En esta página se proporciona información para ayudarle a monitorizar y depurar trabajos de Dataproc, así como a comprender los mensajes de error de los trabajos de Dataproc.
Monitorización y depuración de trabajos
Usa la CLI de Google Cloud, la API REST de Dataproc y la Google Cloud consola para analizar y depurar trabajos de Dataproc.
CLI de gcloud
Para examinar el estado de un trabajo en curso, sigue estos pasos:
gcloud dataproc jobs describe job-id \ --region=region
Para ver la salida del controlador de tareas, consulta Ver la salida de una tarea.
API REST
Llama a jobs.get para examinar los campos JobStatus.State, JobStatus.Substate, JobStatus.details y YarnApplication de una tarea.
Consola
Para ver la salida del controlador de tareas, consulta Ver la salida de una tarea.
Para ver el registro del agente de Dataproc en Logging, selecciona Clúster de Dataproc > Nombre del clúster > UUID del clúster en el selector de clústeres del Explorador de registros.
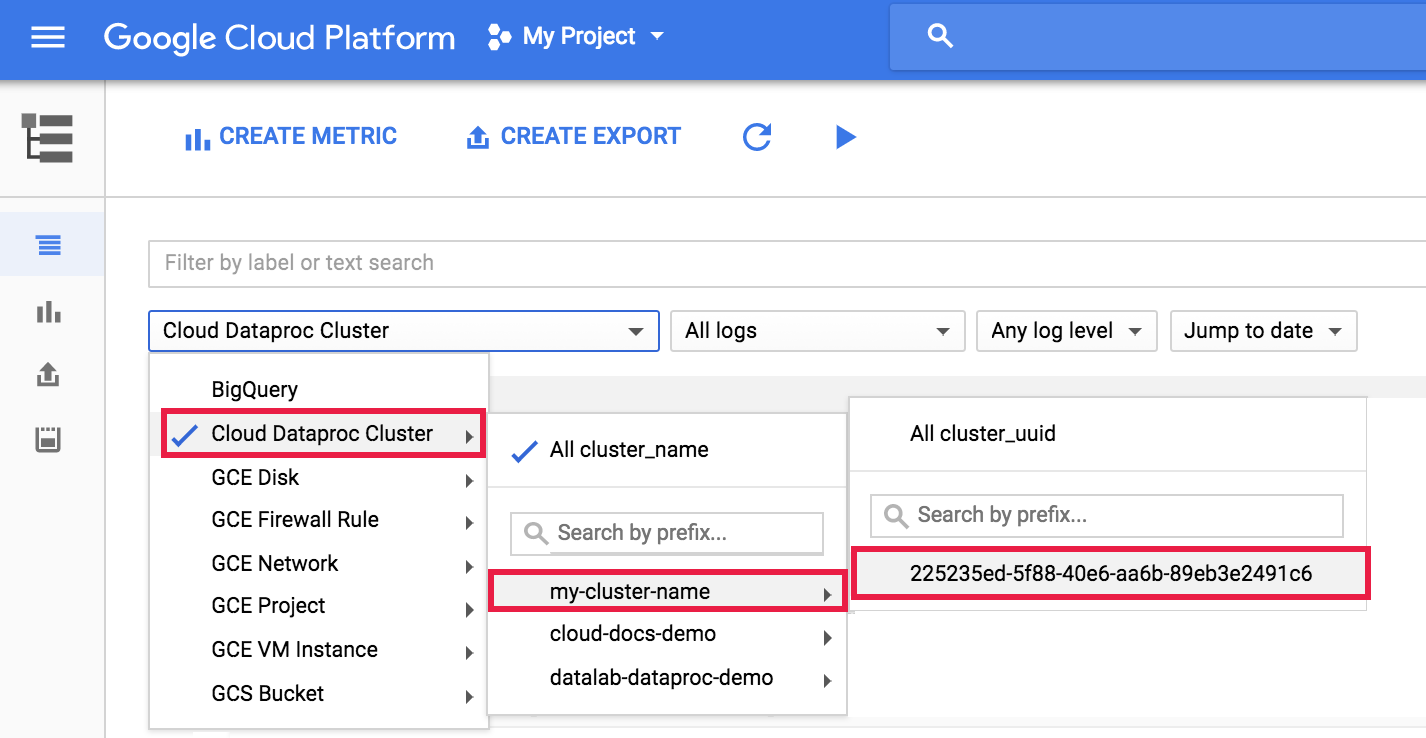
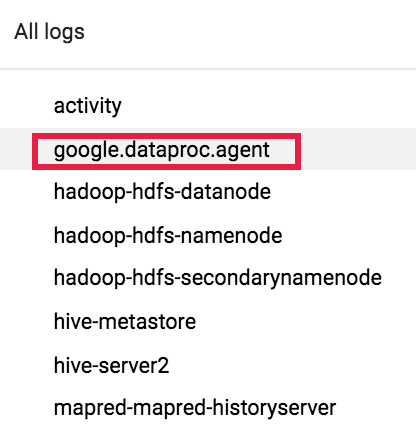
A continuación, usa el selector de registros para seleccionar los registros google.dataproc.agent.
