Descripción general
El servidor de historial persistente (PHS) de Dataproc proporciona interfaces web para ver el historial de trabajos de los trabajos ejecutados en clústeres de Dataproc activos o borrados. Está disponible en la versión 1.5 de la imagen de Dataproc y versiones posteriores, y se ejecuta en un clúster de Dataproc de nodo único. Proporciona interfaces web a los siguientes archivos y datos:
Archivos del historial de trabajos de MapReduce y Spark
Archivos de historial de trabajos de Flink (consulta el componente Flink opcional de Dataproc para crear un clúster de Dataproc que ejecute trabajos de Flink)
Archivos de datos de cronogramas de aplicaciones creados por el servicio de cronogramas de YARN v2 y almacenados en una instancia de Bigtable.
Registros de agregación de YARN
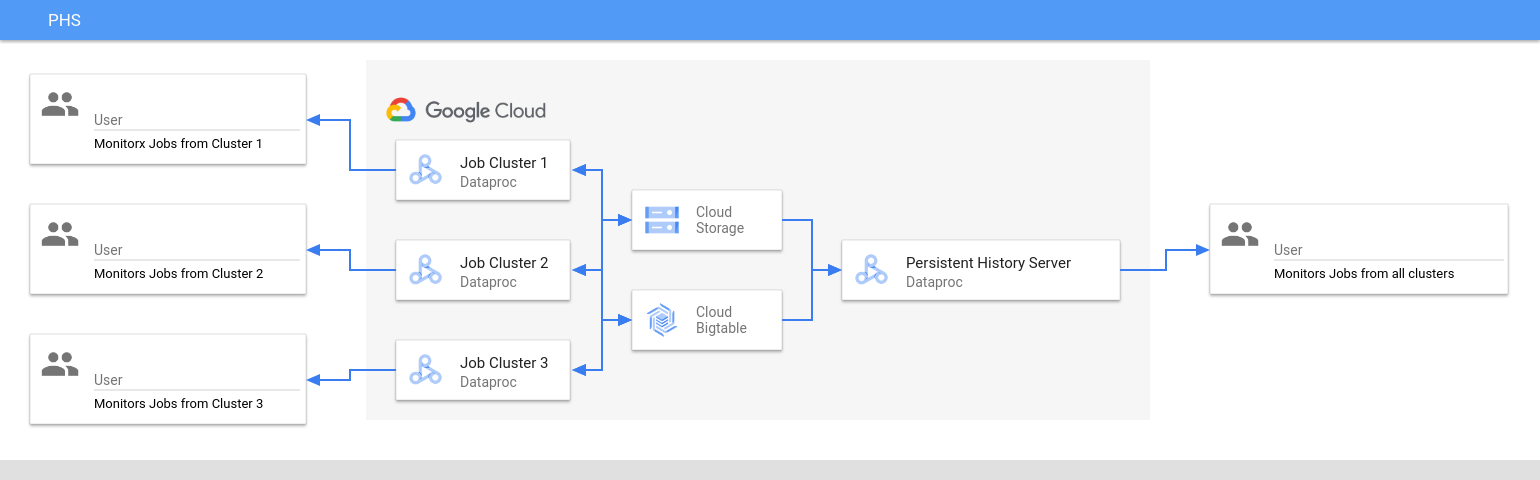
El servidor de historial persistente accede a los archivos del historial de trabajos de Spark y MapReduce, a los archivos del historial de trabajos de Flink y a los archivos de registro de YARN que se escriben en Cloud Storage durante la vida útil de los clústeres de trabajo de Dataproc, y los muestra.
Limitaciones
La versión de la imagen del clúster de PHS y la versión de la imagen de los clústeres de trabajos de Dataproc deben coincidir. Por ejemplo, puedes usar un clúster de PHS de la versión de imagen 2.0 de Dataproc para ver los archivos de historial de trabajos de los trabajos que se ejecutaron en clústeres de trabajo de la versión de imagen 2.0 de Dataproc que se encontraban en el proyecto donde se encuentra el clúster de PHS.
Un clúster de PHS no admite Kerberos ni autenticación personal.
Crea un clúster de PHS de Dataproc
Puedes ejecutar el siguiente comando gcloud dataproc clusters create en una terminal local o en Cloud Shell con las siguientes marcas y propiedades del clúster para crear un clúster de un solo nodo del servidor de historial persistente de Dataproc.
gcloud dataproc clusters create CLUSTER_NAME \ --project=PROJECT \ --region=REGION \ --single-node \ --enable-component-gateway \ --optional-components=COMPONENT \ --properties=PROPERTIES
- CLUSTER_NAME: Especifica el nombre del clúster de PHS.
- PROJECT: Especifica el proyecto que se asociará con el clúster de PHS. Este proyecto debe ser el mismo que el asociado con el clúster que ejecuta tus trabajos (consulta Cómo crear un clúster de trabajos de Dataproc).
- REGION: Especifica una región de Compute Engine en la que se ubicará el clúster de PHS.
--single-node: Un clúster de PHS es un clúster de un solo nodo de Dataproc.--enable-component-gateway: Esta marca habilita las interfaces web de la puerta de enlace de componentes en el clúster de PHS.- COMPONENT: Usa esta marca para instalar uno o más
componentes opcionales
en el clúster. Debes especificar el componente opcional
FLINKpara ejecutar el servicio web de HistoryServer de Flink en el clúster de PHS y ver los archivos del historial de trabajos de Flink. - PROPERTIES. Especifica una o más propiedades del clúster.
