Dataproc 클러스터를 만들 때 Dataproc 개인 클러스터 인증을 사용 설정하여 클러스터의 대화형 워크로드를 사용자 ID로 안전하게 실행할 수 있습니다. 즉, Cloud Storage와 같은 다른 Google Cloud 리소스와의 상호작용은 클러스터 서비스 계정이 아닌 사용자 본인으로 인증됩니다.
고려사항
개인 클러스터 인증이 사용 설정된 클러스터를 만들면 클러스터는 사용자의 ID로만 사용할 수 있습니다. 다른 사용자는 클러스터에서 작업을 실행하거나 클러스터의 구성요소 게이트웨이 엔드포인트에 액세스할 수 없습니다.
개인 클러스터 인증이 사용 설정된 클러스터는 클러스터의 모든 VM에서 시작 스크립트 등의 Compute Engine 기능과 SSH 액세스를 차단합니다.
개인 클러스터 인증이 사용 설정된 클러스터는 클러스터 내 보안 통신을 위해 클러스터에서 Kerberos를 자동으로 사용 설정하고 구성합니다. 하지만 클러스터의 모든 Kerberos ID는 동일한 사용자로 Google Cloud리소스와 상호작용합니다.
개인 클러스터 인증이 사용 설정된 클러스터는 커스텀 이미지를 지원하지 않습니다.
Dataproc 개인 클러스터 인증은 Dataproc 워크플로를 지원하지 않습니다.
Dataproc 개인 클러스터 인증은 개별(사람) 사용자가 실행하는 대화형 작업에만 사용됩니다. 장기 실행 작업은 적절한 서비스 계정 ID를 구성하고 사용해야 합니다.
전파된 사용자 인증 정보는 사용자 인증 정보 액세스 경계를 통해 권한이 축소됩니다. 기본 액세스 경계는 클러스터가 포함된 동일 프로젝트에서 소유한 Cloud Storage 버킷의 Cloud Storage 객체 읽기 및 쓰기로 제한됩니다. enable_an_interactive_session을 사용할 때 기본이 아닌 액세스 경계를 정의할 수 있습니다.
Dataproc 개인 클러스터 인증에는 Compute Engine 게스트 속성이 사용됩니다. 게스트 속성 기능이 사용 중지된 경우 개인 클러스터 인증이 실패합니다.
목표
Dataproc 개인 클러스터 인증이 사용 설정된 Dataproc 클러스터를 만듭니다.
클러스터에 사용자 인증 정보 전파를 시작합니다.
클러스터에서 Jupyter 메모장을 사용하여 사용자 인증 정보로 인증하는 Spark 작업을 실행합니다.
시작하기 전에
프로젝트 만들기
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Dataproc API.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
Install the Google Cloud CLI.
-
외부 ID 공급업체(IdP)를 사용하는 경우 먼저 제휴 ID로 gcloud CLI에 로그인해야 합니다.
-
gcloud CLI를 초기화하려면, 다음 명령어를 실행합니다.
gcloud init -
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Dataproc API.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
Install the Google Cloud CLI.
-
외부 ID 공급업체(IdP)를 사용하는 경우 먼저 제휴 ID로 gcloud CLI에 로그인해야 합니다.
-
gcloud CLI를 초기화하려면, 다음 명령어를 실행합니다.
gcloud init - Cloud Shell 세션을 시작합니다.
gcloud auth login을 실행하여 유효한 사용자 인증 정보를 가져옵니다.gcloud에서 활성 계정의 이메일 주소를 찾습니다.
gcloud auth list --filter=status=ACTIVE --format="value(account)"
클러스터를 만듭니다.
gcloud dataproc clusters create CLUSTER_NAME \ --properties=dataproc:dataproc.personal-auth.user=your-email-address \ --enable-component-gateway \ --optional-components=JUPYTER \ --region=REGION
Google Cloud리소스와 상호작용할 때 개인 사용자 인증 정보를 사용할 수 있도록 클러스터의 사용자 인증 정보 전파 세션을 사용 설정합니다.
gcloud dataproc clusters enable-personal-auth-session \ --region=REGION \ CLUSTER_NAME
샘플 출력:
Injecting initial credentials into the cluster CLUSTER_NAME...done. Periodically refreshing credentials for cluster CLUSTER_NAME. This will continue running until the command is interrupted...
