O plug-in do Cloud Storage do Dataproc Ranger, disponível nas versões 1.5 e 2.0 da imagem do Dataproc, ativa um serviço de autorização em cada VM de cluster do Dataproc. O serviço de autorização avalia solicitações do conector do Cloud Storage em relação às políticas do Ranger e, se a solicitação for permitida, retorna um token de acesso para a conta de serviço da VM do cluster.
O plug-in do Ranger Cloud Storage depende do Kerberos para autenticação e se integra ao suporte do conector do Cloud Storage para tokens de delegação. Os tokens de delegação são armazenados em um banco de dados MySQL no nó mestre do cluster. A senha raiz do banco de dados é especificada nas propriedades do cluster ao criar o cluster do Dataproc.
Antes de começar
Conceda o papel de Criador de token da conta de serviço e o papel de Administrador de papéis do IAM na conta de serviço da VM do Dataproc no seu projeto.
Instalar o plug-in do Ranger Cloud Storage
Execute os comandos a seguir em uma janela de terminal local ou no Cloud Shell para instalar o plug-in do Ranger Cloud Storage ao criar um cluster do Dataproc.
Defina as variáveis de ambiente
export CLUSTER_NAME=new-cluster-name \ export REGION=region \ export KERBEROS_KMS_KEY_URI=Kerberos-KMS-key-URI \ export KERBEROS_PASSWORD_URI=Kerberos-password-URI \ export RANGER_ADMIN_PASSWORD_KMS_KEY_URI=Ranger-admin-password-KMS-key-URI \ export RANGER_ADMIN_PASSWORD_GCS_URI=Ranger-admin-password-GCS-URI \ export RANGER_GCS_PLUGIN_MYSQL_KMS_KEY_URI=MySQL-root-password-KMS-key-URI \ export RANGER_GCS_PLUGIN_MYSQL_PASSWORD_URI=MySQL-root-password-GCS-URI
Observações:
- CLUSTER_NAME: o nome do novo cluster.
- REGION: a região em que o cluster será criado, por exemplo,
us-west1. - KERBEROS_KMS_KEY_URI e KERBEROS_PASSWORD_URI: consulte Configurar a senha principal da raiz do Kerberos.
- RANGER_ADMIN_PASSWORD_KMS_KEY_URI e RANGER_ADMIN_PASSWORD_GCS_URI: consulte Configurar sua senha de administrador do Ranger.
- RANGER_GCS_PLUGIN_MYSQL_KMS_KEY_URI e RANGER_GCS_PLUGIN_MYSQL_PASSWORD_URI: configure uma senha do MySQL seguindo o mesmo procedimento usado para configurar uma senha de administrador do Ranger.
Criar um cluster do Dataproc
Execute o comando a seguir para criar um cluster do Dataproc e instalar o plug-in do Ranger Cloud Storage nele.
gcloud dataproc clusters create ${CLUSTER_NAME} \
--region=${REGION} \
--scopes cloud-platform \
--enable-component-gateway \
--optional-components=SOLR,RANGER \
--kerberos-kms-key=${KERBEROS_KMS_KEY_URI} \
--kerberos-root-principal-password-uri=${KERBEROS_PASSWORD_URI} \
--properties="dataproc:ranger.gcs.plugin.enable=true, \
dataproc:ranger.kms.key.uri=${RANGER_ADMIN_PASSWORD_KMS_KEY_URI}, \
dataproc:ranger.admin.password.uri=${RANGER_ADMIN_PASSWORD_GCS_URI}, \
dataproc:ranger.gcs.plugin.mysql.kms.key.uri=${RANGER_GCS_PLUGIN_MYSQL_KMS_KEY_URI}, \
dataproc:ranger.gcs.plugin.mysql.password.uri=${RANGER_GCS_PLUGIN_MYSQL_PASSWORD_URI}"
Observações:
- Versão da imagem 1.5:se você estiver criando um cluster da versão 1.5 da imagem (consulte Selecionar versões), adicione a flag
--metadata=GCS_CONNECTOR_VERSION="2.2.6" or higherpara instalar a versão necessária do conector.
