuführen
- Treiberressourcen separat von Worker-Ressourcen skalieren
- Schnelleres Herunterskalieren von Dataproc-Clustern mit Version 2.0 und höher In diesen Clustern wird der App-Master in einem Spark-Treiber in einer Treiberknotengruppe ausgeführt. Der Wert für
spark.yarn.unmanagedAM.enabledist standardmäßig auftruefestgelegt. - Start des Treiberknotens anpassen Sie können
{ROLE} == 'Driver'in ein Initialisierungsskript einfügen, damit das Script Aktionen für eine Treiberknotengruppe in der Knotenauswahl ausführt.
Beschränkungen
- Knotengruppen werden in Dataproc-Workflow-Vorlagen nicht unterstützt.
- Knotengruppencluster können nicht angehalten, neu gestartet oder automatisch skaliert werden.
- Der MapReduce-App-Master wird auf Worker-Knoten ausgeführt. Das Herunterskalieren von Worker-Knoten kann langsam sein, wenn Sie die sanfte Außerbetriebnahme aktivieren.
- Die Job-Parallelität wird vom Clusterattribut
dataproc:agent.process.threads.job.maxbeeinflusst. Bei drei Mastern und dieser Eigenschaft, die auf den Standardwert100festgelegt ist, beträgt die maximale Job-Nebenläufigkeit auf Clusterebene300.
Fahrerknotengruppe im Vergleich zum Spark-Clustermodus
| Feature | Spark-Clustermodus | Treiberknotengruppe |
|---|---|---|
| Worker-Knoten herunterskalieren | Langlebige Treiber werden auf denselben Worker-Knoten wie kurzlebige Container ausgeführt. Das verlangsamt das Herunterskalieren von Workern mit ordnungsgemäßer Deaktivierung. | Worker-Knoten werden schneller herunterskaliert, wenn Treiber in Knotengruppen ausgeführt werden. |
| Gestreamte Treiberausgabe | Es ist eine Suche in den YARN-Protokollen erforderlich, um den Knoten zu finden, auf dem der Treiber geplant wurde. | Die Treiberausgabe wird an Cloud Storage gestreamt und kann nach Abschluss eines Jobs in der Google Cloud Console und in der gcloud dataproc jobs wait-Befehlsausgabe angezeigt werden. |
IAM-Berechtigungen für die Treiberknotengruppe
Die folgenden IAM-Berechtigungen sind mit den folgenden Dataproc-Aktionen für Knotengruppen verknüpft.
| Berechtigung | Aktion |
|---|---|
dataproc.nodeGroups.create
|
Erstellen Sie Dataproc-Knotengruppen. Wenn ein Nutzer dataproc.clusters.create im Projekt hat, wird diese Berechtigung erteilt. |
dataproc.nodeGroups.get |
Details zu einer Dataproc-Knotengruppe abrufen |
dataproc.nodeGroups.update |
Größe einer Dataproc-Knotengruppe ändern |
Vorgänge für Treiberknotengruppen
Mit der gcloud CLI und der Dataproc API können Sie eine Dataproc-Treiberknotengruppe erstellen, abrufen, die Größe ändern, löschen und einen Job an sie senden.
Cluster mit Treiberknotengruppe erstellen
Eine Treiberknotengruppe ist mit einem Dataproc-Cluster verknüpft. Sie erstellen eine Knotengruppe im Rahmen des Erstellens eines Dataproc-Clusters. Sie können die gcloud CLI oder die Dataproc REST API verwenden, um einen Dataproc-Cluster mit einer Treiberknotengruppe zu erstellen.
gcloud
gcloud dataproc clusters create CLUSTER_NAME \ --region=REGION \ --driver-pool-size=SIZE \ --driver-pool-id=NODE_GROUP_ID
Erforderliche Flags:
- CLUSTER_NAME: Der Clustername, der innerhalb eines Projekts eindeutig sein muss. Der Name muss mit einem Kleinbuchstaben beginnen und darf bis zu 51 Kleinbuchstaben, Ziffern und Bindestriche enthalten. Er darf nicht mit einem Bindestrich enden. Der Name eines gelöschten Clusters kann wiederverwendet werden.
