Os exemplos a seguir criam e usam um cluster do Dataproc ativado pelo Kerberos com os componentes Ranger e Solr para controlar o acesso de usuários aos recursos Hadoop, YARN e HIVE.
Observações:
A IU da Web do Ranger pode ser acessada com o Gateway de componentes.
Em um cluster do Ranger com Kerberos, o Dataproc mapeia um usuário do Kerberos para o usuário do sistema retirando o domínio e a instância do usuário do Kerberos. Por exemplo, o
user1/cluster-m@MY.REALMprincipal do Kerberos é mapeado para o sistemauser1, e as políticas Ranger são definidas para permitir ou negar permissões parauser1.
Crie o cluster.
- O comando
gclouda seguir pode ser executado em uma janela de terminal local ou no Cloud Shell de um projeto.gcloud dataproc clusters create cluster-name \ --region=region \ --optional-components=SOLR,RANGER \ --enable-component-gateway \ --properties="dataproc:ranger.kms.key.uri=projects/project-id/locations/global/keyRings/keyring/cryptoKeys/key,dataproc:ranger.admin.password.uri=gs://bucket/admin-password.encrypted" \ --kerberos-root-principal-password-uri=gs://bucket/kerberos-root-principal-password.encrypted \ --kerberos-kms-key=projects/project-id/locations/global/keyRings/keyring/cryptoKeys/key
- O comando
Depois que o cluster estiver em execução, navegue até a página Clusters do Dataproc no console do Google Cloud e selecione o nome do cluster para abrir a página Detalhes do cluster. Clique na guia Interfaces da Web para exibir uma lista de links do Gateway de componentes para as interfaces da Web dos componentes padrão e opcionais instalados no cluster. Clique no link do Ranger
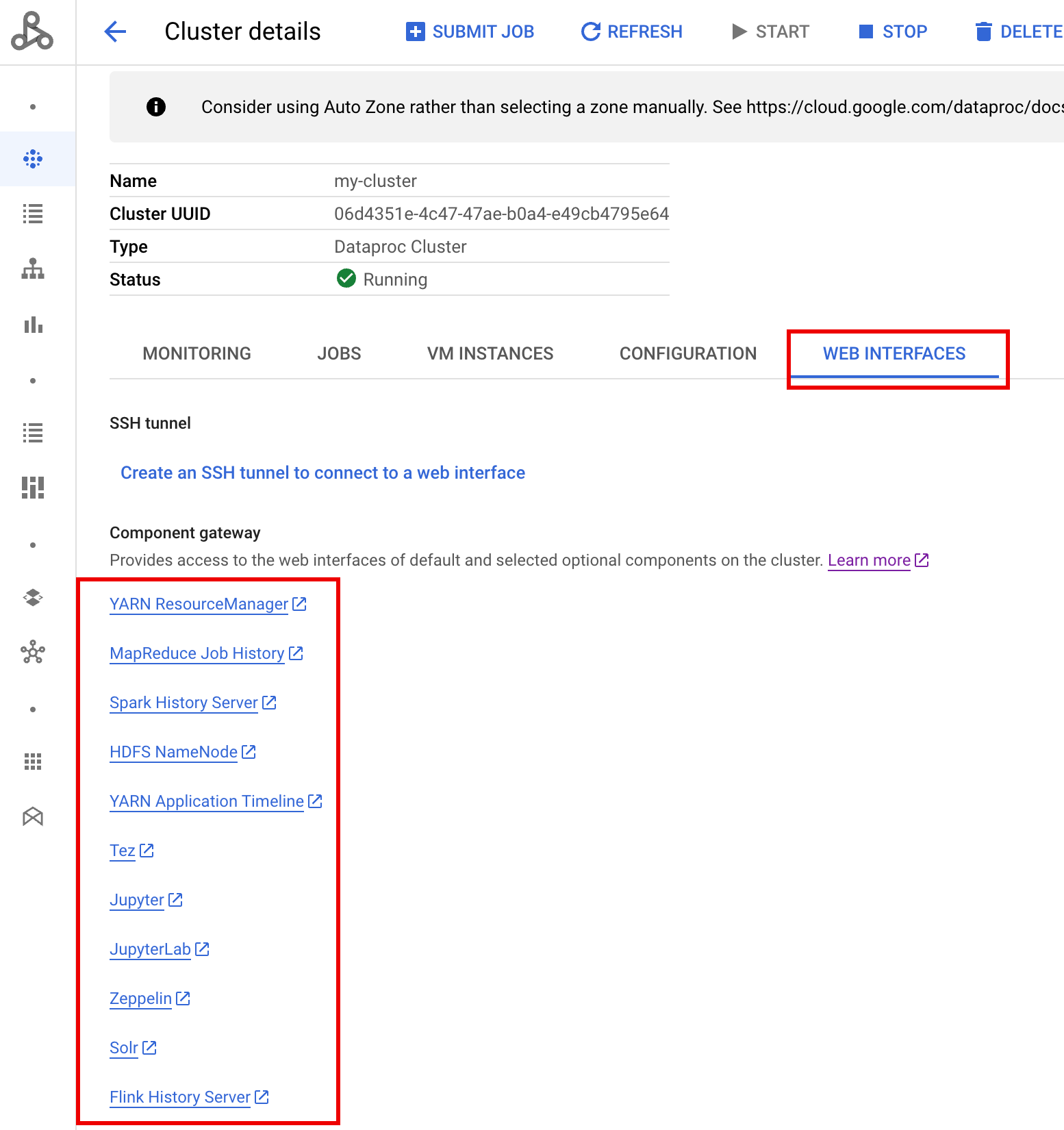
Faça login no Ranger digitando o nome de usuário "admin" e a senha.
