이 페이지에서는 Dataproc 작업을 모니터링 및 디버깅하고 Dataproc 작업 오류 메시지를 이해하는 데 도움이 되는 정보를 제공합니다.
작업 모니터링 및 디버깅
Google Cloud CLI, Dataproc REST API, Google Cloud 콘솔을 사용하여 Dataproc 작업을 분석하고 디버깅합니다.
gcloud CLI
실행 중인 작업의 상태를 검토하려면 다음 명령어를 사용하세요.
gcloud dataproc jobs describe job-id \ --region=region
작업 드라이버 출력을 보려면 작업 출력 보기를 참조하세요.
REST API
jobs.get을 호출하여 작업의 JobStatus.State, JobStatus.Substate, JobStatus.details, YarnApplication 필드를 검토합니다.
Console
작업 드라이버 출력을 보려면 작업 출력 보기를 참조하세요.
Logging에서 dataproc 에이전트 로그를 보려면 로그 탐색기 클러스터 선택기에서 Dataproc 클러스터→클러스터 이름→클러스터 UUID를 선택합니다.
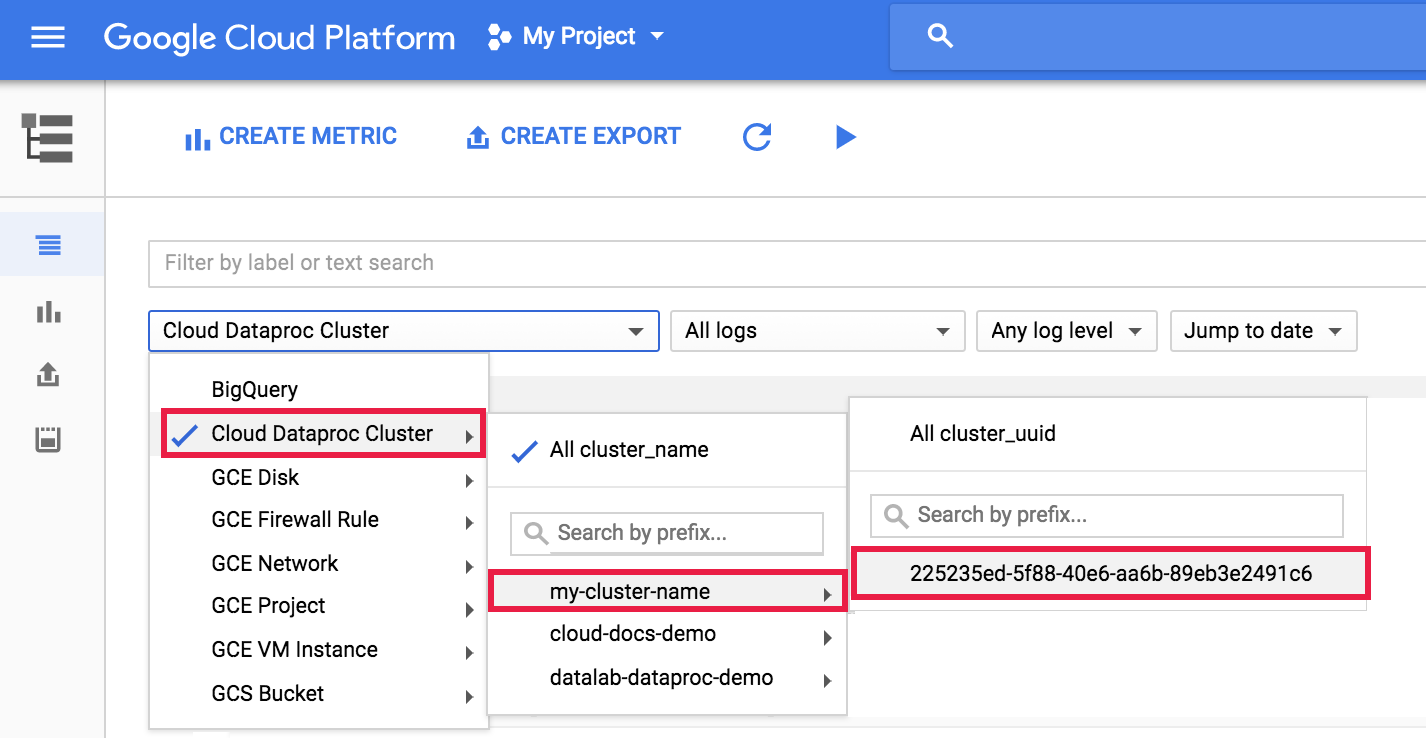
그런 다음 로그 선택기를 사용하여 google.dataproc.agent 로그를 선택합니다.
