Dataproc Ranger Cloud Storage 外掛程式適用於 Dataproc 映像檔 1.5 和 2.0 版,可啟用每個 Dataproc 叢集 VM 的授權服務。授權服務會根據 Ranger 政策評估 Cloud Storage 連接器的要求,如果允許要求,則會為叢集 VM 服務帳戶傳回存取權杖。
Ranger Cloud Storage 外掛程式會使用 Kerberos 進行驗證,並整合 Cloud Storage 連接器支援的委派權杖。委派權杖會儲存在叢集主節點的 MySQL 資料庫中。建立 Dataproc 叢集時,您可透過叢集屬性指定資料庫的根密碼。
事前準備
在專案中,將服務帳戶憑證建立者角色和 IAM 角色管理員角色授予Dataproc VM 服務帳戶。
安裝 Ranger Cloud Storage 外掛程式
在本機終端機視窗或 Cloud Shell 中執行下列指令,在建立 Dataproc 叢集時安裝 Ranger Cloud Storage 外掛程式。
設定環境變數
export CLUSTER_NAME=new-cluster-name \ export REGION=region \ export KERBEROS_KMS_KEY_URI=Kerberos-KMS-key-URI \ export KERBEROS_PASSWORD_URI=Kerberos-password-URI \ export RANGER_ADMIN_PASSWORD_KMS_KEY_URI=Ranger-admin-password-KMS-key-URI \ export RANGER_ADMIN_PASSWORD_GCS_URI=Ranger-admin-password-GCS-URI \ export RANGER_GCS_PLUGIN_MYSQL_KMS_KEY_URI=MySQL-root-password-KMS-key-URI \ export RANGER_GCS_PLUGIN_MYSQL_PASSWORD_URI=MySQL-root-password-GCS-URI
注意:
- CLUSTER_NAME:新叢集的名稱。
- REGION:叢集建立所在的地區,例如
us-west1。 - KERBEROS_KMS_KEY_URI 和 KERBEROS_PASSWORD_URI:請參閱「設定 Kerberos 根主體密碼」。
- RANGER_ADMIN_PASSWORD_KMS_KEY_URI 和 RANGER_ADMIN_PASSWORD_GCS_URI:請參閱「設定 Ranger 管理員密碼」。
- RANGER_GCS_PLUGIN_MYSQL_KMS_KEY_URI 和 RANGER_GCS_PLUGIN_MYSQL_PASSWORD_URI:按照設定 Ranger 管理員密碼時使用的相同程序,設定 MySQL 密碼。
建立 Dataproc 叢集
執行下列指令,建立 Dataproc 叢集並在叢集上安裝 Ranger Cloud Storage 外掛程式。
gcloud dataproc clusters create ${CLUSTER_NAME} \
