Dataproc job and cluster logs can be viewed, searched, filtered, and archived in Cloud Logging.
See Google Cloud Observability pricing to understand your costs.
See Logs retention periods for information on logging retention.
See Logs exclusions to disable all logs or exclude logs from Logging.
See Routing and storage overview to route logs from Logging to Cloud Storage, BigQuery, or Pub/Sub.
Component logging levels
Set Spark, Hadoop, Flink, and other Dataproc component
logging levels with component-specific log4j
cluster properties,
such as hadoop-log4j, when you
create a cluster. Cluster-based
component logging levels apply to service daemons, such as the YARN ResourceManager,
and to jobs that run on the cluster.
If log4j properties are not supported for a component, such as the Presto component,
write an initialization action
that edits the component's log4j.properties or log4j2.properties file.
Job-specific component logging levels: You can also set component logging levels when you submit a job. These logging levels are applied to the job, and take precedence over logging levels set when you created the cluster. See Cluster vs. job properties for more information.
Spark and Hive component version logging levels:
The Spark 3.3.X and Hive 3.X components use log4j2 properties,
while previous versions of these components use log4j properties (see
Apache Log4j2).
Use a spark-log4j: prefix to set Spark logging levels on a cluster.
Example: Dataproc image version 2.0 with Spark 3.1 to set
log4j.logger.org.apache.spark:gcloud dataproc clusters create ... \ --properties spark-log4j:log4j.logger.org.apache.spark=DEBUG
Example: Dataproc image version 2.1 with Spark 3.3 to set
logger.sparkRoot.level:gcloud dataproc clusters create ...\ --properties spark-log4j:logger.sparkRoot.level=debug
Job driver logging levels
Dataproc uses a default
logging level
of INFO for job driver programs. You can change this setting for one or more packages
with the gcloud dataproc jobs submit
--driver-log-levels flag.
Example:
Set the DEBUG logging level when submitting a Spark job that reads
Cloud Storage files.
gcloud dataproc jobs submit spark ...\ --driver-log-levels org.apache.spark=DEBUG,com.google.cloud.hadoop.gcsio=DEBUG
Example:
Set the root logger level to WARN, com.example logger level to INFO.
gcloud dataproc jobs submit hadoop ...\ --driver-log-levels root=WARN,com.example=INFO
Spark executor logging levels
To configure Spark executor logging levels:
Prepare a log4j config file, and then upload it to Cloud Storage
.
Reference your config file when you submit the job.
Example:
gcloud dataproc jobs submit spark ...\ --file gs://my-bucket/path/spark-log4j.properties \ --properties spark.executor.extraJavaOptions=-Dlog4j.configuration=file:spark-log4j.properties
Spark downloads the Cloud Storage properties file to the job's
local working directory, referenced as file:<name> in -Dlog4j.configuration.
Dataproc job logs in Logging
See Dataproc job output and logs for information on enabling Dataproc job driver logs in Logging.
Access job logs in Logging
Access Dataproc job logs using the Logs Explorer, the gcloud logging command, or the Logging API.
Console
Dataproc Job driver and YARN container logs are listed under the Cloud Dataproc Job resource.
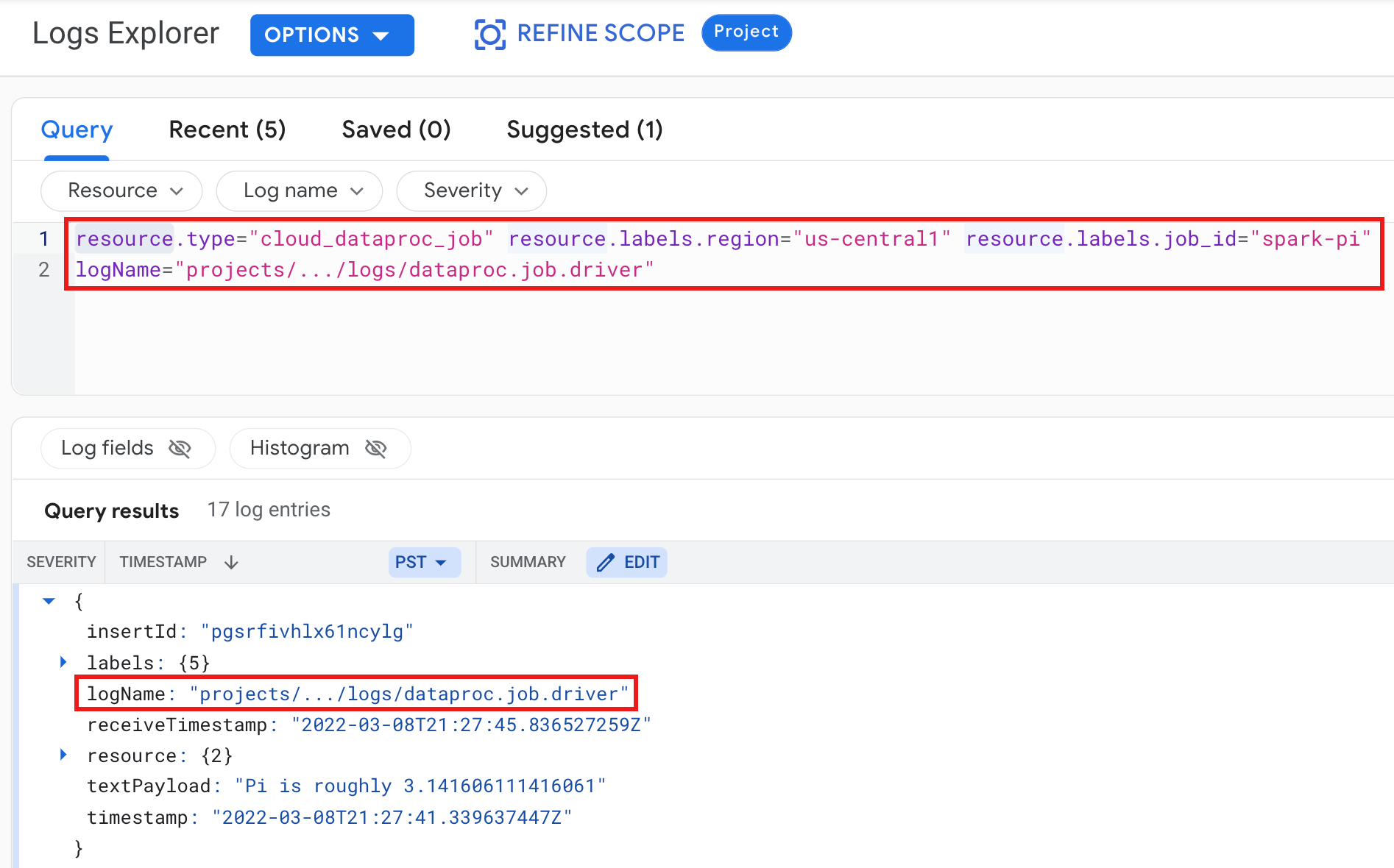
Example: Job driver log after running a Logs Explorer query with the following selections:
- Resource:
Cloud Dataproc Job - Log name:
dataproc.job.driver
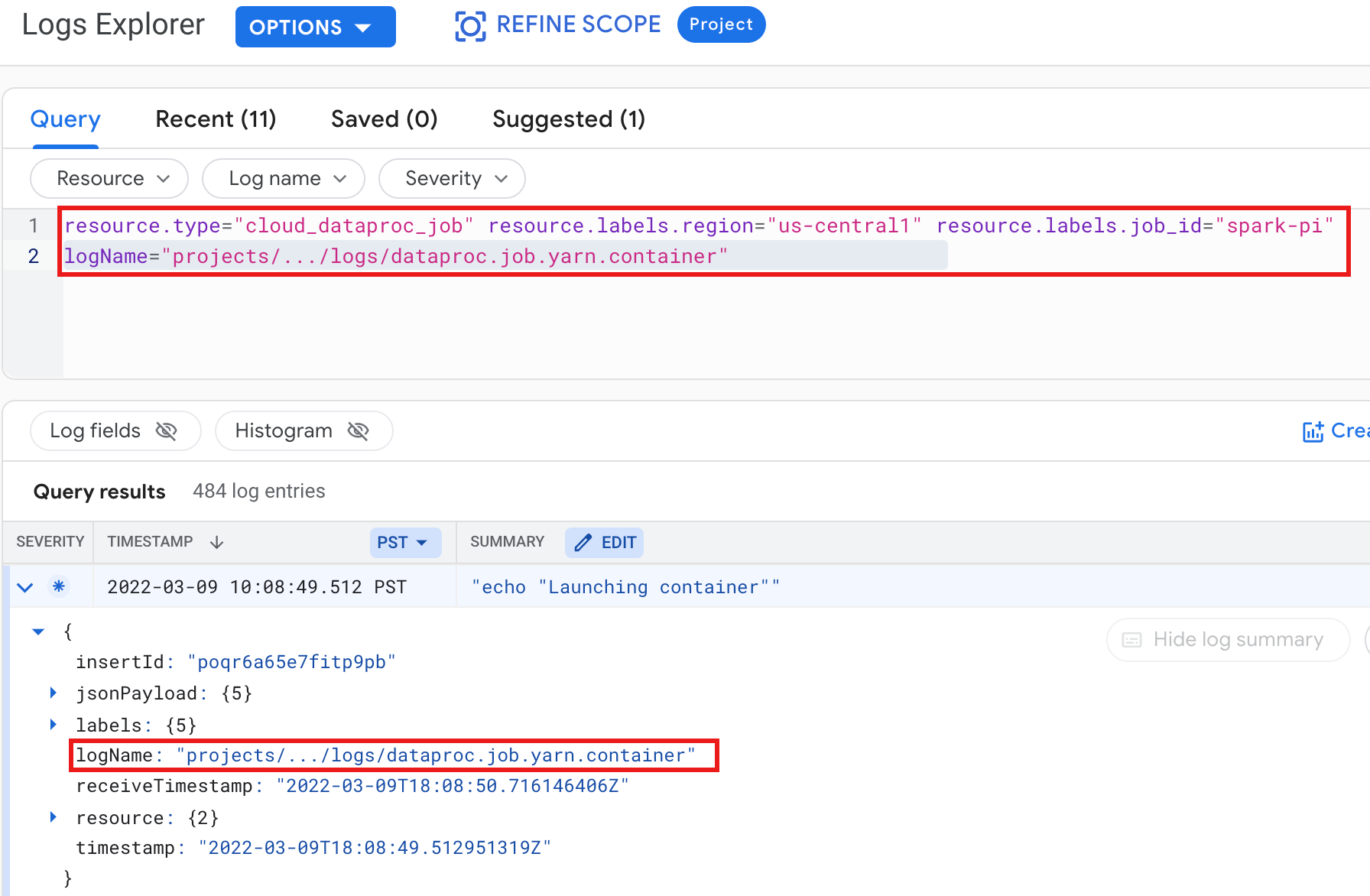
Example: YARN container log after running a Logs Explorer query with the following selections:
- Resource:
Cloud Dataproc Job - Log name:
dataproc.job.yarn.container
gcloud
You can read job log entries using the gcloud logging read command. The resource arguments must be enclosed in quotes ("..."). The following command uses cluster labels to filter the returned log entries.
gcloud logging read \ "resource.type=cloud_dataproc_job \ resource.labels.region=cluster-region \ resource.labels.job_id=my-job-id"
Sample output (partial):
jsonPayload: class: org.apache.hadoop.hdfs.StateChange filename: hadoop-hdfs-namenode-test-dataproc-resize-cluster-20190410-38an-m-0.log ,,, logName: projects/project-id/logs/hadoop-hdfs-namenode --- jsonPayload: class: SecurityLogger.org.apache.hadoop.security.authorize.ServiceAuthorizationManager filename: cluster-name-dataproc-resize-cluster-20190410-38an-m-0.log ... logName: projects/google.com:hadoop-cloud-dev/logs/hadoop-hdfs-namenode
REST API
You can use the Logging REST API to list log entries (see entries.list).
Dataproc cluster logs in Logging
Dataproc exports the following Apache Hadoop, Spark, Hive, Zookeeper, and other Dataproc cluster logs to Cloud Logging.
| Log Type | Log Name | Description | Notes |
|---|---|---|---|
| Master daemon logs | hadoop-hdfs hadoop-hdfs-namenode hadoop-hdfs-secondarynamenode hadoop-hdfs-zkfc hadoop-yarn-resourcemanager hadoop-yarn-timelineserver hive-metastore hive-server2 mapred-mapred-historyserver zookeeper |
Journal node HDFS namenode HDFS secondary namenode Zookeeper failover controller YARN resource manager YARN timeline server Hive metastore Hive server2 Mapreduce job history server Zookeeper server |
|
| Worker daemon logs |
hadoop-hdfs-datanode hadoop-yarn-nodemanager |
HDFS datanode YARN nodemanager |
|
| System logs |
autoscaler google.dataproc.agent google.dataproc.startup |
Dataproc autoscaler log Dataproc agent log Dataproc startup script log + initialization action log |
|
| Extended (additional) logs |
knox gateway-audit zeppelin ranger-usersync jupyter_notebook jupyter_kernel_gateway spark-history-server |
All logs inside /var/log/ subdirectories matching:knox (includes gateway-audit.log) zeppelin ranger-usersync jupyter_notebook jupyter_kernel_gateway spark-history-server |
Setting the
dataproc:dataproc.logging.extended.enabled=false property disables the collection of extended logs on the cluster
|
| VM syslogs |
syslog |
Syslogs from cluster's master and worker nodes |
Setting the
dataproc:dataproc.logging.syslog.enabled=false property disables the collection of VM syslogs on the cluster
|
Access cluster logs in Cloud Logging
You can access Dataproc cluster logs using the Logs Explorer, the gcloud logging command, or the Logging API.
Console
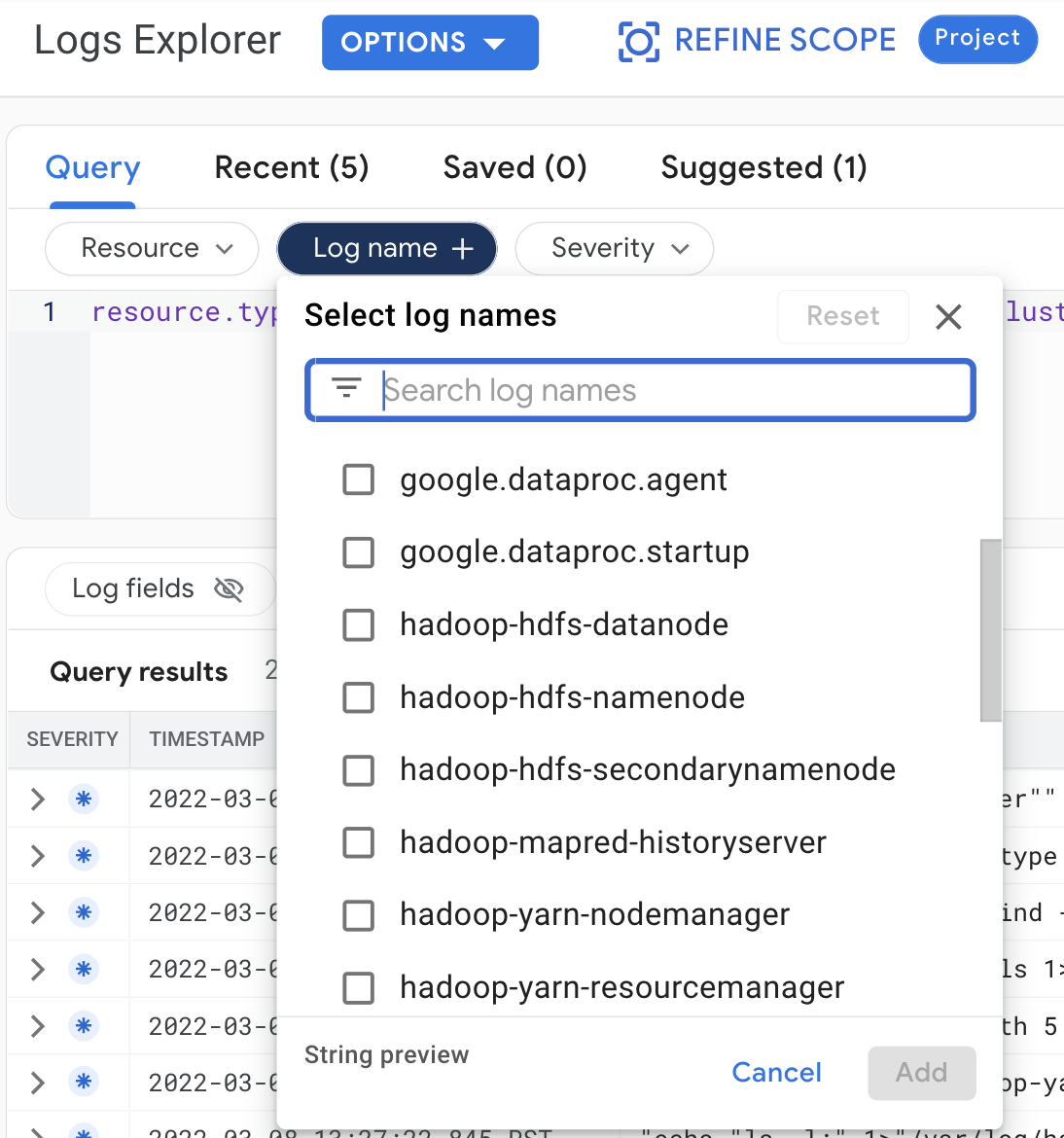
Make the following query selections to view cluster logs in the Logs Explorer:
- Resource:
Cloud Dataproc Cluster - Log name: log name
gcloud
You can read cluster log entries using the gcloud logging read command. The resource arguments must be enclosed in quotes ("..."). The following command uses cluster labels to filter the returned log entries.
gcloud logging read <<'EOF' "resource.type=cloud_dataproc_cluster resource.labels.region=cluster-region resource.labels.cluster_name=cluster-name resource.labels.cluster_uuid=cluster-uuid" EOF
Sample output (partial):
jsonPayload: class: org.apache.hadoop.yarn.server.resourcemanager.ResourceTrackerService filename: hadoop-yarn-resourcemanager-cluster-name-m.log ... logName: projects/project-id/logs/hadoop-yarn-resourcemanager --- jsonPayload: class: org.apache.hadoop.yarn.server.resourcemanager.ResourceTrackerService filename: hadoop-yarn-resourcemanager-component-gateway-cluster-m.log ... logName: projects/project-id/logs/hadoop-yarn-resourcemanager
REST API
You can use the Logging REST API to list log entries (see entries.list).
Permissions
To write logs to Logging, the Dataproc VM service
account must have the logging.logWriter
IAM role. The default Dataproc service account has this role. If you use
a custom service account,
you must assign this role to the service account.
Protecting the logs
By default, logs in Logging are encrypted at rest. You can enable customer-managed encryption keys (CMEK) to encrypt the logs. For more information on CMEK support, see Manage the keys that protect Log Router data and Manage the keys that protect Logging storage data.
What's next
- Explore Google Cloud Observability.