Com o conector Hive-BigQuery de código aberto, suas cargas de trabalho do Apache Hive podem ler e gravar dados das tabelas do BigQuery e do BigLake. É possível armazenar dados no armazenamento do BigQuery ou em formatos de dados de código aberto no Cloud Storage.
O conector Hive-BigQuery implementa a API Hive Storage Handler para permitir que as cargas de trabalho do Hive se integrem às tabelas do BigQuery e do BigLake. O mecanismo de execução do Hive processa operações de computação, como agregações e junções, e o conector gerencia as interações com dados armazenados no BigQuery ou em buckets do Cloud Storage conectados ao BigLake.
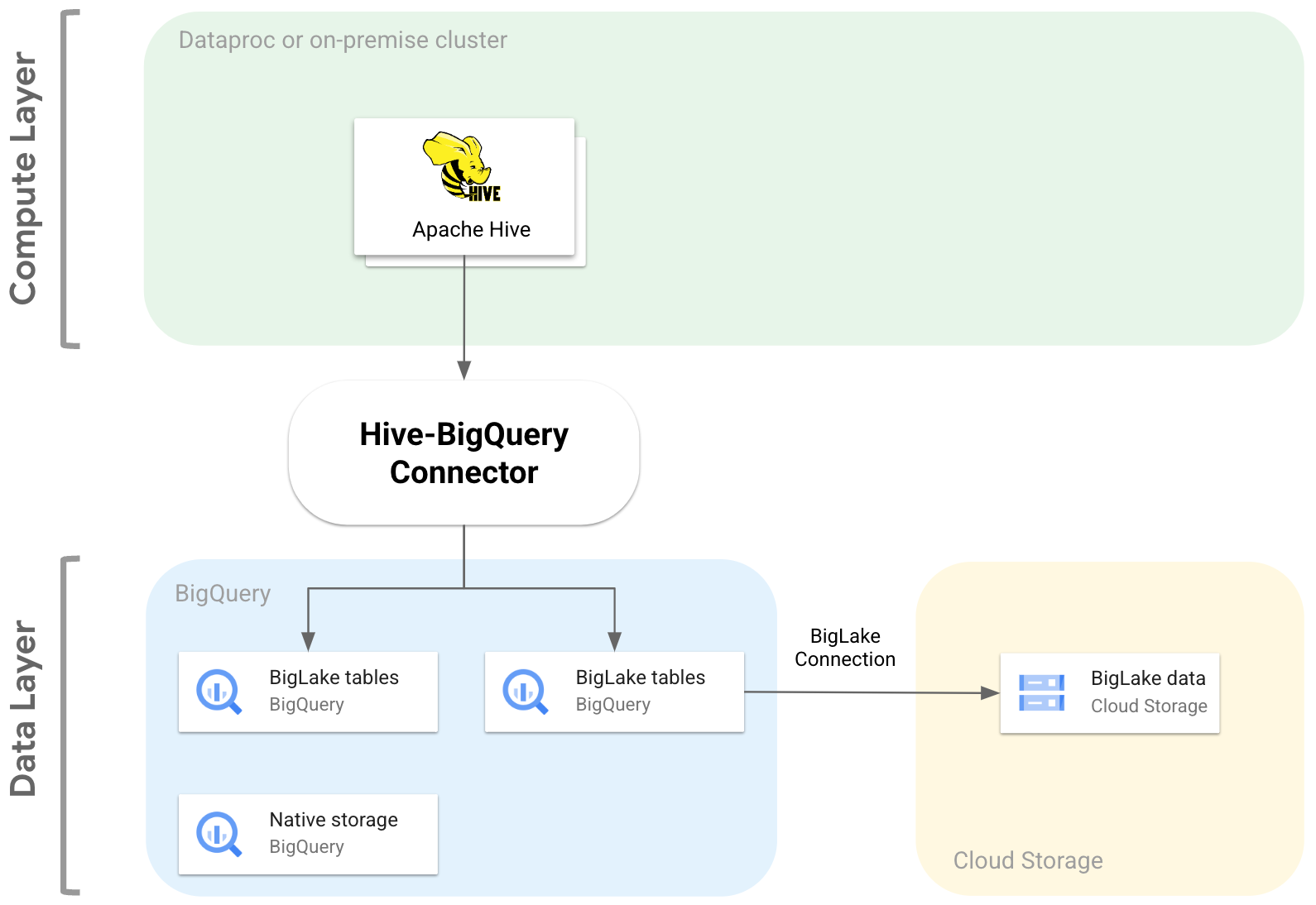
O diagrama a seguir ilustra como o conector Hive-BigQuery se encaixa entre as camadas de computação e dados.
Casos de uso
Confira algumas maneiras como o conector Hive-BigQuery pode ajudar você em cenários comuns baseados em dados:
Migração de dados. Você planeja mover seu data warehouse do Hive para o BigQuery e traduzir incrementalmente suas consultas do Hive para o dialeto SQL do BigQuery. Você espera que a migração leve um tempo significativo devido ao tamanho do data warehouse e ao grande número de aplicativos conectados, e precisa garantir a continuidade durante as operações de migração. Este é o fluxo de trabalho:
- Você move seus dados para o BigQuery
- Usando o conector, você acessa e executa suas consultas originais do Hive enquanto traduz gradualmente as consultas do Hive para o dialeto SQL compatível com ANSI do BigQuery.
- Depois de concluir a migração e a tradução, desative o Hive.
Fluxos de trabalho do Hive e do BigQuery. Você planeja usar o Hive para algumas tarefas e o BigQuery para cargas de trabalho que se beneficiam dos recursos dele, como o BigQuery BI Engine ou o BigQuery ML. Você usa o conector para unir tabelas do Hive às tabelas do BigQuery.
Confiança em uma pilha de software de código aberto (OSS). Para evitar o bloqueio de fornecedor, use uma pilha completa de OSS para seu data warehouse. Este é seu plano de dados:
Migre seus dados no formato OSS original, como Avro, Parquet ou ORC, para buckets do Cloud Storage usando uma conexão do BigLake.
Você continua usando o Hive para executar e processar consultas do dialeto SQL do Hive.
Use o conector conforme necessário para se conectar ao BigQuery e aproveitar os seguintes recursos:
- Armazenamento em cache de metadados para desempenho de consultas
- Prevenção contra perda de dados
- Controle de acesso no nível da coluna
- Mascaramento de dados dinâmicos para segurança e governança em grande escala.
Recursos
É possível usar o conector Hive-BigQuery para trabalhar com seus dados do BigQuery e realizar as seguintes tarefas:
- Execute consultas com mecanismos de execução MapReduce e Tez.
- Criar e excluir tabelas do BigQuery no Hive.
- Mesclar tabelas do BigQuery e do BigLake com tabelas do Hive.
- Faça leituras rápidas de tabelas do BigQuery usando os fluxos da API Storage Read e o formato Apache Arrow.
- Grave dados no BigQuery usando os seguintes
métodos:
- Gravações diretas usando a API Storage Write do BigQuery no modo pendente. Use esse método para cargas de trabalho que exigem baixa latência de gravação, como painéis quase em tempo real com janelas de atualização curtas.
- Gravações indiretas ao armazenar arquivos Avro temporários no Cloud Storage e carregar os arquivos em uma tabela de destino usando a API Load Job. Esse método é menos caro do que o direto, já que os jobs de carregamento do BigQuery não geram cobranças. Como esse método é mais lento e é mais adequado para cargas de trabalho que não são sensíveis ao tempo
Acesse tabelas do BigQuery particionadas por tempo e em cluster. O exemplo a seguir define a relação entre uma tabela do Hive e uma tabela particionada e agrupada em cluster no BigQuery.
CREATE TABLE my_hive_table (int_val BIGINT, text STRING, ts TIMESTAMP) STORED BY 'com.google.cloud.hive.bigquery.connector.BigQueryStorageHandler' TBLPROPERTIES ( 'bq.table'='myproject.mydataset.mytable', 'bq.time.partition.field'='ts', 'bq.time.partition.type'='MONTH', 'bq.clustered.fields'='int_val,text' );
Remova colunas para evitar a recuperação de colunas desnecessárias da camada de dados.
Use pushdowns de predicado para pré-filtrar linhas de dados na camada de armazenamento do BigQuery. Essa técnica pode melhorar significativamente a performance geral da consulta, reduzindo a quantidade de dados que atravessam a rede.
Converter automaticamente tipos de dados do Hive em tipos de dados do BigQuery.
Leia sobre visualizações e snapshots de tabelas do BigQuery.
Integrar com o Spark SQL.
Integração com Apache Pig e HCatalog.
Primeiros passos
Consulte as instruções para instalar e configurar o conector Hive-BigQuery em um cluster do Hive.