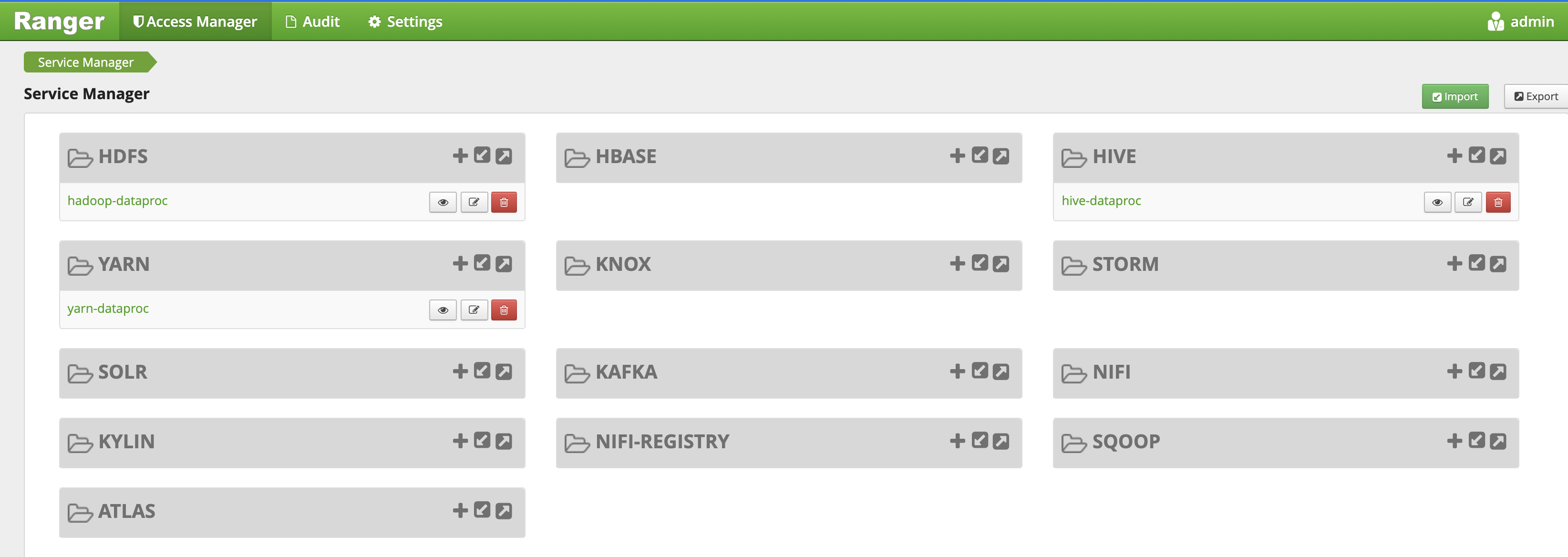
A UI do administrador do Ranger é aberta em um navegador local.
Política de acesso ao YARN
Este exemplo cria uma política do Ranger para permitir e negar acesso do usuário à fila YARN root.default.
Selecione
yarn-dataprocna interface do administrador do Ranger.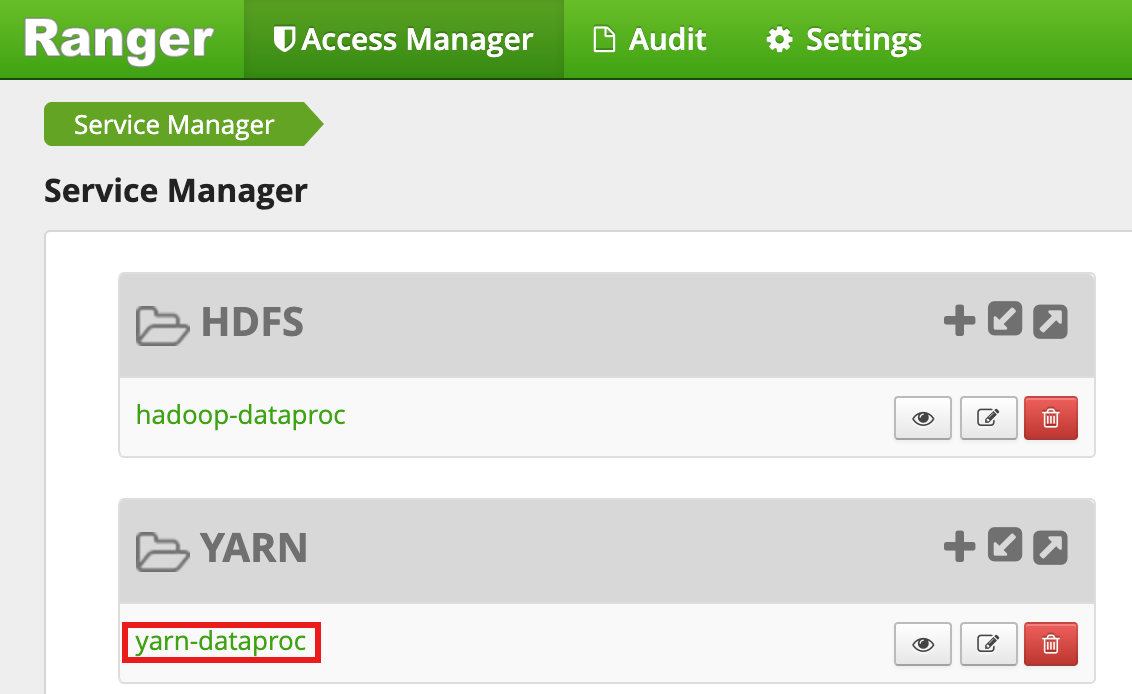
Na página Políticas yinc-dataproc, clique em Adicionar nova política. Na página Criar política, os seguintes campos são inseridos ou selecionados:
Policy Name: "yarn-policy-1"Queue: "root.default"Audit Logging: "Sim"Allow Conditions:Select User: "userone"Permissions: "Selecionar tudo" para conceder todas as permissões
