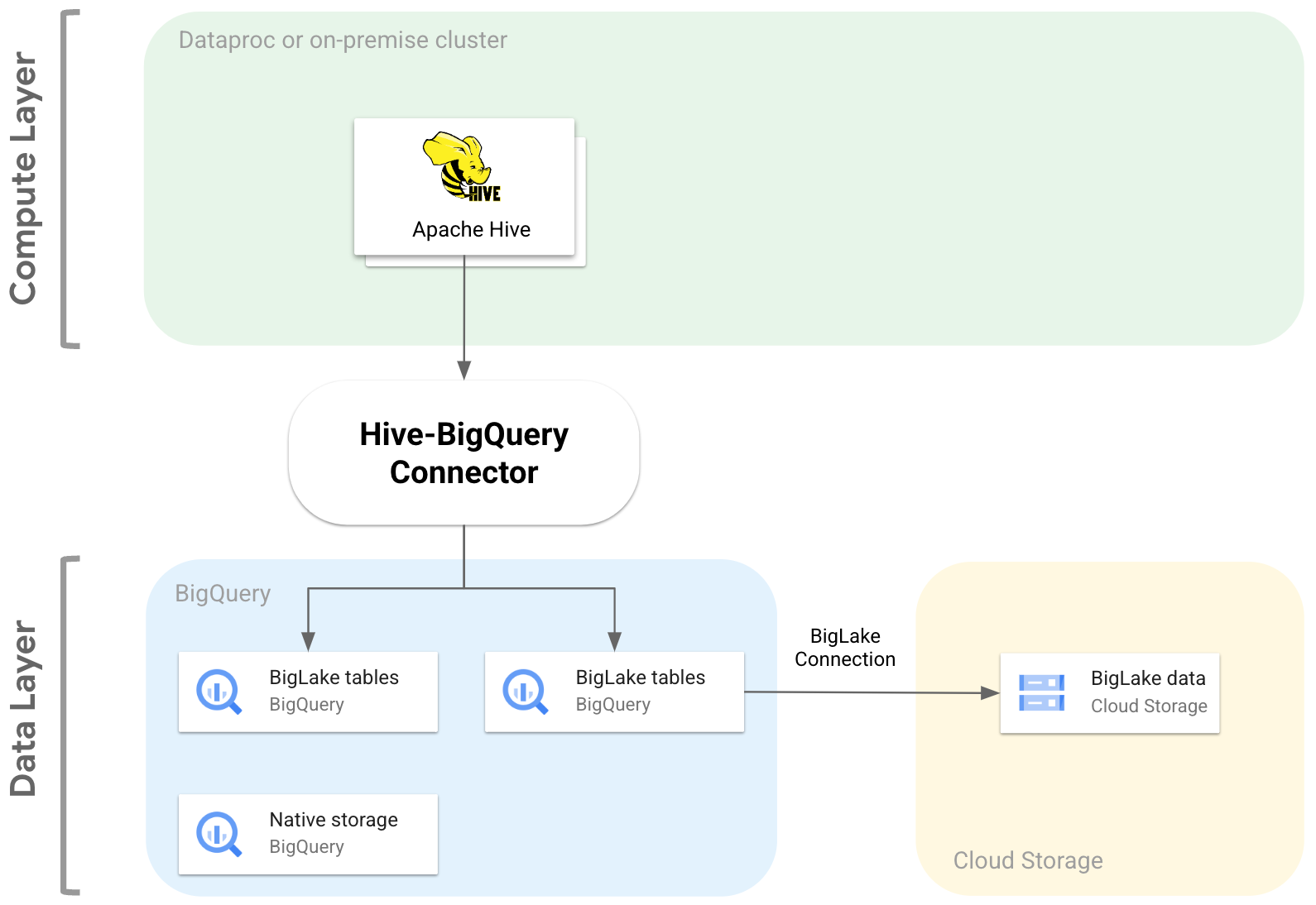
El conector Hive-BigQuery de código abierto permite que tus cargas de trabajo de Apache Hive lean y escriban datos desde y hacia tablas de BigQuery y BigLake. Puede almacenar datos en el almacenamiento de BigQuery o en formatos de datos de código abierto en Cloud Storage.
El conector Hive-BigQuery implementa la API Hive Storage Handler para permitir que las cargas de trabajo de Hive se integren con las tablas de BigQuery y BigLake. El motor de ejecución de Hive gestiona las operaciones de computación, como las agregaciones y las combinaciones, y el conector gestiona las interacciones con los datos almacenados en BigQuery o en los cubos de Cloud Storage conectados a BigLake.
En el siguiente diagrama se muestra cómo se ajusta el conector Hive-BigQuery entre las capas de computación y de datos.
Casos prácticos
Estas son algunas de las formas en las que el conector Hive-BigQuery puede ayudarte en situaciones habituales basadas en datos:
Migración de datos. Tienes previsto migrar tu almacén de datos de Hive a BigQuery y, a continuación, traducir de forma incremental tus consultas de Hive al dialecto SQL de BigQuery. Prevé que la migración llevará bastante tiempo debido al tamaño de tu almacén de datos y al gran número de aplicaciones conectadas, y necesitas garantizar la continuidad durante las operaciones de migración. Este es el flujo de trabajo:
- Mueve tus datos a BigQuery
- Con el conector, puedes acceder a tus consultas de Hive originales y ejecutarlas mientras traduces gradualmente las consultas de Hive al dialecto de SQL compatible con ANSI de BigQuery.
- Una vez que hayas completado la migración y la traducción, podrás retirar Hive.
Flujos de trabajo de Hive y BigQuery. Tienes previsto usar Hive para algunas tareas y BigQuery para cargas de trabajo que se beneficien de sus funciones, como BigQuery BI Engine o BigQuery ML. Usa el conector para unir tablas de Hive a tus tablas de BigQuery.
Dependencia de una pila de software de código abierto. Para evitar la dependencia de un proveedor, utiliza una pila de software libre completa para tu almacén de datos. Este es tu plan de datos:
Migra los datos en su formato OSS original, como Avro, Parquet u ORC, a los cubos de Cloud Storage mediante una conexión de BigLake.
Seguirás usando Hive para ejecutar y procesar tus consultas del dialecto de SQL de Hive.
Puedes usar el conector cuando lo necesites para conectarte a BigQuery y disfrutar de las siguientes funciones:
- Almacenamiento en caché de metadatos para mejorar el rendimiento de las consultas
- Prevención de la pérdida de datos
- Control de acceso a nivel de columna
- Máscara de datos dinámica para la seguridad y la gobernanza a gran escala.
Funciones
Puedes usar el conector Hive-BigQuery para trabajar con tus datos de BigQuery y llevar a cabo las siguientes tareas:
- Ejecuta consultas con los motores de ejecución MapReduce y Tez.
- Crear y eliminar tablas de BigQuery desde Hive.
- Combinar tablas de BigQuery y BigLake con tablas de Hive.
- Realizar lecturas rápidas de tablas de BigQuery mediante las secuencias de la API Storage Read y el formato Apache Arrow
- Escribe datos en BigQuery con los siguientes métodos:
- Escrituras directas con la API Storage Write de BigQuery en modo pendiente. Usa este método para cargas de trabajo que requieran una latencia de escritura baja, como los paneles de control casi en tiempo real con ventanas de tiempo de actualización cortas.
- Escrituras indirectas mediante el almacenamiento temporal de archivos Avro en Cloud Storage y, a continuación, la carga de los archivos en una tabla de destino mediante la API Load Job. Este método es menos caro que el directo, ya que los trabajos de carga de BigQuery no generan cargos. Como este método es más lento, se recomienda usarlo en cargas de trabajo que no sean urgentes.
Acceder a tablas particionadas por tiempo y agrupadas de BigQuery. En el siguiente ejemplo se define la relación entre una tabla de Hive y una tabla con particiones y clústeres en BigQuery.
CREATE TABLE my_hive_table (int_val BIGINT, text STRING, ts TIMESTAMP) STORED BY 'com.google.cloud.hive.bigquery.connector.BigQueryStorageHandler' TBLPROPERTIES ( 'bq.table'='myproject.mydataset.mytable', 'bq.time.partition.field'='ts', 'bq.time.partition.type'='MONTH', 'bq.clustered.fields'='int_val,text' );
Elimina columnas para evitar recuperar columnas innecesarias de la capa de datos.
Usa la inserción de predicados para prefiltrar las filas de datos en la capa de almacenamiento de BigQuery. Esta técnica puede mejorar significativamente el rendimiento general de las consultas al reducir la cantidad de datos que atraviesan la red.
Convertir automáticamente los tipos de datos de Hive en tipos de datos de BigQuery.
Leer vistas y snapshots de tablas de BigQuery.
Integración con Spark SQL.
Integración con Apache Pig y HCatalog.
Empezar
Consulta las instrucciones para instalar y configurar el conector Hive-BigQuery en un clúster de Hive.