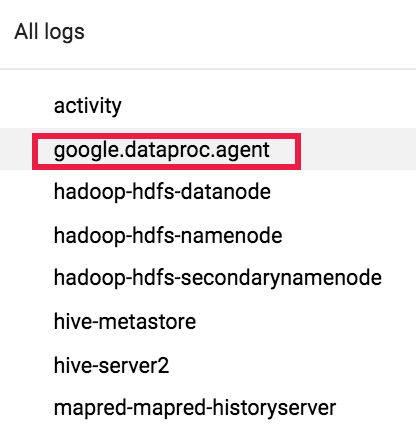
Logging에서 작업 로그 보기
작업이 실패하면 Logging에서 작업 로그에 액세스할 수 있습니다.
작업을 제출한 사람 확인
작업 세부정보를 조회하면 submittedBy 필드에 해당 작업을 제출한 사람이 표시됩니다. 예를 들어 이 작업 출력에는 예시 작업을 클러스터에 제출한 user@domain가 표시됩니다.
... placement: clusterName: cluster-name clusterUuid: cluster-uuid reference: jobId: job-uuid projectId: project status: state: DONE stateStartTime: '2018-11-01T00:53:37.599Z' statusHistory: - state: PENDING stateStartTime: '2018-11-01T00:33:41.387Z' - state: SETUP_DONE stateStartTime: '2018-11-01T00:33:41.765Z' - details: Agent reported job success state: RUNNING stateStartTime: '2018-11-01T00:33:42.146Z' submittedBy: user@domain
오류 메시지
태스크를 획득하지 못함
마스터 노드의 Dataproc 에이전트가 제어 영역에서 태스크를 획득할 수 없음을 나타냅니다. 이 문제는 메모리 부족(OOM) 또는 네트워크 문제로 인해 자주 발생합니다. 이전에 작업이 성공적으로 실행되었고 네트워크 구성 설정을 변경하지 않았으면 OOM이 가장 가능성이 높은 원인이고, 많은 동시 실행 작업 또는 드라이버가 상당한 양의 메모리를 소비하는 작업 (예: 대량의 데이터 세트를 메모리에 로드하는 작업)의 여러 동시 실행을 제출한 결과일 수 있습니다.
마스터 노드에서 활성 상태인 에이전트를 찾을 수 없음
이는 마스터 노드의 Dataproc 에이전트가 활성 상태가 아니고 새 작업을 수락할 수 없음을 나타냅니다. 이 문제는 메모리 부족 (OOM) 또는 네트워크 문제로 인해 또는 마스터 노드 VM이 비정상인 경우에 자주 발생합니다. 이전에 작업이 성공적으로 실행되었고 네트워크 구성 설정을 변경하지 않았으면 OOM이 가장 가능성이 높은 원인이고, 많은 동시 실행 작업 또는 드라이버가 상당한 양의 메모리를 소비하는 작업 (대량의 데이터 세트를 메모리에 로드하는 작업)의 여러 동시 실행을 제출한 결과일 수 있습니다. 이 문제는 Dataproc 클러스터를 다시 시작(중지 후 시작)하거나 나중에 작업 제출을 다시 시도하여 해결할 수 있습니다. 참고: 클러스터를 중지하면 모든 실행 중인 작업이 실패합니다.
작업이 없습니다.
이 오류는 작업이 실행되는 동안 클러스터가 삭제되었음을 나타냅니다. 다음 작업을 실행하여 삭제를 실행한 사용자를 식별하고 작업이 실행 중일 때 클러스터 삭제가 발생했는지 확인할 수 있습니다.
Dataproc 감사 로그를 확인하여 삭제 작업을 실행한 사용자를 식별합니다.
Logging 또는 gcloud CLI를 사용하여 YARN 애플리케이션의 마지막으로 알려진 상태가 RUNNING인지 확인합니다.
- Logging에서 다음 필터를 사용합니다.
resource.type="cloud_dataproc_cluster" resource.labels.cluster_name="CLUSTER_NAME" resource.labels.cluster_uuid="CLUSTER_UUID" "YARN_APPLICATION_ID State change from"
gcloud dataproc jobs describe job-id --region=REGION를 실행한 후 출력에서yarnApplications: > STATE를 확인합니다.
Task not found 오류를 방지하려면 자동화를 사용하여 모든 실행 중인 작업이 완료되기 전에 클러스터가 삭제되지 않도록 합니다.