Deny Conditions:Select User: "usertwo"Permissions: "Selecionar tudo" para negar todas as permissões
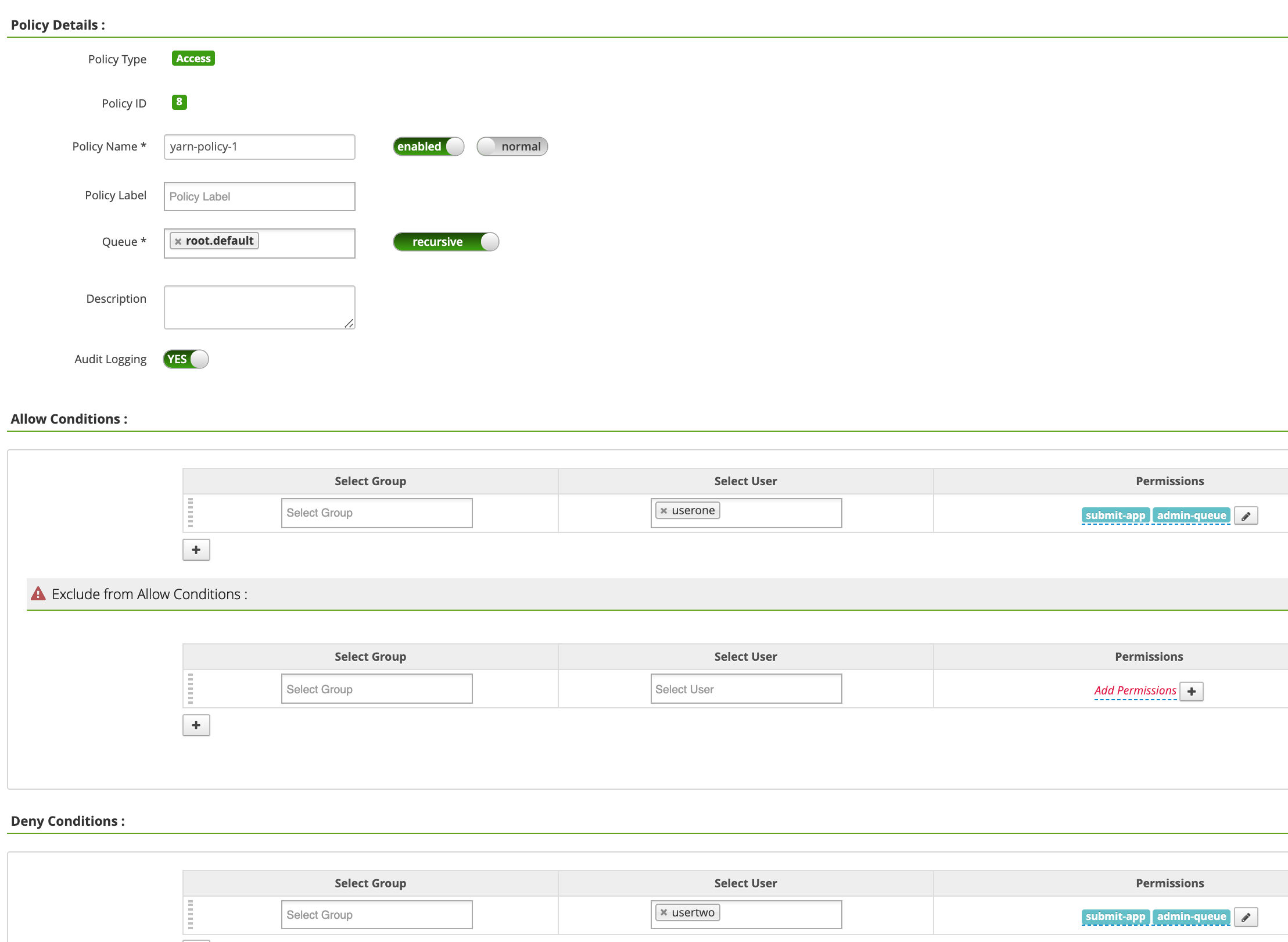
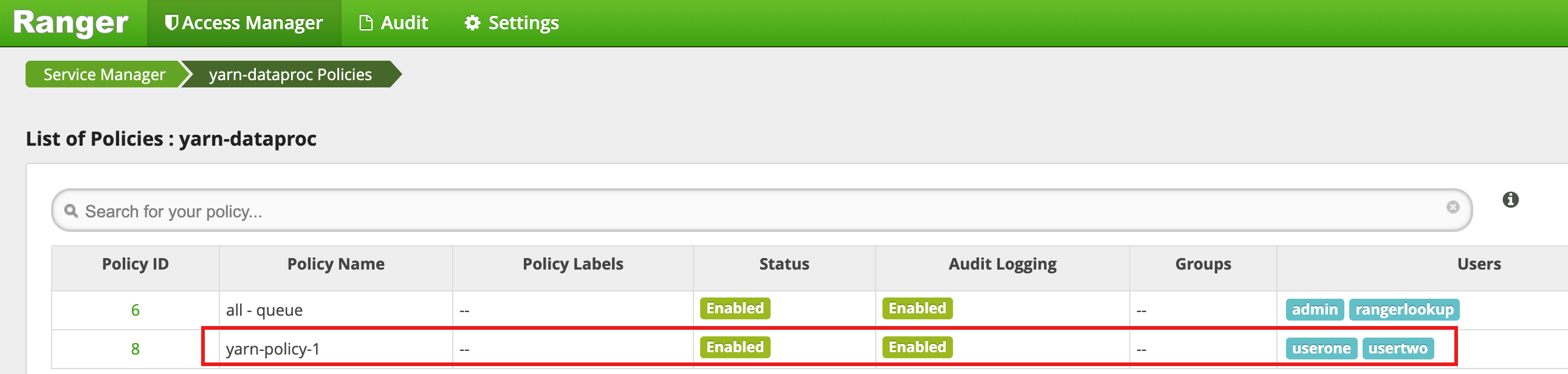
Clique em Adicionar para salvar a política. A política está listada na página Políticas yarn-dataproc:
Execute um job mapreduce do Hadoop na janela da sessão SSH mestre como userone:
userone@example-cluster-m:~$ hadoop jar /usr/lib/hadoop-mapreduce/hadoop-mapreduced-examples. jar pi 5 10
- A interface do Ranger mostra que
useronerecebeu permissão para enviar o job.
- A interface do Ranger mostra que
Execute o job MapReduce do Hadoop na janela de sessão SSH do mestre da VM como
usertwo:usertwo@example-cluster-m:~$ hadoop jar /usr/lib/hadoop-mapreduce/hadoop-mapreduced-examples. jar pi 5 10
- A interface do Ranger mostra que
usertwonão teve o acesso para enviar o job.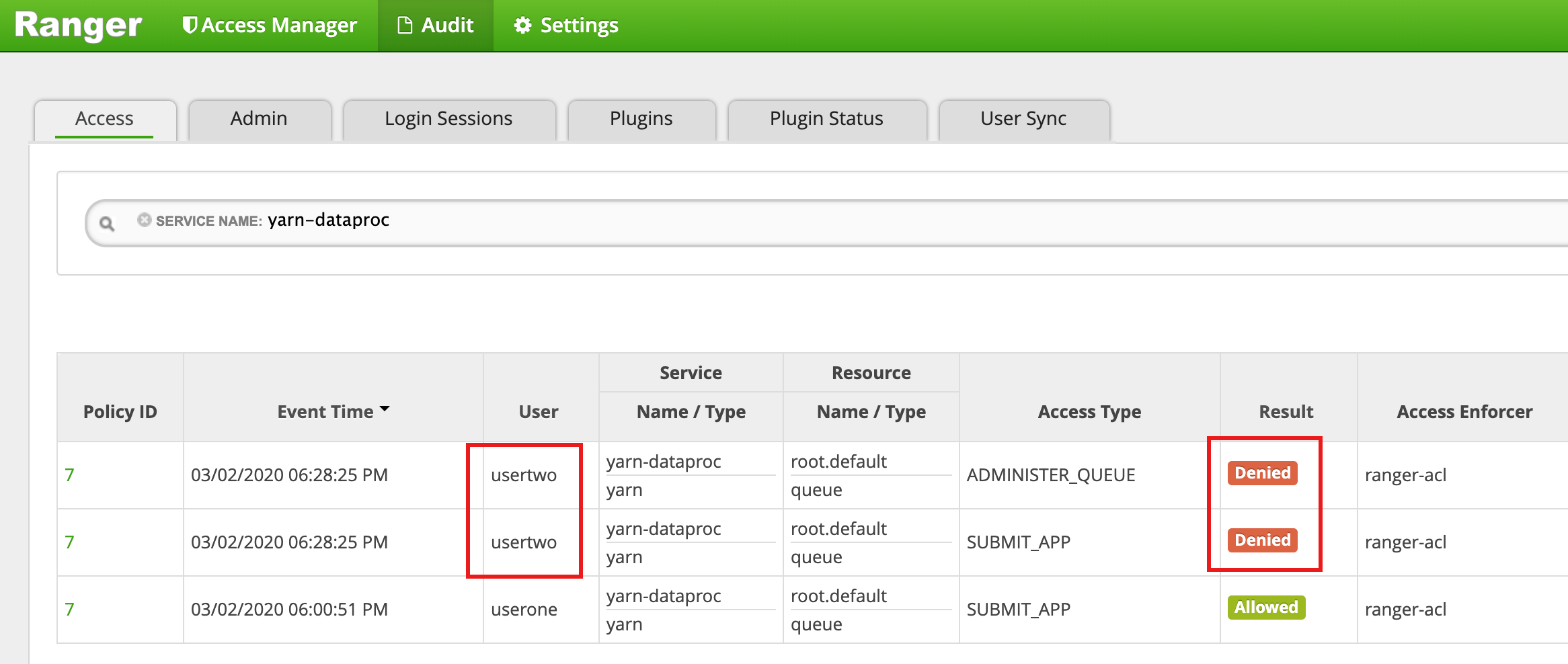
- A interface do Ranger mostra que
Política de acesso ao HDFS
Este exemplo cria uma política do Ranger para permitir e negar o acesso do usuário ao diretório /tmp do HDFS.
Selecione
hadoop-dataprocna interface do administrador do Ranger.
Na página Políticas hadoop-dataproc, clique em Adicionar nova política. Na página Criar política, os seguintes campos são inseridos ou selecionados:
Policy Name: "hadoop-policy-1"Resource Path: "/tmp"Audit Logging: "Sim"Allow Conditions:Select User: "userone"Permissions: "Selecionar tudo" para conceder todas as permissões
Deny Conditions:Select User: "usertwo"Permissions: "Selecionar tudo" para negar todas as permissões
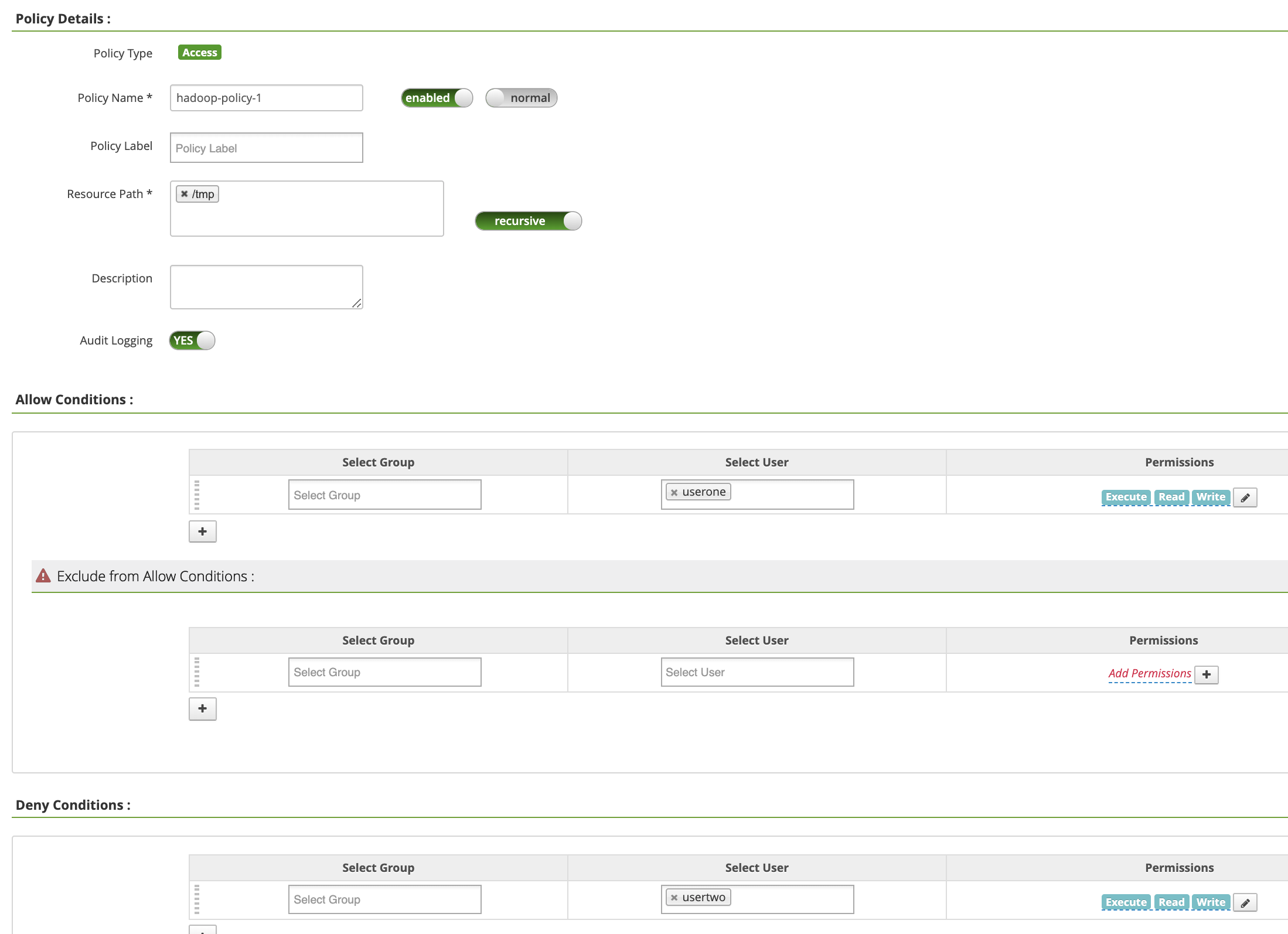
Clique em Adicionar para salvar a política. A política está listada na página Políticas hadoop-dataproc:
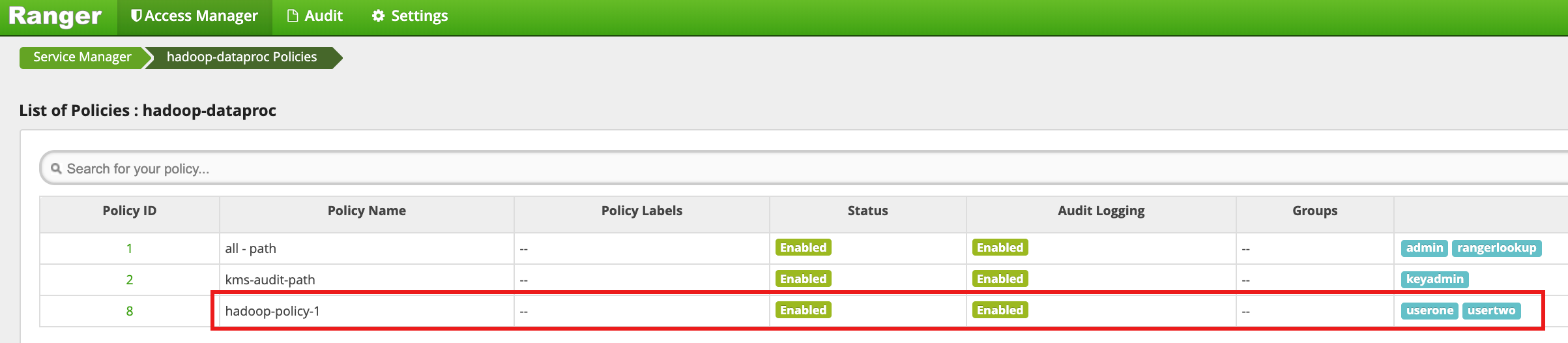
Acesse o diretório
/tmpdo HDFS como userone:userone@example-cluster-m:~$ hadoop fs -ls /tmp
- A interface do Ranger mostra que
useronerecebeu permissão para acessar o diretório /tmp do HDFS.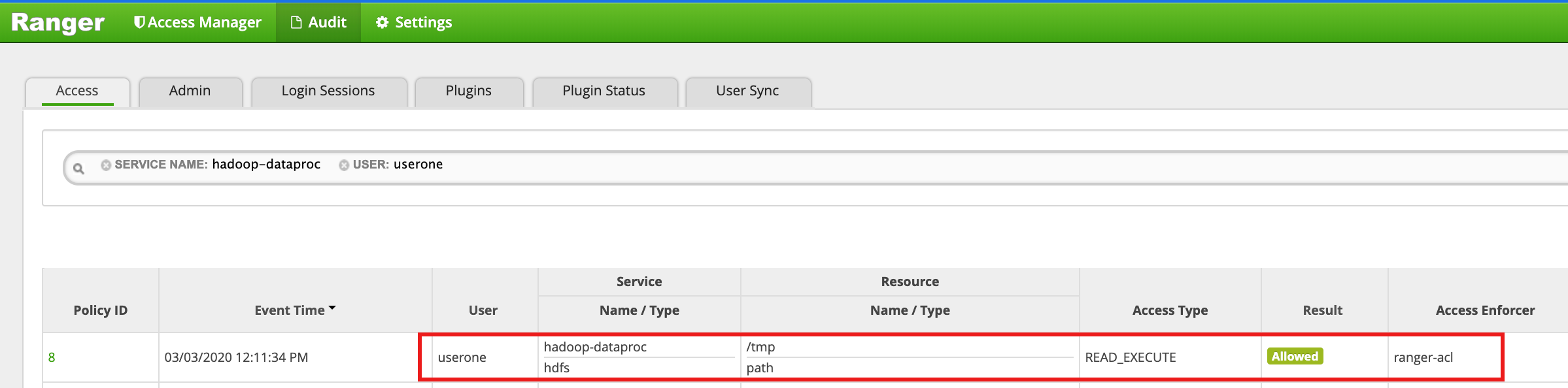
- A interface do Ranger mostra que
Acesse o diretório
/tmpdo HDFS comousertwo:usertwo@example-cluster-m:~$ hadoop fs -ls /tmp
- A interface do Ranger mostra que
usertwonão teve acesso ao diretório HDFS /tmp.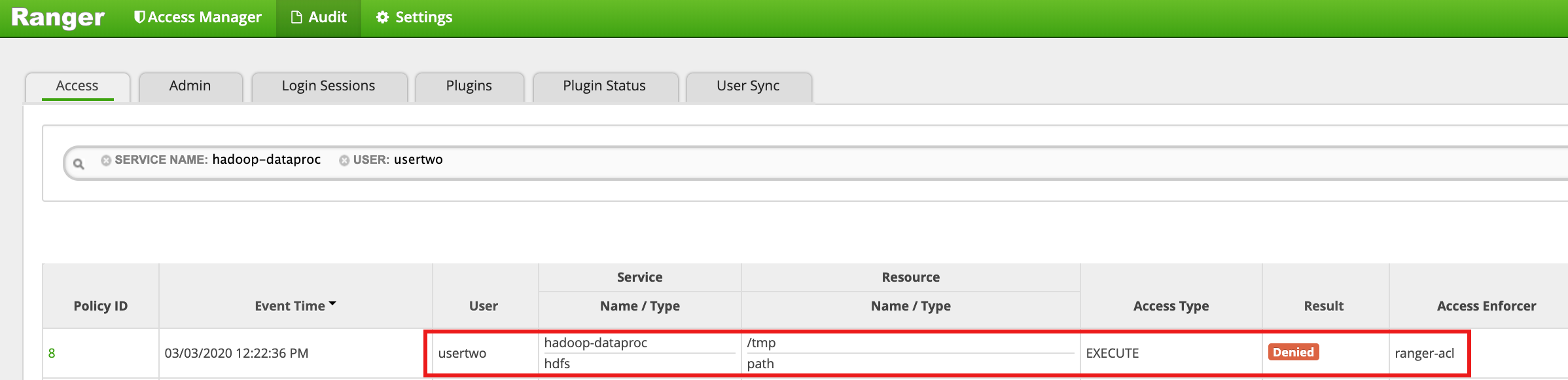
- A interface do Ranger mostra que
Política de acesso ao Hive
Este exemplo cria uma política do Ranger para permitir e negar acesso do usuário a uma tabela do Hive.
