En los siguientes ejemplos se crea y se usa un clúster de Dataproc habilitado para Kerberos con los componentes Ranger y Solr para controlar el acceso de los usuarios a los recursos de Hadoop, YARN y Hive.
Notas:
Se puede acceder a la interfaz de usuario web de Ranger a través de la pasarela de componentes.
En un clúster de Ranger con Kerberos, Dataproc asigna un usuario de Kerberos al usuario del sistema quitando el dominio y la instancia del usuario de Kerberos. Por ejemplo, el principal de Kerberos
user1/cluster-m@MY.REALMse asigna al sistemauser1y las políticas de Ranger se definen para permitir o denegar permisos parauser1.
Crea el clúster.
- El siguiente comando
gcloudse puede ejecutar en una ventana de terminal local o desde el Cloud Shell de un proyecto.gcloud dataproc clusters create cluster-name \ --region=region \ --optional-components=SOLR,RANGER \ --enable-component-gateway \ --properties="dataproc:ranger.kms.key.uri=projects/project-id/locations/global/keyRings/keyring/cryptoKeys/key,dataproc:ranger.admin.password.uri=gs://bucket/admin-password.encrypted" \ --kerberos-root-principal-password-uri=gs://bucket/kerberos-root-principal-password.encrypted \ --kerberos-kms-key=projects/project-id/locations/global/keyRings/keyring/cryptoKeys/key
- El siguiente comando
Una vez que el clúster esté en funcionamiento, ve a la página Clústeres de Dataproc en la consola de Google Cloud y, a continuación, selecciona el nombre del clúster para abrir la página Detalles del clúster. Haz clic en la pestaña Interfaces web para ver una lista de enlaces de la pasarela de componentes a las interfaces web de los componentes predeterminados y opcionales instalados en el clúster. Haz clic en el enlace de Ranger.