De forma opcional, agrega la marca --image-version para especificar la versión de imagen del clúster de PHS. La versión de la imagen de PHS debe coincidir con la versión de la imagen de los clústeres de trabajo de Dataproc. Consulta Limitaciones.
Notas:
- En los ejemplos de valores de propiedad de esta sección, se usa un carácter comodín "*" para permitir que el PHS coincida con varios directorios en el bucket especificado en el que escriben diferentes clústeres de trabajo (pero consulta Consideraciones de eficiencia de los comodines).
- En los siguientes ejemplos, se muestran marcas
--propertiesseparadas para facilitar la lectura. La práctica recomendada cuando se usagcloud dataproc clusters createpara crear un clúster de Dataproc en Compute Engine es usar una marca--propertiespara especificar una lista de propiedades separadas por comas (consulta formato de las propiedades del clúster).
Propiedades:
yarn:yarn.nodemanager.remote-app-log-dir=gs://bucket-name/*/yarn-logs: Agrega esta propiedad para especificar la ubicación de Cloud Storage en la que la PHS accederá a los registros de YARN escritos por los clústeres de trabajo.spark:spark.history.fs.logDirectory=gs://bucket-name/*/spark-job-history: Agrega esta propiedad para habilitar el historial de trabajos de Spark persistentes. Esta propiedad especifica la ubicación en la que la PHS accederá a los registros del historial de trabajos de Spark escritos por los clústeres de trabajo.En los clústeres de Dataproc 2.0 y versiones posteriores, también se deben configurar las siguientes dos propiedades para habilitar los registros de historial de Spark de PHS (consulta Opciones de configuración del servidor de historial de Spark). El valor
spark.history.custom.executor.log.urles un valor literal que contiene {{PLACEHOLDERS}} para las variables que establecerá el servidor de historial persistente. Los usuarios no establecen estas variables; pasa el valor de la propiedad como se muestra.--properties=spark:spark.history.custom.executor.log.url.applyIncompleteApplication=false
--properties=spark:spark.history.custom.executor.log.url={{YARN_LOG_SERVER_URL}}/{{NM_HOST}}:{{NM_PORT}}/{{CONTAINER_ID}}/{{CONTAINER_ID}}/{{USER}}/{{FILE_NAME}}mapred:mapreduce.jobhistory.read-only.dir-pattern=gs://bucket-name/*/mapreduce-job-history/done: Agrega esta propiedad para habilitar el historial de trabajos persistentes de MapReduce. Esta propiedad especifica la ubicación de Cloud Storage en la que la PHS accederá a los registros del historial de trabajos de MapReduce escritos por los clústeres de trabajo.dataproc:yarn.atsv2.bigtable.instance=projects/project-id/instance_id/bigtable-instance-id: Después de configurar el servicio de cronograma de Yarn v2, agrega esta propiedad para usar el clúster de PHS y ver los datos de cronograma en las interfaces web de YARN Application Timeline Service v2 y Tez (consulta Interfaces web de Component Gateway).flink:historyserver.archive.fs.dir=gs://bucket-name/*/flink-job-history/completed-jobs: Usa esta propiedad para configurar elHistoryServerde Flink para supervisar una lista de directorios separados por comas.
Ejemplos de propiedades:
--properties=spark:spark.history.fs.logDirectory=gs://bucket-name/*/spark-job-history
--properties=mapred:mapreduce.jobhistory.read-only.dir-pattern=gs://bucket-name/*/mapreduce-job-history/done
--properties=flink:flink.historyserver.archive.fs.dir=gs://bucket-name/*/flink-job-history/completed-jobs
Crea un clúster de trabajo de Dataproc
Puedes ejecutar el siguiente comando en una terminal local o en Cloud Shell para crear un clúster de trabajos de Dataproc que ejecute trabajos y escriba archivos de historial de trabajos en un servidor de historial persistente (PHS).
gcloud dataproc clusters create CLUSTER_NAME \ --project=PROJECT \ --region=REGION \ --optional-components=COMPONENT \ --enable-component-gateway \ --properties=PROPERTIES \ other args ...
- CLUSTER_NAME: Especifica el nombre del clúster de trabajo.
- PROJECT: Especifica el proyecto asociado con el clúster de trabajo.
- REGION: Especifica la región de Compute Engine en la que se ubicará el clúster de trabajo.
--enable-component-gateway: Esta marca habilita las interfaces web de la puerta de enlace de componentes en el clúster de trabajo.- COMPONENT: Usa esta marca para instalar uno o más
componentes opcionales
en el clúster. Especifica el componente opcional
FLINKpara ejecutar trabajos de Flink en el clúster. PROPERTIES: Agrega una o más de las siguientes propiedades del clúster para establecer ubicaciones de Cloud Storage no predeterminadas relacionadas con la PHS y otras propiedades del clúster de trabajo.
Notas:
- En los ejemplos de valores de propiedad de esta sección, se usa un carácter comodín "*" para permitir que el PHS coincida con varios directorios en el bucket especificado que escriben los diferentes clústeres de trabajo (pero consulta Consideraciones de eficiencia de los comodines).