권한이 축소된 액세스 경계 예시: 다음 예시에서는 권한이 축소된 기본 사용자 인증 정보 액세스 경계보다 더 제한적인 개인 인증 세션을 사용 설정합니다. Dataproc 클러스터의 스테이징 버킷에 대한 액세스를 제한합니다(자세한 내용은 사용자 인증 정보 액세스 경계를 사용하여 권한 축소 참조).
gcloud dataproc clusters enable-personal-auth-session \ --project=PROJECT_ID \ --region=REGION \ --access-boundary=<(echo -n "{ \ \"access_boundary\": { \ \"accessBoundaryRules\": [{ \ \"availableResource\": \"//storage.googleapis.com/projects/_/buckets/$(gcloud dataproc clusters describe --project=PROJECT_ID --region=REGION CLUSTER_NAME --format="value(config.configBucket)")\", \ \"availablePermissions\": [ \ \"inRole:roles/storage.objectViewer\", \ \"inRole:roles/storage.objectCreator\", \ \"inRole:roles/storage.objectAdmin\", \ \"inRole:roles/storage.legacyBucketReader\" \ ] \ }] \ } \ }") \ CLUSTER_NAME
명령어를 계속 실행하고 새 Cloud Shell 탭 또는 터미널 세션으로 전환합니다. 클라이언트는 명령어가 실행 중일 때 사용자 인증 정보를 새로고침합니다.
Ctrl-C를 입력하여 세션을 종료합니다.- 클러스터 세부정보를 가져옵니다.
gcloud dataproc clusters describe CLUSTER_NAME --region=REGION
Jupyter 웹 인터페이스 URL은 클러스터 세부정보에 나열됩니다.
... JupyterLab: https://UUID-dot-us-central1.dataproc.googleusercontent.com/jupyter/lab/ ...
- Jupyter UI를 시작하려면 로컬 브라우저에 URL을 복사합니다.
- 개인 클러스터 인증이 성공했는지 확인합니다.
- Jupyter 터미널을 시작합니다.
gcloud auth list실행- 사용자 이름이 유일한 활성 계정인지 확인합니다.
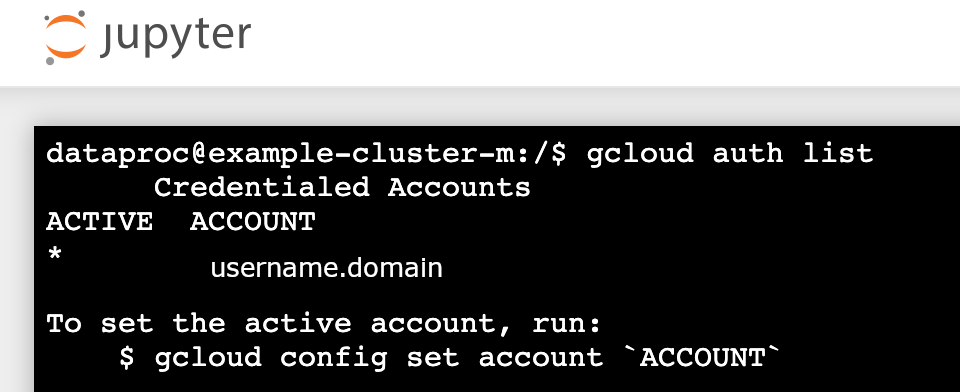
- Jupyter 터미널에서 Jupyter를 사용 설정하여 Kerberos를 인증하고 Spark 작업을 제출합니다.
