このドキュメントでは、Apache Spark SQL と PySpark のサーバーレス バッチ ワークロードを実行して、メタデータが BigLake metastore に保存された Apache Iceberg テーブルを作成する方法について説明します。Spark コードを実行するその他の方法については、BigQuery ノートブックで PySpark コードを実行すると Apache Spark ワークロードを実行するをご覧ください。
始める前に
Google Cloud プロジェクトと Cloud Storage バケットをまだ作成していない場合は、作成します。
プロジェクトを設定する
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Enable the Dataproc, BigQuery, and Cloud Storage APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Enable the Dataproc, BigQuery, and Cloud Storage APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. プロジェクトの Cloud Storage バケットを作成します。
- In the Google Cloud console, go to the Cloud Storage Buckets page.
- Click Create.
- On the Create a bucket page, enter your bucket information. To go to the next
step, click Continue.
-
In the Get started section, do the following:
- Enter a globally unique name that meets the bucket naming requirements.
- To add a
bucket label,
expand the Labels section (),
click add_box
Add label, and specify a
keyand avaluefor your label.
-
In the Choose where to store your data section, do the following:
- Select a Location type.
- Choose a location where your bucket's data is permanently stored from the Location type drop-down menu.
- If you select the dual-region location type, you can also choose to enable turbo replication by using the relevant checkbox.
- To set up cross-bucket replication, select
Add cross-bucket replication via Storage Transfer Service and
follow these steps:
Set up cross-bucket replication
- In the Bucket menu, select a bucket.
In the Replication settings section, click Configure to configure settings for the replication job.
The Configure cross-bucket replication pane appears.
- To filter objects to replicate by object name prefix, enter a prefix that you want to include or exclude objects from, then click Add a prefix.
- To set a storage class for the replicated objects, select a storage class from the Storage class menu. If you skip this step, the replicated objects will use the destination bucket's storage class by default.
- Click Done.
-
In the Choose how to store your data section, do the following:
- Select a default storage class for the bucket or Autoclass for automatic storage class management of your bucket's data.
- To enable hierarchical namespace, in the Optimize storage for data-intensive workloads section, select Enable hierarchical namespace on this bucket.
- In the Choose how to control access to objects section, select whether or not your bucket enforces public access prevention, and select an access control method for your bucket's objects.
-
In the Choose how to protect object data section, do the
following:
- Select any of the options under Data protection that you
want to set for your bucket.
- To enable soft delete, click the Soft delete policy (For data recovery) checkbox, and specify the number of days you want to retain objects after deletion.
- To set Object Versioning, click the Object versioning (For version control) checkbox, and specify the maximum number of versions per object and the number of days after which the noncurrent versions expire.
- To enable the retention policy on objects and buckets, click the Retention (For compliance) checkbox, and then do the following:
- To enable Object Retention Lock, click the Enable object retention checkbox.
- To enable Bucket Lock, click the Set bucket retention policy checkbox, and choose a unit of time and a length of time for your retention period.
- To choose how your object data will be encrypted, expand the Data encryption section (), and select a Data encryption method.
- Select any of the options under Data protection that you
want to set for your bucket.
-
In the Get started section, do the following:
- Click Create.
Compute Engine のデフォルト サービス アカウント(
PROJECT_NUMBER-compute@developer.gserviceaccount.com)に BigQuery データ編集者(roles/bigquery.dataEditor)ロールを付与します。手順については、単一ロールの付与をご覧ください。Google Cloud CLI の例:
gcloud projects add-iam-policy-binding PROJECT_ID \ --member PROJECT_NUMBER-compute@developer.gserviceaccount.com \ --role roles/bigquery.dataEditor
注:
- PROJECT_ID と PROJECT_NUMBER は、 Google Cloud コンソールのダッシュボードの [プロジェクト情報] セクションに表示されます。
次の Spark SQL コマンドをローカルまたは Cloud Shell の
iceberg-table.sqlファイルにコピーします。USE CATALOG_NAME; CREATE NAMESPACE IF NOT EXISTS example_namespace; DROP TABLE IF EXISTS example_table; CREATE TABLE example_table (id int, data string) USING ICEBERG LOCATION 'gs://BUCKET/WAREHOUSE_FOLDER'; INSERT INTO example_table VALUES (1, 'first row'); ALTER TABLE example_table ADD COLUMNS (newDoubleCol double); DESCRIBE TABLE example_table;
次のように置き換えます。
- CATALOG_NAME: Iceberg カタログ名。
- BUCKET と WAREHOUSE_FOLDER: Iceberg ウェアハウスのディレクトリとして使用する Cloud Storage バケットとフォルダ。
iceberg-table.sqlを含むディレクトリからローカルまたは Cloud Shell で次のコマンドを実行して、Spark SQL ワークロードを送信します。gcloud dataproc batches submit spark-sql iceberg-table.sql \ --project=PROJECT_ID \ --region=REGION \ --deps-bucket=BUCKET_NAME \ --version=2.2 \ --subnet=SUBNET_NAME \ --properties="spark.sql.catalog.CATALOG_NAME=org.apache.iceberg.spark.SparkCatalog,spark.sql.catalog.CATALOG_NAME.catalog-impl=org.apache.iceberg.gcp.bigquery.BigQueryMetastoreCatalog,spark.sql.catalog.CATALOG_NAME.gcp_project=PROJECT_ID,spark.sql.catalog.CATALOG_NAME.gcp_location=LOCATION,spark.sql.catalog.CATALOG_NAME.warehouse=gs://BUCKET/WAREHOUSE_FOLDER"
注:
- PROJECT_ID: 実際の Google Cloud プロジェクト ID。 プロジェクト ID は、 Google Cloud コンソールのダッシュボードの [プロジェクト情報] セクションに表示されます。
- REGION: ワークロードを実行できる利用可能な Compute Engine リージョン。
- BUCKET_NAME: Cloud Storage バケットの名前。Spark は、バッチ ワークロードを実行する前に、ワークロードの依存関係をこのバケットの
/dependenciesフォルダにアップロードします。WAREHOUSE_FOLDER はこのバケットにあります。 --version: Apache Spark 用サーバーレス ランタイム バージョン 2.2 以降。- SUBNET_NAME:
REGION内の VPC サブネットの名前。このフラグを省略すると、Apache Spark 向け Serverless はセッション リージョンのdefaultサブネットを選択します。Apache Spark 向けサーバーレスは、サブネットでプライベート Google アクセス(PGA)を有効にします。ネットワーク接続の要件については、Google Cloud Apache Spark 用サーバーレス ネットワーク構成をご覧ください。 - LOCATION: サポートされている BigQuery のロケーション。デフォルトのロケーションは「US」です。
--propertiesカタログ プロパティ。
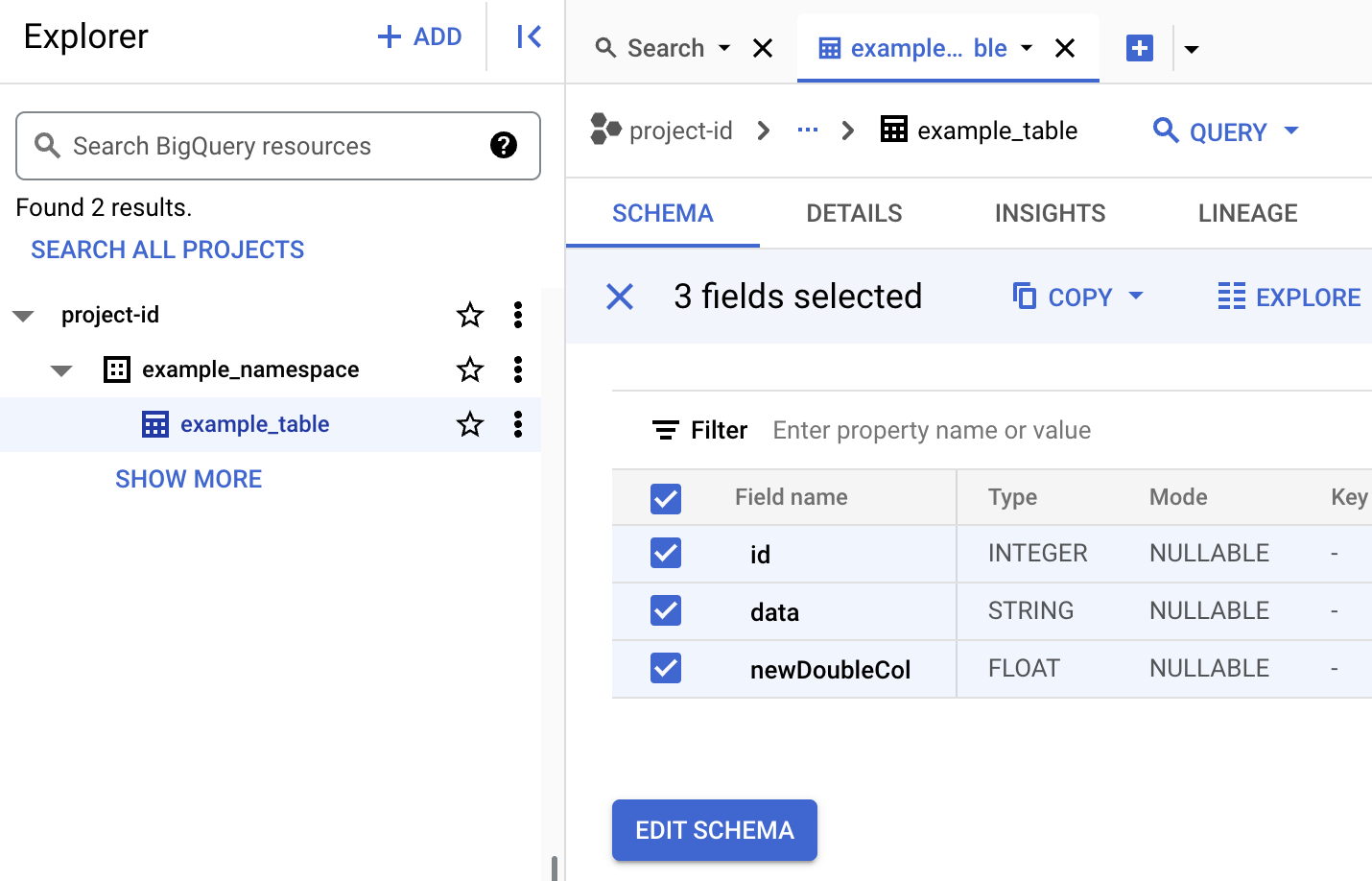
BigQuery でテーブルのメタデータを確認します。
Google Cloud コンソールで、[BigQuery] ページに移動します。
Iceberg テーブルのメタデータを確認します。
- 次の PySpark コードをローカルまたは Cloud Shell で
iceberg-table.pyファイルにコピーします。from pyspark.sql import SparkSession spark = SparkSession.builder.appName("iceberg-table-example").getOrCreate() catalog = "CATALOG_NAME" namespace = "NAMESPACE" spark.sql(f"USE `{catalog}`;") spark.sql(f"CREATE NAMESPACE IF NOT EXISTS `{namespace}`;") spark.sql(f"USE `{namespace}`;") # Create table and display schema spark.sql("DROP TABLE IF EXISTS example_iceberg_table") spark.sql("CREATE TABLE example_iceberg_table (id int, data string) USING ICEBERG") spark.sql("DESCRIBE example_iceberg_table;") # Insert table data. spark.sql("INSERT INTO example_iceberg_table VALUES (1, 'first row');") # Alter table, then display schema. spark.sql("ALTER TABLE example_iceberg_table ADD COLUMNS (newDoubleCol double);") spark.sql("DESCRIBE example_iceberg_table;")
次のように置き換えます。
- CATALOG_NAME と NAMESPACE: Iceberg テーブルを識別するための Iceberg カタログ名と名前空間の組み合わせ(
catalog.namespace.table_name)。
- CATALOG_NAME と NAMESPACE: Iceberg テーブルを識別するための Iceberg カタログ名と名前空間の組み合わせ(
-
iceberg-table.pyを含むディレクトリからローカルまたは Cloud Shell で次のコマンドを実行して、PySpark ワークロードを送信します。gcloud dataproc batches submit pyspark iceberg-table.py \ --project=PROJECT_ID \ --region=REGION \ --deps-bucket=BUCKET_NAME \ --version=2.2 \ --subnet=SUBNET_NAME \ --properties="spark.sql.catalog.CATALOG_NAME=org.apache.iceberg.spark.SparkCatalog,spark.sql.catalog.CATALOG_NAME.catalog-impl=org.apache.iceberg.gcp.bigquery.BigQueryMetastoreCatalog,spark.sql.catalog.CATALOG_NAME.gcp_project=PROJECT_ID,spark.sql.catalog.CATALOG_NAME.gcp_location=LOCATION,spark.sql.catalog.CATALOG_NAME.warehouse=gs://BUCKET/WAREHOUSE_FOLDER"注:
- PROJECT_ID: 実際の Google Cloud プロジェクト ID。 プロジェクト ID は、 Google Cloud コンソールのダッシュボードの [プロジェクト情報] セクションに表示されます。
- REGION: ワークロードを実行できる利用可能な Compute Engine リージョン。
- BUCKET_NAME: Cloud Storage バケットの名前。Spark は、バッチ ワークロードを実行する前に、ワークロードの依存関係をこのバケットの
/dependenciesフォルダにアップロードします。 --version: Apache Spark 用サーバーレス ランタイム バージョン 2.2 以降。- SUBNET_NAME:
REGION内の VPC サブネットの名前。このフラグを省略すると、Apache Spark 向け Serverless はセッション リージョンのdefaultサブネットを選択します。Apache Spark 向け Serverless は、サブネットでプライベート Google アクセス(PGA)を有効にします。ネットワーク接続の要件については、Google Cloud Apache Spark 用サーバーレス ネットワーク構成をご覧ください。 - LOCATION: サポートされている BigQuery のロケーション。デフォルトのロケーションは「US」です。
- BUCKET と WAREHOUSE_FOLDER: Iceberg ウェアハウス ディレクトリとして使用する Cloud Storage バケットとフォルダ。
--properties: カタログ プロパティ。
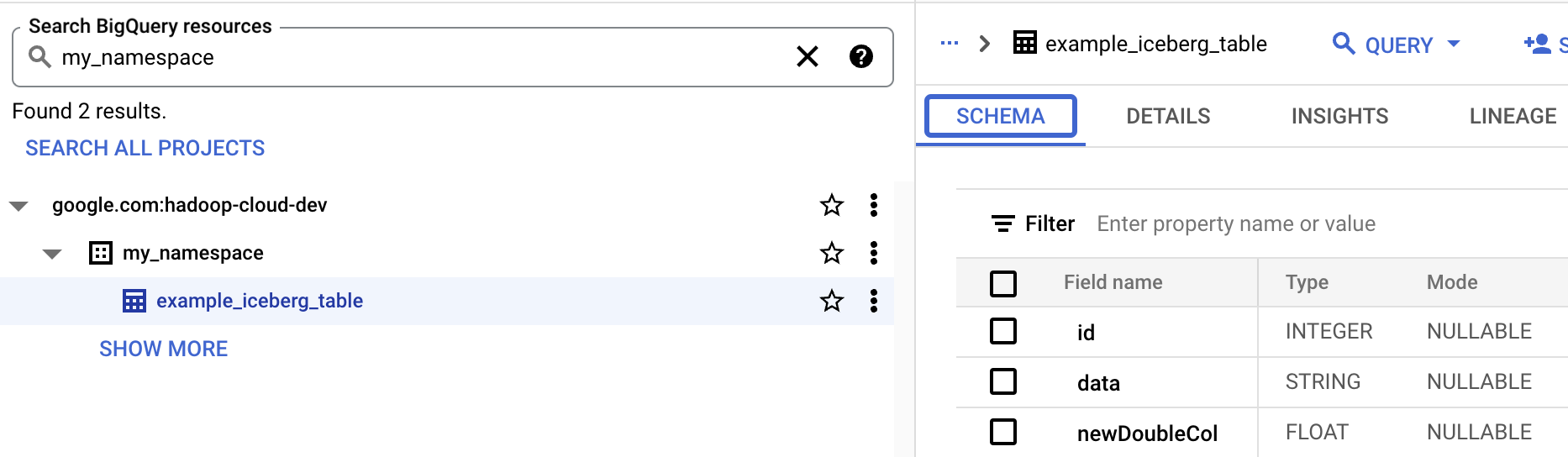
- BigQuery でテーブル スキーマを表示します。
- Google Cloud コンソールで、[BigQuery] ページに移動します。BigQuery Studio に移動します。
- Iceberg テーブルのメタデータを表示します。
OSS リソースと BigQuery リソースのマッピング
オープンソース リソースと BigQuery リソースの用語のマッピングは次のとおりです。
OSS リソース BigQuery リソース 名前空間、データベース データセット パーティション分割ありまたはパーティション分割なしのテーブル テーブル ビュー ビュー Iceberg テーブルを作成する
このセクションでは、Apache Spark 用サーバーレスの Spark SQL と PySpark バッチ ワークロードを使用して、メタデータが BigLake metastore に保存された Iceberg テーブルを作成する方法について説明します。
Spark SQL
Spark SQL ワークロードを実行して Iceberg テーブルを作成する
次の手順では、Serverless for Apache Spark Spark SQL バッチ ワークロードを実行して、テーブル メタデータが BigLake metastore に保存された Iceberg テーブルを作成する方法を示します。
PySpark
次の手順では、Serverless for Apache Spark PySpark バッチ ワークロードを実行して、テーブル メタデータが BigLake metastore に保存された Iceberg テーブルを作成する方法を示します。