In diesem Dokument wird beschrieben, wie Sie mit Dataplex Explore Anomalien in einem Datensatz mit Einzelhandelstransaktionen erkennen.
Mit der Workbench für die explorative Datenanalyse (Explore) können Datenanalysten große Datensätze interaktiv in Echtzeit abfragen und untersuchen. Mit Explore können Sie Statistiken zu Ihren Daten erstellen und in Cloud Storage und BigQuery gespeicherte Daten abfragen. Explore verwendet eine serverlose Spark-Plattform, sodass Sie die zugrunde liegende Infrastruktur nicht verwalten und skalieren müssen.
Lernziele
In diesem Anleitung werden die folgenden Aufgaben erläutert:
- Verwenden Sie die Spark SQL-Workbench von Explore, um Spark SQL-Abfragen zu schreiben und auszuführen.
- Verwenden Sie ein JupyterLab-Notebook, um die Ergebnisse aufzurufen.
- Sie können Ihr Notebook für eine wiederkehrende Ausführung planen, um Ihre Daten auf Anomalien zu prüfen.
Kosten
In diesem Dokument verwenden Sie die folgenden kostenpflichtigen Komponenten von Google Cloud:
Mit dem Preisrechner können Sie eine Kostenschätzung für Ihre voraussichtliche Nutzung vornehmen.
Nach Abschluss der in diesem Dokument beschriebenen Aufgaben können Sie weitere Kosten vermeiden, indem Sie die erstellten Ressourcen löschen. Weitere Informationen finden Sie unter Bereinigen.
Hinweis
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
- Install the Google Cloud CLI.
-
To initialize the gcloud CLI, run the following command:
gcloud init -
Create or select a Google Cloud project.
-
Create a Google Cloud project:
gcloud projects create
PROJECT_ID Replace
PROJECT_IDwith a name for the Google Cloud project you are creating. -
Select the Google Cloud project that you created:
gcloud config set project
PROJECT_ID Replace
PROJECT_IDwith your Google Cloud project name.
-
-
Make sure that billing is enabled for your Google Cloud project.
Daten für die explorative Datenanalyse vorbereiten
Laden Sie die Parquet-Datei
retail_offline_sales_marchherunter.So erstellen Sie einen Cloud Storage-Bucket mit dem Namen
offlinesales_curated:- In the Google Cloud console, go to the Cloud Storage Buckets page.
- Click Create bucket.
- On the Create a bucket page, enter your bucket information. To go to the next
step, click Continue.
- For Name your bucket, enter a name that meets the bucket naming requirements.
-
For Choose where to store your data, do the following:
- Select a Location type option.
- Select a Location option.
- For Choose a default storage class for your data, select a storage class.
- For Choose how to control access to objects, select an Access control option.
- For Advanced settings (optional), specify an encryption method, a retention policy, or bucket labels.
- Click Create.
Laden Sie die heruntergeladene Datei
offlinesales_march_parquetin den von Ihnen erstellten Cloud Storage-Bucketofflinesales_curatedhoch. Folgen Sie dazu der Anleitung unter Objekt aus einem Dateisystem hochladen.Erstellen Sie einen Dataplex-Lake und geben Sie ihm den Namen
operations. Folgen Sie dazu der Anleitung unter Lake erstellen.Fügen Sie dem See
operationseine Zone hinzu und geben Sie ihr den Namenprocurement. Folgen Sie dazu der Anleitung unter Zone hinzufügen.Fügen Sie in der
procurement-Zone den von Ihnen erstelltenofflinesales_curated-Cloud Storage-Bucket als Asset hinzu. Folgen Sie dazu der Anleitung unter Asset hinzufügen.
Tabelle für die explorative Datenanalyse auswählen
Rufen Sie in der Google Cloud Console die Seite Dataplex Explore auf.