kinit -kt /etc/security/keytab/dataproc.service.keytab dataproc/$(hostname -f)
klist를 실행하여 Jupyter가 유효한 TGT를 받았는지 확인합니다.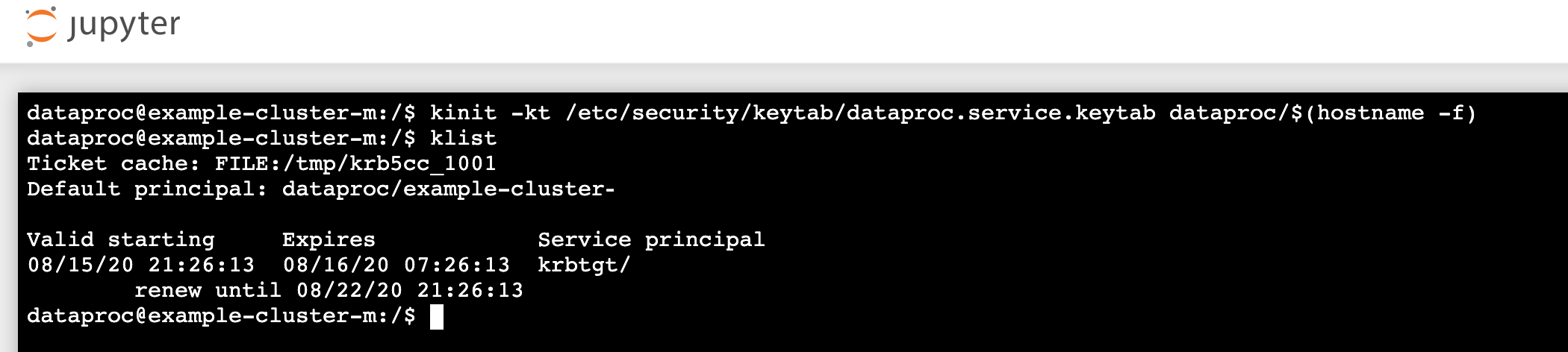
- Juypter 터미널에서 gcloud CLI를 사용하여 프로젝트의 Cloud Storage 버킷에
rose.txt파일을 만듭니다.echo "A rose by any other name would smell as sweet" > /tmp/rose.txt
gcloud storage cp /tmp/rose.txt gs://bucket-name/rose.txt
- 사용자 계정만 파일을 읽거나 쓸 수 있도록 파일을 비공개로 표시합니다. Jupyter는 Cloud Storage와 상호작용할 때 개인 사용자 인증 정보를 사용합니다.
gcloud storage objects update gs://bucket-name/rose.txt --predefined-acl=private
- 비공개 액세스를 확인합니다.
gcloud storage objects describe gs://$BUCKET/rose.txt
acl:
- 사용자 계정만 파일을 읽거나 쓸 수 있도록 파일을 비공개로 표시합니다. Jupyter는 Cloud Storage와 상호작용할 때 개인 사용자 인증 정보를 사용합니다.
- email: $USER entity: user-$USER role: OWNER
- 구성요소 게이트웨이 Jupyter 링크를 클릭하여 Jupyter UI를 시작합니다.
- 개인 클러스터 인증이 성공했는지 확인합니다.
- Jupyter 터미널을 시작합니다.
gcloud auth list실행- 사용자 이름이 유일한 활성 계정인지 확인합니다.
- Jupyter 터미널에서 Jupyter를 사용 설정하여 Kerberos를 인증하고 Spark 작업을 제출합니다.
kinit -kt /etc/security/keytab/dataproc.service.keytab dataproc/$(hostname -f)
klist를 실행하여 Jupyter가 유효한 TGT를 받았는지 확인합니다.
- Jupyter 터미널에서 gcloud CLI를 사용하여 프로젝트의 Cloud Storage 버킷에
rose.txt파일을 만듭니다.echo "A rose by any other name would smell as sweet" > /tmp/rose.txt
gcloud storage cp /tmp/rose.txt gs://bucket-name/rose.txt
- 사용자 계정만 파일을 읽거나 쓸 수 있도록 파일을 비공개로 표시합니다. Jupyter는 Cloud Storage와 상호작용할 때 개인 사용자 인증 정보를 사용합니다.
gcloud storage objects update gs://bucket-name/rose.txt --predefined-acl=private
- 비공개 액세스를 확인합니다.
gcloud storage objects describe gs://bucket-name/rose.txt
acl:
- 사용자 계정만 파일을 읽거나 쓸 수 있도록 파일을 비공개로 표시합니다. Jupyter는 Cloud Storage와 상호작용할 때 개인 사용자 인증 정보를 사용합니다.