- En los siguientes ejemplos, se muestran marcas
--propertiesseparadas para facilitar la lectura. La práctica recomendada cuando se usagcloud dataproc clusters createpara crear un clúster de Dataproc en Compute Engine es usar una marca--propertiespara especificar una lista de propiedades separadas por comas (consulta formato de las propiedades del clúster).
Propiedades:
yarn:yarn.nodemanager.remote-app-log-dir: De forma predeterminada, los registros YARN agregados están habilitados en los clústeres de trabajos de Dataproc y se escriben en el bucket temporal del clúster. Agrega esta propiedad para especificar una ubicación de Cloud Storage diferente en la que el clúster escribirá registros de agregación para que el servidor de historial persistente pueda acceder a ellos.--properties=yarn:yarn.nodemanager.remote-app-log-dir=gs://bucket-name/directory-name/yarn-logs
spark:spark.history.fs.logDirectoryyspark:spark.eventLog.dir: De forma predeterminada, los archivos del historial de trabajos de Spark se guardan en el clústertemp bucketen el directorio/spark-job-history. Puedes agregar estas propiedades para especificar distintas ubicaciones de Cloud Storage para estos archivos. Si se usan ambas propiedades, deben apuntar a directorios del mismo bucket.--properties=spark:spark.history.fs.logDirectory=gs://bucket-name/directory-name/spark-job-history
--properties=spark:spark.eventLog.dir=gs://bucket-name/directory-name/spark-job-history
mapred:mapreduce.jobhistory.done-dirymapred:mapreduce.jobhistory.intermediate-done-dir: De forma predeterminada, los archivos del historial de trabajos de MapReduce se guardan en el clústertemp bucketen los directorios/mapreduce-job-history/doney/mapreduce-job-history/intermediate-done. La ubicaciónmapreduce.jobhistory.intermediate-done-dirintermedia es almacenamiento temporal. Los archivos intermedios se mueven a la ubicaciónmapreduce.jobhistory.done-dircuando se completa el trabajo de MapReduce. Puedes agregar estas propiedades para especificar diferentes ubicaciones de Cloud Storage para estos archivos. Si se usan ambas propiedades, deben apuntar a directorios del mismo bucket.--properties=mapred:mapreduce.jobhistory.done-dir=gs://bucket-name/directory-name/mapreduce-job-history/done
--properties=mapred:mapreduce.jobhistory.intermediate-done-dir=gs://bucket-name/directory-name/mapreduce-job-history/intermediate-done
spark:spark.history.fs.gs.outputstream.typeyspark:spark.history.fs.gs.outputstream.sync.min.interval.ms: Agrega estas propiedades del conector de Cloud Storage para cambiar el comportamiento predeterminado de la forma en que el clúster de trabajo envía datos a Cloud Storage. Elspark:spark.history.fs.gs.outputstream.typepredeterminado esBASIC, que envía datos a Cloud Storage después de que se completa la tarea. Puedes cambiar este parámetro de configuración aFLUSHABLE_COMPOSITEpara cambiar el comportamiento de limpieza y copiar datos a Cloud Storage a intervalos regulares mientras se ejecuta el trabajo.--properties=spark:spark.history.fs.gs.outputstream.type=FLUSHABLE_COMPOSITE
spark:spark.history.fs.gs.outputstream.sync.min.interval.mspredeterminado, que controla la frecuencia con la que se transfieren los datos a Cloud Storage, es5000msy se puede cambiar a un intervalo de tiempomsdiferente:--properties=spark:spark.history.fs.gs.outputstream.sync.min.interval.ms=intervalms
dataproc:yarn.atsv2.bigtable.instance: Después de configurar el servicio de cronograma de Yarn v2, agrega esta propiedad para escribir datos de cronograma de YARN en la instancia de Bigtable especificada para verlos en el clúster de PHS Servicio de cronograma de aplicaciones de YARN v2 y las interfaces web de Tez. Nota: La creación del clúster fallará si no existe la instancia de Bigtable.--properties=dataproc:yarn.atsv2.bigtable.instance=projects/project-id/instance_id/bigtable-instance-id
flink:jobhistory.archive.fs.dir: El administrador de trabajos de Flink archiva trabajos de Flink completados subiendo información de trabajos archivados a un directorio del sistema de archivos. Usa esta propiedad para establecer el directorio de almacenamiento enflink-conf.yaml.--properties=flink:jobmanager.archive.fs.dir=gs://bucket-name/job-cluster-1/flink-job-history/completed-jobs
Usa PHS con cargas de trabajo por lotes de Spark
Para usar el servidor de historial persistente con Dataproc Serverless para cargas de trabajo por lotes de Spark, haz lo siguiente:
Selecciona o especifica el clúster de PHS cuando envíes una carga de trabajo por lotes de Spark.
Usa PHS con Dataproc en Google Kubernetes Engine
Para usar el servidor de historial persistente con Dataproc en GKE, haz lo siguiente:
Selecciona o especifica el clúster de PHS cuando crees un clúster virtual de Dataproc en GKE.
Interfaces web de la puerta de enlace de componentes
En la consola de Google Cloud, en la página Clústeres de Dataproc, haz clic en el nombre del clúster de PHS para abrir la página Detalles del clúster. En la pestaña Interfaces web, selecciona los vínculos de la puerta de enlace de componentes para abrir las interfaces web que se ejecutan en el clúster de PHS.