Ver registros de tareas en Logging
Si un trabajo falla, puedes acceder a los registros de trabajo en Logging.
Determinar quién ha enviado una tarea
Si buscas los detalles de una tarea, verás quién la ha enviado en el campo submittedBy. Por ejemplo, en este resultado de la tarea se muestra que user@domain ha enviado la tarea de ejemplo a un clúster.
... placement: clusterName: cluster-name clusterUuid: cluster-uuid reference: jobId: job-uuid projectId: project status: state: DONE stateStartTime: '2018-11-01T00:53:37.599Z' statusHistory: - state: PENDING stateStartTime: '2018-11-01T00:33:41.387Z' - state: SETUP_DONE stateStartTime: '2018-11-01T00:33:41.765Z' - details: Agent reported job success state: RUNNING stateStartTime: '2018-11-01T00:33:42.146Z' submittedBy: user@domain
Mensajes de error
No se ha adquirido la tarea
Esto indica que el agente de Dataproc en el nodo maestro no ha podido adquirir la tarea del plano de control. Esto suele ocurrir debido a problemas de falta de memoria (OOM) o de red. Si el trabajo se ejecutó correctamente anteriormente y no has cambiado la configuración de la red, es muy probable que se deba a un error de falta de memoria. A menudo, este error se produce cuando se envían muchos trabajos que se ejecutan simultáneamente o trabajos cuyos controladores consumen mucha memoria (por ejemplo, trabajos que cargan grandes conjuntos de datos en la memoria).
No se ha encontrado ningún agente activo en los nodos maestros
Esto indica que el agente de Dataproc del nodo maestro no está activo y no puede aceptar nuevos trabajos. Esto suele ocurrir debido a problemas de falta de memoria (OOM) o de red, o si la VM del nodo maestro no está en buen estado. Si el trabajo se ejecutó correctamente anteriormente y no has cambiado la configuración de la red, lo más probable es que se deba a un error de falta de memoria, que suele producirse cuando se envían muchos trabajos que se ejecutan simultáneamente o trabajos cuyos controladores consumen mucha memoria (trabajos que cargan conjuntos de datos grandes en la memoria).
Para intentar solucionar el problema, puedes probar las siguientes acciones:
- Reinicia el trabajo.
- Conéctate mediante SSH al nodo maestro del clúster y, a continuación, determina qué trabajo u otro recurso está usando más memoria.
Si no puedes iniciar sesión en el nodo principal, puedes consultar los registros del puerto serie (consola).

Genera un paquete de diagnóstico, que contiene el syslog y otros datos.
No se ha encontrado la tarea
Este error indica que el clúster se ha eliminado mientras se ejecutaba un trabajo. Puedes realizar las siguientes acciones para identificar la entidad de seguridad que ha realizado la eliminación y confirmar que se ha producido cuando se estaba ejecutando un trabajo:
Consulta los registros de auditoría de Dataproc para identificar el principal que ha realizado la operación de eliminación.
Usa Logging o la CLI de gcloud para comprobar que el último estado conocido de la aplicación YARN era RUNNING:
- Usa el siguiente filtro en Logging:
resource.type="cloud_dataproc_cluster" resource.labels.cluster_name="CLUSTER_NAME" resource.labels.cluster_uuid="CLUSTER_UUID" "YARN_APPLICATION_ID State change from"
- Ejecuta
gcloud dataproc jobs describe job-id --region=REGIONy, a continuación, compruebayarnApplications: > STATEen el resultado.
Si el principal que ha eliminado el clúster es la cuenta de servicio del agente de servicio de Dataproc, comprueba si el clúster se ha configurado con una duración de eliminación automática inferior a la duración del trabajo.
Para evitar errores Task not found, usa la automatización para asegurarte de que los clústeres no se eliminen antes de que se completen todos los trabajos en ejecución.
No queda espacio en el dispositivo
Dataproc escribe datos de HDFS y de borrador en el disco. Este mensaje de error indica que el clúster se ha creado con espacio en disco insuficiente. Para analizar y evitar este error, haz lo siguiente:
Consulta el tamaño del disco principal del clúster en la pestaña Configuración de la página Detalles del clúster de la consola de Google Cloud . El tamaño mínimo recomendado del disco es
1000 GBpara los clústeres que usan el tipo de máquinan1-standard-4y2 TBpara los clústeres que usan el tipo de máquinan1-standard-32.Si el tamaño del disco del clúster es inferior al recomendado, vuelva a crear el clúster con al menos el tamaño de disco recomendado.
Si el tamaño del disco es el recomendado o superior, usa SSH para conectarte a la VM principal del clúster y, a continuación, ejecuta
df -hen la VM principal para comprobar la utilización del disco y determinar si necesitas más espacio.