- email: $USER entity: user-$USER role: OWNER
- 폴더로 이동한 후 PySpark 노트북을 만듭니다.
위에서 만든
rose.txt파일을 대상으로 기본 워드카운트 작업을 실행합니다.text_file = sc.textFile("gs://bucket-name/rose.txt") counts = text_file.flatMap(lambda line: line.split(" ")) \ .map(lambda word: (word, 1)) \ .reduceByKey(lambda a, b: a + b) print(counts.collect())rose.txt파일을 읽을 수 있습니다.또한 Cloud Storage 버킷 감사 로그를 확인하여 작업이 해당 ID로 Cloud Storage에 액세스하는지 확인할 수 있습니다(자세한 내용은 Cloud Storage에서 Cloud 감사 로그 사용 참조).
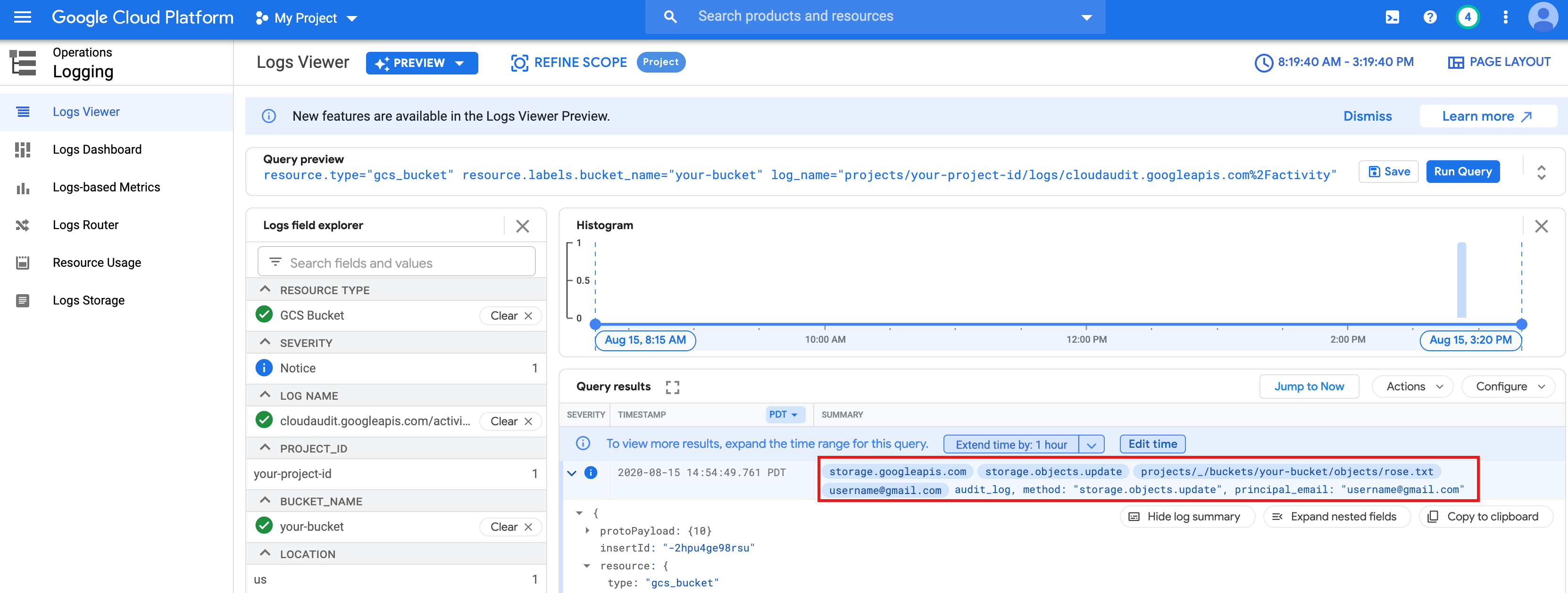
- Dataproc 클러스터를 삭제합니다.
gcloud dataproc clusters delete CLUSTER_NAME --region=REGION
환경 구성
Cloud Shell 또는 로컬 터미널에서 환경을 구성합니다.