Los registros de tareas y clústeres de Dataproc se pueden ver, buscar, filtrar y archivar en Cloud Logging.
Consulta los precios de Google Cloud Observability para conocer tus costes.
Consulta Periodos de conservación de los registros para obtener información sobre la conservación de registros.
Consulta Exclusiones de registros para inhabilitar todos los registros o excluir registros de Logging.
Consulta la descripción general del enrutamiento y el almacenamiento para enrutar los registros de Logging a Cloud Storage, BigQuery o Pub/Sub.
Niveles de registro de componentes
Define los niveles de registro de Spark, Hadoop, Flink y otros componentes de Dataproc con propiedades de clúster log4j específicas de cada componente, como hadoop-log4j, al crear un clúster. Los niveles de registro de componentes basados en clústeres se aplican a los daemons de servicio, como YARN ResourceManager, y a los trabajos que se ejecutan en el clúster.
Si no se admiten las propiedades de log4j en un componente, como el componente Presto, escribe una acción de inicialización que edite el archivo log4j.properties o log4j2.properties del componente.
Niveles de registro de componentes específicos de una tarea: también puedes definir niveles de registro de componentes cuando envías una tarea. Estos niveles de registro se aplican al trabajo y tienen prioridad sobre los niveles de registro definidos al crear el clúster. Consulta más información sobre las propiedades de clústeres y de trabajos.
Niveles de registro de la versión de los componentes Spark y Hive:
Los componentes Spark 3.3.X y Hive 3.X usan propiedades de log4j2, mientras que las versiones anteriores de estos componentes usan propiedades de log4j (consulta Apache Log4j2).
Usa el prefijo spark-log4j: para definir los niveles de registro de Spark en un clúster.
Ejemplo: versión de imagen 2.0 de Dataproc con Spark 3.1 para definir
log4j.logger.org.apache.spark:gcloud dataproc clusters create ... \ --properties spark-log4j:log4j.logger.org.apache.spark=DEBUG
Por ejemplo, versión de imagen de Dataproc 2.1 con Spark 3.3 para definir
logger.sparkRoot.level:gcloud dataproc clusters create ...\ --properties spark-log4j:logger.sparkRoot.level=debug
Niveles de registro del controlador de tareas
Dataproc usa un nivel de registro predeterminado
INFO para los programas de controladores de tareas. Puedes cambiar este ajuste para uno o varios paquetes con la marca gcloud dataproc jobs submit
--driver-log-levels.
Ejemplo:
Define el DEBUGnivel de registro al enviar una tarea de Spark que lea archivos de Cloud Storage.
gcloud dataproc jobs submit spark ...\ --driver-log-levels org.apache.spark=DEBUG,com.google.cloud.hadoop.gcsio=DEBUG
Ejemplo:
Define el nivel del registrador root como WARN y el nivel del registrador com.example como INFO.
gcloud dataproc jobs submit hadoop ...\ --driver-log-levels root=WARN,com.example=INFO
Niveles de registro del ejecutor de Spark
Para configurar los niveles de registro de los ejecutores de Spark, sigue estos pasos:
Prepara un archivo de configuración de log4j y, a continuación, súbelo a Cloud Storage.
.Haz referencia al archivo de configuración cuando envíes el trabajo.
Ejemplo:
gcloud dataproc jobs submit spark ...\ --file gs://my-bucket/path/spark-log4j.properties \ --properties spark.executor.extraJavaOptions=-Dlog4j.configuration=file:spark-log4j.properties
Spark descarga el archivo de propiedades de Cloud Storage en el directorio de trabajo local del trabajo, al que se hace referencia como file:<name> en -Dlog4j.configuration.
Registros de tareas de Dataproc en Logging
Consulta Registros y resultados de las tareas de Dataproc para obtener información sobre cómo habilitar los registros de controladores de tareas de Dataproc en Logging.
Acceder a los registros de tareas en Logging
Accede a los registros de trabajos de Dataproc con el Explorador de registros, el comando gcloud logging o la API Logging.
Consola
Los registros de controladores de tareas de Dataproc y de contenedores de YARN se muestran en el recurso Tarea de Cloud Dataproc.
