El complemento de Dataproc Ranger Cloud Storage, disponible en las versiones de imágenes 1.5 y 2.0 de Dataproc, activa un servicio de autorización en cada VM del clúster de Dataproc. El servicio de autorización evalúa las solicitudes del conector de Cloud Storage en función de las políticas de Ranger y, si se permite la solicitud, devuelve un token de acceso para la cuenta de servicio de la VM del clúster.
El complemento de Ranger Cloud Storage se basa en Kerberos para la autenticación y se integra con la compatibilidad del conector de Cloud Storage para los tokens de delegación. Los tokens de delegación se almacenan en una base de datos de MySQL en el nodo instancia principal del clúster. La contraseña raíz de la base de datos se especifica a través de las propiedades del clúster cuando creas el clúster de Dataproc.
Antes de comenzar
Otorga el rol de Creador de tokens de cuenta de servicio y el rol de Administrador de roles de IAM en la cuenta de servicio de VM de Dataproc de tu proyecto.
Instala el complemento de Ranger Cloud Storage
Ejecuta los siguientes comandos en una ventana de la terminal local o en Cloud Shell para instalar el complemento de Ranger Cloud Storage cuando crees un clúster de Dataproc.
Configure las variables de entorno
export CLUSTER_NAME=new-cluster-name \ export REGION=region \ export KERBEROS_KMS_KEY_URI=Kerberos-KMS-key-URI \ export KERBEROS_PASSWORD_URI=Kerberos-password-URI \ export RANGER_ADMIN_PASSWORD_KMS_KEY_URI=Ranger-admin-password-KMS-key-URI \ export RANGER_ADMIN_PASSWORD_GCS_URI=Ranger-admin-password-GCS-URI \ export RANGER_GCS_PLUGIN_MYSQL_KMS_KEY_URI=MySQL-root-password-KMS-key-URI \ export RANGER_GCS_PLUGIN_MYSQL_PASSWORD_URI=MySQL-root-password-GCS-URI
Notas:
- CLUSTER_NAME: Es el nombre del clúster nuevo.
- REGION: La región en la que se creará el clúster, por ejemplo,
us-west1. - KERBEROS_KMS_KEY_URI y KERBEROS_PASSWORD_URI: Consulta Configura tu contraseña principal de raíz de Kerberos.
- RANGER_ADMIN_PASSWORD_KMS_KEY_URI y RANGER_ADMIN_PASSWORD_GCS_URI: Consulta Configura tu contraseña de administrador de Ranger.
- RANGER_GCS_PLUGIN_MYSQL_KMS_KEY_URI y RANGER_GCS_PLUGIN_MYSQL_PASSWORD_URI: Configura una contraseña de MySQL siguiendo el mismo procedimiento que usaste para configurar una contraseña de administrador de Ranger.
Crea un clúster de Dataproc
Ejecuta el siguiente comando para crear un clúster de Dataproc y, luego, instalar el complemento de Ranger Cloud Storage en él.
gcloud dataproc clusters create ${CLUSTER_NAME} \
--region=${REGION} \
--scopes cloud-platform \
--enable-component-gateway \
--optional-components=SOLR,RANGER \
--kerberos-kms-key=${KERBEROS_KMS_KEY_URI} \
--kerberos-root-principal-password-uri=${KERBEROS_PASSWORD_URI} \
--properties="dataproc:ranger.gcs.plugin.enable=true, \
dataproc:ranger.kms.key.uri=${RANGER_ADMIN_PASSWORD_KMS_KEY_URI}, \
dataproc:ranger.admin.password.uri=${RANGER_ADMIN_PASSWORD_GCS_URI}, \
dataproc:ranger.gcs.plugin.mysql.kms.key.uri=${RANGER_GCS_PLUGIN_MYSQL_KMS_KEY_URI}, \
dataproc:ranger.gcs.plugin.mysql.password.uri=${RANGER_GCS_PLUGIN_MYSQL_PASSWORD_URI}"
Notas:
- Versión de imagen 1.5: Si creas un clúster con la versión de imagen 1.5 (consulta Cómo seleccionar versiones), agrega la marca
--metadata=GCS_CONNECTOR_VERSION="2.2.6" or higherpara instalar la versión del conector requerida.
Verifica la instalación del complemento de Ranger Cloud Storage
Una vez que se complete la creación del clúster, aparecerá un tipo de servicio GCS, llamadogcs-dataproc, en la interfaz web de administrador de Ranger.
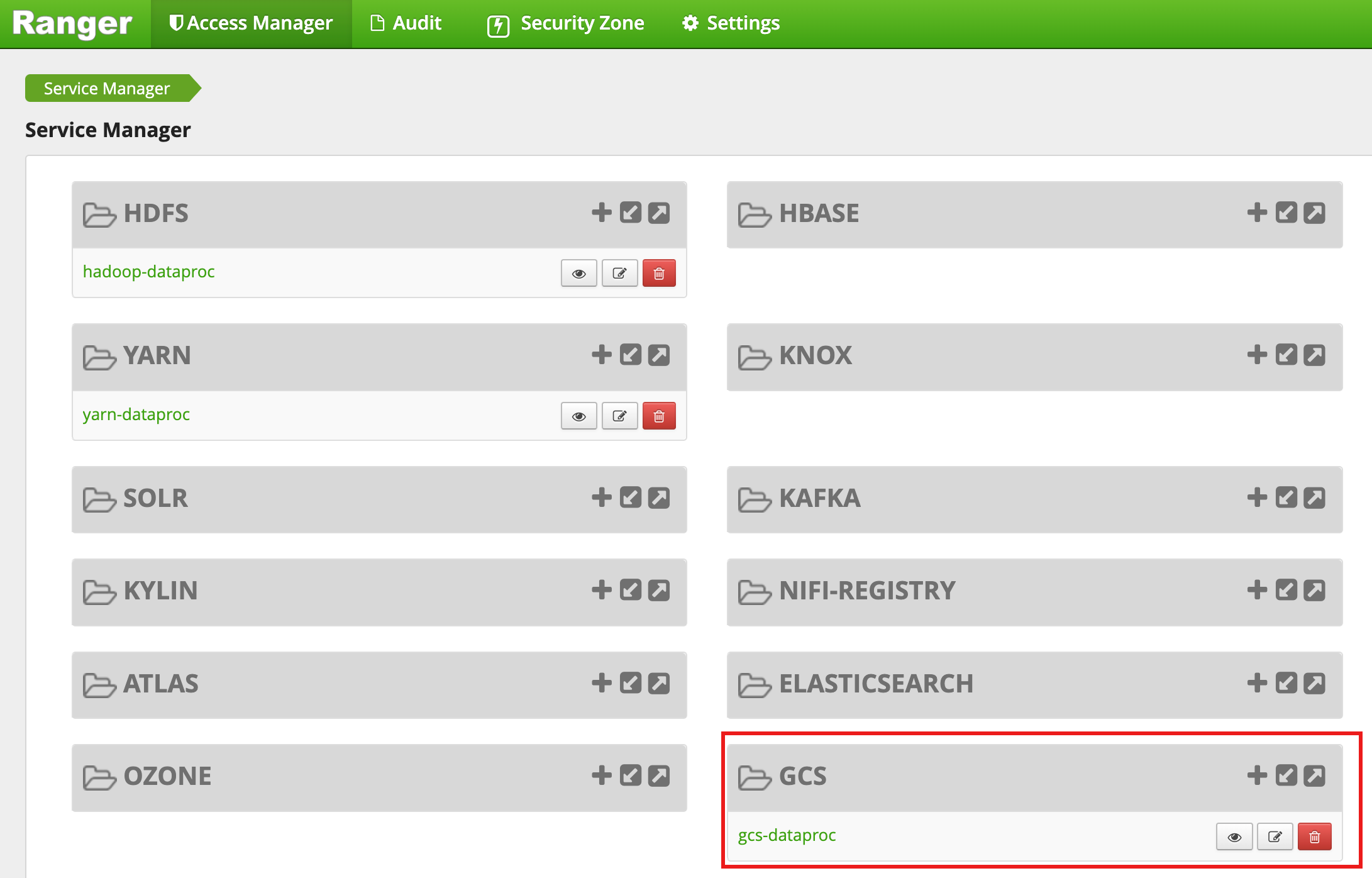
Políticas predeterminadas del complemento de Ranger Cloud Storage
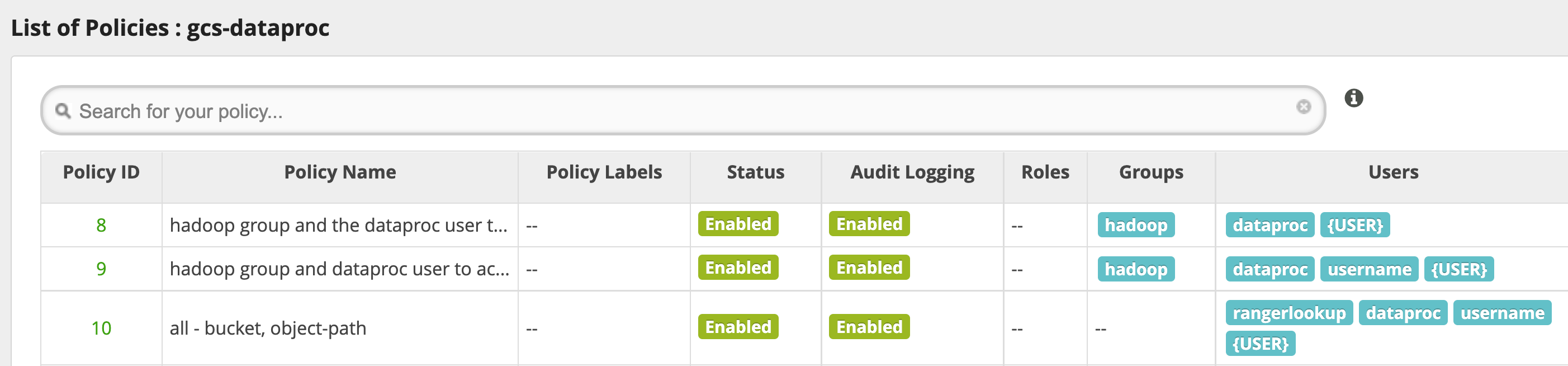
El servicio gcs-dataproc predeterminado tiene las siguientes políticas:
Políticas para leer y escribir en los buckets temporales y de etapa de pruebas del clúster de Dataproc
Una política de
all - bucket, object-path, que permite a todos los usuarios acceder a los metadatos de todos los objetos. Este acceso es necesario para permitir que el conector de Cloud Storage realice operaciones de HCFS (Hadoop Compatible Filesystem).
Sugerencias de uso
Acceso de la app a las carpetas del bucket
Para admitir apps que crean archivos intermedios en el bucket de Cloud Storage, puedes otorgar permisos de Modify Objects, List Objects y Delete Objects en la ruta del bucket de Cloud Storage y, luego, seleccionar el modo recursive para extender los permisos a las subrutas de la ruta especificada.

Medidas de protección
Para evitar la elusión del complemento, haz lo siguiente:
Otorga a la cuenta de servicio de VM acceso a los recursos de tus buckets de Cloud Storage para permitirle otorgar acceso a esos recursos con tokens de acceso con alcance reducido (consulta Permisos de IAM para Cloud Storage). Además, quita el acceso de los usuarios a los recursos del bucket para evitar que accedan directamente a él.
Inhabilita
sudoy otros medios de acceso raíz en las VMs del clúster, incluida la actualización del archivosudoer, para evitar la suplantación o los cambios en la configuración de autenticación y autorización. Para obtener más información, consulta las instrucciones para Linux sobre cómo agregar o quitar privilegios de usuario desudo.Usa
iptablepara bloquear las solicitudes de acceso directo a Cloud Storage desde las VMs del clúster. Por ejemplo, puedes bloquear el acceso al servidor de metadatos de la VM para evitar el acceso a la credencial de la cuenta de servicio de la VM o al token de acceso que se usa para autenticar y autorizar el acceso a Cloud Storage (consultablock_vm_metadata_server.sh, un script de inicialización que usa reglas deiptablepara bloquear el acceso al servidor de metadatos de la VM).
Trabajos de Spark, Hive-on-MapReduce y Hive-on-Tez
Para proteger los detalles sensibles de la autenticación del usuario y reducir la carga en el Centro de distribución de claves (KDC), el controlador de Spark no distribuye las credenciales de Kerberos a los ejecutores. En cambio, el controlador de Spark obtiene un token de delegación del complemento de Ranger Cloud Storage y, luego, lo distribuye a los ejecutores. Los ejecutores usan el token de delegación para autenticarse en el complemento de Ranger Cloud Storage y lo intercambian por un token de acceso de Google que permite el acceso a Cloud Storage.
Los trabajos de Hive-on-MapReduce y Hive-on-Tez también usan tokens para acceder a Cloud Storage. Usa las siguientes propiedades para obtener tokens y acceder a los buckets de Cloud Storage especificados cuando envíes los siguientes tipos de trabajos:
Trabajos de Spark:
--conf spark.yarn.access.hadoopFileSystems=gs://bucket-name,gs://bucket-name,...
Trabajos de Hive-on-MapReduce:
--hiveconf "mapreduce.job.hdfs-servers=gs://bucket-name,gs://bucket-name,..."
Trabajos de Hive en Tez:
--hiveconf "tez.job.fs-servers=gs://bucket-name,gs://bucket-name,..."
Situación de trabajo de Spark
Un trabajo de recuento de palabras de Spark falla cuando se ejecuta desde una ventana de terminal en una VM del clúster de Dataproc que tiene instalado el complemento de Ranger Cloud Storage.
spark-submit \
--conf spark.yarn.access.hadoopFileSystems=gs://${FILE_BUCKET} \
--class org.apache.spark.examples.JavaWordCount \
/usr/lib/spark/examples/jars/spark-examples.jar \
gs://bucket-name/wordcount.txt
Notas:
- FILE_BUCKET: Bucket de Cloud Storage para el acceso a Spark.
Resultado del error:
Caused by: com.google.gcs.ranger.client.shaded.io.grpc.StatusRuntimeException: PERMISSION_DENIED: Access denied by Ranger policy: User: '<USER>', Bucket: '<dataproc_temp_bucket>', Object Path: 'a97127cf-f543-40c3-9851-32f172acc53b/spark-job-history/', Action: 'LIST_OBJECTS'
Notas:
spark.yarn.access.hadoopFileSystems=gs://${FILE_BUCKET}es obligatorio en un entorno habilitado para Kerberos.
Resultado del error:
Caused by: java.lang.RuntimeException: Failed creating a SPNEGO token. Make sure that you have run `kinit` and that your Kerberos configuration is correct. See the full Kerberos error message: No valid credentials provided (Mechanism level: No valid credentials provided)
Una política se edita con el Administrador de acceso en la interfaz web de administrador de Ranger para agregar username a la lista de usuarios que tienen List Objects y otros permisos de bucket de temp.

La ejecución del trabajo genera un error nuevo.
Resultado del error:
com.google.gcs.ranger.client.shaded.io.grpc.StatusRuntimeException: PERMISSION_DENIED: Access denied by Ranger policy: User: <USER>, Bucket: '<file-bucket>', Object Path: 'wordcount.txt', Action: 'READ_OBJECTS'
Se agrega una política para otorgar al usuario acceso de lectura a la ruta de acceso de wordcount.text Cloud Storage.
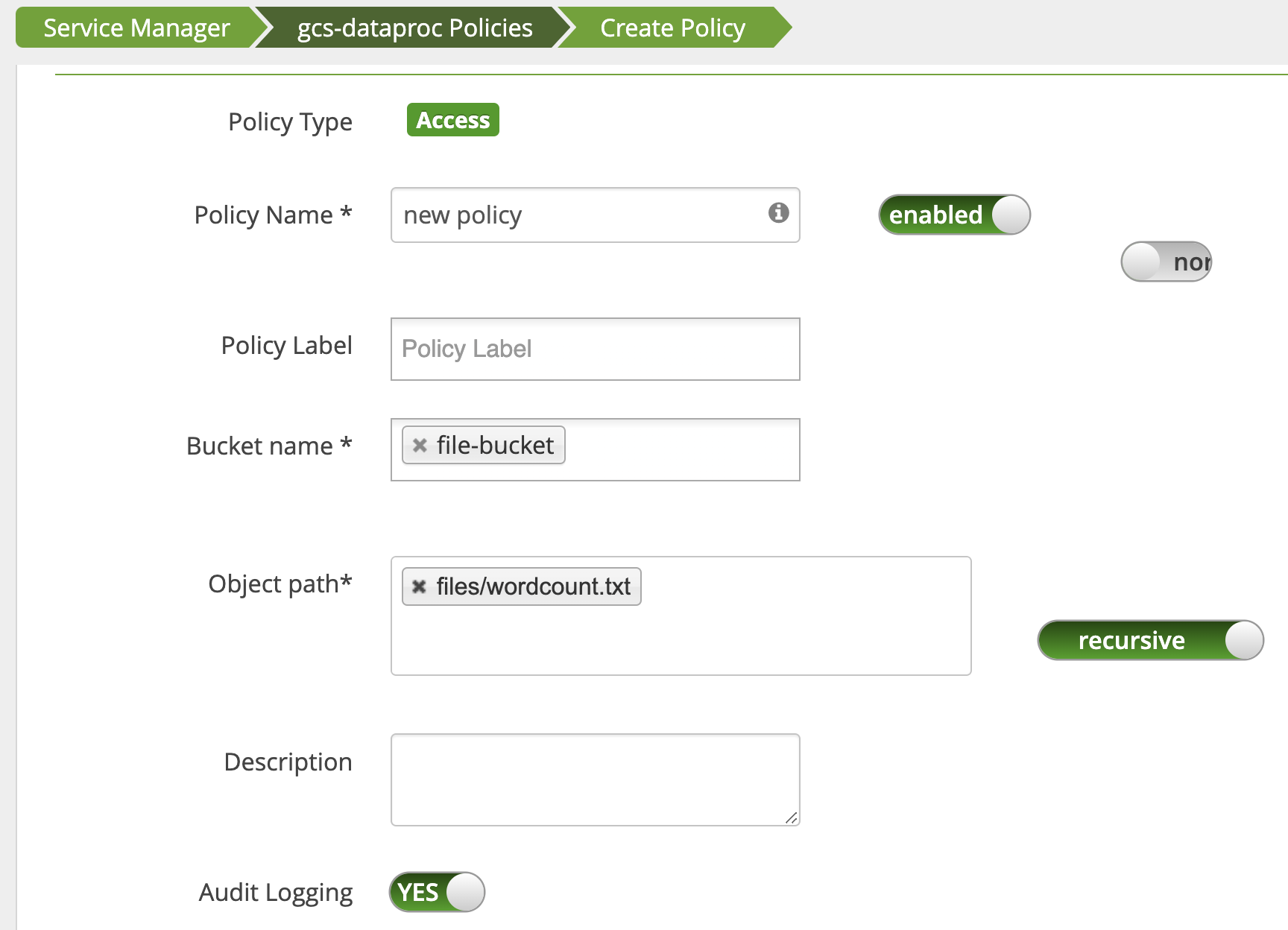
El trabajo se ejecuta y se completa correctamente.
INFO com.google.cloud.hadoop.fs.gcs.auth.GcsDelegationTokens: Using delegation token RangerGCSAuthorizationServerSessionToken owner=<USER>, renewer=yarn, realUser=, issueDate=1654116824281, maxDate=0, sequenceNumber=0, masterKeyId=0 this: 1 is: 1 a: 1 text: 1 file: 1 22/06/01 20:54:13 INFO org.sparkproject.jetty.server.AbstractConnector: Stopped