사용자가 Dataproc 작업을 제출하면 Dataproc은 자동으로 작업 출력을 수집하여 사용자에게 제공합니다. 따라서 작업 실행 중 클러스터에 대한 연결을 유지하거나 복잡한 로그를 조사할 필요 없이 작업 출력을 빠르게 검토할 수 있습니다.
Spark 로그
Spark 로그에는 Spark 드라이버 로그와 Spark 실행자 로그 등 두 가지 유형이 있습니다.
Spark 드라이버 로그에 작업 출력이 포함됩니다. Spark 실행자 로그는 spark-submit 'Submitted application xxx' 메시지와 같은 작업 실행 파일이나 런처 출력을 포함하며 작업 실패를 디버깅하는 데 유용할 수 있습니다.
Spark 드라이버와 구분되는 Dataproc 작업 드라이버는 여러 작업 유형을 위한 런처입니다. Spark 작업을 실행하면 기본 spark-submit 실행 파일에서 래퍼로 실행되므로 Spark 드라이버가 시작됩니다. Spark 드라이버는 Spark client 또는 cluster 모드의 Dataproc 클러스터에서 작업을 실행합니다.
client모드: Spark 드라이버가spark-submit프로세스에서 작업을 실행하고 Spark 로그를 Dataproc 작업 드라이버로 전송합니다.cluster모드: Spark 드라이버가 YARN 컨테이너에서 작업을 실행합니다. Spark 작업 로그를 Spark 작업 드라이버에 사용할 수 없습니다.
Dataproc 및 Spark 작업 속성 개요
| 속성 | 값 | 기본값 | 설명 |
|---|---|---|---|
dataproc:dataproc.logging.stackdriver.job.driver.enable |
true 또는 false | 거짓 | 클러스터 생성 시 설정해야 합니다. true인 경우 작업 드라이버 출력은 작업 리소스와 연결된 Logging에 있습니다. false면 작업 드라이버 출력은 Logging에 없습니다.참고: Logging에서 작업 드라이버 로그를 사용 설정하려면 다음 클러스터 속성 설정도 필요하며, dataproc:dataproc.logging.stackdriver.enable=true 및 dataproc:jobs.file-backed-output.enable=true 클러스터가 생성될 때 기본적으로 설정됩니다.
|
dataproc:dataproc.logging.stackdriver.job.yarn.container.enable |
true 또는 false | 거짓 | 클러스터 생성 시 설정해야 합니다.
true면 작업 YARN 컨테이너 로그가 작업 리소스와 연결됩니다. false면 작업 YARN 컨테이너 로그가 클러스터 리소스와 연결됩니다. |
spark:spark.submit.deployMode |
클라이언트 또는 클러스터 | 클라이언트 | Spark client 또는 cluster 모드를 제어합니다. |
Dataproc jobs API를 사용하여 제출된 Spark 작업
이 섹션의 표에는 Dataproc jobs 드라이버를 통해 작업을 제출할 때 Dataproc 작업 드라이버 출력의 대상 위치에 대한 여러 가지 속성 설정이 미치는 영향이 나와 있습니다. 여기에는Google Cloud 콘솔, gcloud CLI, Cloud 클라이언트 라이브러리를 사용한 작업 제출이 포함됩니다.
나열된 Dataproc 및 Spark 속성은 클러스터를 만들 때 --properties 플래그로 설정할 수 있으며 클러스터에서 실행되는 모든 Spark 작업에 적용됩니다. Spark 속성은 작업이 Dataproc jobs API에 제출될 때 --properties 플래그로 설정할 수 있으며('spark' 프리픽스 없이) 해당 작업에만 적용됩니다.
Dataproc 작업 드라이버 출력
다음 표에는 다양한 속성 설정이 Dataproc 작업 드라이버 출력의 대상에 미치는 영향이 나와 있습니다.
dataproc: |
출력 |
|---|---|
| false(기본값) |
|
| 참 |
|
Spark 드라이버 로그
다음 표에는 다양한 속성 설정이 Spark 드라이버 로그의 대상에 미치는 영향이 나와 있습니다.
spark: |
dataproc: |
dataproc: |
드라이버 출력 |
|---|---|---|---|
| 클라이언트 | false(기본값) | true 또는 false |
|
| 클라이언트 | 참 | true 또는 false |
|
| 클러스터 | false(기본값) | 거짓 |
|
| 클러스터 | 참 | 참 |
|
Spark 실행자 로그
다음 표에는 다양한 속성 설정이 Spark 실행자 로그의 대상에 미치는 영향이 나와 있습니다.
dataproc: |
실행자 로그 |
|---|---|
| false(기본값) | Logging에서: 클러스터 리소스 아래에 있는 yarn-userlogs |
| 참 | Logging에서 작업 리소스 아래의 dataproc.job.yarn.container |
Dataproc jobs API를 사용하지 않고 제출된 Spark 작업
이 섹션에는 작업이 Dataproc jobs API를 사용하지 않고 제출될 때(예: spark-submit을 사용하여 클러스터 노드에서 직접 작업을 제출하거나 Jupyter 또는 Zeppelin 노트북을 사용하는 경우) 다양한 속성 설정이 Spark 작업 로그 대상에 미치는 영향이 나와 있습니다. 이러한 작업에는 Dataproc 작업 ID나 드라이버가 없습니다.