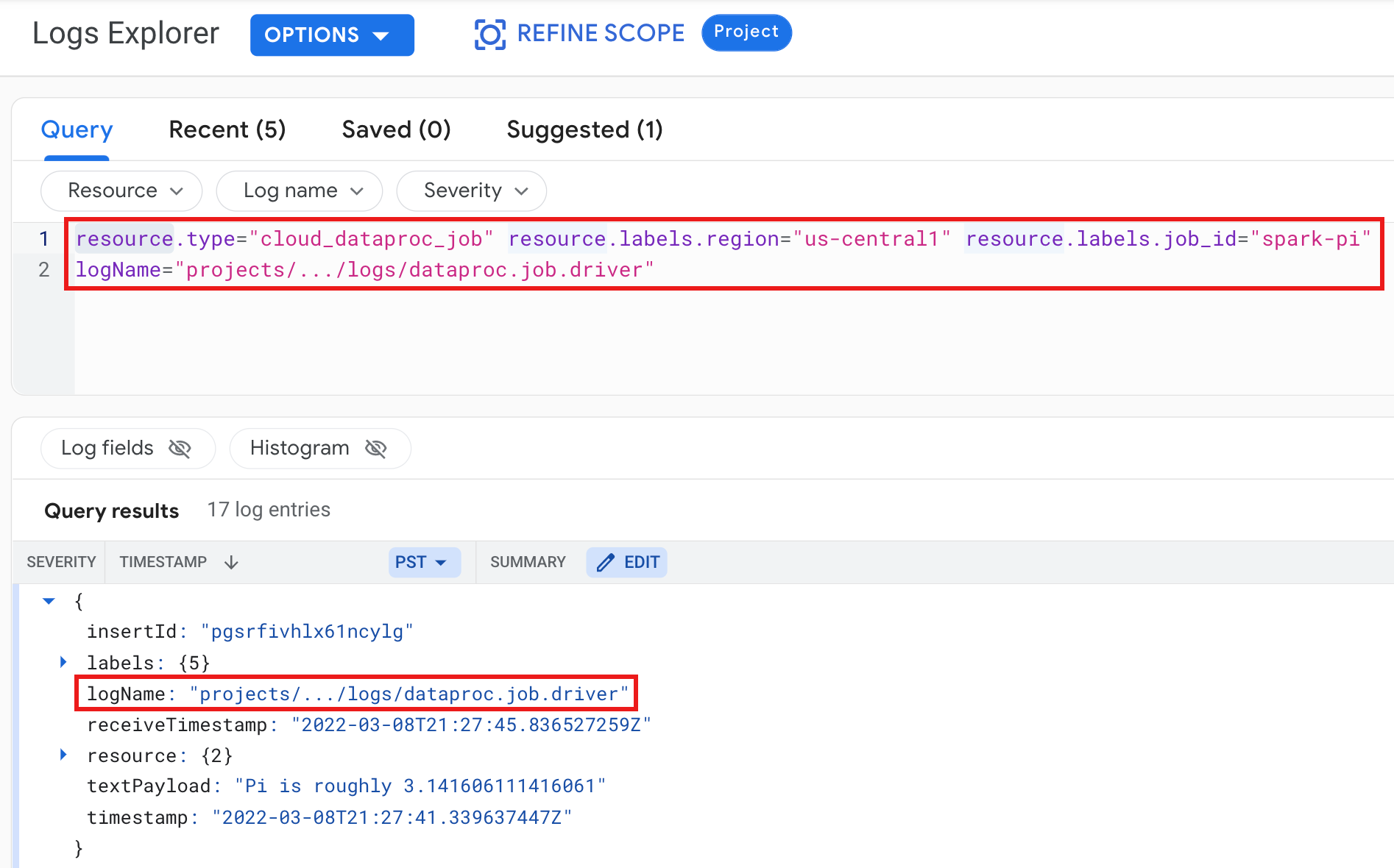
Ejemplo: registro del controlador de trabajos después de ejecutar una consulta del explorador de registros con las siguientes selecciones:
- Recurso:
Cloud Dataproc Job - Nombre del registro:
dataproc.job.driver
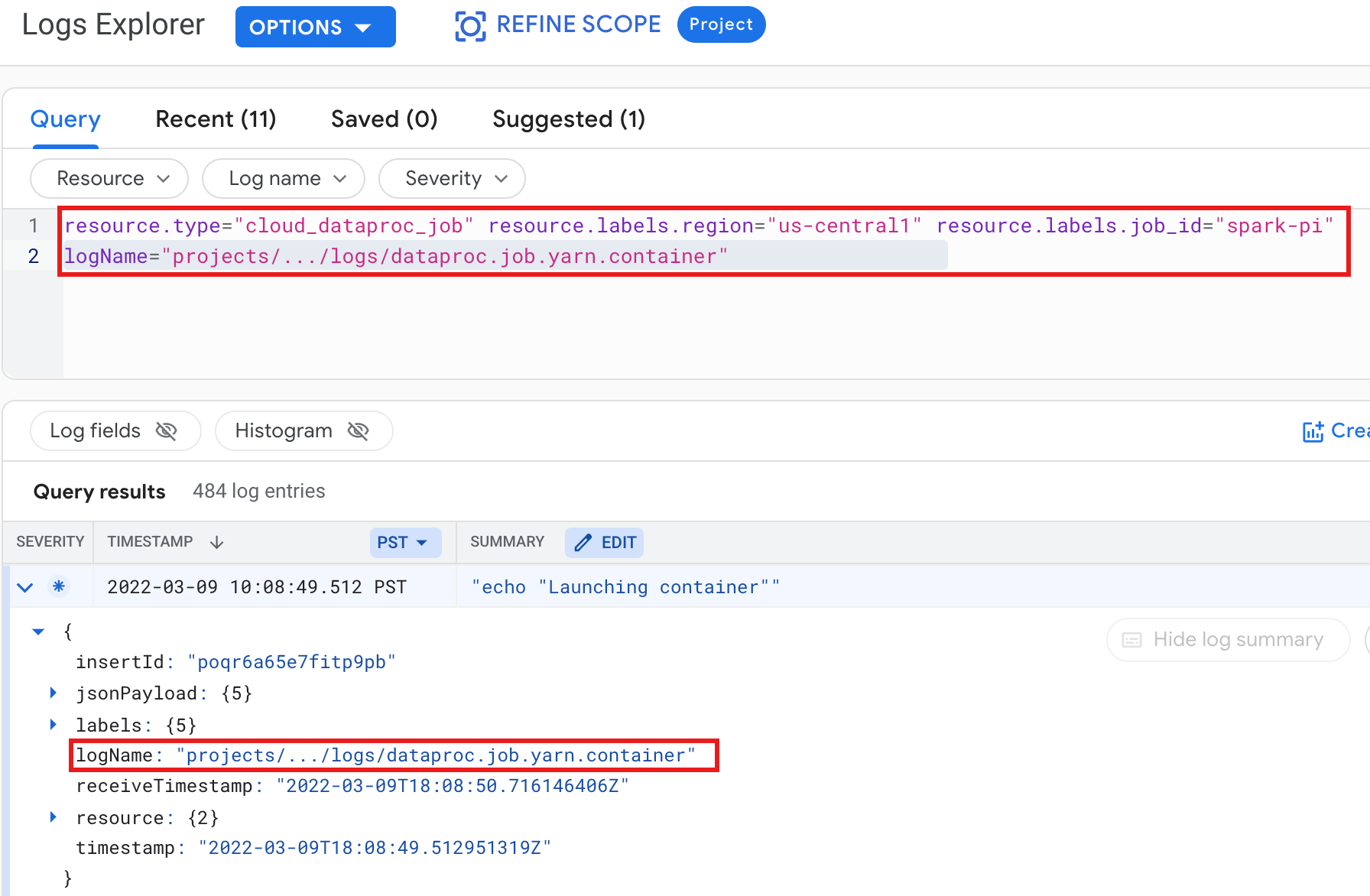
Ejemplo: registro de contenedor de YARN después de ejecutar una consulta de Explorador de registros con las siguientes selecciones:
- Recurso:
Cloud Dataproc Job - Nombre del registro:
dataproc.job.yarn.container
gcloud
Puedes leer las entradas de registro de un trabajo con el comando gcloud logging read. Los argumentos de los recursos deben ir entre comillas ("..."). El siguiente comando usa etiquetas de clúster para filtrar las entradas de registro devueltas.
gcloud logging read \ "resource.type=cloud_dataproc_job \ resource.labels.region=cluster-region \ resource.labels.job_id=my-job-id"
Ejemplo de salida (parcial):
jsonPayload: class: org.apache.hadoop.hdfs.StateChange filename: hadoop-hdfs-namenode-test-dataproc-resize-cluster-20190410-38an-m-0.log ,,, logName: projects/project-id/logs/hadoop-hdfs-namenode --- jsonPayload: class: SecurityLogger.org.apache.hadoop.security.authorize.ServiceAuthorizationManager filename: cluster-name-dataproc-resize-cluster-20190410-38an-m-0.log ... logName: projects/google.com:hadoop-cloud-dev/logs/hadoop-hdfs-namenode
API REST
Puede usar la API REST de Logging para enumerar las entradas de registro (consulte entries.list).