Verificar a instalação do plug-in do Cloud Storage do Ranger
Depois que a criação do cluster for concluída, um tipo de serviço GCS, chamado gcs-dataproc, vai aparecer na interface da Web de administrador do Ranger.
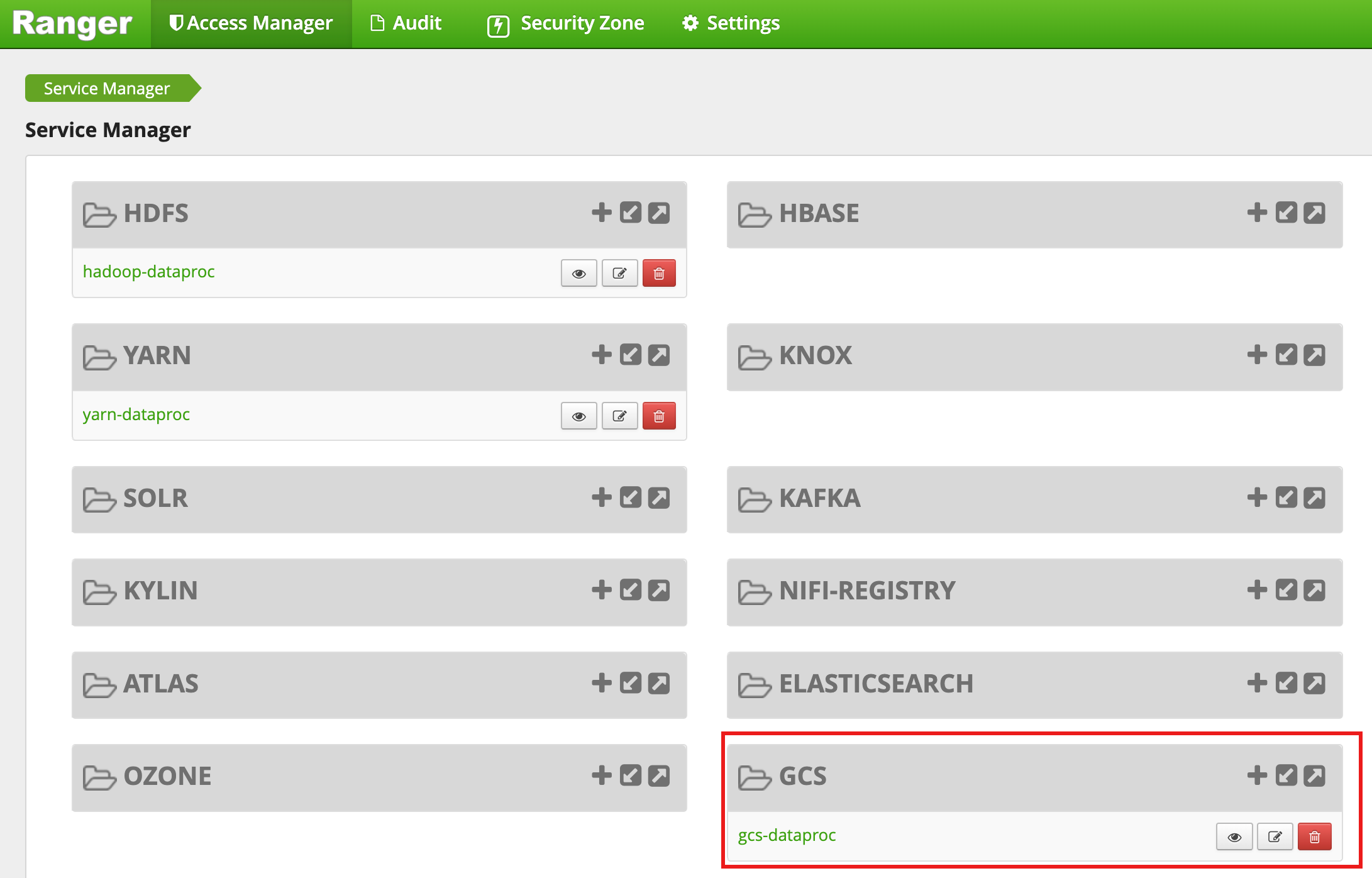
Políticas padrão do plug-in do Ranger Cloud Storage
O serviço gcs-dataproc padrão tem as seguintes políticas:
Políticas para ler e gravar nos buckets temporários e de preparo do cluster do Dataproc.