Wählen Sie im Feld See den See
operationsaus.Klicken Sie auf den See
operations.Rufen Sie die Zone
procurementauf und klicken Sie auf die Tabelle, um die zugehörigen Metadaten zu sehen.Auf dem folgenden Bild enthält die ausgewählte Beschaffungszone die Tabelle
Offlinemit den Metadatenorderid,product,quantityordered,unitprice,orderdateundpurchaseaddress.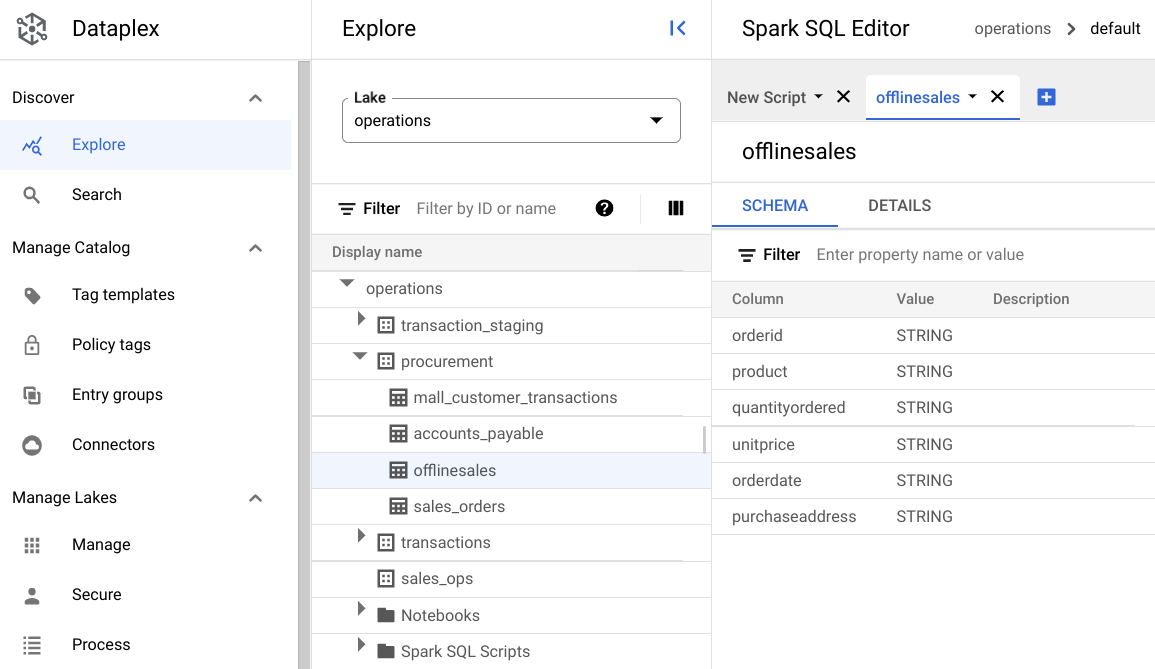
Klicken Sie im Spark SQL-Editor auf Hinzufügen. Ein Spark SQL-Script wird angezeigt.
Optional: Öffnen Sie das Script im Splitscreen-Modus, um die Metadaten und das neue Script nebeneinander zu sehen. Klicken Sie auf dem neuen Scripttab auf das Dreipunkt-Menü Mehr und wählen Sie Tab nach rechts aufteilen oder Tab nach links aufteilen aus.
Öffentliche Daten durchsuchen
Eine Umgebung stellt serverlose Computing-Ressourcen für Ihre Spark SQL-Abfragen und ‑Notebooks bereit, die in einem Lake ausgeführt werden. Bevor Sie Spark SQL-Abfragen schreiben, erstellen Sie eine Umgebung, in der Sie Ihre Abfragen ausführen.
Mit den folgenden SparkSQL-Abfragen können Sie Ihre Daten untersuchen. Geben Sie im SparkSQL-Editor die Abfrage im Bereich Neues Script ein.
Beispiel für 10 Zeilen der Tabelle
Geben Sie die folgende Abfrage ein:
select * from procurement.offlinesales where orderid != 'orderid' limit 10;Klicken Sie auf Ausführen.
Gesamtzahl der Transaktionen im Datensatz abrufen
Geben Sie die folgende Abfrage ein:
select count(*) from procurement.offlinesales where orderid!='orderid';Klicken Sie auf Ausführen.
Anzahl der verschiedenen Produkttypen im Datensatz ermitteln
Geben Sie die folgende Abfrage ein:
select count(distinct product) from procurement.offlinesales where orderid!='orderid';Klicken Sie auf Ausführen.
Produkte mit hohem Transaktionswert ermitteln
Sie können sich ein Bild davon machen, welche Produkte einen hohen Transaktionswert haben, indem Sie die Verkäufe nach Produkttyp und durchschnittlichem Verkaufspreis aufschlüsseln.
Geben Sie die folgende Abfrage ein:
select product,avg(quantityordered * unitprice) as avg_sales_amount from procurement.offlinesales where orderid!='orderid' group by product order by avg_sales_amount desc;Klicken Sie auf Ausführen.
