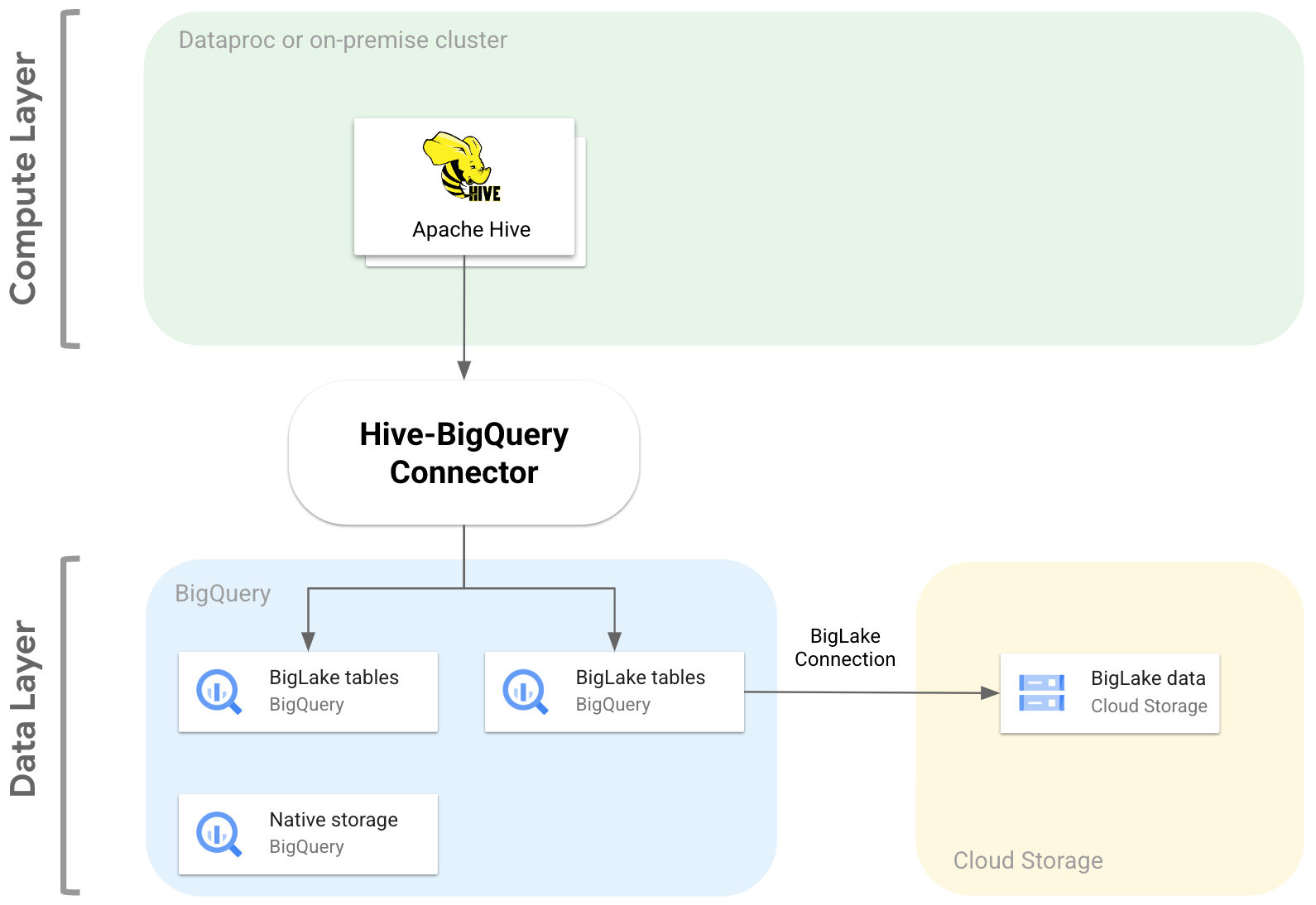
借助开源 Hive-BigQuery 连接器,Apache Hive 工作负载可以从 BigQuery 和 BigLake 表中读取数据以及向其写入数据。您可以将数据存储在 BigQuery 存储空间中,也可以采用开源数据格式存储在 Cloud Storage 中。
Hive-BigQuery 连接器实现了 Hive Storage Handler API,以允许 Hive 工作负载与 BigQuery 和 BigLake 表集成。Hive 执行引擎会处理聚合和联接等计算操作,而该连接器会管理与存储在 BigQuery 或 BigLake 连接的 Cloud Storage 存储桶中的数据的交互。
下图说明了 Hive-BigQuery 连接器如何在计算层和数据层之间进行适配。
使用场景
在常见的数据驱动型场景中,Hive-BigQuery 连接器可通过以下方式为您提供帮助:
数据迁移。您打算将 Hive 数据仓库迁移到 BigQuery,然后逐步将 Hive 查询转换为 BigQuery SQL 方言。由于数据仓库的大小和大量关联的应用,迁移预计需要花费大量时间,并且您需要确保迁移操作期间的连续性。工作流如下:
- 将数据迁移到 BigQuery
- 使用该连接器,访问和运行原始 Hive 查询,同时逐步将 Hive 查询转换为符合 ANSI 标准的 BigQuery SQL 方言。
- 完成迁移和转换后弃用 Hive。
Hive 和 BigQuery 工作流。您打算使用 Hive 执行某些任务,并使用 BigQuery 处理可从其功能(例如 BigQuery BI Engine 或 BigQuery ML)受益的工作负载。您可以使用该连接器将 Hive 表联接到 BigQuery 表。
依赖于开源软件 (OSS) 栈。为了避免对供应商的依赖,您需要为数据仓库使用完整的 OSS 技术栈。数据方案如下:
功能
您可以使用 Hive-BigQuery 连接器处理 BigQuery 数据,并完成以下任务:
- 使用 MapReduce 和 Tez 执行引擎运行查询。
- 在 Hive 中创建和删除 BigQuery 表。
- 将 BigQuery 表和 BigLake 表与 Hive 表联接。
- 使用 Storage Read API 数据流和 Apache Arrow 格式从 BigQuery 表中快速读取数据
- 使用以下方法将数据写入 BigQuery:
- 使用 BigQuery Storage Write API 在待处理模式下进行直接写入。此方法适用于需要低延迟的工作负载,例如刷新时段较短的近乎实时信息中心。
- 通过将临时 Avro 文件暂存到 Cloud Storage,然后使用 Load Job API 将文件加载到目标表中,进行间接写入。此方法的费用低于直接方法,因为 BigQuery 加载作业不会产生费用。由于此方法速度较慢,因此最适合用于对时间要求不高的工作负载
访问 BigQuery 时间分区表和聚簇表。以下示例定义了 Hive 表与在 BigQuery 中进行分区和聚簇的表之间的关系。
CREATE TABLE my_hive_table (int_val BIGINT, text STRING, ts TIMESTAMP) STORED BY 'com.google.cloud.hive.bigquery.connector.BigQueryStorageHandler' TBLPROPERTIES ( 'bq.table'='myproject.mydataset.mytable', 'bq.time.partition.field'='ts', 'bq.time.partition.type'='MONTH', 'bq.clustered.fields'='int_val,text' );
删减列,以避免从数据层检索不必要的列。
使用谓词下推在 BigQuery 存储层预过滤数据行。此技术可减少在网络中传输的数据量,从而显著提高整体查询性能。
自动将 Hive 数据类型转换为 BigQuery 数据类型。
与 Spark SQL 集成。
与 Apache Pig 和 HCatalog 集成。
开始使用
请参阅相关说明在 Hive 集群上安装和配置 Hive-BigQuery 连接器。