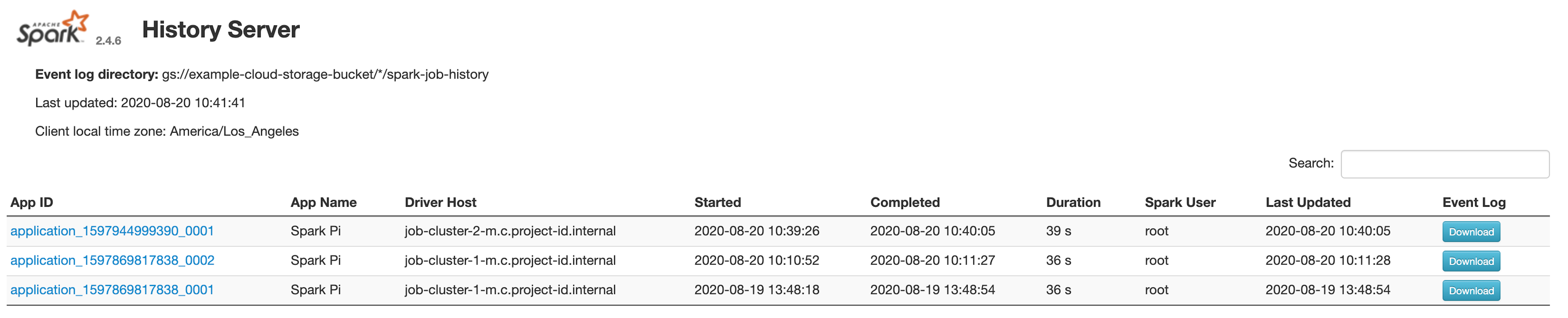
Interfaz web del servidor de historial de Spark
En la siguiente captura de pantalla, se muestra la interfaz web del servidor de historial de Spark, que muestra los vínculos a los trabajos de Spark que se ejecutan en job-cluster-1 y job-cluster-2 después de configurar spark.history.fs.logDirectory y spark:spark.eventLog.dir de los clústeres de trabajo y las ubicaciones de spark.history.fs.logDirectory del clúster de PHS de la siguiente manera:
| job-cluster-1 | gs://example-cloud-storage-bucket/job-cluster-1/spark-job-history |
| job-cluster-2 | gs://example-cloud-storage-bucket/job-cluster-2/spark-job-history |
| phs-cluster | gs://example-cloud-storage-bucket/*/spark-job-history |
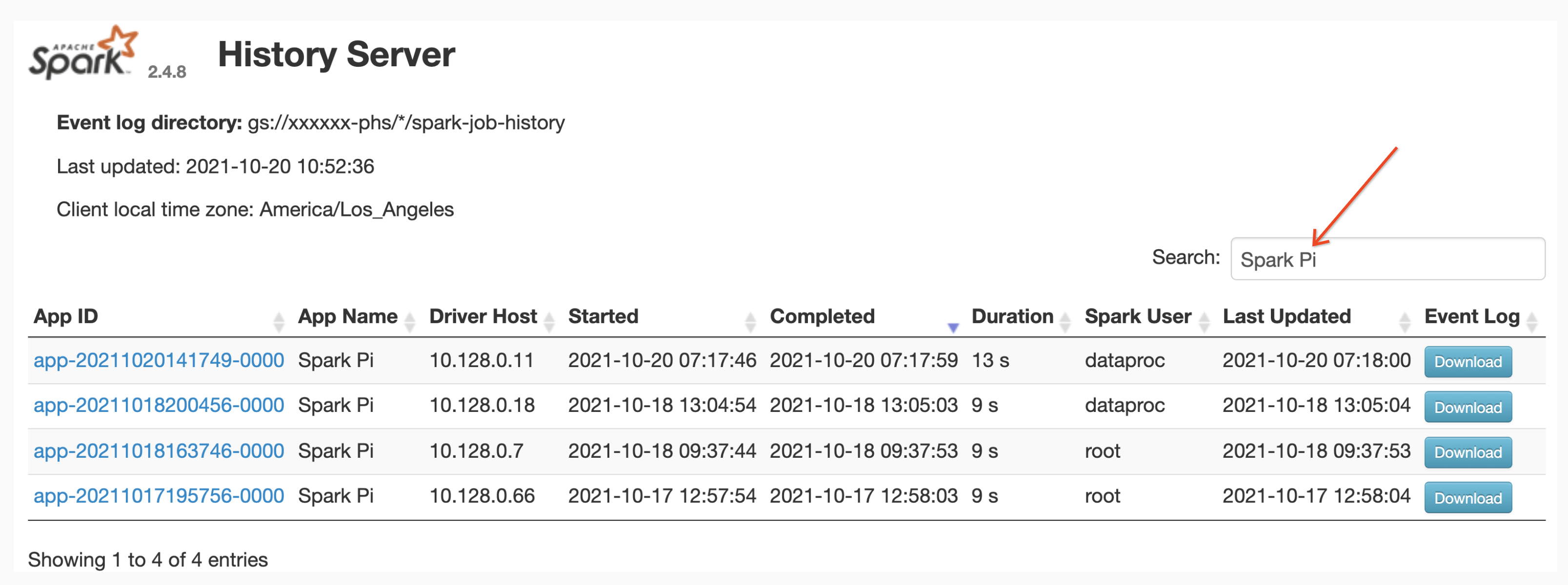
Búsqueda del nombre de la aplicación
Puedes ver una lista de trabajos por nombre de la app en la interfaz web del servidor de historial de Spark si ingresas un nombre de app en el cuadro de búsqueda. El nombre de la app se puede configurar de una de las siguientes formas (enumeradas por prioridad):
- Configurar dentro del código de la aplicación cuando se crea el contexto de Spark
- Se establece con la propiedad spark.app.name cuando se envía el trabajo
- Configurar por Dataproc para el nombre completo del recurso de REST para el trabajo (
projects/project-id/regions/region/jobs/job-id)
Los usuarios pueden ingresar un término de nombre de app o recurso en el cuadro Búsqueda para encontrar y enumerar trabajos.