Registros de clústeres de Dataproc en Logging
Dataproc exporta los siguientes registros de clústeres de Apache Hadoop, Spark, Hive, Zookeeper y otros de Dataproc a Cloud Logging.
| Tipo de registro | Nombre del registro | Descripción | Notas |
|---|---|---|---|
| Registros del daemon maestro | hadoop-hdfs hadoop-hdfs-namenode hadoop-hdfs-secondarynamenode hadoop-hdfs-zkfc hadoop-yarn-resourcemanager hadoop-yarn-timelineserver hive-metastore hive-server2 mapred-mapred-historyserver zookeeper |
Nodo de registro Namenode de HDFS Namenode secundario de HDFS Controlador de conmutación por error de ZooKeeper Gestor de recursos de YARN Servidor de cronología de YARN Metastore de Hive Servidor 2 de Hive Servidor de historial de tareas de MapReduce Servidor de ZooKeeper |
|
| Registros de daemon de trabajador |
hadoop-hdfs-datanode hadoop-yarn-nodemanager |
Nodo de datos de HDFS Gestor de nodos de YARN |
|
| Registros del sistema |
autoscaler google.dataproc.agent google.dataproc.startup |
Registro del escalador automático de Dataproc Registro del agente de Dataproc Registro de la secuencia de comandos de inicio de Dataproc + registro de la acción de inicialización |
|
| Registros ampliados (adicionales) |
knox gateway-audit zeppelin ranger-usersync jupyter_notebook jupyter_kernel_gateway spark-history-server |
Todos los registros de los subdirectorios de /var/log/ que coincidan con:knox (incluye gateway-audit.log) zeppelin ranger-usersync jupyter_notebook jupyter_kernel_gateway spark-history-server |
Si se define la propiedad
dataproc:dataproc.logging.extended.enabled=false, se inhabilita la recogida de registros ampliados en el clúster.
|
| Registros del sistema de la máquina virtual |
syslog |
Registros del sistema de los nodos maestros y de trabajador del clúster |
Si se define la propiedad
dataproc:dataproc.logging.syslog.enabled=false, se inhabilita la recogida de registros del sistema de las máquinas virtuales en el clúster.
|
Acceder a los registros de clústeres en Cloud Logging
Puedes acceder a los registros de clústeres de Dataproc con el Explorador de registros, el comando gcloud logging o la API Logging.