Spark 드라이버 로그
다음 표에는 다양한 속성 설정이 Dataproc jobs API를 통해 제출되지 않은 작업의 Spark 드라이버 로그 대상에 미치는 영향이 나와 있습니다.
spark: |
드라이버 출력 |
|---|---|
| 클라이언트 |
|
| 클러스터 |
|
Spark 실행자 로그
Spark 작업이 Dataproc jobs API를 통해 제출되지 않으면 실행자 로그는 클러스터 리소스 아래의 Logging yarn-userlogs에 위치합니다.
작업 출력 보기
Google Cloud 콘솔, gcloud CLI, Cloud Storage 또는 Logging에서 Dataproc 작업 출력에 액세스할 수 있습니다.
콘솔
작업 드라이버 출력을 보려면 프로젝트의 Dataproc 작업 섹션으로 이동한 후 작업 ID를 클릭하여 작업 출력을 확인합니다.
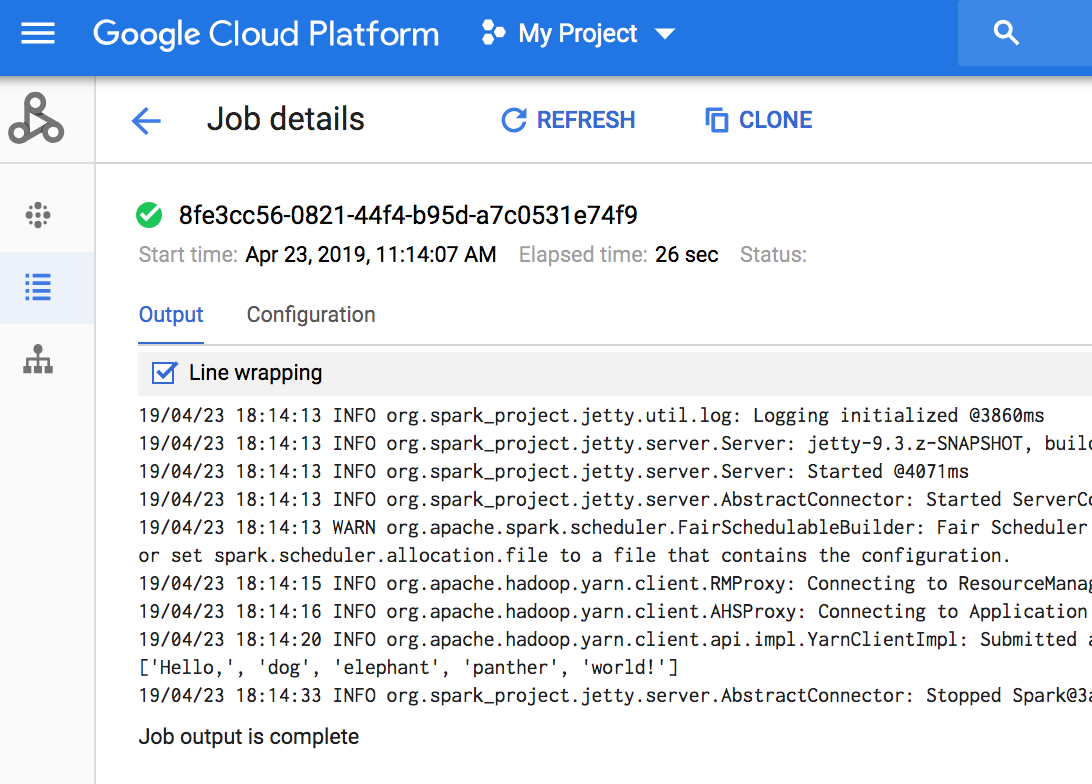
작업이 실행 중이면 새로운 콘텐츠를 사용하여 작업 출력이 주기적으로 새로 고쳐집니다.
gcloud 명령어
gcloud dataproc jobs submit 명령어로 작업을 제출하면 작업 출력이 콘솔에 표시됩니다. 작업 ID를 gcloud dataproc jobs wait 명령어로 전달하여 이후에 다른 컴퓨터나 새 창에서 출력을 '다시 결합'할 수 있습니다. 작업 ID는 5c1754a5-34f7-4553-b667-8a1199cb9cab와 같은 GUID입니다. 예를 들면 다음과 같습니다.
gcloud dataproc jobs wait 5c1754a5-34f7-4553-b667-8a1199cb9cab \ --project my-project-id --region my-cluster-region
Waiting for job output... ... INFO gcs.GoogleHadoopFileSystemBase: GHFS version: 1.4.2-hadoop2 ... 16:47:45 INFO client.RMProxy: Connecting to ResourceManager at my-test-cluster-m/ ...
Cloud Storage
작업 출력은 Cloud Storage에서 스테이징 버킷 또는 클러스터를 만들 때 지정된 버킷에 저장됩니다. Cloud Storage에서 작업 출력에 대한 링크는 다음으로 반환되는 Job.driverOutputResourceUri 필드에 제공됩니다.
- jobs.get API 요청
- gcloud dataproc jobs describe job-id 명령어
$ gcloud dataproc jobs describe spark-pi ... driverOutputResourceUri: gs://dataproc-nnn/jobs/spark-pi/driveroutput ...