Registros de eventos
La interfaz web del servidor de historial de Spark proporciona un botón Registro de eventos en el que puedes hacer clic para descargar los registros de eventos de Spark. Estos registros son útiles para examinar el ciclo de vida de la aplicación de Spark.
Trabajos de Spark
Las aplicaciones de Spark se dividen en varios trabajos, que se desglosan en varias etapas. Cada etapa puede tener varias tareas, que se ejecutan en nodos ejecutores (trabajadores).
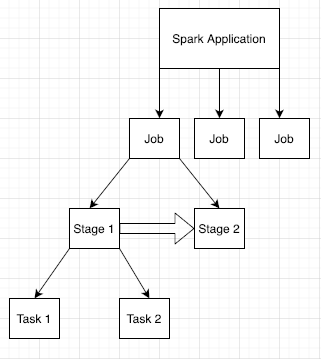
Haz clic en un ID de app de Spark en la interfaz web para abrir la página Trabajos de Spark, que proporciona un cronograma de eventos y un resumen de los trabajos dentro de la aplicación.
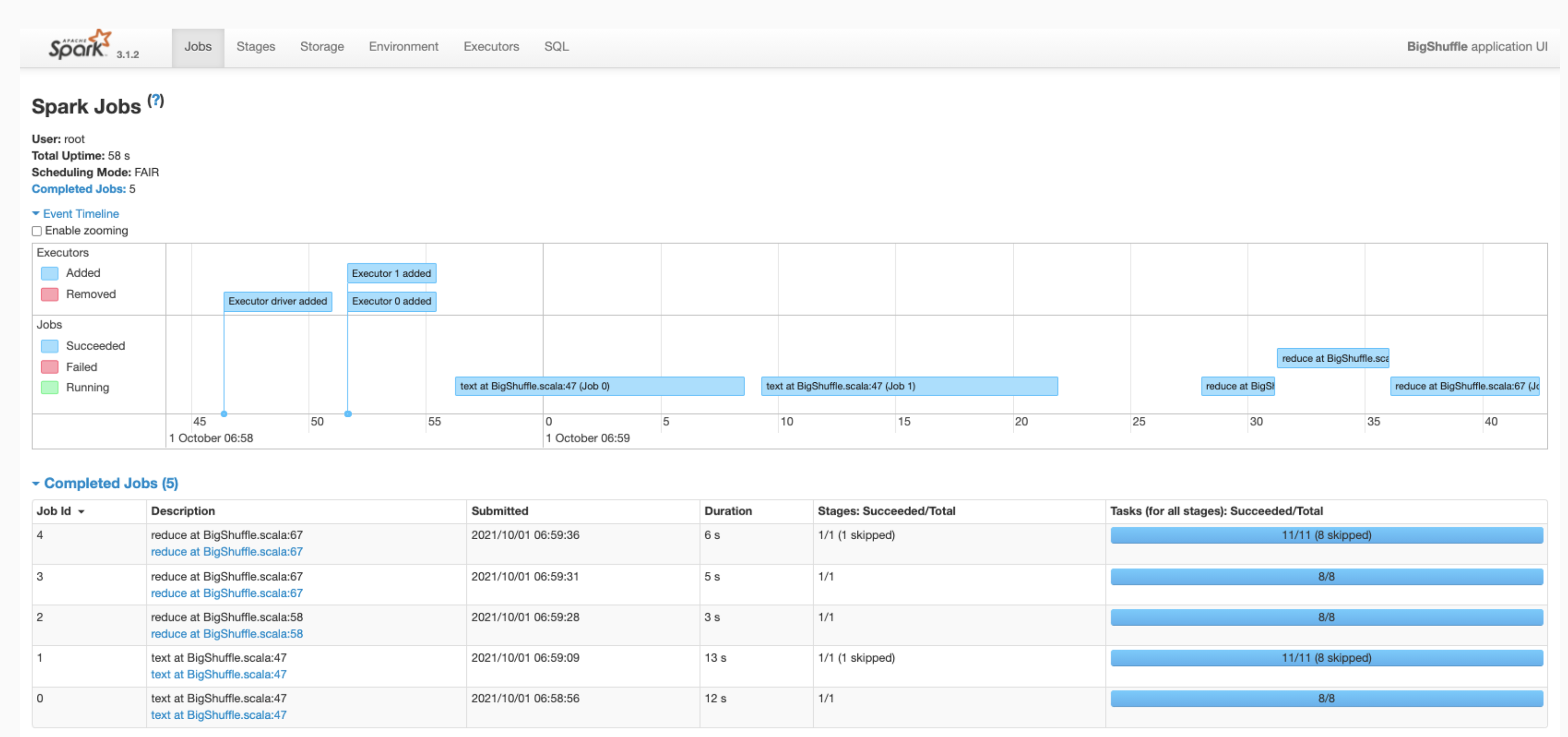
Haz clic en un trabajo para abrir una página de detalles de trabajo con un grafo acíclico dirigido (DAG) y el resumen de las etapas del trabajo.