Consola
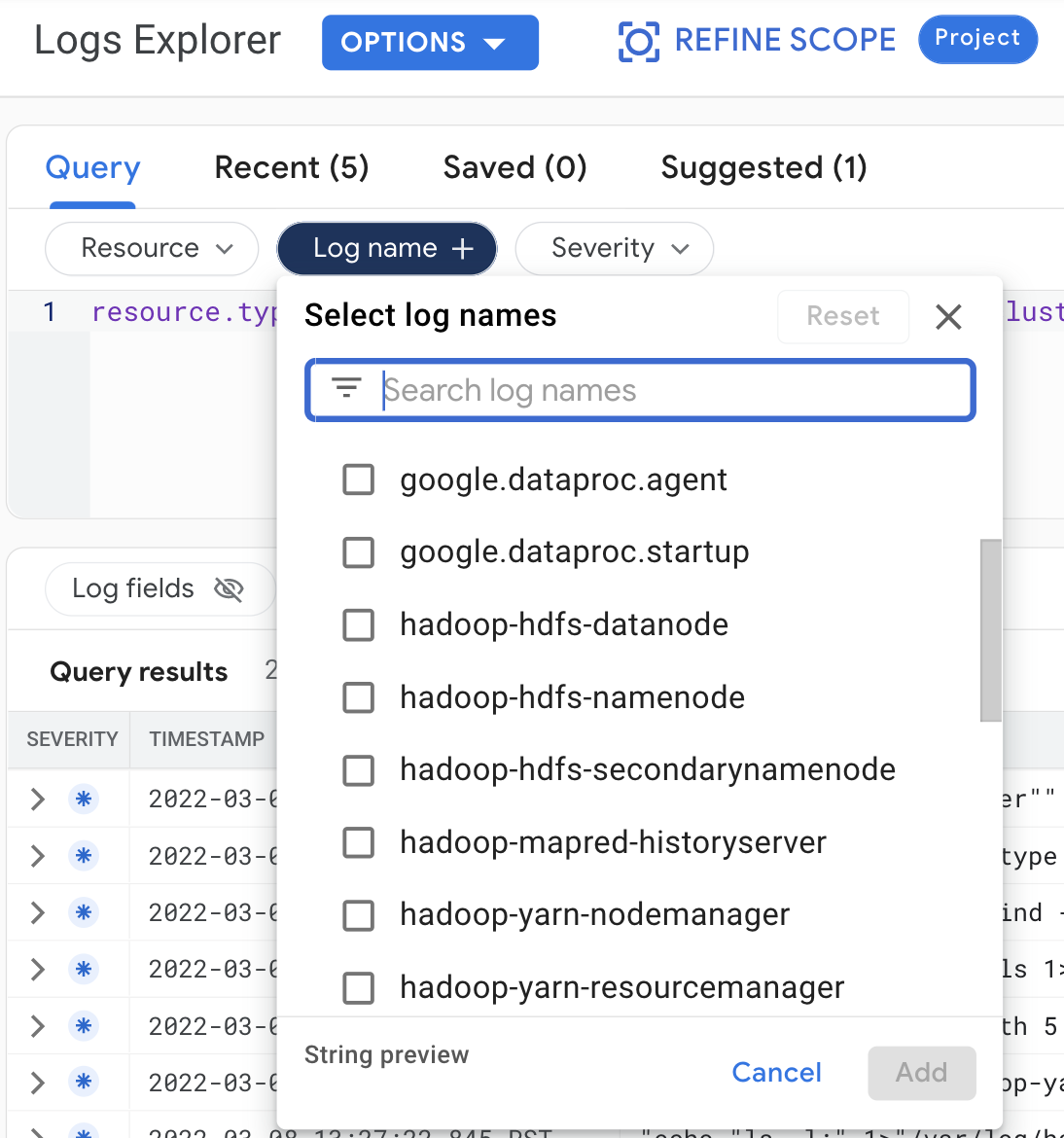
Seleccione las siguientes opciones de consulta para ver los registros del clúster en el Explorador de registros:
- Recurso:
Cloud Dataproc Cluster - Nombre del registro: log name
gcloud
Puedes leer las entradas de registro de un clúster con el comando gcloud logging read. Los argumentos de los recursos deben ir entre comillas ("..."). El siguiente comando usa etiquetas de clúster para filtrar las entradas de registro devueltas.
gcloud logging read <<'EOF' "resource.type=cloud_dataproc_cluster resource.labels.region=cluster-region resource.labels.cluster_name=cluster-name resource.labels.cluster_uuid=cluster-uuid" EOF
Ejemplo de salida (parcial):
jsonPayload: class: org.apache.hadoop.yarn.server.resourcemanager.ResourceTrackerService filename: hadoop-yarn-resourcemanager-cluster-name-m.log ... logName: projects/project-id/logs/hadoop-yarn-resourcemanager --- jsonPayload: class: org.apache.hadoop.yarn.server.resourcemanager.ResourceTrackerService filename: hadoop-yarn-resourcemanager-component-gateway-cluster-m.log ... logName: projects/project-id/logs/hadoop-yarn-resourcemanager
API REST
Puede usar la API REST de Logging para enumerar las entradas de registro (consulte entries.list).
Permisos
Para escribir registros en Logging, la cuenta de servicio de la VM de Dataproc debe tener el rol de gestión de identidades y accesos logging.logWriter. La cuenta de servicio predeterminada de Dataproc tiene este rol. Si usas una cuenta de servicio personalizada, debes asignar este rol a la cuenta de servicio.
Proteger los registros
De forma predeterminada, los registros de Logging se cifran en reposo. Puedes habilitar las claves de cifrado gestionadas por el cliente (CMEK) para cifrar los registros. Para obtener más información sobre la compatibilidad con CMEK, consulta Gestionar las claves que protegen los datos del enrutador de registros y Gestionar las claves que protegen los datos de almacenamiento de Logging.
Siguientes pasos
- Consulta Google Cloud Observability.