Auf dem folgenden Bild ist ein Results-Bereich zu sehen, in dem die Artikel mit hohen Transaktionswerten in der Spalte avg_sales_amount anhand der Spalte product identifiziert werden.
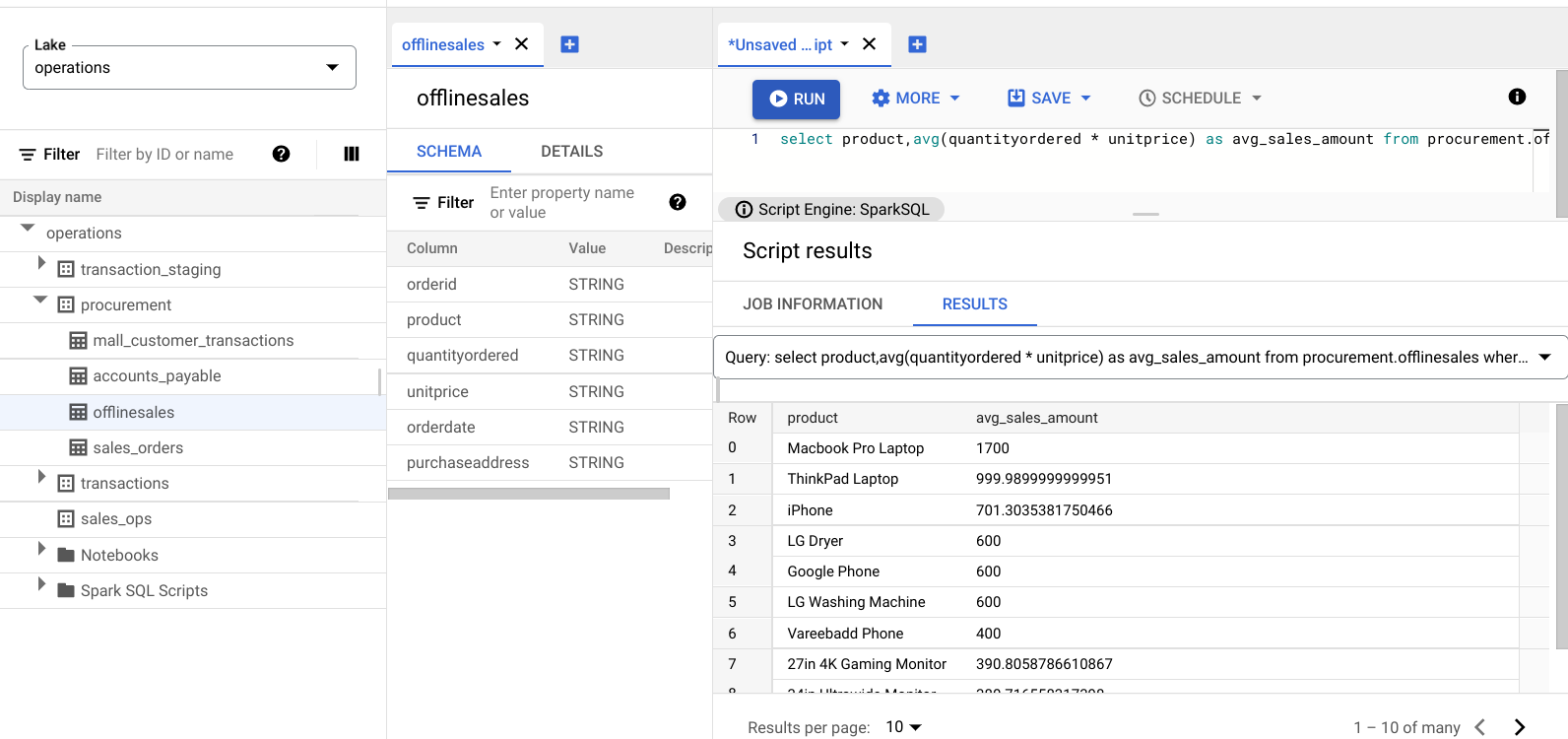
Anomalien mit dem Variationskoeffizienten erkennen
Die letzte Abfrage hat gezeigt, dass Laptops einen hohen durchschnittlichen Transaktionsbetrag haben. In der folgenden Abfrage wird veranschaulicht, wie Laptoptransaktionen erkannt werden, die im Datensatz nicht anormal sind.
In der folgenden Abfrage wird der Messwert „Variationskoeffizient“, rsd_value, verwendet, um Transaktionen zu finden, die nicht ungewöhnlich sind und bei denen die Streuung der Werte im Vergleich zum Mittelwert niedrig ist. Ein niedrigerer Variationskoeffizient weist auf weniger Anomalien hin.
Geben Sie die folgende Abfrage ein:
WITH stats AS ( SELECT product, AVG(quantityordered * unitprice) AS avg_value, STDDEV(quantityordered * unitprice) / AVG(quantityordered * unitprice) AS rsd_value FROM procurement.offlinesales GROUP BY product) SELECT orderid, orderdate, product, (quantityordered * unitprice) as sales_amount, ABS(1 - (quantityordered * unitprice)/ avg_value) AS distance_from_avg FROM procurement.offlinesales INNER JOIN stats USING (product) WHERE rsd_value <= 0.2 ORDER BY distance_from_avg DESC LIMIT 10Klicken Sie auf Ausführen.
Ergebnisse des Scripts ansehen
Im folgenden Bild wird in einem Ergebnisbereich die Spalte „Produkt“ verwendet, um die Verkaufsartikel mit Transaktionswerten zu identifizieren, die innerhalb des Variationskoeffizienten von 0,2 liegen.
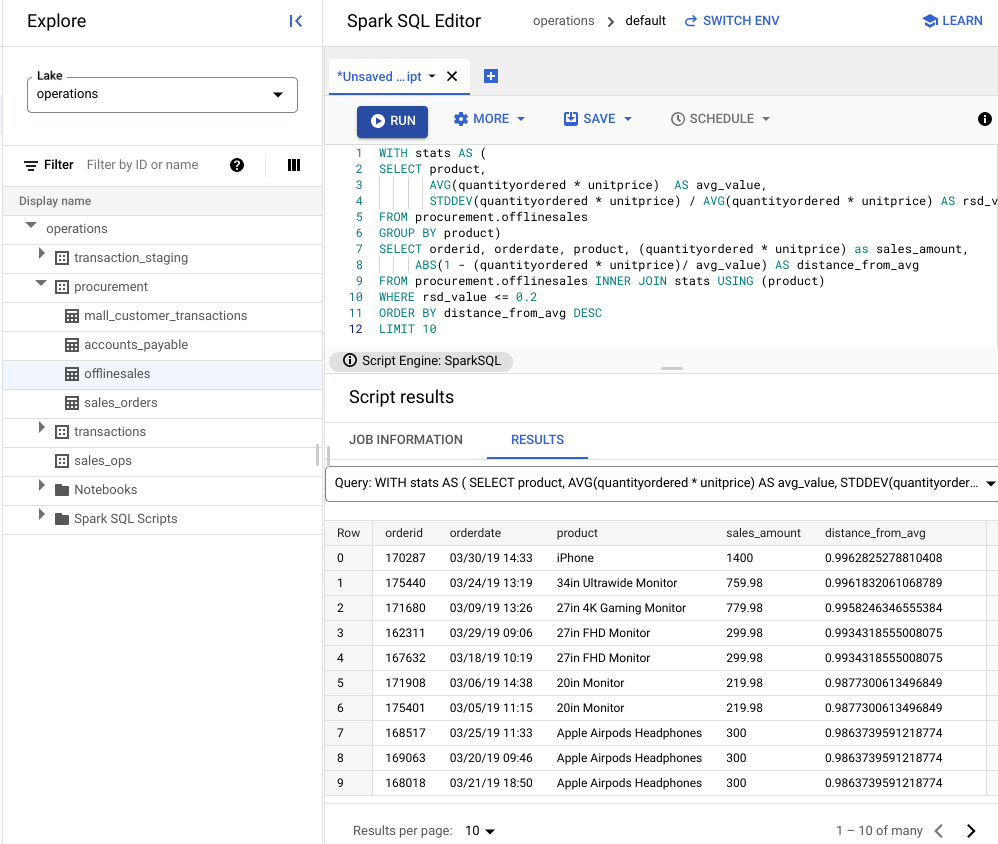
Anomalien mit einem JupyterLab-Notebook visualisieren
Erstellen Sie ein ML-Modell, um Anomalien im großen Maßstab zu erkennen und zu visualisieren.
Öffnen Sie das Notizbuch in einem separaten Tab und warten Sie, bis es geladen ist. Die Sitzung, in der Sie die Spark SQL-Abfragen ausgeführt haben, wird fortgesetzt.
Importieren Sie die erforderlichen Pakete und stellen Sie eine Verbindung zur externen BigQuery-Tabelle her, die die Transaktionsdaten enthält. Führen Sie den folgenden Code aus:
from google.cloud import bigquery from google.api_core.client_options import ClientOptions import os import warnings warnings.filterwarnings('ignore') import pandas as pd project = os.environ['GOOGLE_CLOUD_PROJECT'] options = ClientOptions(quota_project_id=project) client = bigquery.Client(client_options=options) client = bigquery.Client() #Load data into DataFrame sql = '''select * from procurement.offlinesales limit 100;''' df = client.query(sql).to_dataframe()Führen Sie den Isolation Forest-Algorithmus aus, um die Anomalien im Datensatz zu ermitteln:
to_model_columns = df.columns[2:4] from sklearn.ensemble import IsolationForest clf=IsolationForest(n_estimators=100, max_samples='auto', contamination=float(.12), \ max_features=1.0, bootstrap=False, n_jobs=-1, random_state=42, verbose=0) clf.fit(df[to_model_columns]) pred = clf.predict(df[to_model_columns]) df['anomaly']=pred outliers=df.loc[df['anomaly']==-1] outlier_index=list(outliers.index) #print(outlier_index) #Find the number of anomalies and normal points here points classified -1 are anomalous print(df['anomaly'].value_counts())Zeichnen Sie die vorhergesagten Anomalien mit einer Matplotlib-Visualisierung auf:
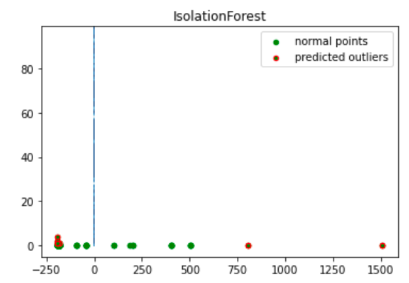
import numpy as np from sklearn.decomposition import PCA pca = PCA(2) pca.fit(df[to_model_columns]) res=pd.DataFrame(pca.transform(df[to_model_columns])) Z = np.array(res) plt.title("IsolationForest") plt.contourf( Z, cmap=plt.cm.Blues_r) b1 = plt.scatter(res[0], res[1], c='green', s=20,label="normal points") b1 =plt.scatter(res.iloc[outlier_index,0],res.iloc[outlier_index,1], c='green',s=20, edgecolor="red",label="predicted outliers") plt.legend(loc="upper right") plt.show()
Auf diesem Bild sind die Transaktionsdaten zu sehen, wobei die Anomalien rot hervorgehoben sind.
Notebook planen
Im Explore können Sie ein Notebook so planen, dass es regelmäßig ausgeführt wird. Folgen Sie der Anleitung, um das von Ihnen erstellte Jupyter-Notebook zu planen.
Dataplex erstellt eine geplante Aufgabe, um Ihr Notebook regelmäßig auszuführen. Klicken Sie auf Zeitpläne ansehen, um den Fortschritt der Aufgabe zu verfolgen.
Notebook freigeben oder exportieren
In Explore können Sie ein Notizbuch mit anderen Nutzern in Ihrer Organisation über IAM-Berechtigungen teilen.
Prüfen Sie die Rollen. Weisen Sie Nutzern für dieses Notebook die Rollen „Dataplex-Betrachter“ (roles/dataplex.viewer), „Dataplex-Bearbeiter“ (roles/dataplex.editor) und „Dataplex-Administrator“ (roles/dataplex.admin) zu oder widerrufen Sie sie. Nachdem Sie ein Notebook freigegeben haben, können Nutzer mit der Rolle „Betrachter“ oder „Bearbeiter“ auf Ebene des Datensees den Datensee aufrufen und am freigegebenen Notebook arbeiten.
Weitere Informationen zum Freigeben oder Exportieren eines Notebooks finden Sie unter Notebook freigeben oder Notebook exportieren.
Bereinigen
Damit Ihrem Google Cloud-Konto die in dieser Anleitung verwendeten Ressourcen nicht in Rechnung gestellt werden, löschen Sie entweder das Projekt, das die Ressourcen enthält, oder Sie behalten das Projekt und löschen die einzelnen Ressourcen.
Projekt löschen
Delete a Google Cloud project:
gcloud projects deletePROJECT_ID
Einzelne Ressourcen löschen
-
Löschen Sie den Bucket:
gcloud storage buckets delete
BUCKET_NAME -
Löschen Sie die Instanz:
gcloud compute instances delete
INSTANCE_NAME