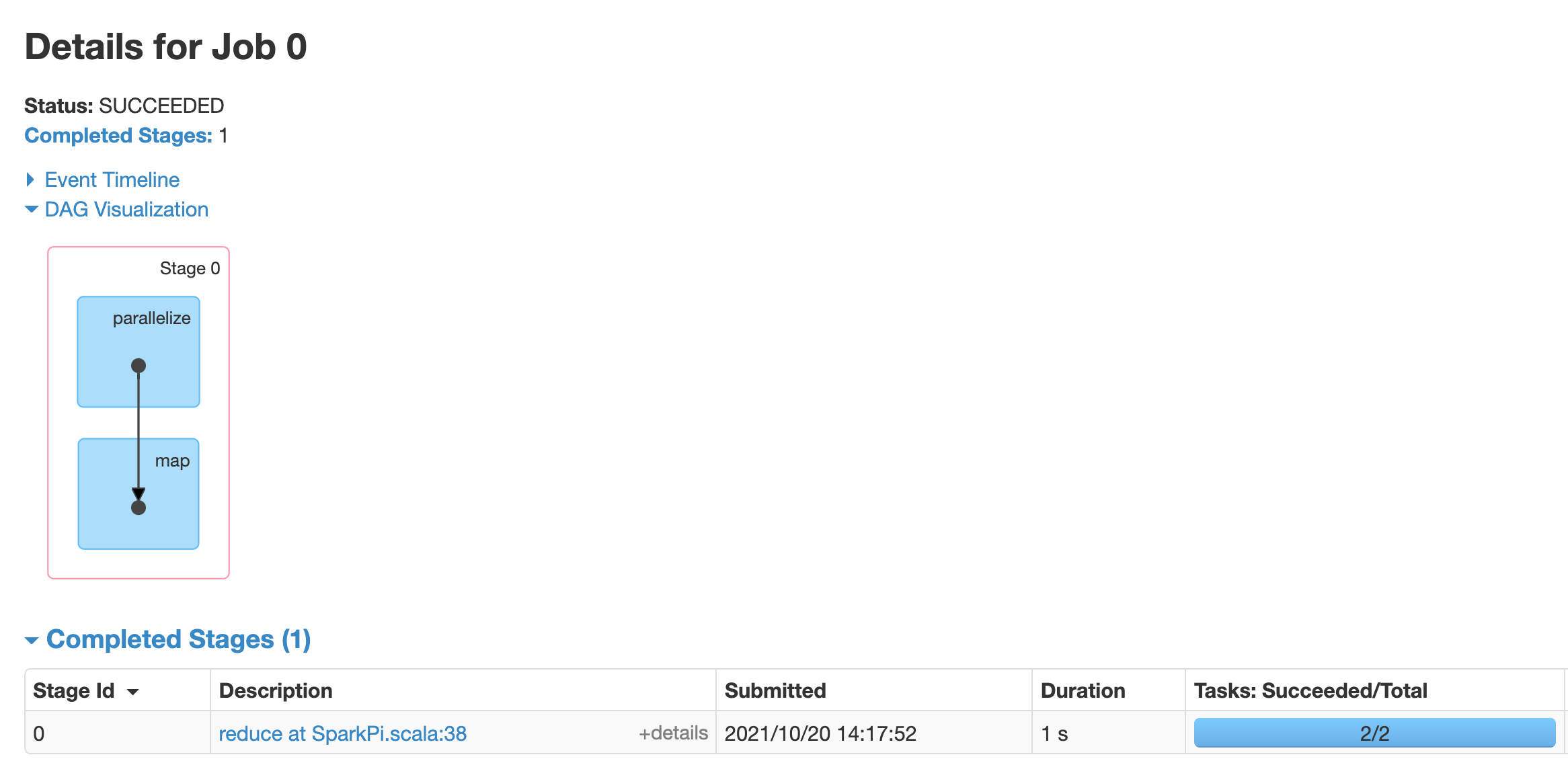
Haz clic en una etapa o usa la pestaña Etapas para seleccionar una etapa a fin de abrir la página Detalles de la etapa.
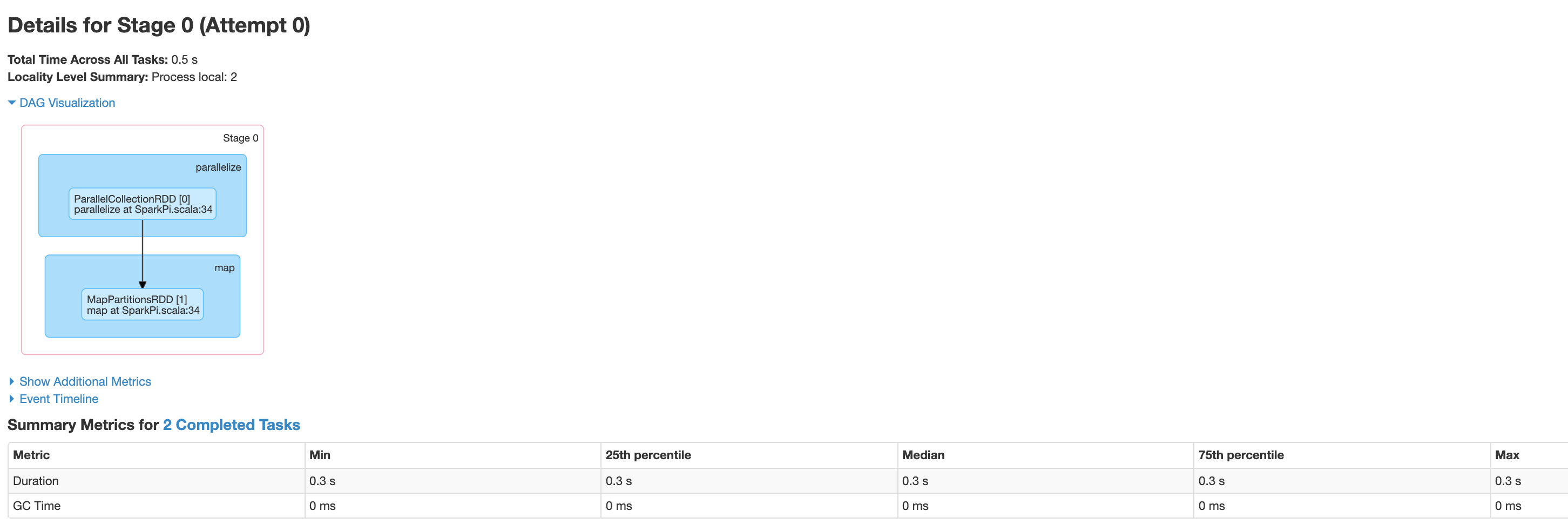
Los detalles de la etapa incluyen una visualización de DAG, un cronograma de eventos y métricas para las tareas dentro de la etapa. Puedes usar esta página para solucionar problemas relacionados con tareas suprimidas, retrasos del programador y errores de memoria insuficiente. El visualizador de DAG muestra la línea de código a partir de la cual se deriva la etapa, lo que te ayuda a hacer un seguimiento de los problemas hasta el código.
Haz clic en la pestaña Ejecutores para obtener información sobre el controlador de la aplicación de Spark y los nodos ejecutores.
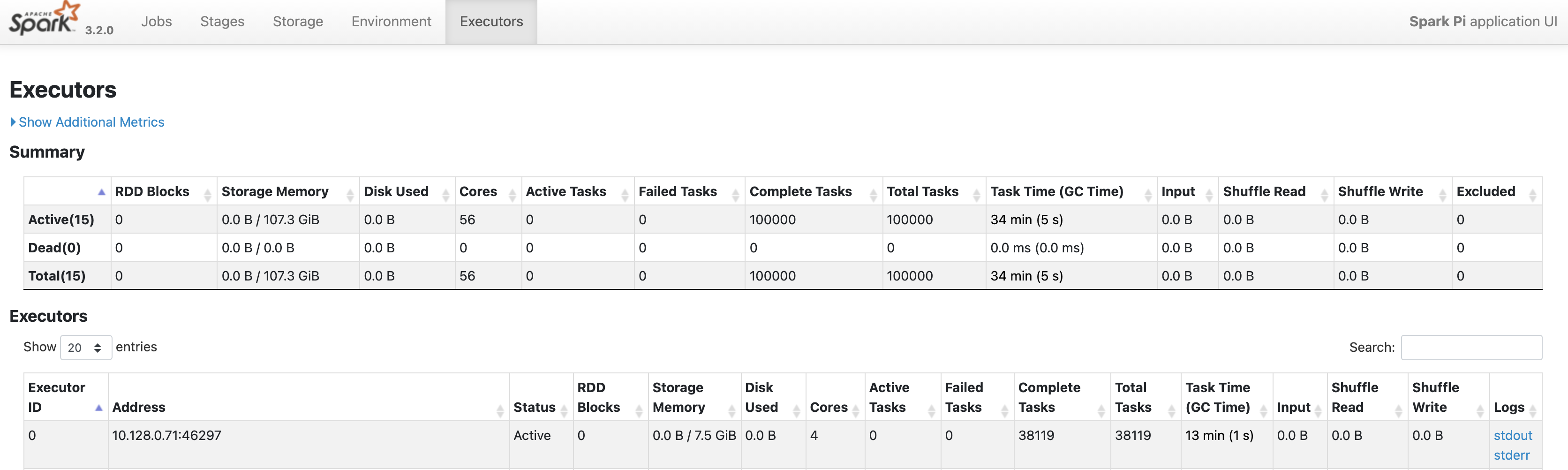
La información importante de esta página incluye la cantidad de núcleos y la cantidad de tareas que se ejecutaron en cada ejecutor.
Interfaz web de Tez
Tez es el motor de ejecución predeterminado para Hive y Pig en Dataproc. El envío de un trabajo de Hive en un clúster de trabajo de Dataproc inicia una aplicación de Tez (consulta Cómo usar Apache Hive en Dataproc ).
Si configuraste el servicio de cronograma de Yarn v2 y estableciste la propiedad dataproc:yarn.atsv2.bigtable.instance cuando creaste los clústeres de trabajo de PHS y Dataproc, YARN escribe los datos de cronograma de trabajo generados de Hive y Pig en la instancia de Bigtable especificada para su recuperación y visualización en la interfaz web de Tez que se ejecuta en el servidor de PHS.

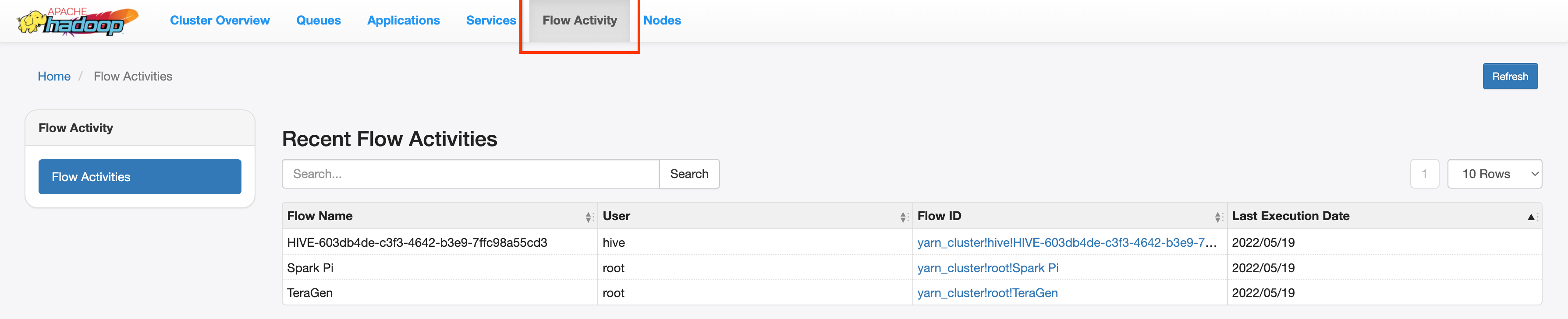
Interfaz web de la V2 de YARN Application Timeline
Si configuraste el servicio de cronograma de Yarn v2 y estableciste la propiedad dataproc:yarn.atsv2.bigtable.instance cuando creaste los clústeres de trabajo de la PHS y de Dataproc, YARN escribe los datos generados del cronograma de trabajo en la instancia de Bigtable especificada para su recuperación y visualización en la interfaz web del servicio de cronograma de aplicaciones de YARN que se ejecuta en el servidor de la PHS. Los trabajos de Dataproc se enumeran en la pestaña Actividad de flujo
de la interfaz web.
Configura el servicio de cronograma de Yarn v2
Para configurar el servicio de cronograma de Yarn v2, configura una instancia de Bigtable y, si es necesario, verifica los roles de la cuenta de servicio de la siguiente manera:
Verifica los roles de la cuenta de servicio, si es necesario. La cuenta de servicio de VM predeterminada que usan las VMs del clúster de Dataproc tiene los permisos necesarios para crear y configurar la instancia de Bigtable para el servicio de cronograma de YARN. Si creas tu trabajo o clúster de PHS con una cuenta de servicio de VM personalizada, la cuenta debe tener el rol
AdministratoroBigtable Userde Bigtable.
Esquema de tabla obligatorio
La compatibilidad de PHS de Dataproc con el servicio de cronograma de YARN v2 requiere un esquema específico creado en la instancia de Bigtable. Dataproc crea el esquema requerido cuando se crea un clúster de trabajo o un clúster de PHS con la propiedad dataproc:yarn.atsv2.bigtable.instance configurada para apuntar a la instancia de Bigtable.
El siguiente es el esquema de instancia de Bigtable obligatorio:
| Tablas | Familias de columnas |
|---|---|
| prod.timelineservice.application | c,i,m |
| prod.timelineservice.app_flow | m |
| prod.timelineservice.entity | c,i,m |
| prod.timelineservice.flowactivity | i |
| prod.timelineservice.flowrun | i |
| prod.timelineservice.subapplication | c,i,m |
Recolección de elementos no utilizados de Bigtable
Puedes configurar la recolección de elementos no utilizados de Bigtable basada en la antigüedad para las tablas de ATSv2:
Instala cbt (incluida la creación de
.cbrtc file).Crea la política de recolección de elementos no utilizados basada en la antigüedad de ATSv2:
export NUMBER_OF_DAYS = number \
cbt setgcpolicy prod.timelineservice.application c maxage=${NUMBER_OF_DAYS} \
cbt setgcpolicy prod.timelineservice.application i maxage=${NUMBER_OF_DAYS} \
cbt setgcpolicy prod.timelineservice.application m maxage=${NUMBER_OF_DAYS} \
cbt setgcpolicy prod.timelineservice.app_flow m maxage=${NUMBER_OF_DAYS} \
cbt setgcpolicy prod.timelineservice.entity c maxage=${NUMBER_OF_DAYS} \
cbt setgcpolicy prod.timelineservice.entity i maxage=${NUMBER_OF_DAYS} \
cbt setgcpolicy prod.timelineservice.entity m maxage=${NUMBER_OF_DAYS} \
cbt setgcpolicy prod.timelineservice.flowactivity i maxage=${NUMBER_OF_DAYS} \
cbt setgcpolicy prod.timelineservice.flowrun i maxage=${NUMBER_OF_DAYS} \
cbt setgcpolicy prod.timelineservice.subapplication c maxage=${NUMBER_OF_DAYS} \
cbt setgcpolicy prod.timelineservice.subapplication i maxage=${NUMBER_OF_DAYS} \
cbt setgcpolicy prod.timelineservice.subapplication m maxage=${NUMBER_OF_DAYS}
Notas:
NUMBER_OF_DAYS: La cantidad máxima de días es 30d.