Cloud Profiler 是一个低开销的统计性能剖析器,可从生产应用中持续收集有关 CPU 使用情况和内存分配情况的信息。如需了解详情,请参阅性能剖析相关概念。要排查或监控流水线性能的问题,请使用 Dataflow 与 Cloud Profiler 的集成来确定流水线代码中资源耗用量最大的部分。
如需了解构建或运行 Dataflow 流水线的问题排查提示和调试策略,请参阅排查和调试流水线。
准备工作
了解性能剖析相关概念并熟悉性能分析器界面。如需了解如何开始使用性能分析器界面,请参阅选择要分析的性能剖析文件。
在启动作业之前,必须为您的项目启用 Cloud Profiler API。您首次访问 Profiler 页面时,它会自动启用。或者,您可以使用 Google Cloud CLI gcloud 命令行工具或 Google Cloud 控制台启用 Cloud Profiler API。
如需使用 Cloud Profiler,您的项目必须具有足够的配额。此外,Dataflow 作业的工作器服务账号必须具有 Profiler 的适当权限。例如,如需创建配置文件,工作器服务账号必须具有 cloudprofiler.profiles.create 权限,Cloud Profiler Agent (roles/cloudprofiler.agent) IAM 角色可提供此权限。如需了解详情,请参阅使用 IAM 进行访问权限控制。
为 Dataflow 流水线启用 Cloud Profiler
Cloud Profiler 可用于使用 Java 版和 Python 版 Apache Beam SDK 2.33.0 或更高版本编写的 Dataflow 流水线。Python 流水线必须使用 Dataflow Runner v2。可以在流水线启动时启用 Cloud Profiler。您的流水线分摊的 CPU 和内存开销预计小于 1%。
Java
如需启用 CPU 性能剖析,请使用以下选项启动流水线。
--dataflowServiceOptions=enable_google_cloud_profiler
如需启用堆性能剖析,请使用以下选项启动流水线。堆性能剖析需要使用 Java 11 或更高版本。
--dataflowServiceOptions=enable_google_cloud_profiler
--dataflowServiceOptions=enable_google_cloud_heap_sampling
Python
如需使用 Cloud Profiler,您的 Python 流水线必须使用 Dataflow Runner v2 运行。
如需启用 CPU 性能剖析,请使用以下选项启动流水线。堆性能剖析功能尚不支持用于 Python。
--dataflow_service_options=enable_google_cloud_profiler
Go
如需启用 CPU 和堆性能剖析,请使用以下选项启动流水线。
--dataflow_service_options=enable_google_cloud_profiler
如果您通过 Dataflow 模板部署流水线并希望启用 Cloud Profiler,请将 enable_google_cloud_profiler 和 enable_google_cloud_heap_sampling 标志指定为额外的实验。
控制台
如果您使用 Google 提供的模板,则可以在 Dataflow 基于模板创建作业页面的额外实验字段中指定这些标志。
gcloud
如果您使用 Google Cloud CLI 运行模板(gcloud
dataflow jobs run 或 gcloud dataflow flex-template run,具体取决于模板类型),请使用 --additional-
experiments 选项来指定这些标志。
API
如果您使用 REST API 运行模板,请使用运行时环境(RuntimeEnvironment 或 FlexTemplateRuntimeEnvironment,具体取决于模板类型)的 additionalExperiments 字段来指定这些标志。
查看性能分析数据
如果启用了 Cloud Profiler,则作业页面上将显示指向 Profiler 页面的链接。
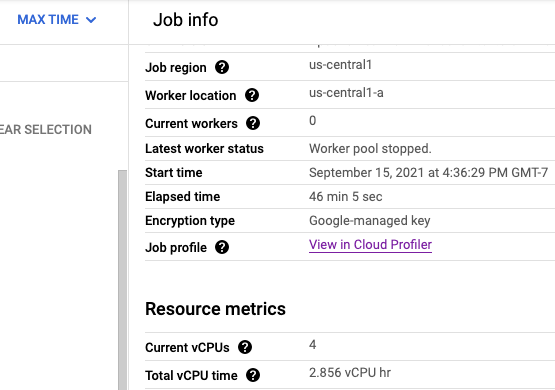
您可以在 Profiler 页面上找到 Dataflow 流水线的性能剖析数据。Service 是您的作业名称,Version 是您的作业 ID。

使用 Cloud Profiler
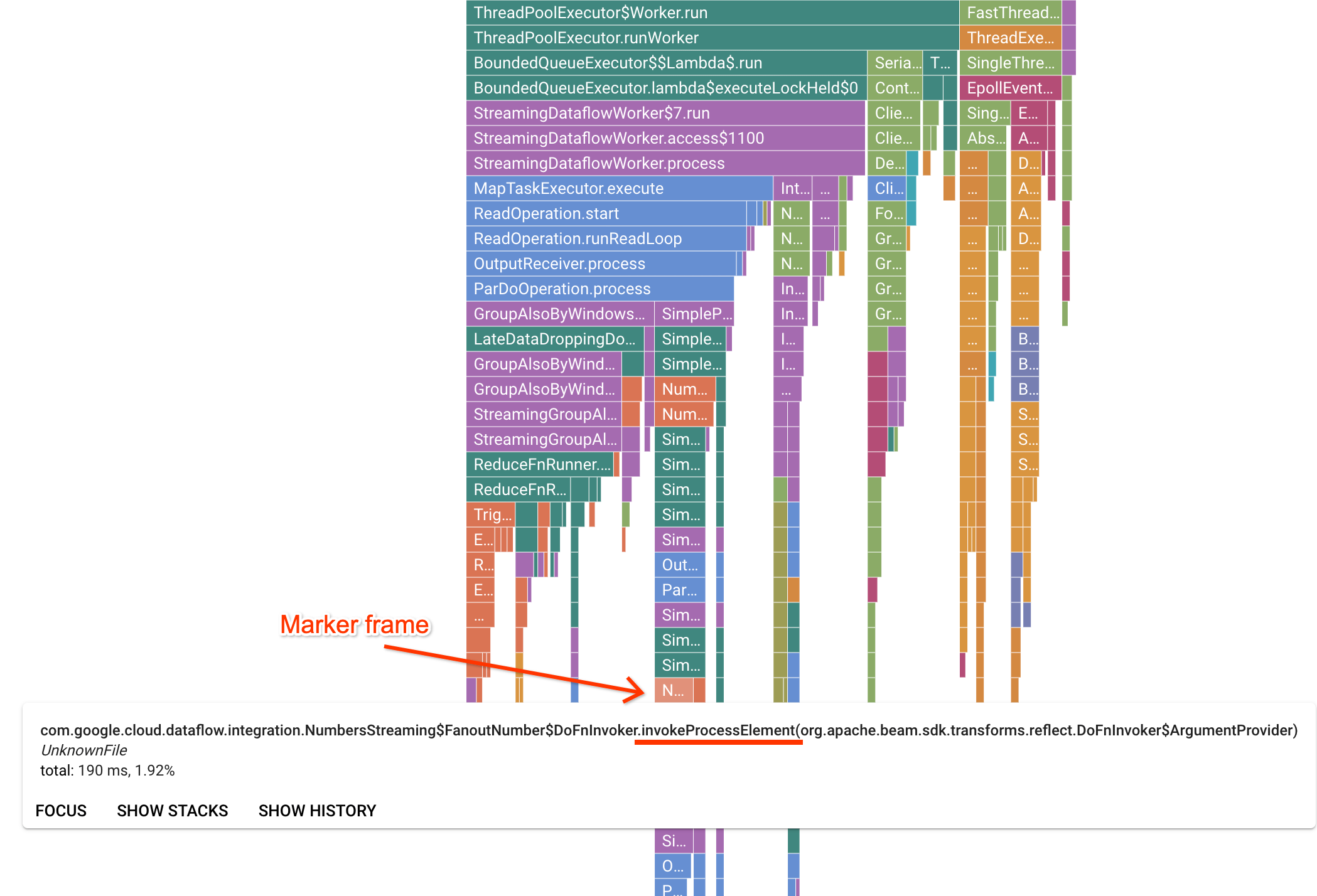
Profiler 页面包含一个火焰图,其中显示工作器上运行的每个帧的统计信息。 在水平方向上,您可以查看每个帧在 CPU 时间方面的执行时间。在垂直方向上,您可以看到堆栈轨迹和并行运行的代码。堆栈轨迹由运行程序基础架构代码主导。出于调试目的,我们通常关注用户代码执行,它通常位于图表底部提示附近。通过查找标记帧(表示已知仅调用用户代码的运行程序代码),可以识别用户代码。对于 Beam ParDo 运行程序,系统会创建一个动态适配器层来调用用户提供的 DoFn 方法签名。此层可以标识为具有 invokeProcessElement 后缀的帧。 下图展示了如何查找标记帧。
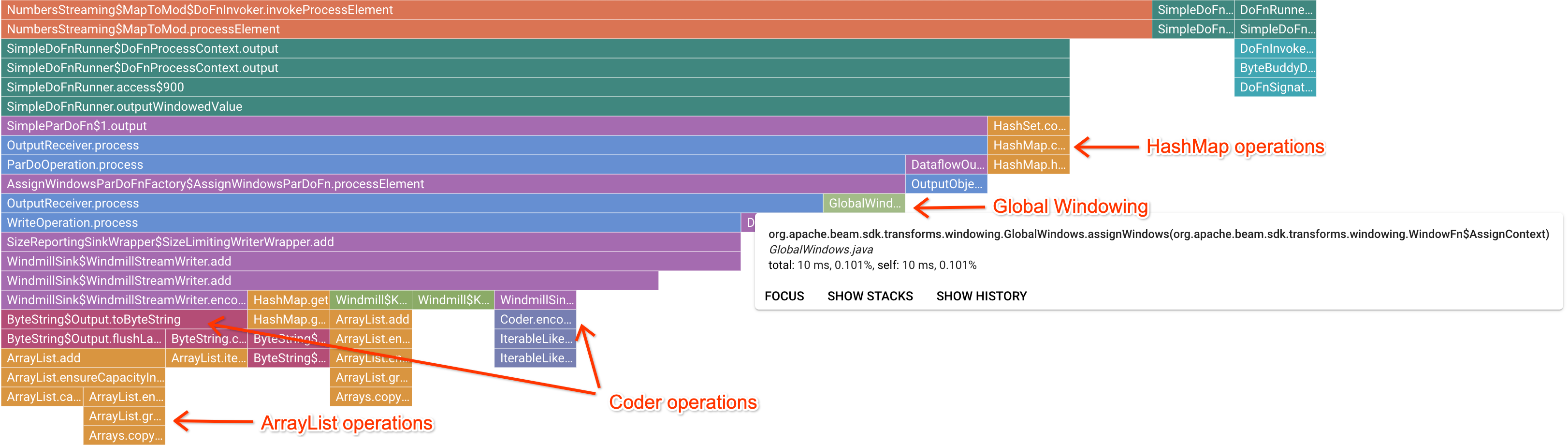
点击感兴趣的标记帧后,火焰图会聚焦于堆栈轨迹,从而充分显示长时间运行的用户代码。 最慢的操作可以指明形成瓶颈的位置,并提供优化机会。在以下示例中,您可以看到全局数据选取与 ByteArrayCoder 结合使用。 在这种情况下,编码器可能是很好的优化领域,因为它与 ArrayList 和 HashMap 操作相比,占用了大量 CPU 时间。
排查 Cloud Profiler 问题
如果您启用了 Cloud Profiler,但您的流水线并未生成性能剖析数据,则可能是由以下某个原因造成。
您的流水线使用的是较旧的 Apache Beam SDK 版本。如需使用 Cloud Profiler,您需要使用 Apache Beam SDK 2.33.0 版或更高版本。您可以在作业页面上查看流水线的 Apache Beam SDK 版本。如果您的作业是通过 Dataflow 模板创建的,则这些模板必须使用受支持的 SDK 版本。
您的项目即将用尽 Cloud Profiler 配额。您可以在项目的配额页面中查看配额用量。如果超出 Cloud Profiler 配额,则可能会发生错误,例如
Failed to collect and upload profile whose profile type is WALL。如果已用尽配额,Cloud Profiler 服务将拒绝性能剖析数据。 如需详细了解 Cloud Profiler 配额,请参阅配额和限制。
Cloud Profiler 代理在 Dataflow 工作器启动过程中安装。Cloud Profiler 生成的日志消息可在 dataflow.googleapis.com/worker-startup 类型的日志中获得。
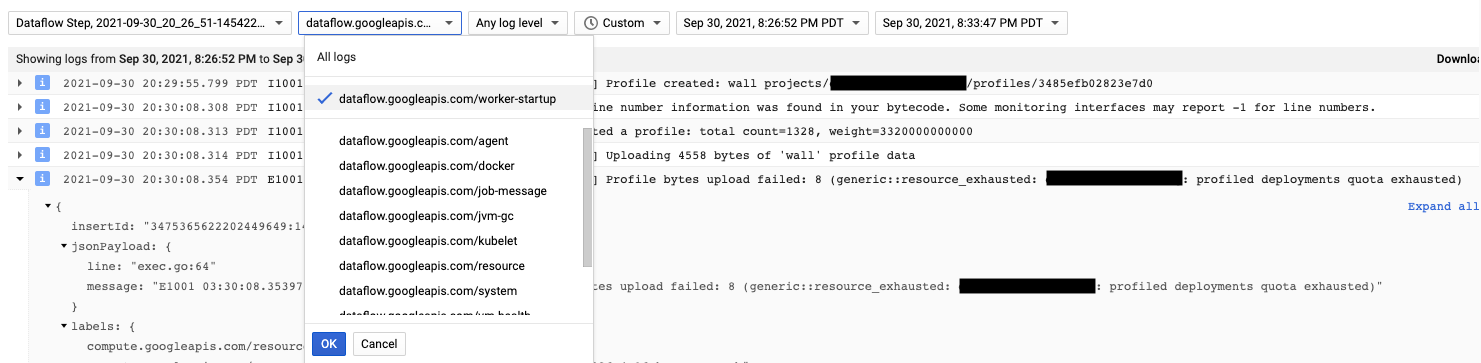
有时,存在性能剖析数据,但 Cloud Profiler 不显示任何输出。Profiler 会显示类似 There were
profiles collected for the specified time range, but none match the current
filters 的消息。
如需解决此问题,请尝试执行以下问题排查步骤。
确保 Profiler 中的时间跨度和结束时间覆盖作业的运行时间。
确认在 Profiler 中选择了正确的作业。服务是您的作业名称。
确认
job_name流水线选项的值与 Dataflow 作业页面上的作业名称相同。如果您在加载 Profiler 代理时指定了 service-name 参数,请确认服务名称已正确配置。