Crie uma pequena tabela
employeeusando a CLI do Hive na instância mestre.hive> CREATE TABLE IF NOT EXISTS employee (eid int, name String); INSERT INTO employee VALUES (1 , 'bob') , (2 , 'alice'), (3 , 'john');
Selecione
hive-dataprocna interface do administrador do Ranger.
Na página Políticas hive-dataproc, clique em Adicionar nova política. Na página Criar política, os seguintes campos são inseridos ou selecionados:
Policy Name: "hive-policy-1"database: "padrão"table: "funcionário"Hive Column: "*"Audit Logging: "Sim"Allow Conditions:Select User: "userone"Permissions: "Selecionar tudo" para conceder todas as permissões
Deny Conditions:Select User: "usertwo"Permissions: "Selecionar tudo" para negar todas as permissões
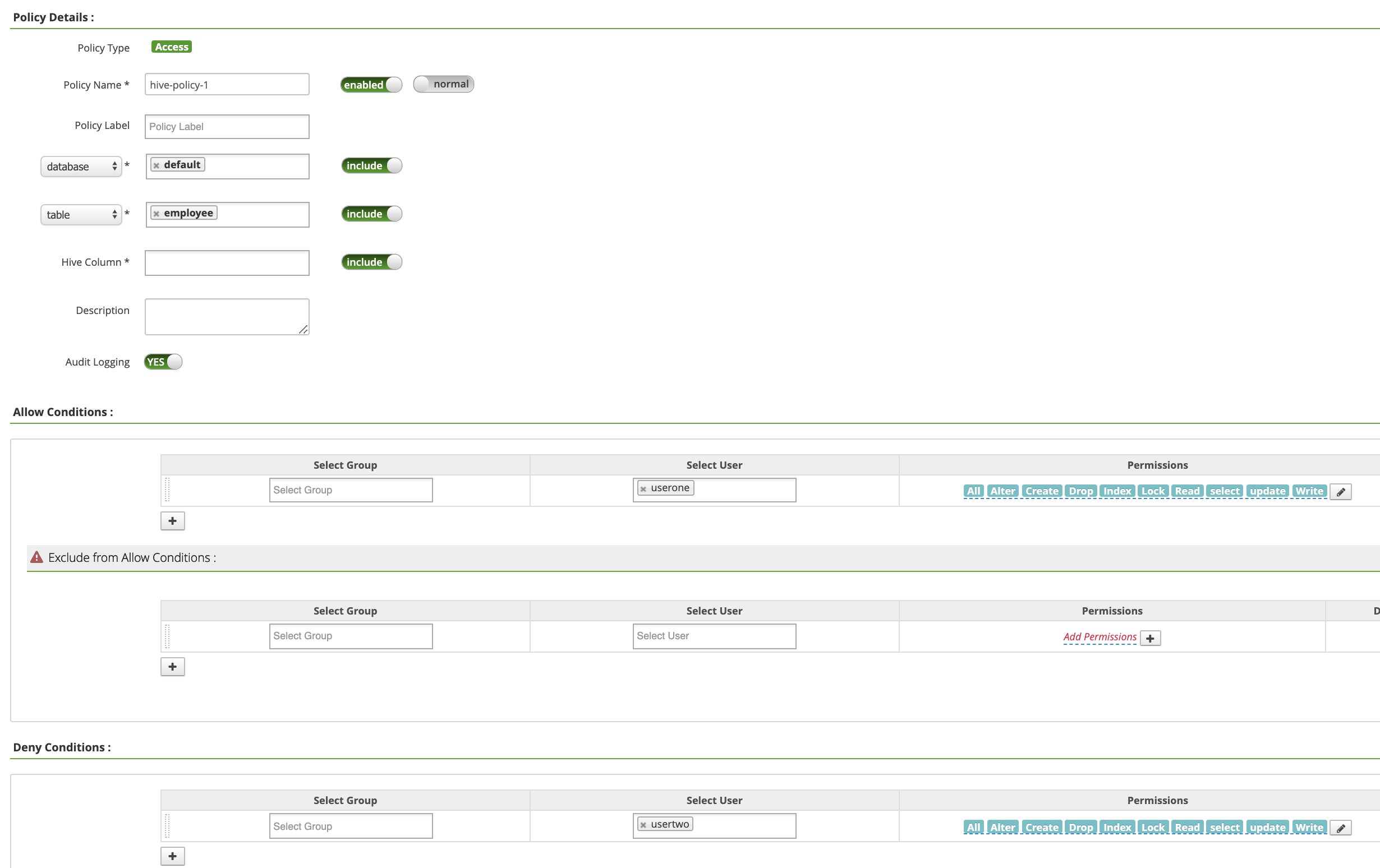
Clique em Adicionar para salvar a política. A política está listada na página Políticas hive-dataproc:
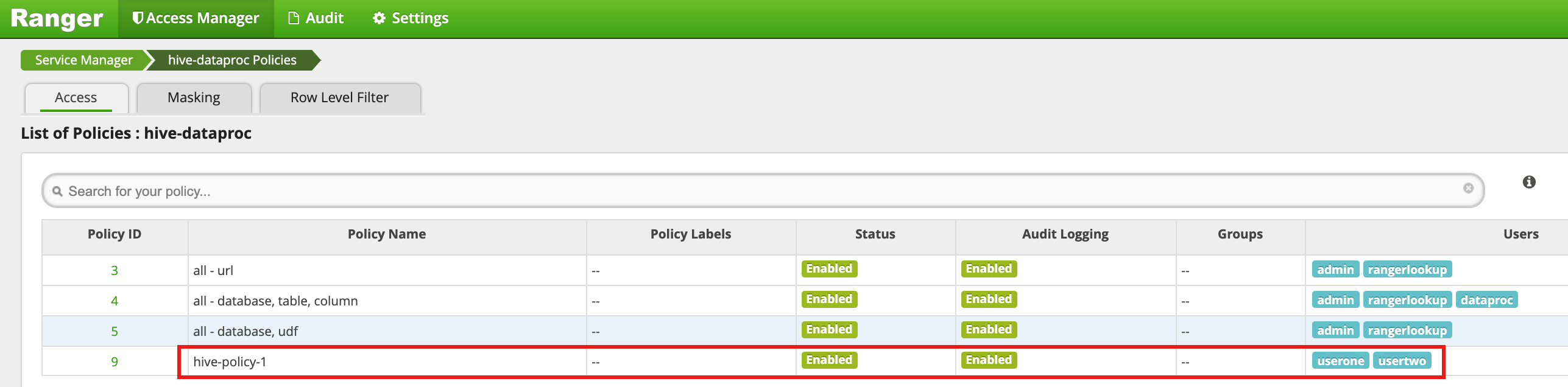
Execute uma consulta da sessão SSH do mestre da VM na tabela de funcionários do Hive como userone:
userone@example-cluster-m:~$ beeline -u "jdbc:hive2://$(hostname -f):10000/default;principal=hive/$(hostname -f)@REALM" -e "select * from employee;"
- A consulta userone é bem-sucedida:
Connected to: Apache Hive (version 2.3.6) Driver: Hive JDBC (version 2.3.6) Transaction isolation: TRANSACTION_REPEATABLE_READ +---------------+----------------+ | employee.eid | employee.name | +---------------+----------------+ | 1 | bob | | 2 | alice | | 3 | john | +---------------+----------------+ 3 rows selected (2.033 seconds)