Uma política
all - bucket, object-path, que permite que todos os usuários acessem metadados de todos os objetos. Esse acesso é necessário para permitir que o conector do Cloud Storage execute operações do HCFS (Hadoop Compatible Filesystem).
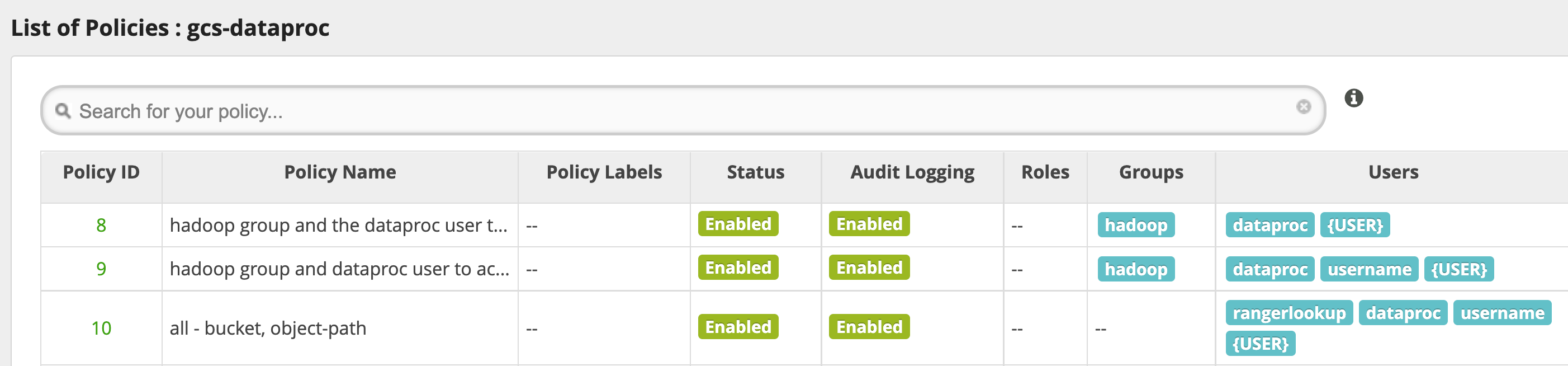
Dicas de uso
Acesso dos apps às pastas de bucket
Para acomodar apps que criam arquivos intermediários em um bucket do Cloud Storage,
conceda permissões Modify Objects, List Objects e Delete Objects
no caminho do bucket do Cloud Storage e selecione o modo
recursive para estender as permissões a subcaminhos no caminho especificado.
Medidas de proteção
Para evitar a violação do plug-in:
Conceda à conta de serviço da VM acesso aos recursos nos seus buckets do Cloud Storage para permitir que ela conceda acesso a esses recursos com tokens de acesso com escopo reduzido (consulte Permissões do IAM para o Cloud Storage). Além disso, remova o acesso dos usuários aos recursos do bucket para evitar o acesso direto.
Desative o
sudoe outros meios de acesso root nas VMs do cluster, incluindo a atualização do arquivosudoer, para evitar a representação ou mudanças nas configurações de autenticação e autorização. Para mais informações, consulte as instruções do Linux para adicionar/remover privilégios de usuário dosudo.Use
iptablepara bloquear solicitações de acesso direto ao Cloud Storage de VMs do cluster. Por exemplo, é possível bloquear o acesso ao servidor de metadados da VM para impedir o acesso à credencial da conta de serviço da VM ou ao token de acesso usado para autenticar e autorizar o acesso ao Cloud Storage. Consulteblock_vm_metadata_server.sh, um script de inicialização que usa regrasiptablepara bloquear o acesso ao servidor de metadados da VM.
Jobs do Spark, do Hive no MapReduce e do Hive no Tez
Para proteger detalhes sensíveis de autenticação do usuário e reduzir a carga no centro de distribuição de chaves (KDC), o driver do Spark não distribui credenciais do Kerberos para os executores. Em vez disso, o driver do Spark recebe um token de delegação do plug-in do Ranger Cloud Storage e o distribui para os executores. Os executores usam o token de delegação para autenticar o plug-in do Ranger Cloud Storage, trocando-o por um token de acesso do Google que permite o acesso ao Cloud Storage.
Os jobs do Hive no MapReduce e do Hive no Tez também usam tokens para acessar o Cloud Storage. Use as propriedades a seguir para receber tokens e acessar buckets especificados do Cloud Storage ao enviar os seguintes tipos de jobs:
Jobs do Spark:
--conf spark.yarn.access.hadoopFileSystems=gs://bucket-name,gs://bucket-name,...
Jobs do Hive no MapReduce:
--hiveconf "mapreduce.job.hdfs-servers=gs://bucket-name,gs://bucket-name,..."
Jobs do Hive no Tez:
--hiveconf "tez.job.fs-servers=gs://bucket-name,gs://bucket-name,..."
Cenário de job do Spark
Um job de contagem de palavras do Spark falha quando executado em uma janela de terminal em uma VM de cluster do Dataproc que tem o plug-in do Ranger Cloud Storage instalado.
spark-submit \
--conf spark.yarn.access.hadoopFileSystems=gs://${FILE_BUCKET} \
--class org.apache.spark.examples.JavaWordCount \
/usr/lib/spark/examples/jars/spark-examples.jar \
gs://bucket-name/wordcount.txt
Observações:
- FILE_BUCKET: bucket do Cloud Storage para acesso do Spark.
Saída de erro:
Caused by: com.google.gcs.ranger.client.shaded.io.grpc.StatusRuntimeException: PERMISSION_DENIED: Access denied by Ranger policy: User: '<USER>', Bucket: '<dataproc_temp_bucket>', Object Path: 'a97127cf-f543-40c3-9851-32f172acc53b/spark-job-history/', Action: 'LIST_OBJECTS'
Observações:
spark.yarn.access.hadoopFileSystems=gs://${FILE_BUCKET}é obrigatório em um ambiente compatível com Kerberos.
Saída de erro:
Caused by: java.lang.RuntimeException: Failed creating a SPNEGO token. Make sure that you have run `kinit` and that your Kerberos configuration is correct. See the full Kerberos error message: No valid credentials provided (Mechanism level: No valid credentials provided)
Uma política é editada usando o Gerenciador de acesso na interface da Web de administrador do Ranger
para adicionar username à lista de usuários que têm List Objects e outras permissões de bucket temp.
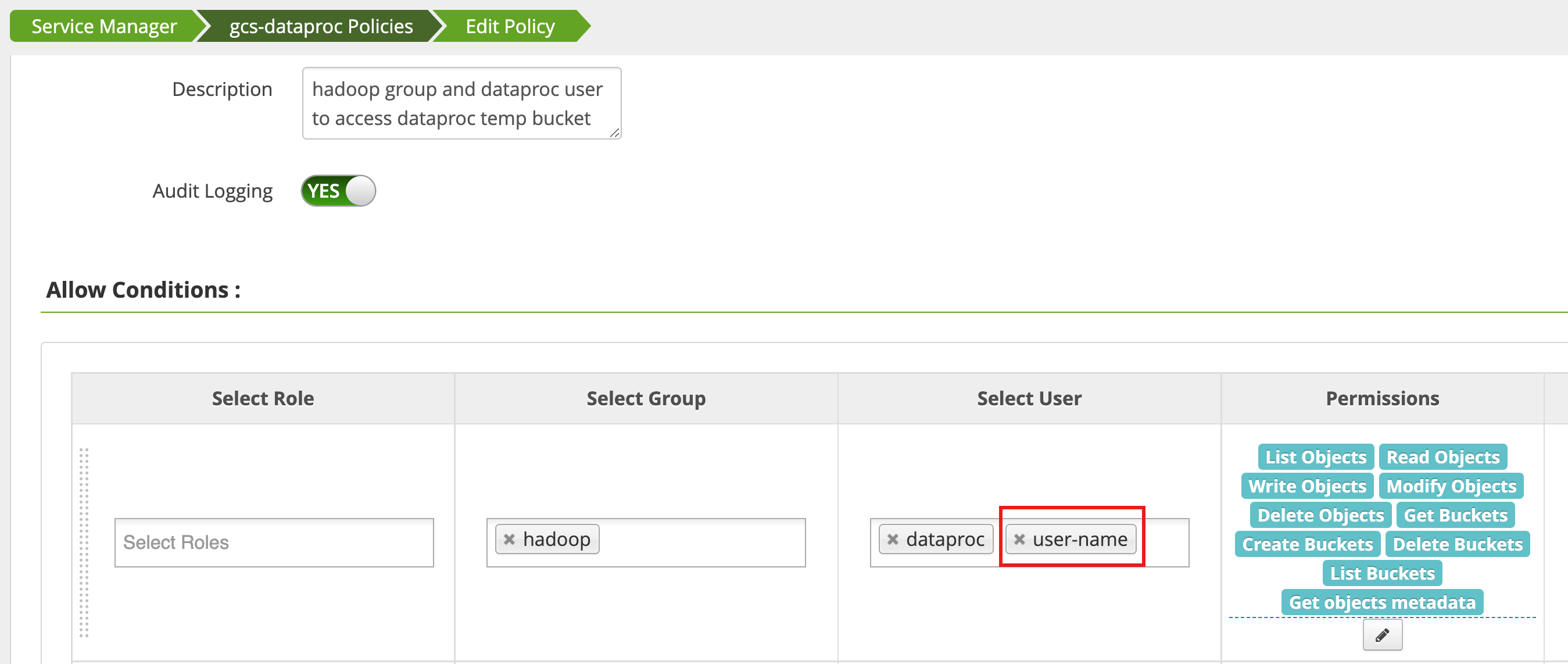
A execução do job gera um novo erro.
Saída de erro:
com.google.gcs.ranger.client.shaded.io.grpc.StatusRuntimeException: PERMISSION_DENIED: Access denied by Ranger policy: User: <USER>, Bucket: '<file-bucket>', Object Path: 'wordcount.txt', Action: 'READ_OBJECTS'
Uma política é adicionada para conceder ao usuário acesso de leitura ao caminho do Cloud Storage wordcount.text.
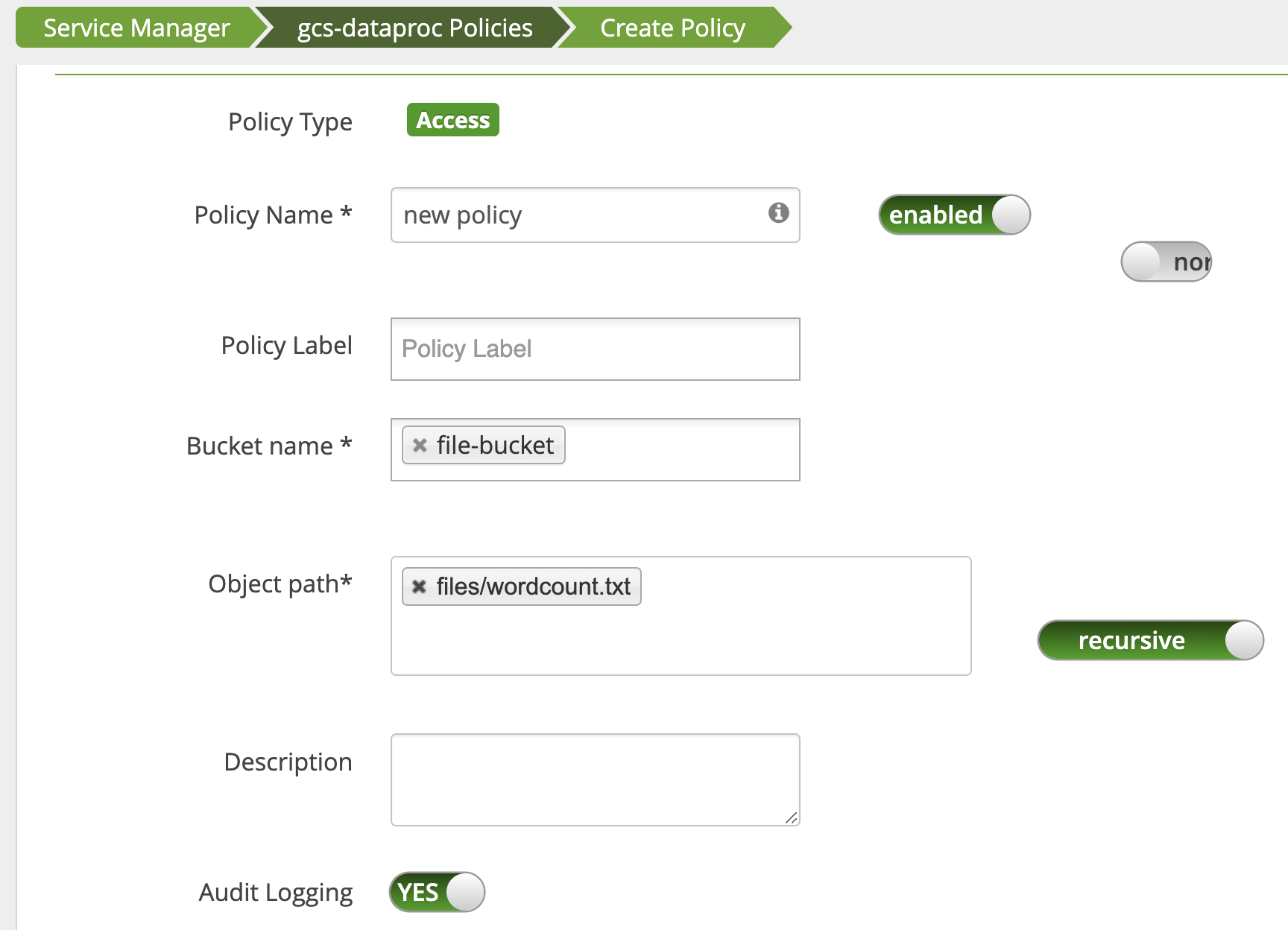
O job é executado e concluído.
INFO com.google.cloud.hadoop.fs.gcs.auth.GcsDelegationTokens: Using delegation token RangerGCSAuthorizationServerSessionToken owner=<USER>, renewer=yarn, realUser=, issueDate=1654116824281, maxDate=0, sequenceNumber=0, masterKeyId=0 this: 1 is: 1 a: 1 text: 1 file: 1 22/06/01 20:54:13 INFO org.sparkproject.jetty.server.AbstractConnector: Stopped