--region=${REGION} \
--scopes cloud-platform \
--enable-component-gateway \
--optional-components=SOLR,RANGER \
--kerberos-kms-key=${KERBEROS_KMS_KEY_URI} \
--kerberos-root-principal-password-uri=${KERBEROS_PASSWORD_URI} \
--properties="dataproc:ranger.gcs.plugin.enable=true, \
dataproc:ranger.kms.key.uri=${RANGER_ADMIN_PASSWORD_KMS_KEY_URI}, \
dataproc:ranger.admin.password.uri=${RANGER_ADMIN_PASSWORD_GCS_URI}, \
dataproc:ranger.gcs.plugin.mysql.kms.key.uri=${RANGER_GCS_PLUGIN_MYSQL_KMS_KEY_URI}, \
dataproc:ranger.gcs.plugin.mysql.password.uri=${RANGER_GCS_PLUGIN_MYSQL_PASSWORD_URI}"
注意:
- 1.5 版映像檔:如果您要建立 1.5 版映像檔叢集 (請參閱「選取版本」),請新增
--metadata=GCS_CONNECTOR_VERSION="2.2.6" or higher旗標,安裝所需連接器版本。
驗證 Ranger Cloud Storage 外掛程式安裝作業
叢集建立完成後,Ranger 管理員網頁介面中會顯示名為 gcs-dataproc 的 GCS 服務類型。
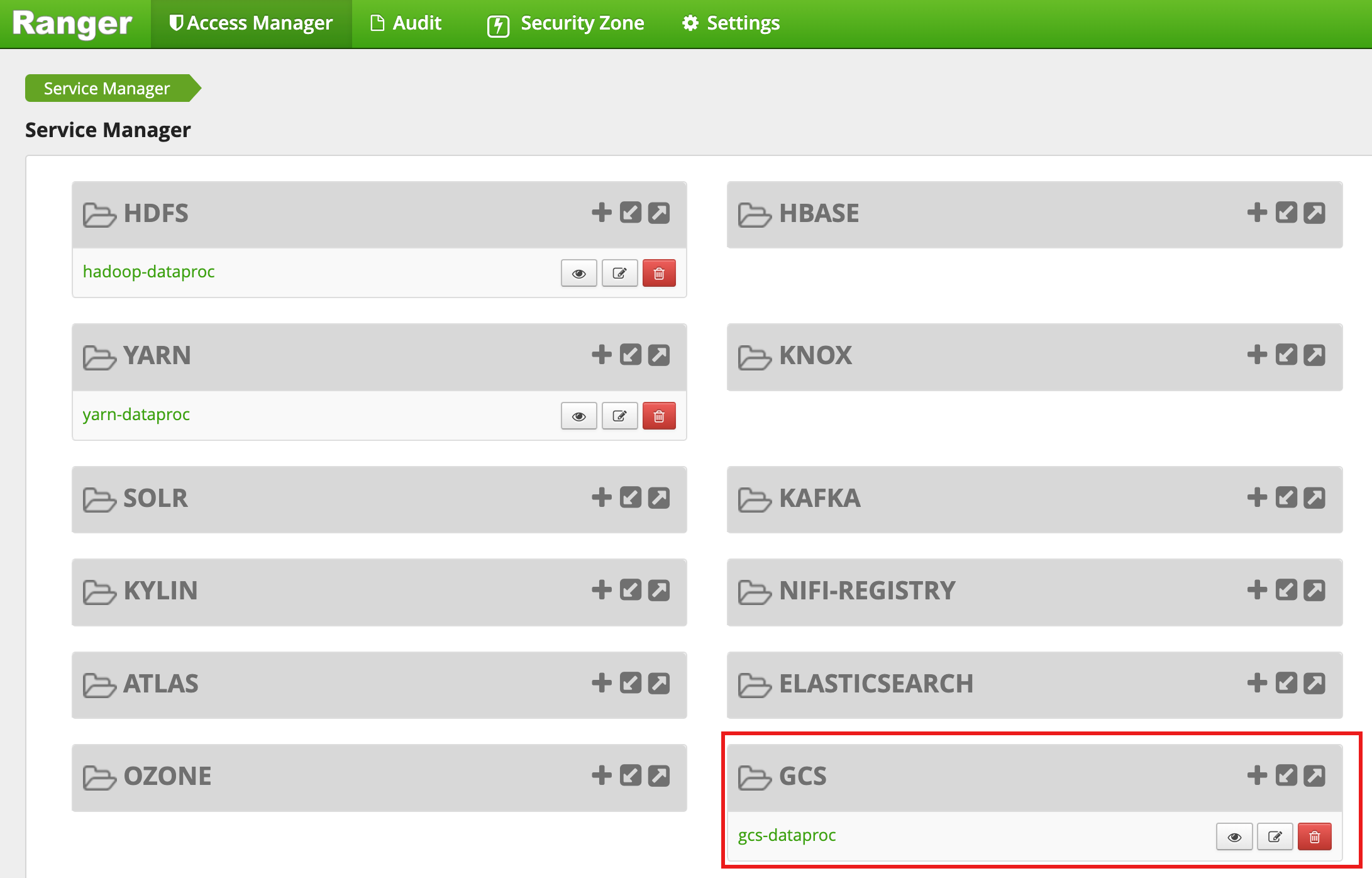
Ranger Cloud Storage 外掛程式預設政策
預設 gcs-dataproc 服務具有下列政策:
從 Dataproc 叢集暫存和臨時值區讀取及寫入資料的政策
all - bucket, object-path政策,允許所有使用者存取所有物件的中繼資料。Cloud Storage 連接器必須具備這項存取權,才能執行 HCFS (Hadoop 相容檔案系統) 作業。
使用秘訣
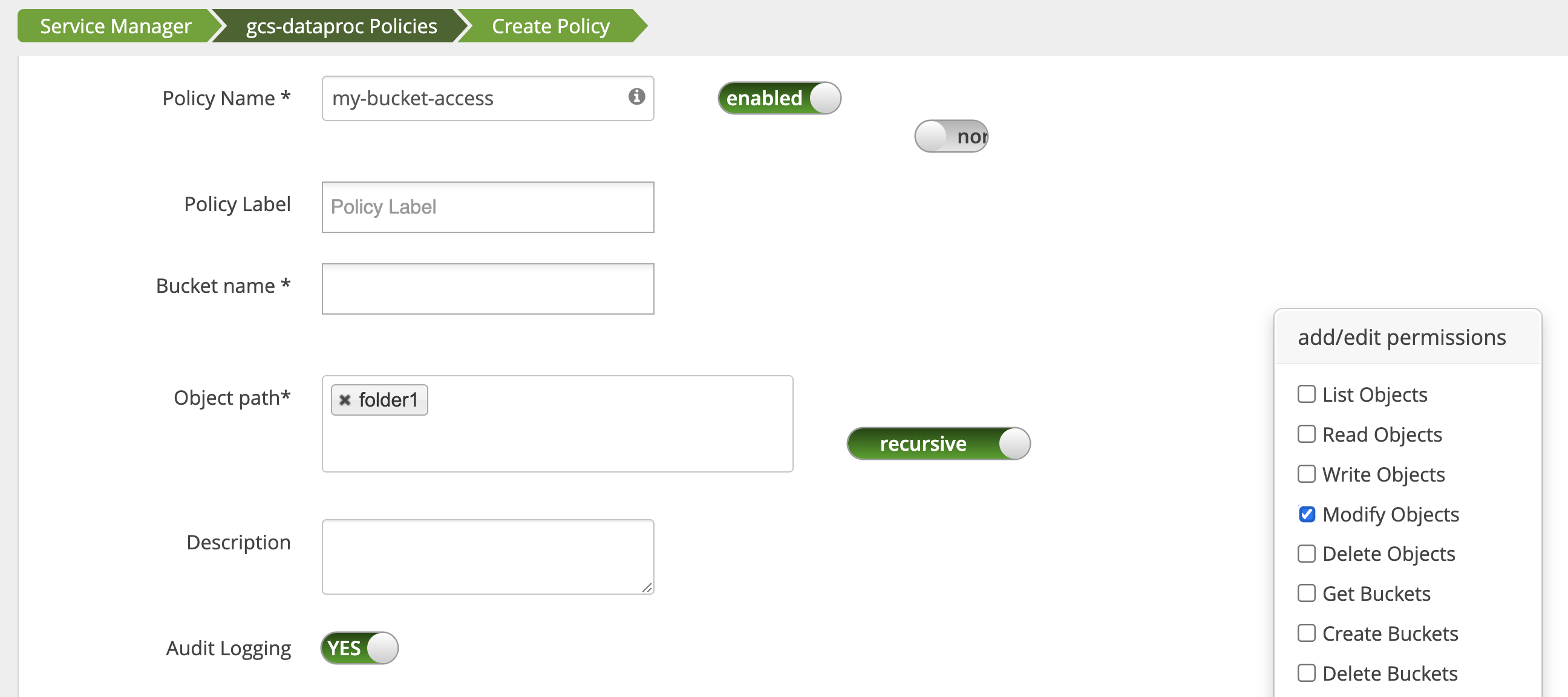
應用程式存取值區資料夾
如要配合在 Cloud Storage bucket 中建立中繼檔案的應用程式,您可以授予 Cloud Storage bucket 路徑的 Modify Objects、List Objects 和 Delete Objects 權限,然後選取 recursive 模式,將權限擴展至指定路徑的子路徑。
保護措施
為避免外掛程式遭到規避,請採取下列做法:
授予 VM 服務帳戶 Cloud Storage bucket 中的資源存取權,允許該帳戶使用範圍縮減的存取權權杖授予這些資源的存取權 (請參閱「Cloud Storage 的 IAM 權限」)。此外,請移除使用者對值區資源的存取權,避免使用者直接存取值區。
在叢集 VM 上停用
sudo和其他根存取方式,包括更新sudoer檔案,防止他人冒用身分或變更驗證和授權設定。詳情請參閱 Linux 指令,瞭解如何新增/移除sudo使用者權限。使用
iptable封鎖叢集 VM 對 Cloud Storage 的直接存取要求。舉例來說,您可以封鎖 VM 中繼資料伺服器的存取權,防止存取用於驗證及授權存取 Cloud Storage 的 VM 服務帳戶憑證或存取權杖 (請參閱block_vm_metadata_server.sh,這是使用iptable規則封鎖 VM 中繼資料伺服器存取權的初始化指令碼)。
Spark、Hive-on-MapReduce 和 Hive-on-Tez 工作
為保護機密的使用者驗證詳細資料,並減輕金鑰分配中心 (KDC) 的負擔,Spark 驅動程式不會將 Kerberos 憑證分配給執行器。Spark 驅動程式會改為從 Ranger Cloud Storage 外掛程式取得委派權杖,然後將委派權杖分配給執行器。執行器會使用委派權杖向 Ranger Cloud Storage 外掛程式進行驗證,並將其換成 Google 存取權杖,以便存取 Cloud Storage。
Hive-on-MapReduce 和 Hive-on-Tez 工作也會使用權杖存取 Cloud Storage。提交下列工作類型時,請使用下列屬性取得存取指定 Cloud Storage bucket 的權杖:
Spark 工作:
--conf spark.yarn.access.hadoopFileSystems=gs://bucket-name,gs://bucket-name,...
Hive-on-MapReduce 工作:
--hiveconf "mapreduce.job.hdfs-servers=gs://bucket-name,gs://bucket-name,..."
Hive-on-Tez 工作:
--hiveconf "tez.job.fs-servers=gs://bucket-name,gs://bucket-name,..."
Spark 工作情境
在安裝 Ranger Cloud Storage 外掛程式的 Dataproc 叢集 VM 上,透過終端機視窗執行 Spark 字數計算工作時,工作會失敗。
spark-submit \
--conf spark.yarn.access.hadoopFileSystems=gs://${FILE_BUCKET} \
--class org.apache.spark.examples.JavaWordCount \
/usr/lib/spark/examples/jars/spark-examples.jar \
gs://bucket-name/wordcount.txt
注意:
- FILE_BUCKET:用於 Spark 存取的 Cloud Storage bucket。
錯誤輸出內容:
Caused by: com.google.gcs.ranger.client.shaded.io.grpc.StatusRuntimeException: PERMISSION_DENIED: Access denied by Ranger policy: User: '<USER>', Bucket: '<dataproc_temp_bucket>', Object Path: 'a97127cf-f543-40c3-9851-32f172acc53b/spark-job-history/', Action: 'LIST_OBJECTS'
注意:
- 在啟用 Kerberos 的環境中,必須使用
spark.yarn.access.hadoopFileSystems=gs://${FILE_BUCKET}。
錯誤輸出內容:
Caused by: java.lang.RuntimeException: Failed creating a SPNEGO token. Make sure that you have run `kinit` and that your Kerberos configuration is correct. See the full Kerberos error message: No valid credentials provided (Mechanism level: No valid credentials provided)
在 Ranger 管理員網頁介面中,使用「Access Manager」編輯政策,將 username 新增至具有 List Objects 和其他 temp 值區權限的使用者清單。

執行工作會產生新的錯誤。
錯誤輸出內容:
com.google.gcs.ranger.client.shaded.io.grpc.StatusRuntimeException: PERMISSION_DENIED: Access denied by Ranger policy: User: <USER>, Bucket: '<file-bucket>', Object Path: 'wordcount.txt', Action: 'READ_OBJECTS'
新增政策,授予使用者 wordcount.textCloud Storage 路徑的讀取權。

工作順利執行並完成。
INFO com.google.cloud.hadoop.fs.gcs.auth.GcsDelegationTokens: Using delegation token RangerGCSAuthorizationServerSessionToken owner=<USER>, renewer=yarn, realUser=, issueDate=1654116824281, maxDate=0, sequenceNumber=0, masterKeyId=0 this: 1 is: 1 a: 1 text: 1 file: 1 22/06/01 20:54:13 INFO org.sparkproject.jetty.server.AbstractConnector: Stopped