- A consulta userone é bem-sucedida:
Execute uma consulta da sessão SSH do mestre da VM na tabela de funcionários do Hive como usertwo:
usertwo@example-cluster-m:~$ beeline -u "jdbc:hive2://$(hostname -f):10000/default;principal=hive/$(hostname -f)@REALM" -e "select * from employee;"
- O usuáriotwo tem acesso negado à tabela:
Error: Could not open client transport with JDBC Uri: ... Permission denied: user=usertwo, access=EXECUTE, inode="/tmp/hive"
- O usuáriotwo tem acesso negado à tabela:
Acesso refinado ao Hive
O Ranger é compatível com filtros de máscara e no nível da linha no Hive. Este exemplo se baseia no hive-policy-1 anterior adicionando políticas de mascaramento e filtro.
Selecione
hive-dataprocna interface do administrador do Ranger, selecione a guia Masking e clique em Add New Policy.
Na página Criar política, os seguintes campos são inseridos ou selecionados para criar uma política para mascarar (esconder) a coluna de nome do funcionário:
Policy Name: "política de mascaramento do Hive"database: "padrão"table: "funcionário"Hive Column: "nome"Audit Logging: "Sim"Mask Conditions:Select User: "userone"Access Types: "selecione" adicionar/editar permissõesSelect Masking Option: "anular"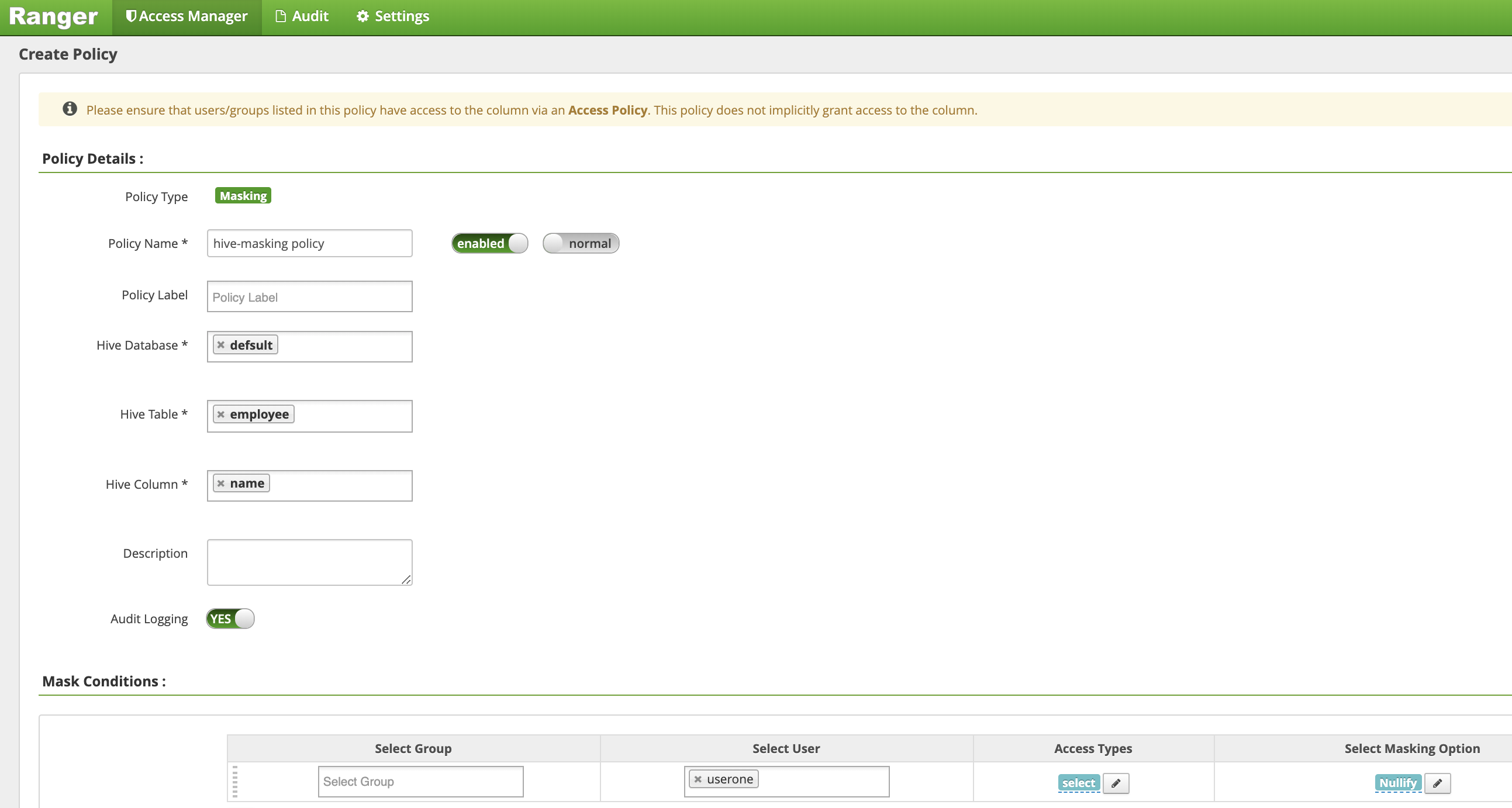
Clique em Adicionar para salvar a política.
Selecione
hive-dataprocna interface do administrador do Ranger, selecione a guia Row Level Filter e clique em Add New Policy.
Na página Criar política, os seguintes campos são inseridos ou selecionados para criar uma política para filtrar (retornar) linhas em que
eidnão é igual a1:Policy Name: "política de filtro do hive"Hive Database: "padrão"Hive Table: "funcionário"Audit Logging: "Sim"Mask Conditions:Select User: "userone"Access Types: "selecione" adicionar/editar permissõesRow Level Filter: expressão de filtro "eid != 1"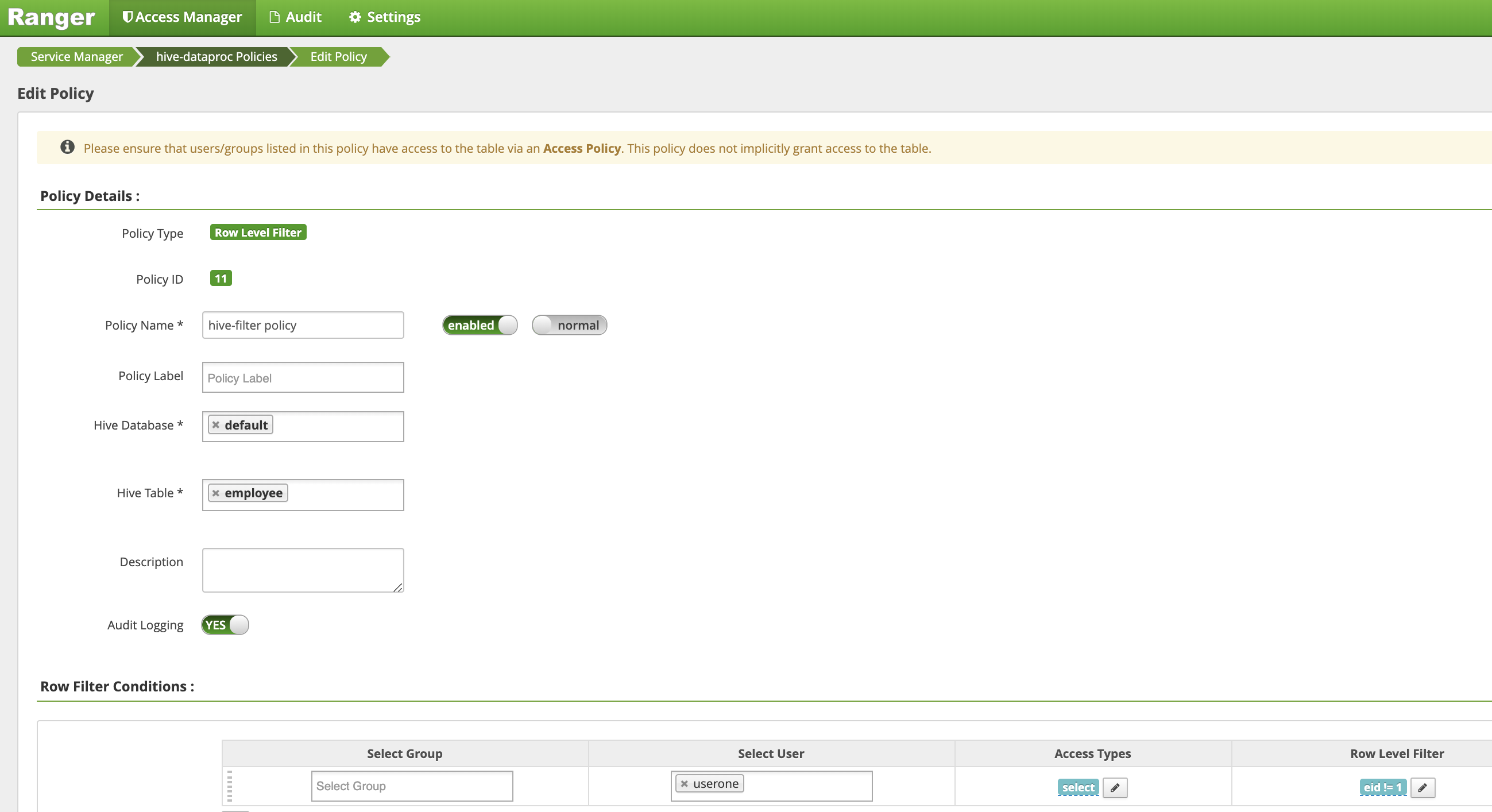
Clique em Adicionar para salvar a política.
Repita a consulta anterior da sessão SSH do mestre da VM na tabela de funcionários do Hive como userone:
userone@example-cluster-m:~$ beeline -u "jdbc:hive2://$(hostname -f):10000/default;principal=hive/$(hostname -f)@REALM" -e "select * from employee;"
- A consulta retorna com a coluna de nome mascarada e bob (eid=1) filtrada dos resultados:
Transaction isolation: TRANSACTION_REPEATABLE_READ +---------------+----------------+ | employee.eid | employee.name | +---------------+----------------+ | 2 | NULL | | 3 | NULL | +---------------+----------------+ 2 rows selected (0.47 seconds)
- A consulta retorna com a coluna de nome mascarada e bob (eid=1) filtrada dos resultados: