다음 예시에서는 Ranger 및 Solr 구성요소가 있는 Kerberos 사용 설정 Dataproc 클러스터를 만들고 사용하여 Hadoop, YARN, HIVE 리소스에 대한 사용자의 액세스를 제어합니다.
참고:
Ranger 웹 UI는 구성요소 게이트웨이를 통해 액세스할 수 있습니다.
Kerberos와 Ranger 클러스터에서 Dataproc은 Kerberos 사용자의 영역과 인스턴스를 제거하여 Kerberos 사용자를 시스템 사용자에 매핑합니다. 예를 들어 Kerberos 주 구성원
user1/cluster-m@MY.REALM은 시스템user1에 매핑되고 Ranger 정책은user1에 대한 권한을 허용하거나 거부하도록 정의됩니다.
클러스터를 만듭니다.
- 다음
gcloud명령어는 로컬 터미널 창이나 프로젝트의 Cloud Shell에서 실행할 수 있습니다.gcloud dataproc clusters create cluster-name \ --region=region \ --optional-components=SOLR,RANGER \ --enable-component-gateway \ --properties="dataproc:ranger.kms.key.uri=projects/project-id/locations/global/keyRings/keyring/cryptoKeys/key,dataproc:ranger.admin.password.uri=gs://bucket/admin-password.encrypted" \ --kerberos-root-principal-password-uri=gs://bucket/kerberos-root-principal-password.encrypted \ --kerberos-kms-key=projects/project-id/locations/global/keyRings/keyring/cryptoKeys/key
- 다음
클러스터가 실행된 후 Google Cloud 콘솔에서 Dataproc 클러스터 페이지로 이동한 다음 클러스터 이름을 선택하여 클러스터 세부정보 페이지를 엽니다. 웹 인터페이스 탭을 클릭하여 클러스터에 설치된 기본 및 선택적 구성요소의 웹 인터페이스에 구성요소 게이트웨이 링크 목록을 표시합니다. Ranger 링크를 클릭합니다.
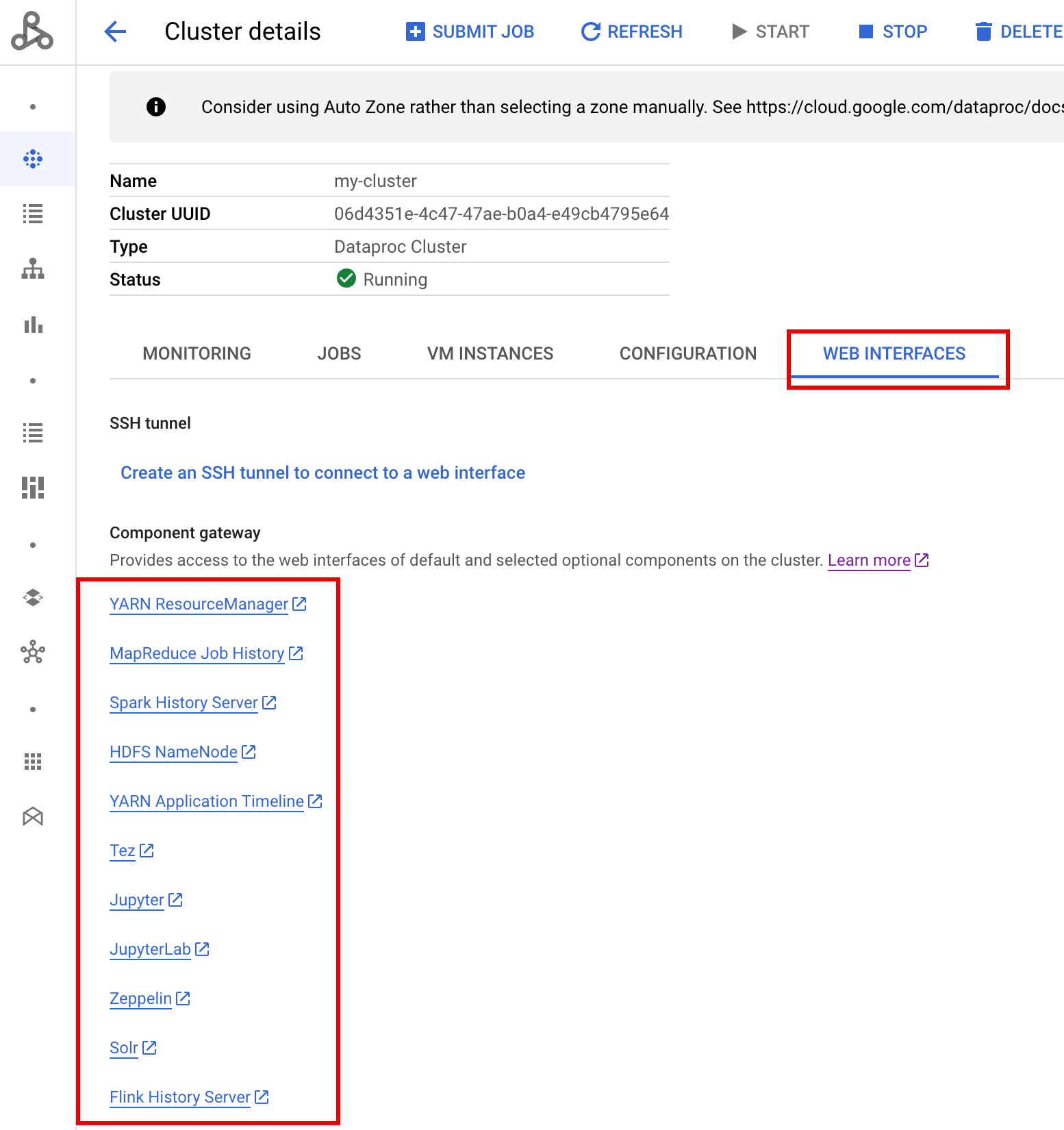
'관리' 사용자 이름과 Ranger 관리 비밀번호를 입력하여 Ranger에 로그인합니다.

Ranger 관리 UI가 로컬 브라우저에서 열립니다.
YARN 액세스 정책
이 예시에서는 YARN 루트.기본 큐에 대한 사용자 액세스를 허용하고 거부하는 Ranger 정책을 만듭니다.
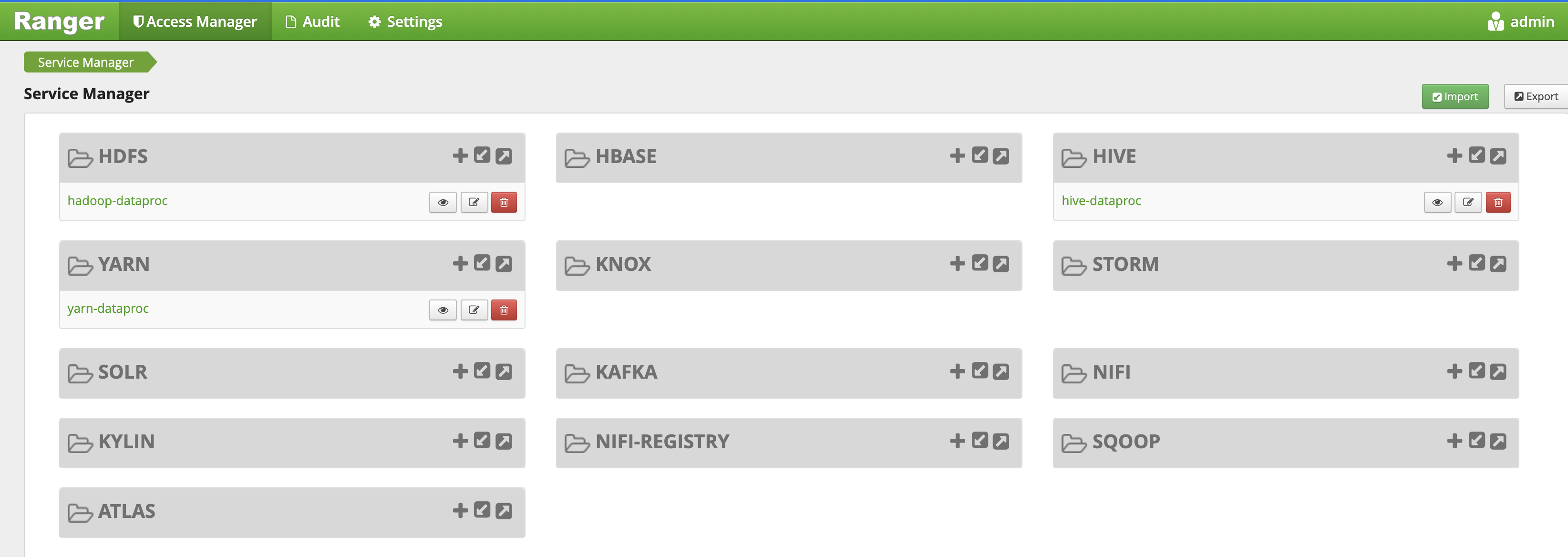
Ranger 관리 UI에서
yarn-dataproc를 선택합니다.
yarn-dataproc 정책 페이지에서 새 정책 추가를 클릭합니다. 정책 만들기 페이지에서 다음 필드를 입력하거나 선택합니다.
Policy Name: 'yarn-policy-1'Queue: "root.default"Audit Logging: '예'Allow Conditions:Select User: '사용자1'Permissions: 모든 권한을 부여하려면 '모두 선택'
Deny Conditions:Select User: '사용자2'Permissions: 모든 권한을 거부하려면 '모두 선택'
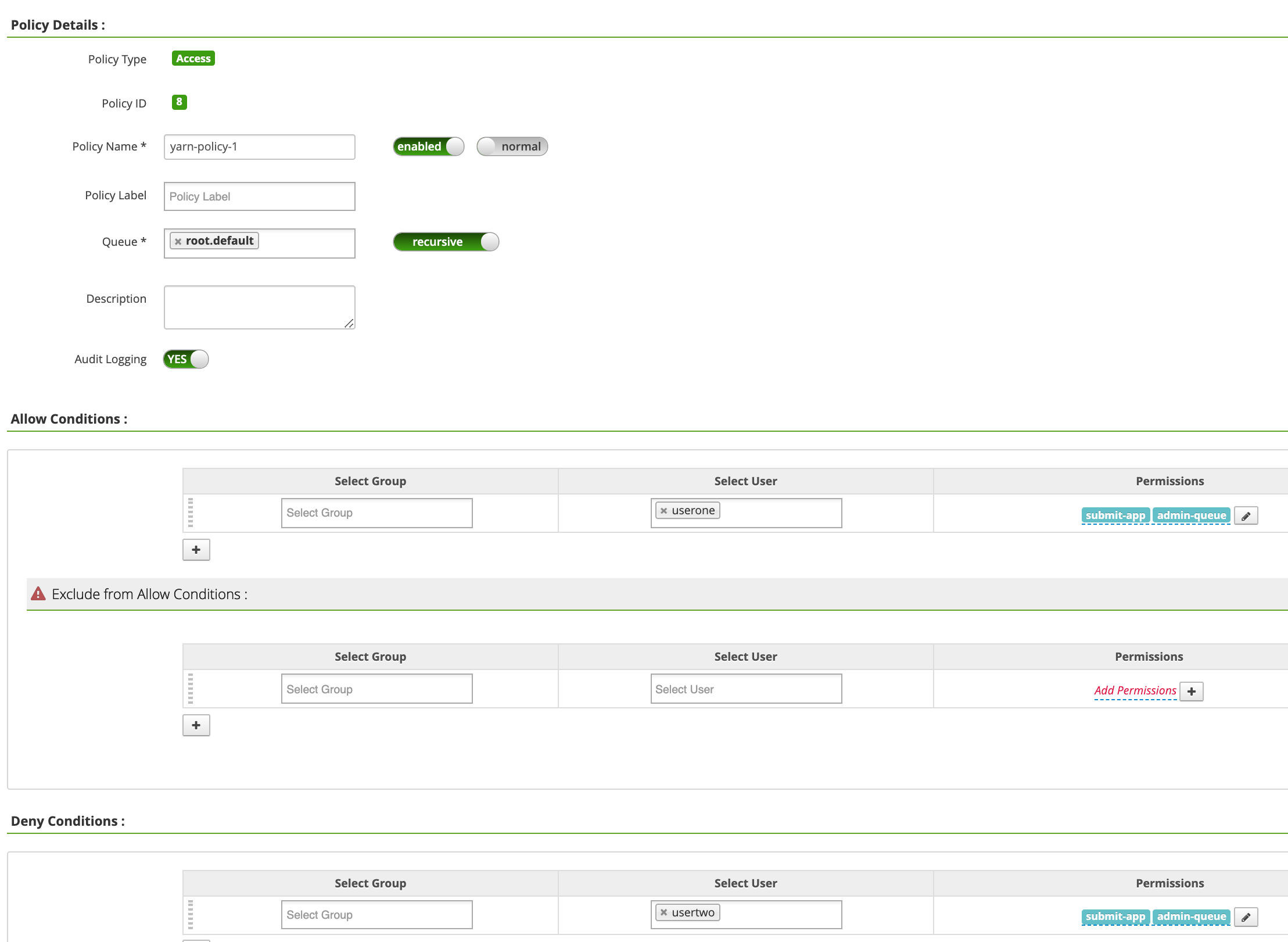
추가를 클릭하여 정책을 저장합니다. 이 정책은 yarn-dataproc 정책 페이지에 나열됩니다.

마스터 SSH 세션 창에서 Hadoop 맵리듀스 작업을 사용자1로 실행합니다.
userone@example-cluster-m:~$ hadoop jar /usr/lib/hadoop-mapreduce/hadoop-mapreduced-examples. jar pi 5 10
- Ranger UI는
userone가 작업을 제출하도록 허용되었음을 표시합니다.
- Ranger UI는
VM 마스터 SSH 세션 창에서 Hadoop 맵리듀스 작업을
usertwo로 실행합니다.usertwo@example-cluster-m:~$ hadoop jar /usr/lib/hadoop-mapreduce/hadoop-mapreduced-examples. jar pi 5 10
- Ranger UI는
usertwo가 작업을 제출할 수 있는 액세스가 거부되었음을 표시합니다.
- Ranger UI는
HDFS 액세스 정책
이 예시에서는 HDFS /tmp 디렉터리에 대한 사용자 액세스를 허용 및 거부하는 Ranger 정책을 만듭니다.
Ranger 관리 UI에서
hadoop-dataproc를 선택합니다.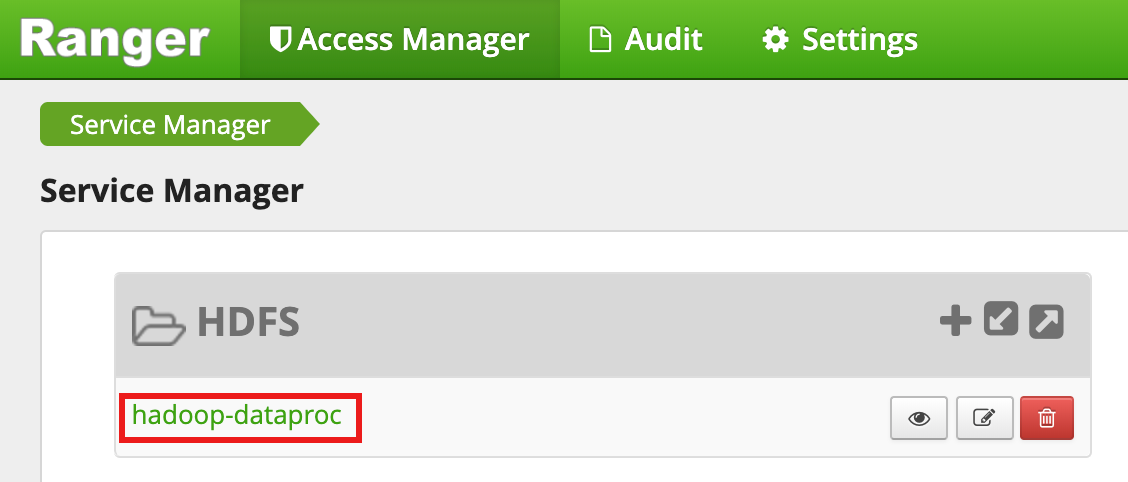
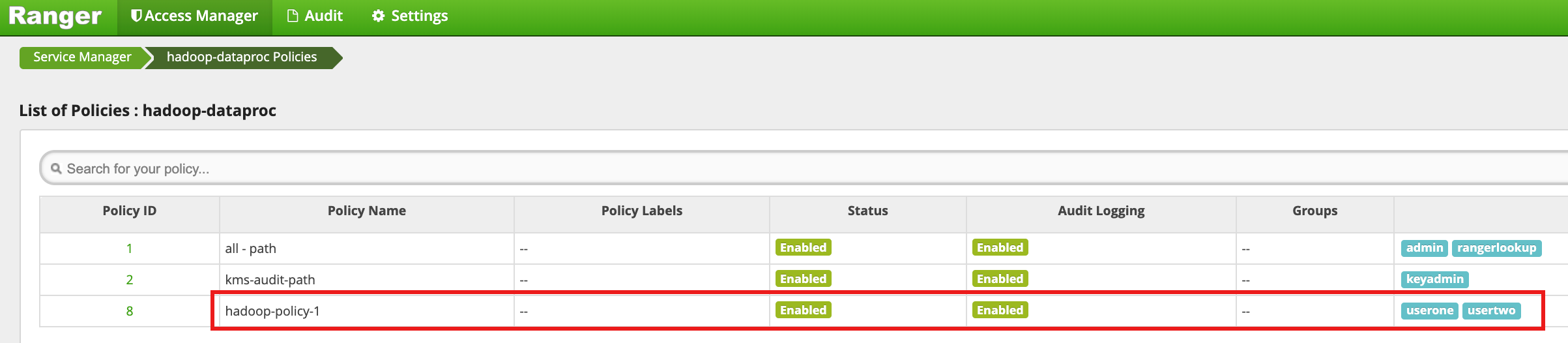
hadoop-dataproc 정책 페이지에서 새 정책 추가를 클릭합니다. 정책 만들기 페이지에서 다음 필드를 입력하거나 선택합니다.
Policy Name: 'hadoop-policy-1'Resource Path: '/tmp'Audit Logging: '예'Allow Conditions:Select User: '사용자1'Permissions: 모든 권한을 부여하려면 '모두 선택'
Deny Conditions:Select User: '사용자2'Permissions: 모든 권한을 거부하려면 '모두 선택'

추가를 클릭하여 정책을 저장합니다. 정책은 hadoop-dataproc 정책 페이지에 나와 있습니다.
HDFS
/tmp디렉터리에 사용자1로 액세스합니다.userone@example-cluster-m:~$ hadoop fs -ls /tmp
- Ranger UI는
userone가 HDFS /tmp 디렉터리에 액세스하도록 허용되었음을 표시합니다.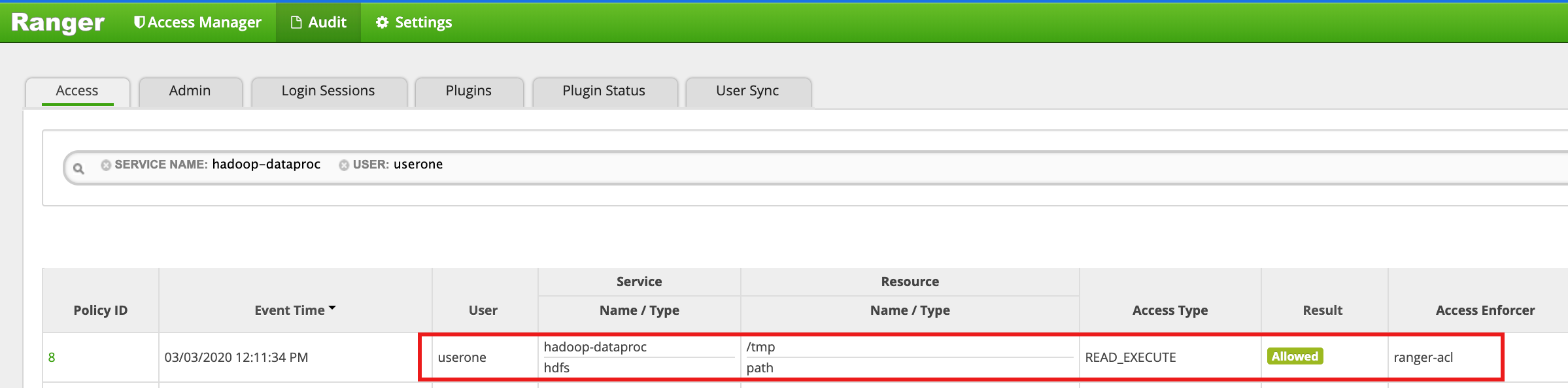
- Ranger UI는
HDFS
/tmp디렉터리에usertwo로 액세스:usertwo@example-cluster-m:~$ hadoop fs -ls /tmp
- Ranger UI는
usertwo가 HDFS /tmp 디렉터리에 대한 액세스가 거부되었음을 표시합니다.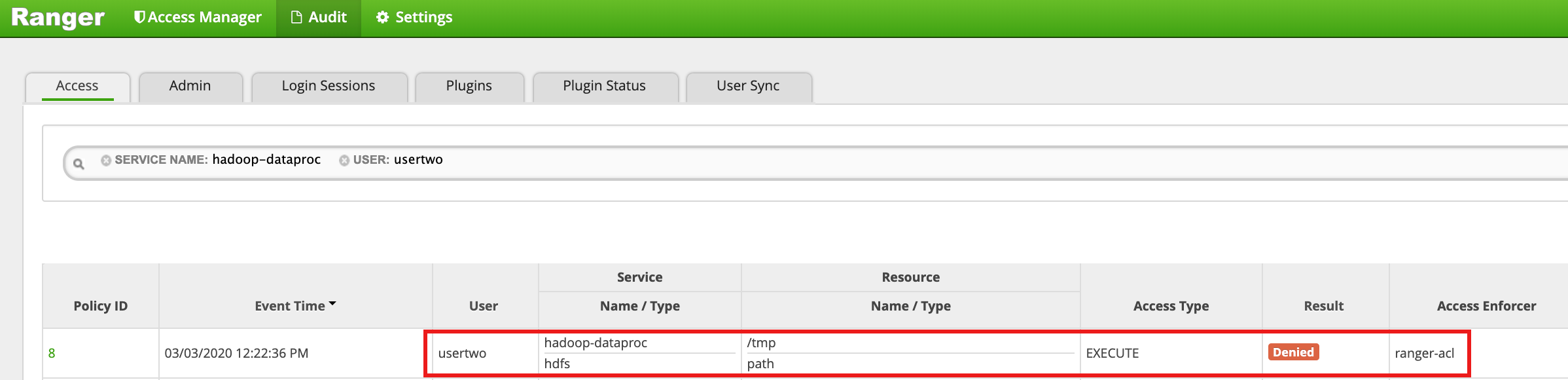
- Ranger UI는
Hive 액세스 정책
이 예시에서는 Hive 테이블에 대한 사용자 액세스를 허용 및 거부하는 Ranger 정책을 만듭니다.
마스터 인스턴스에서 hive CLI를 사용하여 작은
employee테이블을 만듭니다.hive> CREATE TABLE IF NOT EXISTS employee (eid int, name String); INSERT INTO employee VALUES (1 , 'bob') , (2 , 'alice'), (3 , 'john');
Ranger 관리 UI에서
hive-dataproc를 선택합니다.
hive-dataproc 정책 페이지에서 새 정책 추가를 클릭합니다. 정책 만들기 페이지에서 다음 필드를 입력하거나 선택합니다.
Policy Name: 'hive-policy-1'database: '기본값'table: '직원'Hive Column: '*'Audit Logging: '예'Allow Conditions:Select User: '사용자1'Permissions: 모든 권한을 부여하려면 '모두 선택'
Deny Conditions:Select User: '사용자2'Permissions: 모든 권한을 거부하려면 '모두 선택'

추가를 클릭하여 정책을 저장합니다. 이 정책은 hive-dataproc 정책 페이지에 나열됩니다.
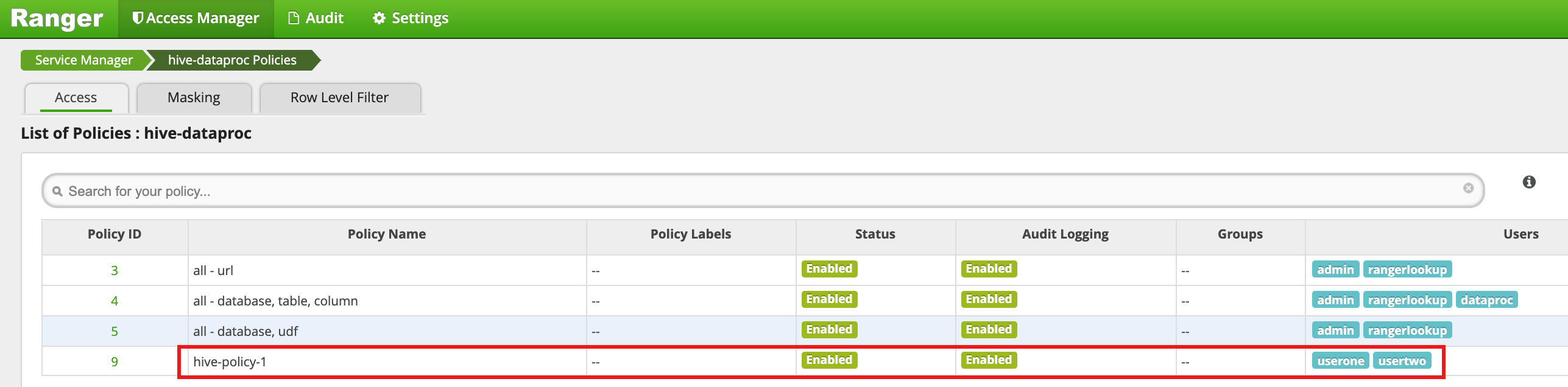
Hive 직원 테이블과 비교하여 VM 마스터 SSH 세션에서 쿼리를 사용자1로 실행합니다.
userone@example-cluster-m:~$ beeline -u "jdbc:hive2://$(hostname -f):10000/default;principal=hive/$(hostname -f)@REALM" -e "select * from employee;"
- 사용자1 쿼리가 성공합니다.
Connected to: Apache Hive (version 2.3.6) Driver: Hive JDBC (version 2.3.6) Transaction isolation: TRANSACTION_REPEATABLE_READ +---------------+----------------+ | employee.eid | employee.name | +---------------+----------------+ | 1 | bob | | 2 | alice | | 3 | john | +---------------+----------------+ 3 rows selected (2.033 seconds)
- 사용자1 쿼리가 성공합니다.
Hive 직원 테이블과 비교하여 VM 마스터 SSH 세션에서 쿼리를 사용자2로 실행합니다.
usertwo@example-cluster-m:~$ beeline -u "jdbc:hive2://$(hostname -f):10000/default;principal=hive/$(hostname -f)@REALM" -e "select * from employee;"
- 사용자2는 테이블에 대한 액세스가 거부됩니다.
Error: Could not open client transport with JDBC Uri: ... Permission denied: user=usertwo, access=EXECUTE, inode="/tmp/hive"
- 사용자2는 테이블에 대한 액세스가 거부됩니다.
세분화된 Hive 액세스
Ranger는 Hive에서 마스킹 및 행 수준 필터를 지원합니다. 이 예시에서는 마스킹 및 필터 정책을 추가하여 이전 hive-policy-1를 확장합니다.
Ranger 관리 UI에서
hive-dataproc를 선택한 다음 마스킹 탭과 새 정책 추가를 클릭합니다.
정책 만들기 페이지에서 직원 이름 열을 가리는(무효화하는) 정책을 만들려면 다음 필드를 입력하거나 선택합니다.
Policy Name: 'hive 마스킹 정책'database: '기본값'table: '직원'Hive Column: '이름'Audit Logging: '예'Mask Conditions:Select User: '사용자1'Access Types: 추가/수정 권한 '선택'Select Masking Option: '무효화'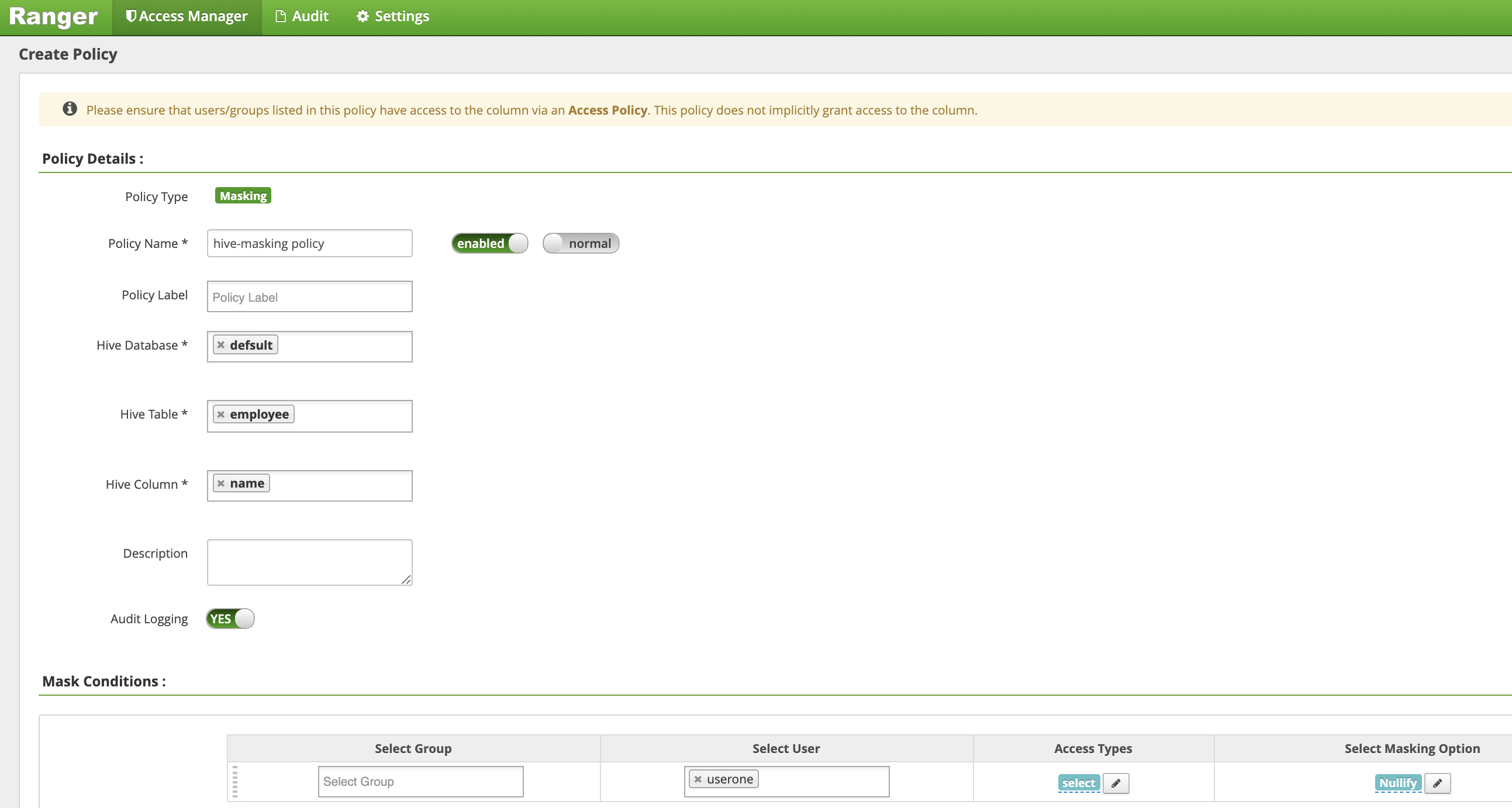
추가를 클릭하여 정책을 저장합니다.
Ranger 관리 UI에서
hive-dataproc를 선택한 다음 행 수준 필터 탭을 선택하고 새 정책 추가를 클릭합니다.
정책 만들기 페이지에서 다음 필드를 입력하거나 선택하여
eid이1와 같지 않은 행을 필터링(반환)합니다.Policy Name: 'Hive-filter 정책'Hive Database: '기본값'Hive Table: '직원'Audit Logging: '예'Mask Conditions:Select User: '사용자1'Access Types: 추가/수정 권한 '선택'Row Level Filter: 'eid != 1' 필터 표현식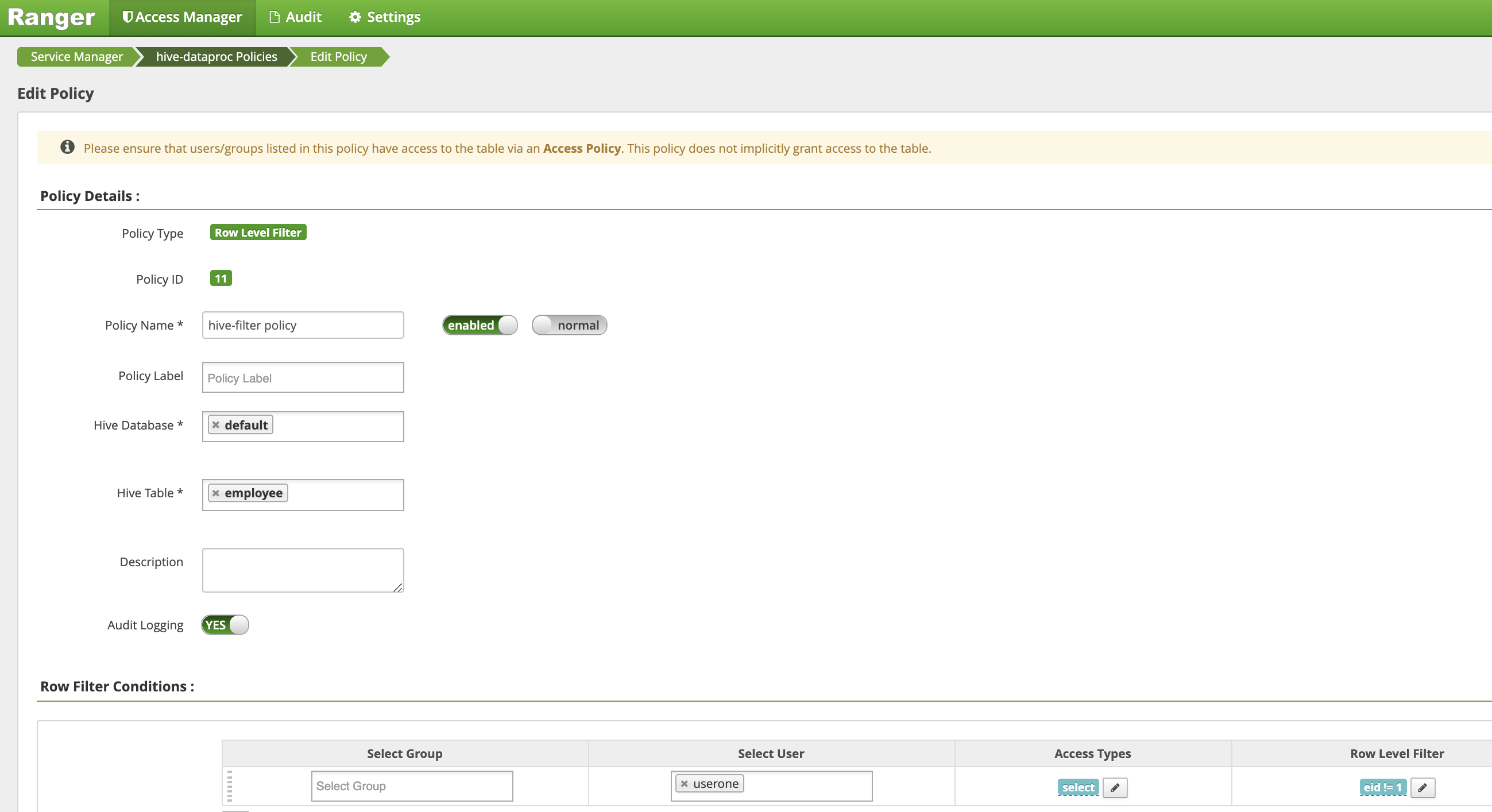
추가를 클릭하여 정책을 저장합니다.
Hive 직원 테이블과 비교하여 VM 마스터 SSH 세션의 이전 쿼리를 사용자1로 반복합니다.
userone@example-cluster-m:~$ beeline -u "jdbc:hive2://$(hostname -f):10000/default;principal=hive/$(hostname -f)@REALM" -e "select * from employee;"
- 이 쿼리는 이름 열이 마스킹되고 결과에서 Bob(eid=1)로 필터링되어 반환됩니다.
Transaction isolation: TRANSACTION_REPEATABLE_READ +---------------+----------------+ | employee.eid | employee.name | +---------------+----------------+ | 2 | NULL | | 3 | NULL | +---------------+----------------+ 2 rows selected (0.47 seconds)
- 이 쿼리는 이름 열이 마스킹되고 결과에서 Bob(eid=1)로 필터링되어 반환됩니다.