- REGION: Die Region, in der sich der Cluster befinden wird.
- SIZE: Die Anzahl der Treiberknoten in der Knotengruppe. Die erforderliche Anzahl von Knoten hängt von der Joblast und dem Maschinentyp des Treiberpools ab. Die Anzahl der minimalen Knoten der Treibergruppe entspricht dem Gesamtarbeitsspeicher oder den Gesamt-vCPUs, die von Job-Treibern benötigt werden, geteilt durch den Arbeitsspeicher oder die vCPUs der einzelnen Treiberpools.
- NODE_GROUP_ID: Optional und empfohlen. Die ID muss innerhalb des Clusters eindeutig sein. Verwenden Sie diese ID, um die Treibergruppe bei zukünftigen Vorgängen zu identifizieren, z. B. wenn Sie die Größe der Knotengruppe ändern möchten. Wenn Sie keine ID angeben, generiert Dataproc die ID der Knotengruppe.
Empfohlene Kennzeichnung:
--enable-component-gateway: Fügen Sie dieses Flag hinzu, um das Dataproc Component Gateway zu aktivieren, das Zugriff auf die YARN-Weboberfläche bietet. Auf den YARN-UI-Seiten „Application“ (Anwendung) und „Scheduler“ (Planer) werden Cluster- und Jobstatus, Speicher der Anwendungswarteschlange, Kernkapazität und andere Messwerte angezeigt.
Zusätzliche Flags:Die folgenden optionalen driver-pool-Flags können dem Befehl gcloud dataproc clusters create hinzugefügt werden, um die Knotengruppe anzupassen.
| Flag | Standardwert |
|---|---|
--driver-pool-id |
Eine String-ID, die vom Dienst generiert wird, wenn sie nicht durch das Flag festgelegt wurde. Diese ID kann bei zukünftigen Knotenpool-Vorgängen wie dem Ändern der Größe der Knotengruppe verwendet werden. |
--driver-pool-machine-type |
n1-standard-4 |
--driver-pool-accelerator |
Kein Standardeinstellung Wenn Sie einen Beschleuniger angeben, ist der GPU-Typ erforderlich. Die Anzahl der GPUs ist optional. |
--num-driver-pool-local-ssds |
Kein Standard |
--driver-pool-local-ssd-interface |
Kein Standard |
--driver-pool-boot-disk-type |
pd-standard |
--driver-pool-boot-disk-size |
1000 GB |
--driver-pool-min-cpu-platform |
AUTOMATIC |
REST
Geben Sie eine AuxiliaryNodeGroup als Teil einer Dataproc API-cluster.create-Anfrage an.
Ersetzen Sie diese Werte in den folgenden Anfragedaten:
- PROJECT_ID: erforderlich. Google Cloud-Projekt-ID
- REGION: erforderlich. Region des Dataproc-Clusters.
- CLUSTER_NAME: erforderlich. Der Clustername, der innerhalb eines Projekts eindeutig sein muss. Der Name muss mit einem Kleinbuchstaben beginnen und darf bis zu 51 Kleinbuchstaben, Ziffern und Bindestriche enthalten. Er darf nicht mit einem Bindestrich enden. Der Name eines gelöschten Clusters kann wiederverwendet werden.
- SIZE: erforderlich. Anzahl der Knoten in der Knotengruppe.
- NODE_GROUP_ID: Optional und empfohlen. Die ID muss innerhalb des Clusters eindeutig sein. Verwenden Sie diese ID, um die Treibergruppe bei zukünftigen Vorgängen zu identifizieren, z. B. bei der Größenänderung der Knotengruppe. Wenn Sie keine ID angeben, generiert Dataproc die ID der Knotengruppe.
Weitere Optionen:Weitere Informationen finden Sie unter NodeGroup.
HTTP-Methode und URL:
POST https://dataproc.googleapis.com/v1/projects/PROJECT_ID/regions/REGION/clusters
JSON-Text anfordern:
{
"clusterName":"CLUSTER_NAME",
"config": {
"softwareConfig": {
"imageVersion":""
},
"endpointConfig": {
"enableHttpPortAccess": true
},
"auxiliaryNodeGroups": [{
"nodeGroup":{
"roles":["DRIVER"],
"nodeGroupConfig": {
"numInstances": SIZE
}
},
"nodeGroupId": "NODE_GROUP_ID"
}]
}
}
Wenn Sie die Anfrage senden möchten, maximieren Sie eine der folgenden Optionen:
Sie sollten eine JSON-Antwort ähnlich wie diese erhalten:
{
"projectId": "PROJECT_ID",
"clusterName": "CLUSTER_NAME",
"config": {
...
"auxiliaryNodeGroups": [
{
"nodeGroup": {
"name": "projects/PROJECT_ID/regions/REGION/clusters/CLUSTER_NAME/nodeGroups/NODE_GROUP_ID",
"roles": [
"DRIVER"
],
"nodeGroupConfig": {
"numInstances": SIZE,
"instanceNames": [
"CLUSTER_NAME-np-q1gp",
"CLUSTER_NAME-np-xfc0"
],
"imageUri": "https://www.googleapis.com/compute/v1/projects/cloud-dataproc-ci/global/images/dataproc-2-0-deb10-...-rc01",
"machineTypeUri": "https://www.googleapis.com/compute/v1/projects/PROJECT_ID/zones/REGION-a/machineTypes/n1-standard-4",
"diskConfig": {
"bootDiskSizeGb": 1000,
"bootDiskType": "pd-standard"
},
"managedGroupConfig": {
"instanceTemplateName": "dataproc-2a8224d2-...",
"instanceGroupManagerName": "dataproc-2a8224d2-..."
},
"minCpuPlatform": "AUTOMATIC",
"preemptibility": "NON_PREEMPTIBLE"
}
},
"nodeGroupId": "NODE_GROUP_ID"
}
]
},
}
Clustermetadaten der Treiberknotengruppe abrufen
Sie können den Befehl gcloud dataproc node-groups describe oder die Dataproc API verwenden, um Metadaten für die Treiberknotengruppe abzurufen.
gcloud
gcloud dataproc node-groups describe NODE_GROUP_ID \ --cluster=CLUSTER_NAME \ --region=REGION
Erforderliche Flags:
- NODE_GROUP_ID: Mit
gcloud dataproc clusters describe CLUSTER_NAMEkönnen Sie die ID der Knotengruppe auflisten. - CLUSTER_NAME: Der Clustername.
- REGION: Die Clusterregion.
REST
Ersetzen Sie diese Werte in den folgenden Anfragedaten:
- PROJECT_ID: erforderlich. Google Cloud-Projekt-ID
- REGION: erforderlich. Die Clusterregion.
- CLUSTER_NAME: erforderlich. Den Clusternamen.
- NODE_GROUP_ID: erforderlich. Sie können
gcloud dataproc clusters describe CLUSTER_NAMEausführen, um die Knotengruppen-ID aufzulisten.
HTTP-Methode und URL:
GET https://dataproc.googleapis.com/v1/projects/PROJECT_ID/regions/REGION/clusters/CLUSTER_NAMEnodeGroups/Node_GROUP_ID
Wenn Sie die Anfrage senden möchten, maximieren Sie eine der folgenden Optionen:
Sie sollten eine JSON-Antwort ähnlich wie diese erhalten:
{
"name": "projects/PROJECT_ID/regions/REGION/clusters/CLUSTER_NAME/nodeGroups/NODE_GROUP_ID",
"roles": [
"DRIVER"
],
"nodeGroupConfig": {
"numInstances": 5,
"imageUri": "https://www.googleapis.com/compute/v1/projects/cloud-dataproc-ci/global/images/dataproc-2-0-deb10-...-rc01",
"machineTypeUri": "https://www.googleapis.com/compute/v1/projects/PROJECT_ID/zones/REGION-a/machineTypes/n1-standard-4",
"diskConfig": {
"bootDiskSizeGb": 1000,
"bootDiskType": "pd-standard"
},
"managedGroupConfig": {
"instanceTemplateName": "dataproc-driver-pool-mcia3j656h2fy",
"instanceGroupManagerName": "dataproc-driver-pool-mcia3j656h2fy"
},
"minCpuPlatform": "AUTOMATIC",
"preemptibility": "NON_PREEMPTIBLE"
}
}
Größe einer Treiberknotengruppe ändern
Sie können den Befehl gcloud dataproc node-groups resize oder die Dataproc API verwenden, um einer Cluster-Clusterknotengruppe Treiberknoten hinzuzufügen oder daraus zu entfernen.
gcloud
gcloud dataproc node-groups resize NODE_GROUP_ID \ --cluster=CLUSTER_NAME \ --region=REGION \ --size=SIZE
Erforderliche Flags:
- NODE_GROUP_ID: Mit
gcloud dataproc clusters describe CLUSTER_NAMEkönnen Sie die ID der Knotengruppe auflisten. - CLUSTER_NAME: Der Clustername.
- REGION: Die Clusterregion.
- SIZE: Geben Sie die neue Anzahl der Treiberknoten in der Knotengruppe an.
Optionales Flag:
--graceful-decommission-timeout=TIMEOUT_DURATION: Wenn Sie eine Knotengruppe herunterskalieren, können Sie dieses Flag hinzufügen, um eine ordnungsgemäße Außerbetriebnahme TIMEOUT_DURATION anzugeben, um das sofortige Beenden von Job-Treibern zu vermeiden. Empfehlung:Legen Sie eine Zeitüberschreitung fest, die mindestens der Dauer des längsten Jobs entspricht, der in der Knotengruppe ausgeführt wird. Die Wiederherstellung fehlgeschlagener Treiber wird nicht unterstützt.
Beispiel: gcloud CLI-Befehl NodeGroup scale up:
gcloud dataproc node-groups resize NODE_GROUP_ID \ --cluster=CLUSTER_NAME \ --region=REGION \ --size=4
Beispiel: Befehl „scale down“ (verkleinern) der gcloud CLI für NodeGroup:
gcloud dataproc node-groups resize NODE_GROUP_ID \ --cluster=CLUSTER_NAME \ --region=REGION \ --size=1 \ --graceful-decommission-timeout="100s"
REST
Ersetzen Sie diese Werte in den folgenden Anfragedaten:
- PROJECT_ID: erforderlich. Google Cloud-Projekt-ID
- REGION: erforderlich. Die Clusterregion.
- NODE_GROUP_ID: erforderlich. Sie können
gcloud dataproc clusters describe CLUSTER_NAMEausführen, um die Knotengruppen-ID aufzulisten. - SIZE: erforderlich. Neue Anzahl der Knoten in der Knotengruppe.
- TIMEOUT_DURATION: Optional. Wenn Sie eine Knotengruppe herunterskalieren, können Sie dem Anfragetext ein
gracefulDecommissionTimeouthinzufügen, um eine sofortige Beendigung der Job-Treiber zu vermeiden. Empfehlung:Legen Sie eine Zeitüberschreitung fest, die mindestens der Dauer des längsten Jobs entspricht, der in der Knotengruppe ausgeführt wird. Die Wiederherstellung fehlgeschlagener Treiber wird nicht unterstützt.Beispiel:
{ "size": SIZE, "gracefulDecommissionTimeout": "TIMEOUT_DURATION" }
HTTP-Methode und URL:
POST https://dataproc.googleapis.com/v1/projects/PROJECT_ID/regions/REGION/clusters/CLUSTER_NAME/nodeGroups/Node_GROUP_ID:resize
JSON-Text anfordern:
{
"size": SIZE,
}
Wenn Sie die Anfrage senden möchten, maximieren Sie eine der folgenden Optionen:
Sie sollten eine JSON-Antwort ähnlich wie diese erhalten:
{
"name": "projects/PROJECT_ID/regions/REGION/operations/OPERATION_ID",
"metadata": {
"@type": "type.googleapis.com/google.cloud.dataproc.v1.NodeGroupOperationMetadata",
"nodeGroupId": "NODE_GROUP_ID",
"clusterUuid": "CLUSTER_UUID",
"status": {
"state": "PENDING",
"innerState": "PENDING",
"stateStartTime": "2022-12-01T23:34:53.064308Z"
},
"operationType": "RESIZE",
"description": "Scale "up or "down" a GCE node pool to SIZE nodes."
}
}
Cluster einer Treiberknotengruppe löschen
Wenn Sie einen Dataproc-Cluster löschen, werden auch die mit dem Cluster verknüpften Knotengruppen gelöscht.
Job senden
Sie können den Befehl gcloud dataproc jobs submit oder die Dataproc API verwenden, um einen Job an einen Cluster mit einer Treiberknotengruppe zu senden.
gcloud
gcloud dataproc jobs submit JOB_COMMAND \ --cluster=CLUSTER_NAME \ --region=REGION \ --driver-required-memory-mb=DRIVER_MEMORY \ --driver-required-vcores=DRIVER_VCORES \ DATAPROC_FLAGS \ -- JOB_ARGS
Erforderliche Flags:
- JOB_COMMAND: Geben Sie den Jobbefehl an.
- CLUSTER_NAME: Der Clustername.
- DRIVER_MEMORY: Arbeitsspeicherplatz in MB, der für die Ausführung eines Jobs benötigt wird (siehe Yarn-Speichersteuerungen).
- DRIVER_VCORES: Die Anzahl der vCPUs, die zum Ausführen eines Jobs erforderlich sind.
Zusätzliche Flags:
- DATAPROC_FLAGS: Fügen Sie alle zusätzlichen gcloud dataproc jobs submit-Flags hinzu, die sich auf den Jobtyp beziehen.
- JOB_ARGS: Fügen Sie nach dem
--Argumente hinzu, die an den Job übergeben werden sollen.
Beispiele:Sie können die folgenden Beispiele in einer SSH-Terminalsitzung auf einem Dataproc-Cluster mit Treiberknotengruppe ausführen.
Spark-Job zum Schätzen des Werts von
pi:gcloud dataproc jobs submit spark \ --cluster=CLUSTER_NAME \ --region=REGION \ --driver-required-memory-mb=2048 \ --driver-required-vcores=2 \ --class=org.apache.spark.examples.SparkPi \ --jars=file:///usr/lib/spark/examples/jars/spark-examples.jar \ -- 1000
Spark-WordCount-Job:
gcloud dataproc jobs submit spark \ --cluster=CLUSTER_NAME \ --region=REGION \ --driver-required-memory-mb=2048 \ --driver-required-vcores=2 \ --class=org.apache.spark.examples.JavaWordCount \ --jars=file:///usr/lib/spark/examples/jars/spark-examples.jar \ -- 'gs://apache-beam-samples/shakespeare/macbeth.txt'
PySpark-Job zum Schätzen des Werts von
pi:gcloud dataproc jobs submit pyspark \ file:///usr/lib/spark/examples/src/main/python/pi.py \ --cluster=CLUSTER_NAME \ --region=REGION \ --driver-required-memory-mb=2048 \ --driver-required-vcores=2 \ -- 1000
Hadoop-TeraGen-MapReduce-Job:
gcloud dataproc jobs submit hadoop \ --cluster=CLUSTER_NAME \ --region=REGION \ --driver-required-memory-mb=2048 \ --driver-required-vcores=2 \ --jar file:///usr/lib/hadoop-mapreduce/hadoop-mapreduce-examples.jar \ -- teragen 1000 \ hdfs:///gen1/test
REST
Ersetzen Sie diese Werte in den folgenden Anfragedaten:
- PROJECT_ID: erforderlich. Google Cloud-Projekt-ID
- REGION: erforderlich. Region des Dataproc-Clusters
- CLUSTER_NAME: erforderlich. Der Clustername, der innerhalb eines Projekts eindeutig sein muss. Der Name muss mit einem Kleinbuchstaben beginnen und darf bis zu 51 Kleinbuchstaben, Ziffern und Bindestriche enthalten. Er darf nicht mit einem Bindestrich enden. Der Name eines gelöschten Clusters kann wiederverwendet werden.
- DRIVER_MEMORY: erforderlich. Größe des Arbeitsspeichers für Job-Treiber in MB, der zum Ausführen eines Jobs erforderlich ist (siehe Yarn-Speichersteuerungen).
- DRIVER_VCORES: erforderlich. Die Anzahl der vCPUs, die zum Ausführen eines Jobs erforderlich sind.
pi geschätzt wird.
HTTP-Methode und URL:
POST https://dataproc.googleapis.com/v1/projects/PROJECT_ID/regions/REGION/jobs:submit
JSON-Text anfordern:
{
"job": {
"placement": {
"clusterName": "CLUSTER_NAME",
},
"driverSchedulingConfig": {
"memoryMb]": DRIVER_MEMORY,
"vcores": DRIVER_VCORES
},
"sparkJob": {
"jarFileUris": "file:///usr/lib/spark/examples/jars/spark-examples.jar",
"args": [
"10000"
],
"mainClass": "org.apache.spark.examples.SparkPi"
}
}
}
Wenn Sie die Anfrage senden möchten, maximieren Sie eine der folgenden Optionen:
Sie sollten eine JSON-Antwort ähnlich wie diese erhalten:
{
"reference": {
"projectId": "PROJECT_ID",
"jobId": "job-id"
},
"placement": {
"clusterName": "CLUSTER_NAME",
"clusterUuid": "cluster-Uuid"
},
"sparkJob": {
"mainClass": "org.apache.spark.examples.SparkPi",
"args": [
"1000"
],
"jarFileUris": [
"file:///usr/lib/spark/examples/jars/spark-examples.jar"
]
},
"status": {
"state": "PENDING",
"stateStartTime": "start-time"
},
"jobUuid": "job-Uuid"
}
Jobprotokolle ansehen
Sie können den Jobstatus und die Jobprobleme mithilfe der gcloud CLI oder der Google Cloud Console prüfen.
gcloud
Job-Treiber-Logs werden während der Jobausführung an die gcloud CLI-Ausgabe oder die Google Cloud Console gestreamt. Treiberprotokolle werden im Staging-Bucket des Dataproc-Clusters in Cloud Storage gespeichert.
Führen Sie den folgenden gcloud CLI-Befehl aus, um den Speicherort der Treiberprotokolle in Cloud Storage aufzulisten:
gcloud dataproc jobs describe JOB_ID \ --region=REGION
Der Cloud Storage-Speicherort der Treiberprotokolle wird in der Befehlsausgabe als driverOutputResourceUri im folgenden Format aufgeführt:
driverOutputResourceUri: gs://CLUSTER_STAGING_BUCKET/google-cloud-dataproc-metainfo/CLUSTER_UUID/jobs/JOB_ID
Console
So rufen Sie Clusterprotokolle der Knotengruppe auf:
Sie können das folgende Abfrageformat im Log-Explorer verwenden, um Logs zu finden:
resource.type="cloud_dataproc_cluster" resource.labels.project_id="PROJECT_ID" resource.labels.cluster_name="CLUSTER_NAME" log_name="projects/PROJECT_ID/logs/LOG_TYPE>"
- PROJECT_ID: Google Cloud Projekt-ID.
- CLUSTER_NAME: Der Clustername.
- LOG_TYPE:
- Yarn-Nutzerprotokolle:
yarn-userlogs - Yarn-Ressourcenmanager-Protokolle:
hadoop-yarn-resourcemanager - Yarn-Knotenmanager-Logs:
hadoop-yarn-nodemanager
- Yarn-Nutzerprotokolle:
Messwerte überwachen
Dataproc-Knotengruppen-Job-Treiber werden in einer dataproc-driverpool-driver-queue-Unterwarteschlange unter einer dataproc-driverpool-Partition ausgeführt.
Messwerte für Treiberknotengruppen
In der folgenden Tabelle sind die zugehörigen Knotengruppenmesswerte für Treiber aufgeführt, die standardmäßig für Treiberknotengruppen erfasst werden.
| Messwert für Treiberknotengruppe | Beschreibung |
|---|---|
yarn:ResourceManager:DriverPoolsQueueMetrics:AvailableMB |
Die Menge des verfügbaren Arbeitsspeichers in Mebibyte in dataproc-driverpool-driver-queue unter der Partition dataproc-driverpool.
|
yarn:ResourceManager:DriverPoolsQueueMetrics:PendingContainers |
Die Anzahl der ausstehenden (in der Warteschlange befindlichen) Container in dataproc-driverpool-driver-queue unter der Partition dataproc-driverpool. |
Messwerte für untergeordnete Warteschlangen
In der folgenden Tabelle sind die Messwerte für untergeordnete Warteschlangen aufgeführt. Die Messwerte werden standardmäßig für Treiberknotengruppen erfasst und können für die Erfassung in allen Dataproc-Clustern aktiviert werden.
| Messwert für untergeordnete Warteschlange | Beschreibung |
|---|---|
yarn:ResourceManager:ChildQueueMetrics:AvailableMB |
Die Größe des verfügbaren Arbeitsspeichers in dieser Warteschlange unter der Standardpartition in Mebibyte. |
yarn:ResourceManager:ChildQueueMetrics:PendingContainers |
Anzahl der ausstehenden (in der Warteschlange befindlichen) Container in dieser Warteschlange in der Standardpartition. |
yarn:ResourceManager:ChildQueueMetrics:running_0 |
Die Anzahl der Jobs mit einer Laufzeit zwischen 0 und 60 Minuten in dieser Warteschlange unter allen Partitionen. |
yarn:ResourceManager:ChildQueueMetrics:running_60 |
Die Anzahl der Jobs mit einer Laufzeit zwischen 60 und 300 Minuten in dieser Warteschlange unter allen Partitionen. |
yarn:ResourceManager:ChildQueueMetrics:running_300 |
Die Anzahl der Jobs mit einer Laufzeit zwischen 300 und 1440 Minuten in dieser Warteschlange unter allen Partitionen. |
yarn:ResourceManager:ChildQueueMetrics:running_1440 |
Die Anzahl der Jobs mit einer Laufzeit von mehr als 1440 Minuten in dieser Warteschlange in allen Partitionen. |
yarn:ResourceManager:ChildQueueMetrics:AppsSubmitted |
Anzahl der Anwendungen, die in dieser Warteschlange unter allen Partitionen eingereicht wurden. |
So rufen Sie YARN ChildQueueMetrics und DriverPoolsQueueMetrics in der Google Cloud Console auf:
- Wählen Sie im Metrics Explorer die Ressourcen VM-Instanz → Benutzerdefiniert aus.
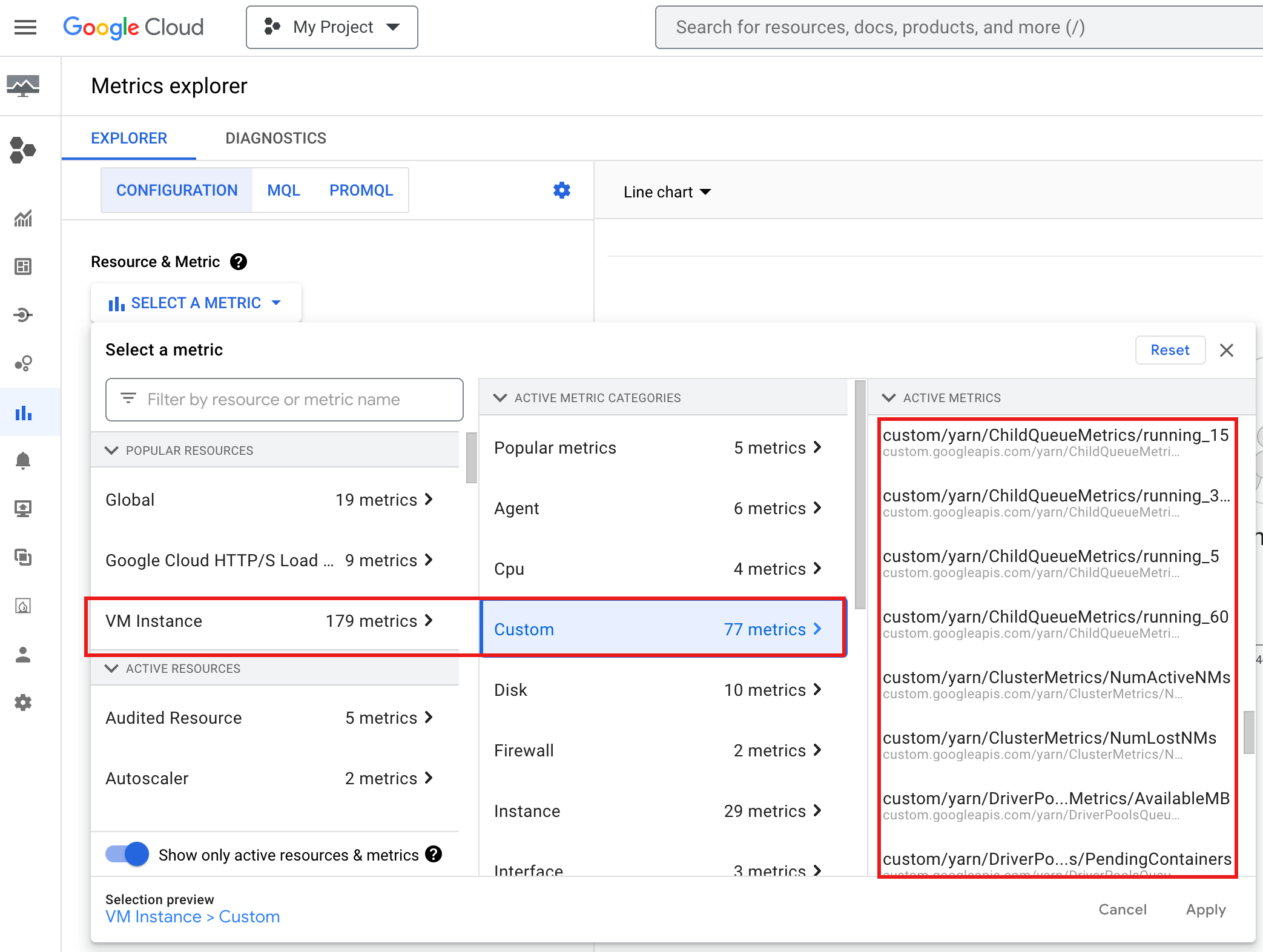
Debugging des Job-Treibers für Knotengruppen
Dieser Abschnitt enthält Bedingungen und Fehler für Treiberknotengruppen mit Empfehlungen zur Behebung der jeweiligen Situation.
Bedingungen
Bedingung:
yarn:ResourceManager:DriverPoolsQueueMetrics:AvailableMBnähert sich0. Dies bedeutet, dass in der Warteschlange der Cluster-Treiberpools nicht genügend Arbeitsspeicher verfügbar ist.Empfehlung: Erhöhen Sie die Größe des Fahrerpools.
Bedingung:
yarn:ResourceManager:DriverPoolsQueueMetrics:PendingContainersist größer als 0. Dies kann darauf hindeuten, dass der Arbeitsspeicher der Cluster-Treiberpool-Warteschlange aufgebraucht ist und YARN Jobs in die Warteschlange stellt.Empfehlung: Erhöhen Sie die Größe des Fahrerpools.
Fehler
Fehler:
Cluster <var>CLUSTER_NAME</var> requires driver scheduling config to run SPARK job because it contains a node pool with role DRIVER. Positive values are required for all driver scheduling config values.Empfehlung:Legen Sie für
driver-required-memory-mbunddriver-required-vcorespositive Zahlen fest.Fehler:
Container exited with a non-zero exit code 137.Empfehlung:Erhöhen Sie
driver-required-memory-mbauf die Arbeitsspeichernutzung des Jobs.