Inicia sesión en Ranger introduciendo el nombre de usuario "admin" y la contraseña de administrador de Ranger.

La interfaz de administración de Ranger se abre en un navegador local.
Política de acceso de YARN
En este ejemplo, se crea una política de Ranger para permitir y denegar el acceso de los usuarios a la cola root.default de YARN.
Selecciona
yarn-dataprocen la interfaz de usuario de administrador de Ranger.
En la página yarn-dataproc Policies (Políticas de yarn-dataproc), haga clic en Add New Policy (Añadir nueva política). En la página Crear política, se introducen o seleccionan los siguientes campos:
Policy Name: "yarn-policy-1"Queue: "root.default"Audit Logging: "Sí"Allow Conditions:Select User: "userone"Permissions: selecciona "Seleccionar todo" para conceder todos los permisos.
Deny Conditions:Select User: "usertwo"Permissions: "Seleccionar todo" para denegar todos los permisos
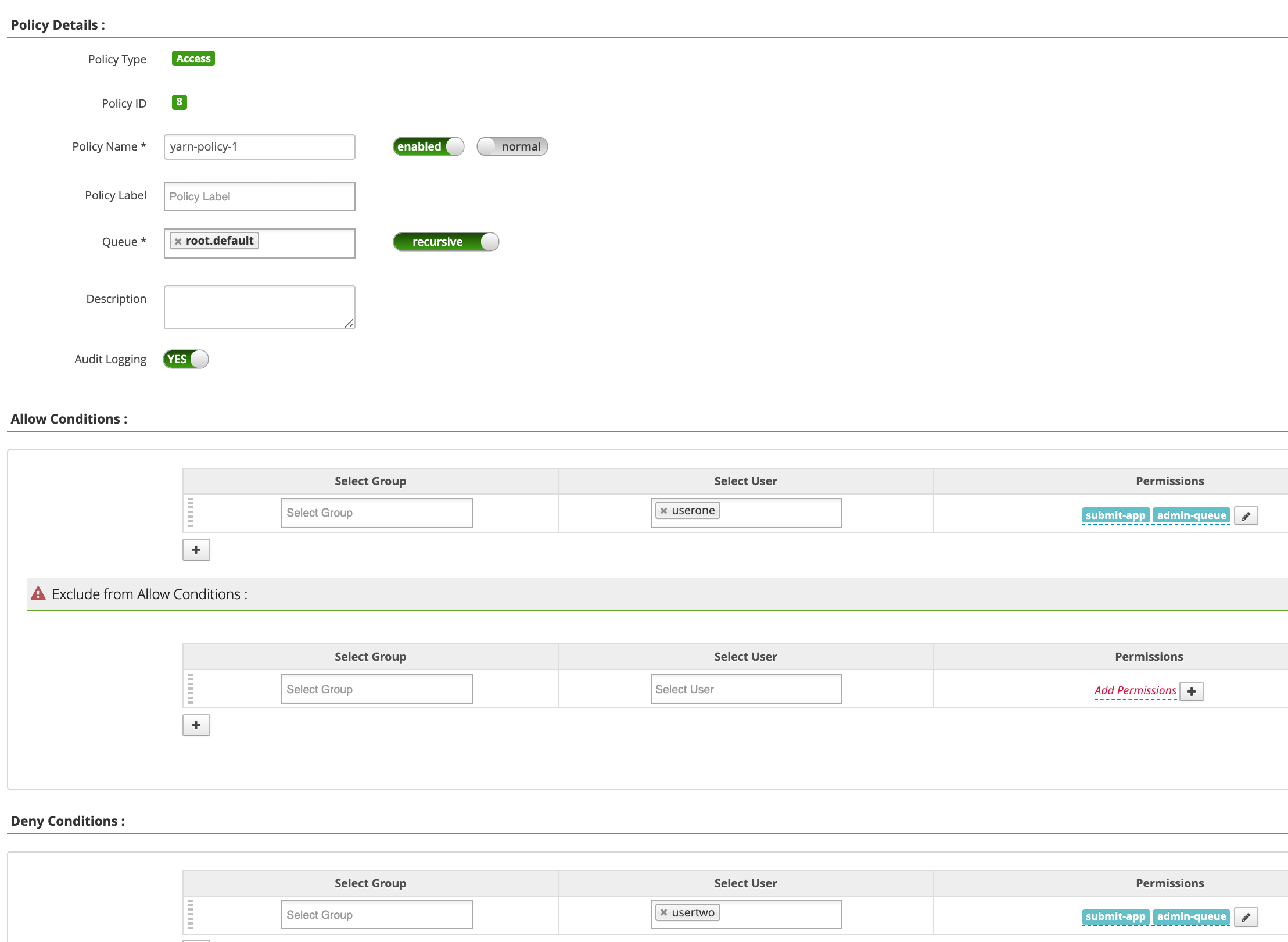
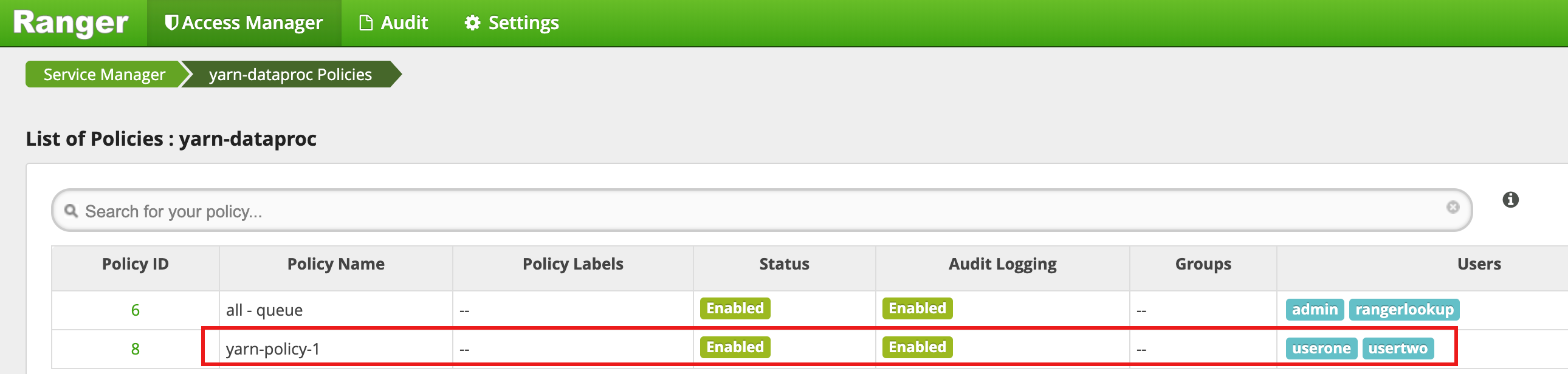
Haz clic en Añadir para guardar la política. La política se indica en la página Políticas de yarn-dataproc:
Ejecuta una tarea de MapReduce de Hadoop en la ventana de sesión SSH maestra como usuario uno:
userone@example-cluster-m:~$ hadoop jar /usr/lib/hadoop-mapreduce/hadoop-mapreduced-examples. jar pi 5 10
- La interfaz de usuario de Ranger muestra que se ha permitido a
useroneenviar la tarea.
- La interfaz de usuario de Ranger muestra que se ha permitido a
Ejecuta la tarea de MapReduce de Hadoop desde la ventana de la sesión SSH de la VM maestra como
usertwo:usertwo@example-cluster-m:~$ hadoop jar /usr/lib/hadoop-mapreduce/hadoop-mapreduced-examples. jar pi 5 10
- La interfaz de usuario de Ranger muestra que se ha denegado el acceso a
usertwopara enviar el trabajo.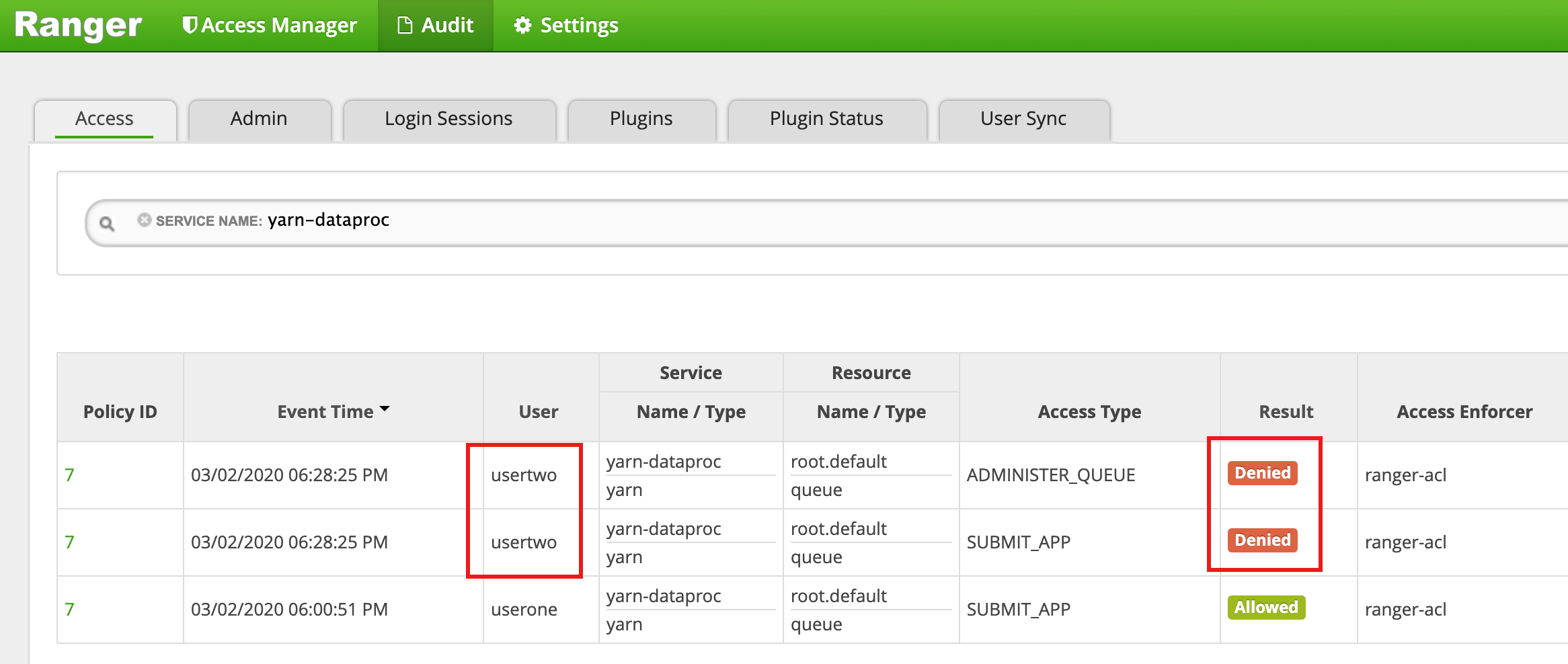
- La interfaz de usuario de Ranger muestra que se ha denegado el acceso a
Política de acceso a HDFS
En este ejemplo, se crea una política de Ranger para permitir y denegar el acceso de los usuarios al directorio /tmp de HDFS.
Selecciona
hadoop-dataprocen la interfaz de usuario de administrador de Ranger.
En la página hadoop-dataproc Policies (Políticas de hadoop-dataproc), haga clic en Add New Policy (Añadir nueva política). En la página Crear política, se introducen o seleccionan los siguientes campos:
Policy Name: "hadoop-policy-1"Resource Path: "/tmp"Audit Logging: "Sí"Allow Conditions:Select User: "userone"Permissions: selecciona "Seleccionar todo" para conceder todos los permisos.
Deny Conditions:Select User: "usertwo"Permissions: "Seleccionar todo" para denegar todos los permisos
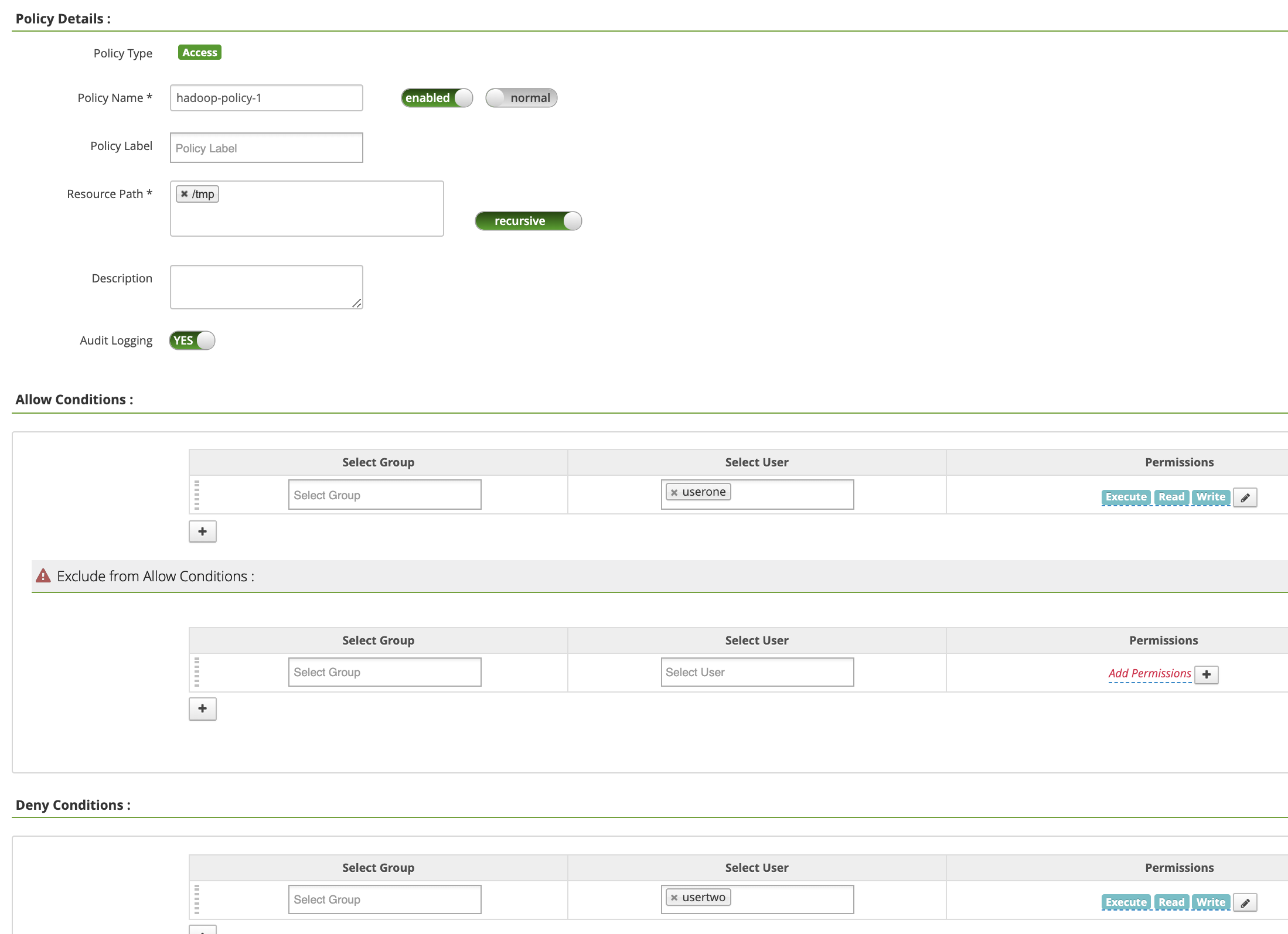
Haz clic en Añadir para guardar la política. La política se indica en la página hadoop-dataproc Policies (Políticas de hadoop-dataproc):

Accede al directorio
/tmpde HDFS como usuario 1:userone@example-cluster-m:~$ hadoop fs -ls /tmp
- La interfaz de usuario de Ranger muestra que se ha permitido el acceso de
useroneal directorio /tmp de HDFS.
- La interfaz de usuario de Ranger muestra que se ha permitido el acceso de
Accede al directorio
/tmpde HDFS comousertwo:usertwo@example-cluster-m:~$ hadoop fs -ls /tmp
- La interfaz de usuario de Ranger muestra que se ha denegado el acceso de
usertwoal directorio /tmp de HDFS.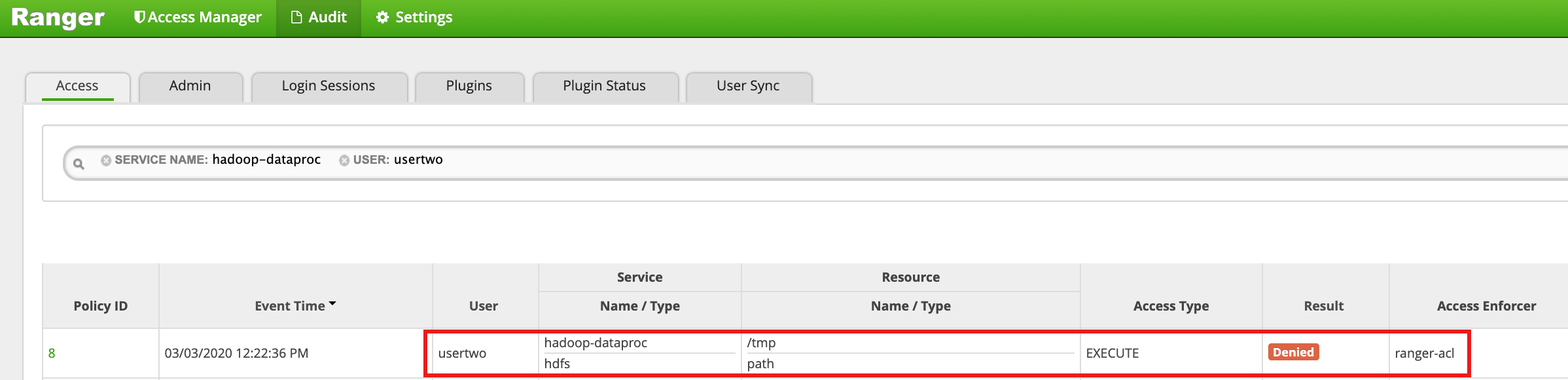
- La interfaz de usuario de Ranger muestra que se ha denegado el acceso de
Política de acceso de Hive
En este ejemplo, se crea una política de Ranger para permitir y denegar el acceso de los usuarios a una tabla de Hive.
Crea una tabla
employeepequeña con la CLI de Hive en la instancia maestra.hive> CREATE TABLE IF NOT EXISTS employee (eid int, name String); INSERT INTO employee VALUES (1 , 'bob') , (2 , 'alice'), (3 , 'john');
Selecciona
hive-dataprocen la interfaz de usuario de administrador de Ranger.
En la página hive-dataproc Policies (Políticas de hive-dataproc), haga clic en Add New Policy (Añadir nueva política). En la página Crear política, se introducen o seleccionan los siguientes campos:
Policy Name: "hive-policy-1"database: "default"table: "employee"Hive Column: "*"Audit Logging: "Sí"Allow Conditions:Select User: "userone"Permissions: selecciona "Seleccionar todo" para conceder todos los permisos.
Deny Conditions:Select User: "usertwo"Permissions: "Seleccionar todo" para denegar todos los permisos
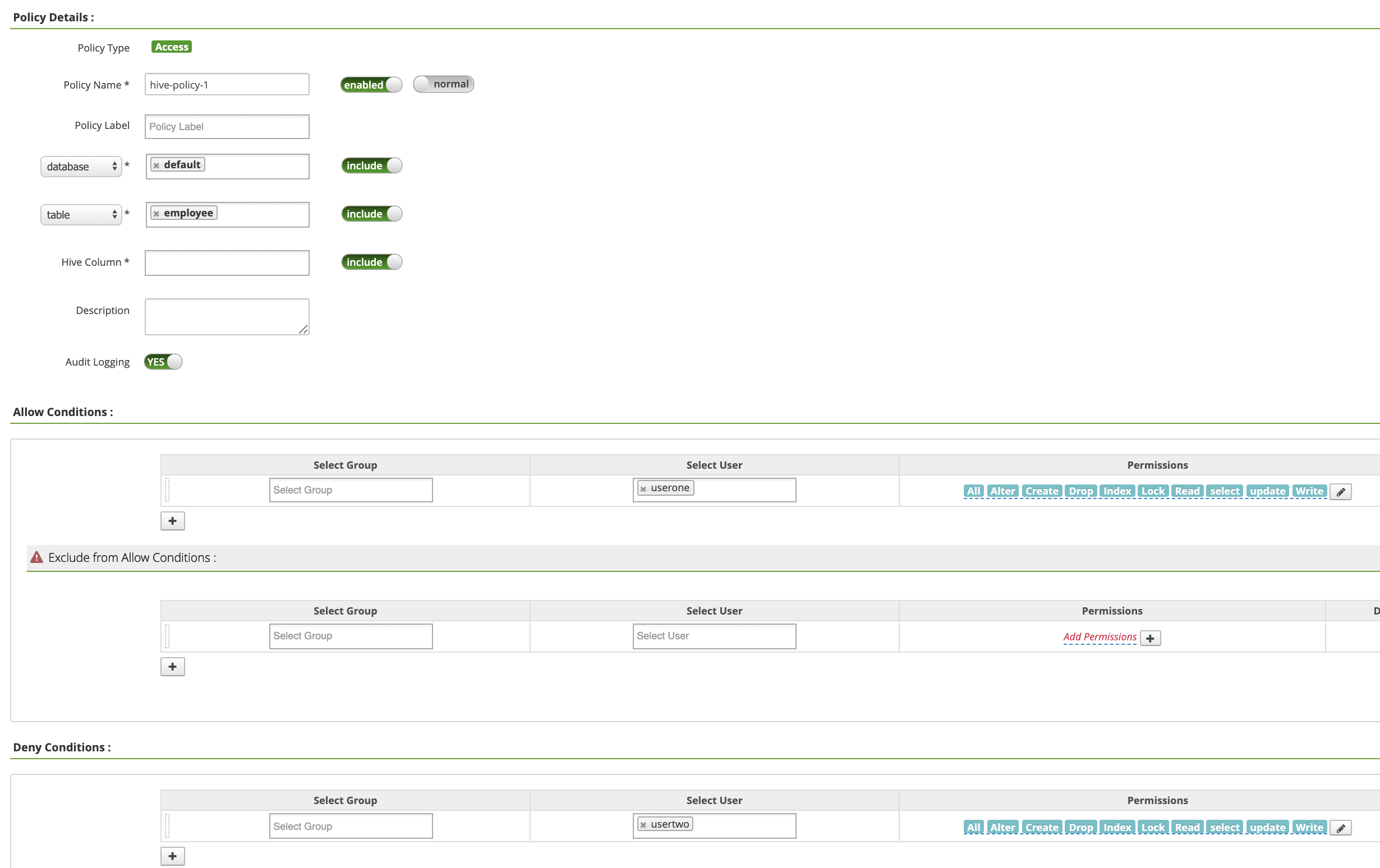
Haz clic en Añadir para guardar la política. La política se indica en la página hive-dataproc Policies (Políticas de hive-dataproc):

Ejecuta una consulta desde la sesión SSH maestra de la VM en la tabla de empleados de Hive como usuario uno:
userone@example-cluster-m:~$ beeline -u "jdbc:hive2://$(hostname -f):10000/default;principal=hive/$(hostname -f)@REALM" -e "select * from employee;"
- La consulta de usuario1 se realiza correctamente:
Connected to: Apache Hive (version 2.3.6) Driver: Hive JDBC (version 2.3.6) Transaction isolation: TRANSACTION_REPEATABLE_READ +---------------+----------------+ | employee.eid | employee.name | +---------------+----------------+ | 1 | bob | | 2 | alice | | 3 | john | +---------------+----------------+ 3 rows selected (2.033 seconds)
- La consulta de usuario1 se realiza correctamente:
Ejecuta una consulta desde la sesión SSH maestra de la VM en la tabla de empleados de Hive como usertwo:
usertwo@example-cluster-m:~$ beeline -u "jdbc:hive2://$(hostname -f):10000/default;principal=hive/$(hostname -f)@REALM" -e "select * from employee;"
- Se deniega el acceso a la tabla a usertwo:
Error: Could not open client transport with JDBC Uri: ... Permission denied: user=usertwo, access=EXECUTE, inode="/tmp/hive"
- Se deniega el acceso a la tabla a usertwo:
Acceso pormenorizado a Hive
Ranger admite el enmascaramiento y los filtros a nivel de fila en Hive. Este ejemplo
se basa en el anterior hive-policy-1 añadiendo políticas de
máscara y filtro.
Selecciona
hive-dataprocen la interfaz de administración de Ranger y, a continuación, selecciona la pestaña Masking (Máscara) y haz clic en Add New Policy (Añadir nueva política).
En la página Crear política, se introducen o seleccionan los siguientes campos para crear una política que enmascare (anule) la columna Nombre del empleado:
Policy Name: "hive-masking policy"database: "default"table: "employee"Hive Column: "name"Audit Logging: "Sí"Mask Conditions:Select User: "userone"Access Types: "select" add/edit permissionsSelect Masking Option: "nullify"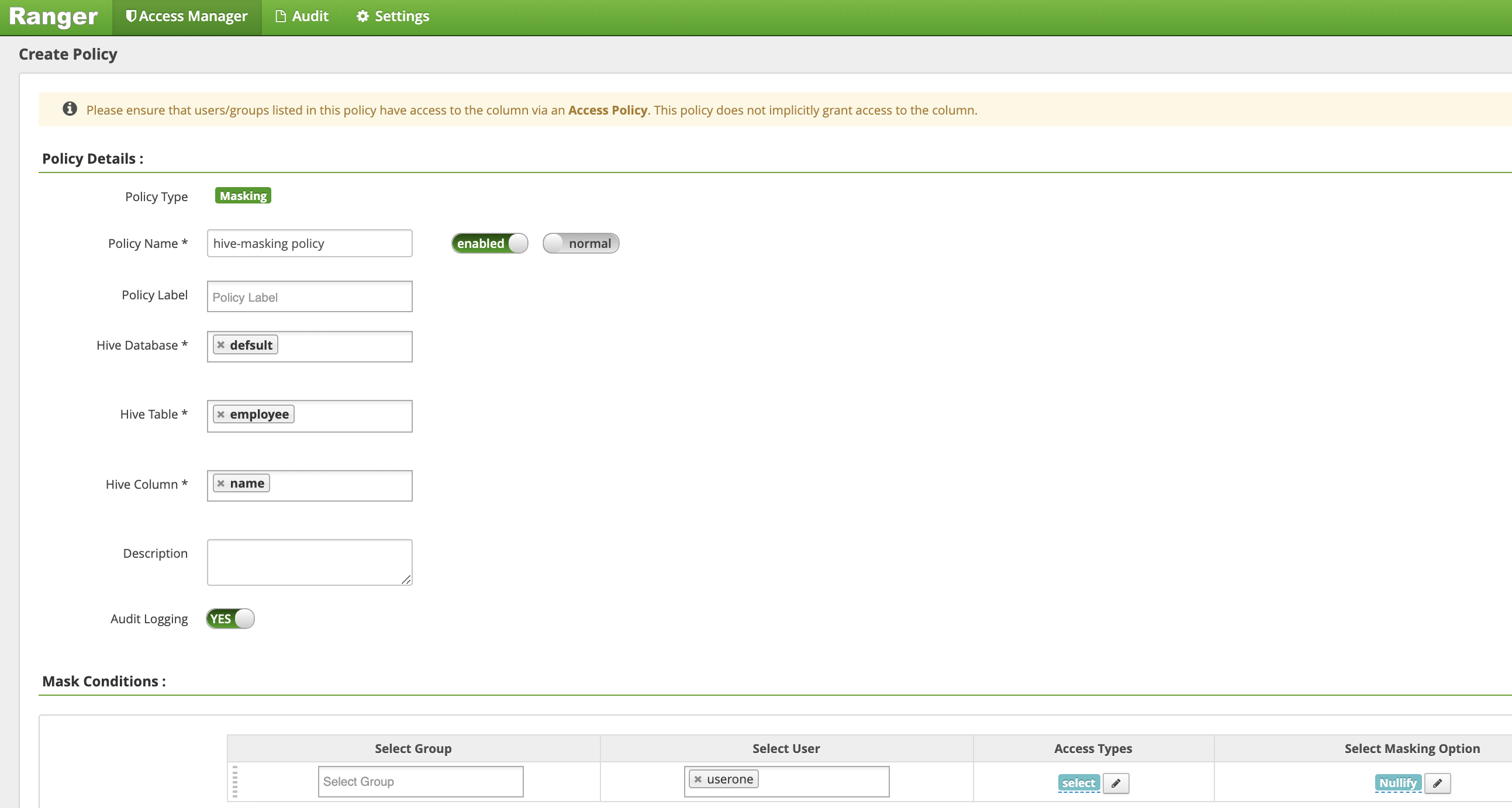
Haz clic en Añadir para guardar la política.
Selecciona
hive-dataprocen la interfaz de administración de Ranger y, a continuación, selecciona la pestaña Filtro a nivel de fila y haz clic en Añadir nueva política.
En la página Crear política, se introducen o seleccionan los siguientes campos para crear una política que filtre (devuelva) las filas en las que
eidno sea igual a1:Policy Name: "hive-filter policy"Hive Database: "default"Hive Table: "employee"Audit Logging: "Sí"Mask Conditions:Select User: "userone"Access Types: "select" add/edit permissionsRow Level Filter: expresión de filtro "eid != 1"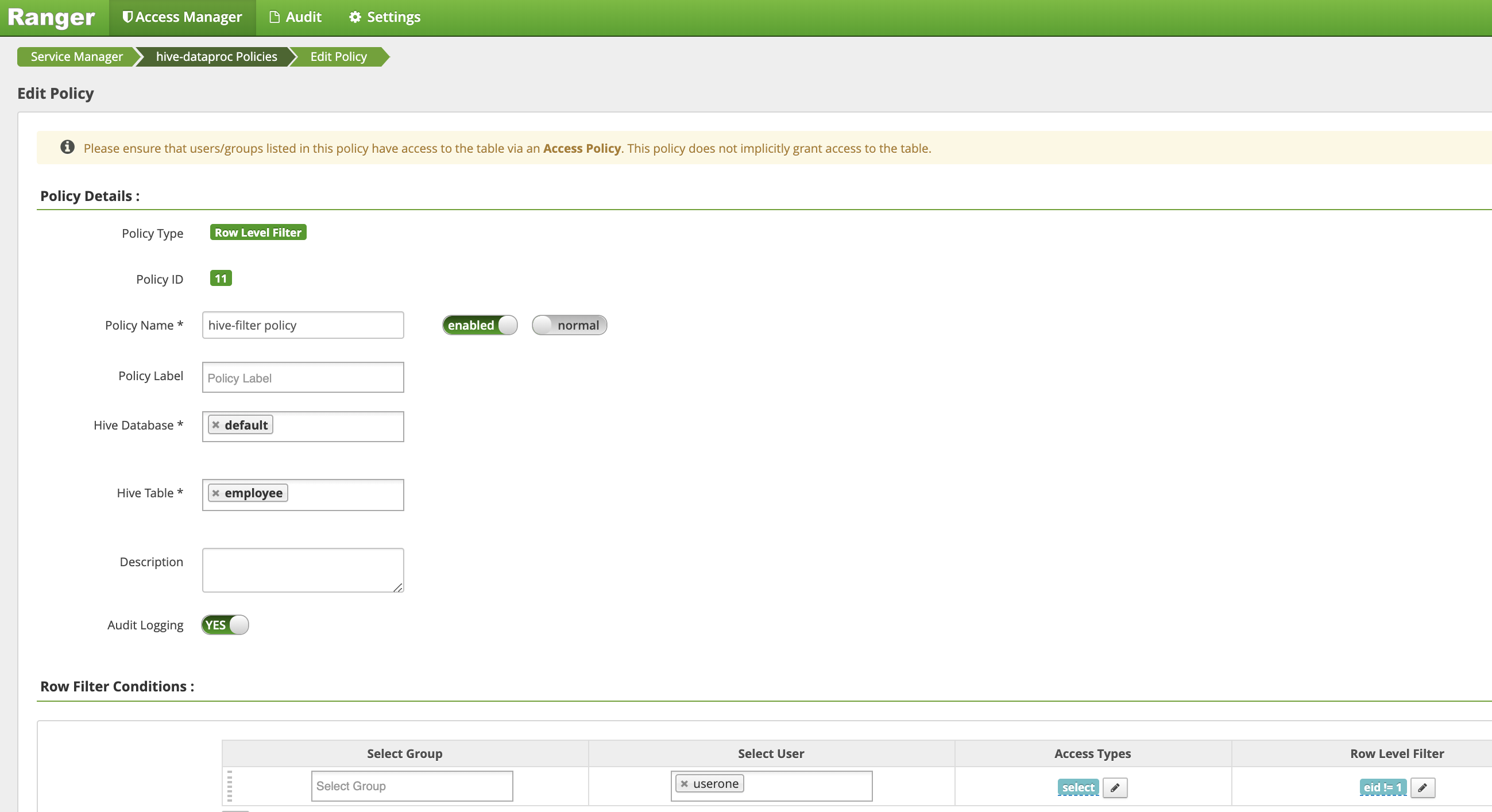
Haz clic en Añadir para guardar la política.
Repite la consulta anterior desde la sesión SSH maestra de la VM en la tabla de empleados de Hive como usuario uno:
userone@example-cluster-m:~$ beeline -u "jdbc:hive2://$(hostname -f):10000/default;principal=hive/$(hostname -f)@REALM" -e "select * from employee;"
- La consulta devuelve la columna de nombre enmascarada y bob
(eid=1) filtrado de los resultados.:
Transaction isolation: TRANSACTION_REPEATABLE_READ +---------------+----------------+ | employee.eid | employee.name | +---------------+----------------+ | 2 | NULL | | 3 | NULL | +---------------+----------------+ 2 rows selected (0.47 seconds)
- La consulta devuelve la columna de nombre enmascarada y bob
(eid=1) filtrado de los resultados.: