Quando você envia um job do Dataproc, o Dataproc coleta automaticamente a saída do job e a disponibiliza. Isso significa que é possível analisar rapidamente a saída do job sem a necessidade de manter uma conexão com o cluster enquanto os jobs são executados ou de conferir arquivos de registro complexos.
Registros do Spark
Há dois tipos de registros do Spark: registros do driver e do executor.
Os registros do driver do Spark contêm a saída do job. Os registros do executor do Spark contêm a saída do executável
ou do iniciador do job, como uma mensagem spark-submit "Submitted application xxx", e
podem ser úteis para depurar falhas de jobs.
O driver de job do Dataproc, que é diferente do driver do Spark, é um iniciador para muitos tipos de jobs. Ao iniciar jobs do Spark, ele é executado como um
wrapper no executável spark-submit subjacente, que inicia o driver do
Spark. O driver do Spark executa o job no cluster do Dataproc no modo Spark
client ou cluster:
Modo
client: o driver do Spark executa o job no processospark-submite os registros do Spark são enviados para o driver do job do Dataproc.Modo
cluster: o driver do Spark executa o job em um contêiner YARN. Os registros do driver do Spark não estão disponíveis para o driver do job do Dataproc.
Visão geral das propriedades de jobs do Dataproc e do Spark
| Propriedade | Valor | Padrão | Descrição |
|---|---|---|---|
dataproc:dataproc.logging.stackdriver.job.driver.enable |
verdadeiro ou falso | falso | Precisa ser definido no momento da criação do cluster. Quando true, a saída do driver do job está no Logging, associada ao recurso do job. Quando false, a saída do driver do job não está no Logging.Observação: as seguintes configurações de propriedade do cluster também são necessárias para ativar os registros do driver do job no Logging e são definidas por padrão quando um cluster é criado: dataproc:dataproc.logging.stackdriver.enable=true
e dataproc:jobs.file-backed-output.enable=true
|
dataproc:dataproc.logging.stackdriver.job.yarn.container.enable |
verdadeiro ou falso | falso | Precisa ser definido no momento da criação do cluster.
Quando true, os registros do contêiner YARN do job são associados
ao recurso do job. Quando false, os registros do contêiner YARN do job
são associados ao recurso do cluster. |
spark:spark.submit.deployMode |
cliente ou cluster | cliente | Controla o modo client ou cluster do Spark. |
Jobs do Spark enviados usando a API jobs do Dataproc
As tabelas nesta seção listam o efeito de diferentes configurações de propriedades no destino da saída do driver de job do Dataproc quando os jobs são enviados pela API jobs do Dataproc, o que inclui o envio de jobs pelo consoleGoogle Cloud , pela CLI gcloud e pelas bibliotecas de cliente do Cloud.
As propriedades do Dataproc e do Spark listadas podem ser definidas com a flag --properties quando um cluster é criado e se aplicam a todos os jobs do Spark executados no cluster. As propriedades do Spark também podem ser definidas com a flag --properties (sem o prefixo "spark:") quando um job é enviado à API jobs do Dataproc e se aplicam apenas ao job.
Saída do driver do job do Dataproc
As tabelas a seguir listam o efeito de diferentes configurações de propriedade no destino da saída do driver de job do Dataproc.
dataproc: |
Saída |
|---|---|
| false (padrão) |
|
| verdadeiro |
|
Registros do driver do Spark
As tabelas a seguir listam o efeito de diferentes configurações de propriedade no destino dos registros do driver do Spark.
spark: |
dataproc: |
dataproc: |
Saída do driver |
|---|---|---|---|
| cliente | false (padrão) | verdadeiro ou falso |
|
| cliente | verdadeiro | verdadeiro ou falso |
|
| cluster | false (padrão) | falso |
|
| cluster | verdadeiro | verdadeiro |
|
Registros do executor do Spark
As tabelas a seguir listam o efeito de diferentes configurações de propriedade no destino dos registros do executor do Spark.
dataproc: |
Registro do executor |
|---|---|
| false (padrão) | No Logging: yarn-userlogs no recurso de cluster |
| verdadeiro | No Logging dataproc.job.yarn.container no recurso de job |
Jobs do Spark enviados sem usar a API jobs do Dataproc
Esta seção lista o efeito de diferentes configurações de propriedades no destino dos registros de jobs do Spark quando os jobs são enviados sem usar a API jobs do Dataproc, por exemplo, ao enviar um job diretamente em um nó de cluster usando spark-submit ou ao usar um notebook Jupyter ou Zeppelin. Esses jobs não têm IDs nem drivers do Dataproc.
Registros do driver do Spark
As tabelas a seguir listam o efeito de diferentes configurações de propriedades no destino dos registros de driver do Spark para jobs não enviados pela API jobs do Dataproc.
spark: |
Saída do driver |
|---|---|
| cliente |
|
| cluster |
|
Registros do executor do Spark
Quando os jobs do Spark não são enviados pela API jobs do Dataproc, os registros do executor ficam no Logging yarn-userlogs, no recurso do cluster.
Ver a saída do job
É possível acessar a saída do job do Dataproc no console Google Cloud , na CLI gcloud, no Cloud Storage ou no Logging.
Console
Para isso, acesse a seção Jobs do Dataproc do projeto e clique no código do job.
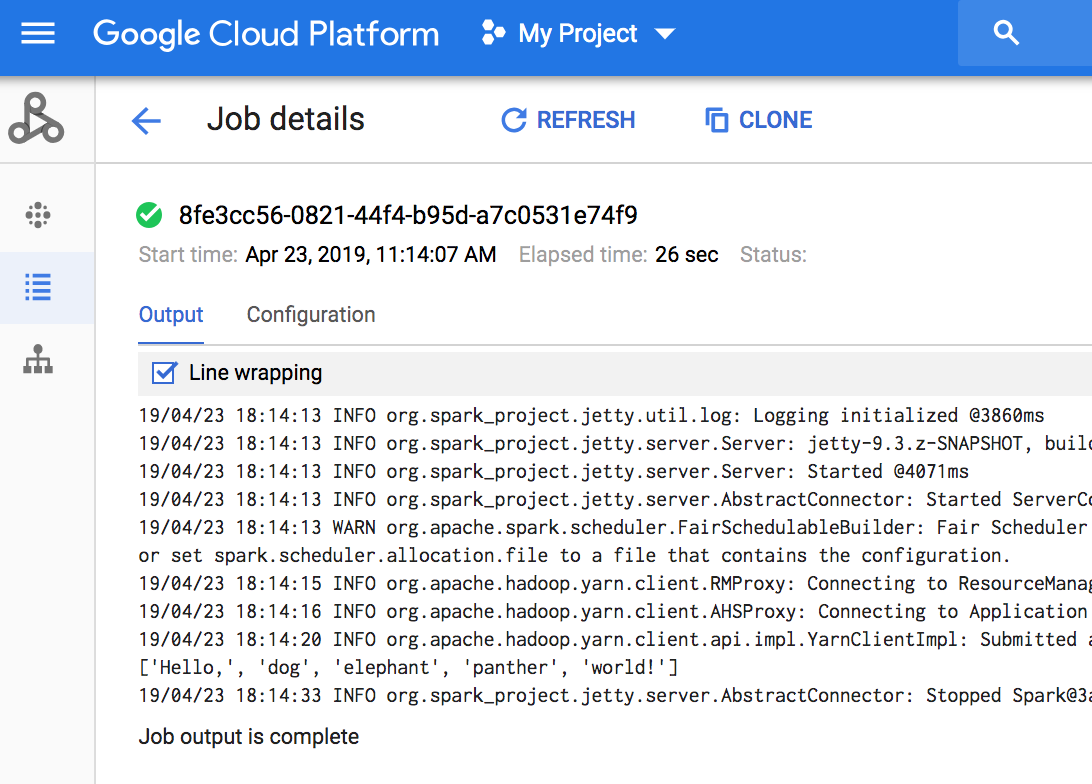
Se o job estiver em execução, a saída será atualizada periodicamente com novo conteúdo.
Comando gcloud
Quando um job é enviado com o comando gcloud dataproc jobs submit, a saída do job é exibida no console. É possível "reingressar" na saída posteriormente, em outro computador ou em uma nova janela, passando o ID do job para o comando gcloud dataproc jobs wait. O código do job é um GUID, como 5c1754a5-34f7-4553-b667-8a1199cb9cab. Aqui está um exemplo:
gcloud dataproc jobs wait 5c1754a5-34f7-4553-b667-8a1199cb9cab \ --project my-project-id --region my-cluster-region
Waiting for job output... ... INFO gcs.GoogleHadoopFileSystemBase: GHFS version: 1.4.2-hadoop2 ... 16:47:45 INFO client.RMProxy: Connecting to ResourceManager at my-test-cluster-m/ ...
Cloud Storage
A saída do job é armazenada no Cloud Storage no bucket de preparação ou no bucket especificado quando você criou o cluster. Um link para a saída do job no Cloud Storage é fornecido no campo Job.driverOutputResourceUri retornado por:
- uma solicitação de API jobs.get.
- um comando gcloud dataproc jobs describe job-id.
$ gcloud dataproc jobs describe spark-pi ... driverOutputResourceUri: gs://dataproc-nnn/jobs/spark-pi/driveroutput ...