本页面介绍了问题排查技巧和调试策略,如果您在构建或运行 Dataflow 流水线时遇到问题,这些技巧和策略可能会派上用场。本文的内容可以帮助您检测流水线故障,确定流水线运行失败的原因,并推荐了一些可用来纠正问题的操作流程。
下图展示了本页面介绍的 Dataflow 问题排查工作流。

Dataflow 会提供与您的作业有关的实时反馈和一组基本步骤,可供您用来检查错误消息、日志和作业进度停滞等情况。
如需获取有关运行 Dataflow 作业时可能遇到的常见错误的指南,请参阅排查 Dataflow 错误。如需监控流水线性能并排查问题,请参阅监控流水线性能。
流水线的最佳实践
以下是 Java、Python 和 Go 流水线的最佳实践。
Java
对于批量作业,我们建议您为临时位置设置存留时间 (TTL)。
在设置 TTL 之前,最好确保将暂存位置和临时位置设置为不同的位置。
不要删除暂存位置中的对象,因为这些对象将被重复使用。
如果作业完成或停止并且临时对象没有被清理,请从用作临时位置的 Cloud Storage 存储桶中手动移除这些文件。
Python
临时位置和暂存位置的前缀为 <job_name>.<time>。
确保您将暂存位置和临时位置设置为不同的位置。
如果需要,您可以在作业完成或停止后删除暂存位置中的对象。此外,暂存对象不会在 Python 流水线中重复使用。
如果作业结束并且临时对象没有被清理,请从用作临时位置的 Cloud Storage 存储桶中手动移除这些文件。
对于批处理作业,我们建议您为临时和暂存位置设置存留时间 (TTL)。
Go
临时位置和暂存位置的前缀为
<job_name>.<time>。确保您将暂存位置和临时位置设置为不同的位置。
如果需要,您可以在作业完成或停止后删除暂存位置中的对象。此外,暂存对象不会在 Go 流水线中重复使用。
如果作业结束并且临时对象没有被清理,请从用作临时位置的 Cloud Storage 存储桶中手动移除这些文件。
对于批处理作业,我们建议您为临时和暂存位置设置存留时间 (TTL)。
检查流水线状态
您可以使用 Dataflow 监控界面检测流水线运行中的任何错误。
- 前往 Google Cloud 控制台。
- 从项目列表中选择您的 Google Cloud Platform 项目。
- 在导航菜单的大数据下,点击 Dataflow。 右侧窗格中将显示正在运行的作业的列表。
- 选择要查看的流水线作业。您可以在状态字段中快速查看作业状态:“正在运行”“成功”或“失败”。

查找有关流水线故障的信息
如果其中一个流水线作业失败,您可以选择作业以查看有关错误和运行结果的详细信息。选择作业后,您可以查看流水线的关键图表、执行图、作业信息面板以及具有作业日志、工作器日志、诊断和建议标签页的日志面板。
查看作业错误消息
要查看由流水线代码和 Dataflow 服务生成的作业日志,请在日志面板中点击segment显示。
您可以通过点击信息arrow_drop_down 和 filter_list过滤来过滤作业日志中显示的消息。如需仅显示错误消息,请点击信息arrow_drop_down,然后选择错误。
如需展开错误消息,请点击可展开部分 arrow_right。
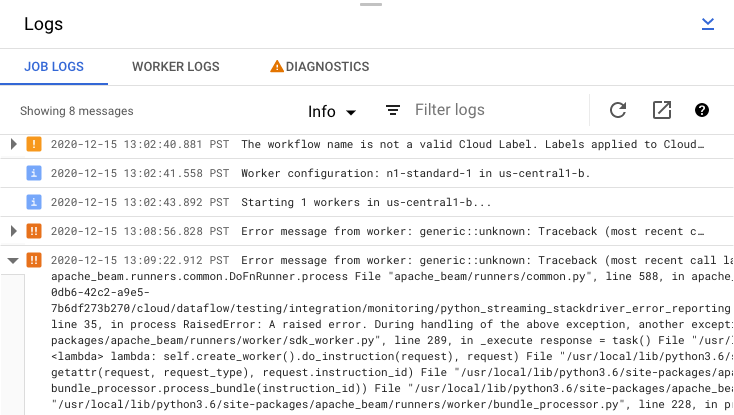
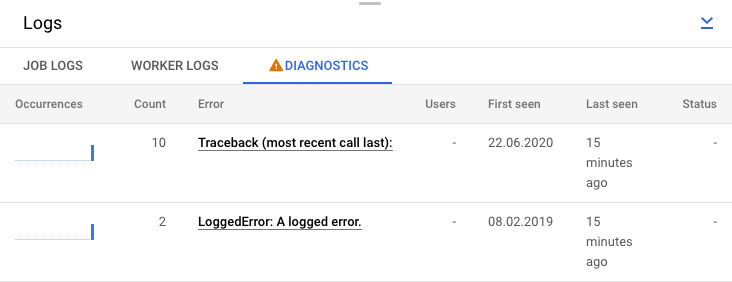
或者,您也可以点击诊断标签页。此标签页会显示沿所选时间轴发生的错误、所有已记录错误的数量以及关于流水线的可能建议。
查看作业的步骤日志
在流水线图中选择步骤时,日志面板将不再显示 Dataflow 服务生成的作业日志,而是改为显示运行流水线步骤的 Compute Engine 实例中的日志。
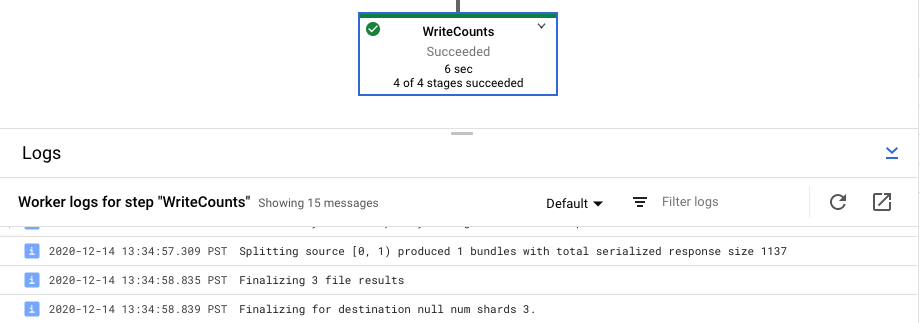
Cloud Logging 会将从项目的 Compute Engine 实例中收集的所有日志合并到一个位置。如需详细了解如何使用 Dataflow 的各种日志记录功能,请参阅日志记录流水线消息。
处理自动拒绝流水线操作
在某些情况下,Dataflow 服务会识别出您的流水线可能触发已知的 SDK 问题。为了阻止提交可能遇到问题的流水线,Dataflow 会自动拒绝您的流水线并显示以下消息:
The workflow was automatically rejected by the service because it might trigger an identified bug in the SDK (details below). If you think this identification is in error, and would like to override this automated rejection, please re-submit this workflow with the following override flag: [OVERRIDE FLAG]. Bug details: [BUG DETAILS]. Contact Google Cloud Support for further help. Please use this identifier in your communication: [BUG ID].
在阅读链接的错误详情中的警告后,如果您仍然想尝试运行流水线,则可以替换自动拒绝操作。添加 --experiments=<override-flag> 标志,然后重新提交您的流水线。
确定流水线失败的原因
通常,失败的 Apache Beam 流水线运行可归因于以下原因之一:
- 图表或流水线构造错误。如果 Dataflow 按照 Apache Beam 流水线的描述,在构建用于组成流水线的步骤图时遇到问题,就会发生这些错误。
- 作业验证错误。Dataflow 服务会验证您启动的任何流水线作业。验证过程中发现的错误可能会阻止您成功创建或执行作业。验证错误可能包括 Google Cloud 项目的 Cloud Storage 存储桶问题,也可能包括项目的权限问题。
- 工作器代码异常。如果用户提供的代码中存在错误,且 Dataflow 将该代码分发给并行工作器(例如
ParDo转换的DoFn实例),就会发生这些错误。 - 其他 Google Cloud 服务中的暂时性故障导致的错误。如果 Dataflow 所依赖的Google Cloud 服务(例如 Compute Engine 或 Cloud Storage)出现临时中断或其他问题,您的流水线可能会因此而失败。
检测图表或流水线构造错误
当 Dataflow 从您的 Dataflow 程序中的代码构建流水线的执行图表时,可能会发生图表构造错误。在构建图表期间,Dataflow 会检查非法操作。
请注意,如果 Dataflow 在图表构造期间检测到错误,系统将不会在 Dataflow 服务上创建任何作业。因此,您不会在 Dataflow 监控界面中看到任何反馈。 运行 Apache Beam 流水线的控制台或终端窗口中会显示如下错误消息:
Java
例如,如果您的流水线尝试对一个全局窗口化、非触发、无界限的 PCollection 执行 GroupByKey 等聚合操作,则系统会显示类似于以下内容的错误消息:
... ... Exception in thread "main" java.lang.IllegalStateException: ... GroupByKey cannot be applied to non-bounded PCollection in the GlobalWindow without a trigger. ... Use a Window.into or Window.triggering transform prior to GroupByKey ...
Python
例如,如果您的流水线使用类型提示并且其中一项转换中的参数类型不符合预期,则系统会显示类似于以下内容的错误消息:
... in <module> run()
... in run | beam.Map('count', lambda (word, ones): (word, sum(ones))))
... in __or__ return self.pipeline.apply(ptransform, self)
... in apply transform.type_check_inputs(pvalueish)
... in type_check_inputs self.type_check_inputs_or_outputs(pvalueish, 'input')
... in type_check_inputs_or_outputs pvalue_.element_type))
google.cloud.dataflow.typehints.decorators.TypeCheckError: Input type hint violation at group: expected Tuple[TypeVariable[K], TypeVariable[V]], got <type 'str'>
Go
例如,如果您的流水线使用不接受任何输入的“DoFn”,则会出现类似于以下内容的错误消息:
... panic: Method ProcessElement in DoFn main.extractFn is missing all inputs. A main input is required. ... Full error: ... inserting ParDo in scope root/CountWords ... graph.AsDoFn: for Fn named main.extractFn ... ProcessElement method has no main inputs ... goroutine 1 [running]: ... github.com/apache/beam/sdks/v2/go/pkg/beam.MustN(...) ... (more stacktrace)
如果您遇到此类错误,请检查流水线代码,以确保您的流水线操作是正确的。
检测 Dataflow 作业验证中的错误
一旦 Dataflow 服务收到您的流水线图表,就会尝试验证您的作业。此验证包括以下内容:
- 确保该服务可以访问作业的相关 Cloud Storage 存储分区,以执行文件暂存和临时输出。
- 在 Google Cloud 项目中检查所需的权限。
- 确保该服务可以访问输入和输出来源(如文件)。
如果您的作业未通过验证,Dataflow 监控界面以及您的控制台或终端窗口中将显示错误消息(前提是您使用了“阻止执行”功能)。错误消息类似于以下形式:
Java
INFO: To access the Dataflow monitoring console, please navigate to
https://console.developers.google.com/project/google.com%3Aclouddfe/dataflow/job/2016-03-08_18_59_25-16868399470801620798
Submitted job: 2016-03-08_18_59_25-16868399470801620798
...
... Starting 3 workers...
... Executing operation BigQuery-Read+AnonymousParDo+BigQuery-Write
... Executing BigQuery import job "dataflow_job_16868399470801619475".
... Stopping worker pool...
... Workflow failed. Causes: ...BigQuery-Read+AnonymousParDo+BigQuery-Write failed.
Causes: ... BigQuery getting table "non_existent_table" from dataset "cws_demo" in project "my_project" failed.
Message: Not found: Table x:cws_demo.non_existent_table HTTP Code: 404
... Worker pool stopped.
... com.google.cloud.dataflow.sdk.runners.BlockingDataflowPipelineRunner run
INFO: Job finished with status FAILED
Exception in thread "main" com.google.cloud.dataflow.sdk.runners.DataflowJobExecutionException:
Job 2016-03-08_18_59_25-16868399470801620798 failed with status FAILED
at com.google.cloud.dataflow.sdk.runners.DataflowRunner.run(DataflowRunner.java:155)
at com.google.cloud.dataflow.sdk.runners.DataflowRunner.run(DataflowRunner.java:56)
at com.google.cloud.dataflow.sdk.Pipeline.run(Pipeline.java:180)
at com.google.cloud.dataflow.integration.BigQueryCopyTableExample.main(BigQueryCopyTableExample.java:74)
Python
INFO:root:Created job with id: [2016-03-08_14_12_01-2117248033993412477] ... Checking required Cloud APIs are enabled. ... Job 2016-03-08_14_12_01-2117248033993412477 is in state JOB_STATE_RUNNING. ... Combiner lifting skipped for step group: GroupByKey not followed by a combiner. ... Expanding GroupByKey operations into optimizable parts. ... Lifting ValueCombiningMappingFns into MergeBucketsMappingFns ... Annotating graph with Autotuner information. ... Fusing adjacent ParDo, Read, Write, and Flatten operations ... Fusing consumer split into read ... ... Starting 1 workers... ... ... Executing operation read+split+pair_with_one+group/Reify+group/Write ... Executing failure step failure14 ... Workflow failed. Causes: ... read+split+pair_with_one+group/Reify+group/Write failed. Causes: ... Unable to view metadata for files: gs://dataflow-samples/shakespeare/missing.txt. ... Cleaning up. ... Tearing down pending resources... INFO:root:Job 2016-03-08_14_12_01-2117248033993412477 is in state JOB_STATE_FAILED.
Go
Go 目前不支持本部分中介绍的作业验证。因这些问题而引发的错误会显示为工作器异常。
检测工作器代码异常
当您的作业运行时,您可能会遇到工作器代码错误或异常。这些错误通常表示流水线代码中的 DoFn 产生了未处理的异常,这种异常会导致 Dataflow 作业中的任务失败。
Dataflow 监控界面会报告用户代码(例如 DoFn 实例)中的异常。如果您使用“阻止执行”功能运行流水线,则系统会在控制台或终端窗口中输出错误消息,如下所示:
Java
INFO: To access the Dataflow monitoring console, please navigate to https://console.developers.google.com/project/example_project/dataflow/job/2017-05-23_14_02_46-1117850763061203461
Submitted job: 2017-05-23_14_02_46-1117850763061203461
...
... To cancel the job using the 'gcloud' tool, run: gcloud beta dataflow jobs --project=example_project cancel 2017-05-23_14_02_46-1117850763061203461
... Autoscaling is enabled for job 2017-05-23_14_02_46-1117850763061203461.
... The number of workers will be between 1 and 15.
... Autoscaling was automatically enabled for job 2017-05-23_14_02_46-1117850763061203461.
...
... Executing operation BigQueryIO.Write/BatchLoads/Create/Read(CreateSource)+BigQueryIO.Write/BatchLoads/GetTempFilePrefix+BigQueryIO.Write/BatchLoads/TempFilePrefixView/BatchViewOverrides.GroupByWindowHashAsKeyAndWindowAsSortKey/ParDo(UseWindowHashAsKeyAndWindowAsSortKey)+BigQueryIO.Write/BatchLoads/TempFilePrefixView/Combine.GloballyAsSingletonView/Combine.globally(Singleton)/WithKeys/AddKeys/Map/ParMultiDo(Anonymous)+BigQueryIO.Write/BatchLoads/TempFilePrefixView/Combine.GloballyAsSingletonView/Combine.globally(Singleton)/Combine.perKey(Singleton)/GroupByKey/Reify+BigQueryIO.Write/BatchLoads/TempFilePrefixView/Combine.GloballyAsSingletonView/Combine.globally(Singleton)/Combine.perKey(Singleton)/GroupByKey/Write+BigQueryIO.Write/BatchLoads/TempFilePrefixView/BatchViewOverrides.GroupByWindowHashAsKeyAndWindowAsSortKey/BatchViewOverrides.GroupByKeyAndSortValuesOnly/Write
... Workers have started successfully.
...
... org.apache.beam.runners.dataflow.util.MonitoringUtil$LoggingHandler process SEVERE: 2017-05-23T21:06:33.711Z: (c14bab21d699a182): java.lang.RuntimeException: org.apache.beam.sdk.util.UserCodeException: java.lang.ArithmeticException: / by zero
at com.google.cloud.dataflow.worker.runners.worker.GroupAlsoByWindowsParDoFn$1.output(GroupAlsoByWindowsParDoFn.java:146)
at com.google.cloud.dataflow.worker.runners.worker.GroupAlsoByWindowFnRunner$1.outputWindowedValue(GroupAlsoByWindowFnRunner.java:104)
at com.google.cloud.dataflow.worker.util.BatchGroupAlsoByWindowAndCombineFn.closeWindow(BatchGroupAlsoByWindowAndCombineFn.java:191)
...
... Cleaning up.
... Stopping worker pool...
... Worker pool stopped.
Python
INFO:root:Job 2016-03-08_14_21_32-8974754969325215880 is in state JOB_STATE_RUNNING. ... INFO:root:... Expanding GroupByKey operations into optimizable parts. INFO:root:... Lifting ValueCombiningMappingFns into MergeBucketsMappingFns INFO:root:... Annotating graph with Autotuner information. INFO:root:... Fusing adjacent ParDo, Read, Write, and Flatten operations ... INFO:root:...: Starting 1 workers... INFO:root:...: Executing operation group/Create INFO:root:...: Value "group/Session" materialized. INFO:root:...: Executing operation read+split+pair_with_one+group/Reify+group/Write INFO:root:Job 2016-03-08_14_21_32-8974754969325215880 is in state JOB_STATE_RUNNING. INFO:root:...: ...: Workers have started successfully. INFO:root:Job 2016-03-08_14_21_32-8974754969325215880 is in state JOB_STATE_RUNNING. INFO:root:...: Traceback (most recent call last): File ".../dataflow_worker/batchworker.py", line 384, in do_work self.current_executor.execute(work_item.map_task) ... File ".../apache_beam/examples/wordcount.runfiles/py/apache_beam/examples/wordcount.py", line 73, in <lambda> ValueError: invalid literal for int() with base 10: 'www'
Go
... 2022-05-26T18:32:52.752315397Zprocess bundle failed for instruction ... process_bundle-4031463614776698457-2 using plan s02-6 : while executing ... Process for Plan[s02-6] failed: Oh no! This is an error message!
考虑通过添加异常处理程序来防止代码中的错误。例如,如果您因为某些元素未能通过在 ParDo 中执行的一些自定义输入验证而要舍弃它们,请处理 DoFn 中的异常并删除这些元素。
您还可以通过几种不同的方式跟踪失败的元素:
- 您可以使用 Cloud Logging 记录失败的元素并检查输出。
- 您可以按照查看日志中的说明检查 Dataflow 工作器和工作器启动日志中的警告或错误。
- 您可以让
ParDo将失败的元素写入其他输出中,以供后续检查使用。
如需跟踪正在执行的流水线的属性,您可以使用 Metrics 类,如以下示例所示:
Java
final Counter counter = Metrics.counter("stats", "even-items"); PCollection<Integer> input = pipeline.apply(...); ... input.apply(ParDo.of(new DoFn<Integer, Integer>() { @ProcessElement public void processElement(ProcessContext c) { if (c.element() % 2 == 0) { counter.inc(); } });
Python
class FilterTextFn(beam.DoFn): """A DoFn that filters for a specific key based on a regex.""" def __init__(self, pattern): self.pattern = pattern # A custom metric can track values in your pipeline as it runs. Create # custom metrics to count unmatched words, and know the distribution of # word lengths in the input PCollection. self.word_len_dist = Metrics.distribution(self.__class__, 'word_len_dist') self.unmatched_words = Metrics.counter(self.__class__, 'unmatched_words') def process(self, element): word = element self.word_len_dist.update(len(word)) if re.match(self.pattern, word): yield element else: self.unmatched_words.inc() filtered_words = ( words | 'FilterText' >> beam.ParDo(FilterTextFn('s.*')))
Go
func addMetricDoFnToPipeline(s beam.Scope, input beam.PCollection) beam.PCollection { return beam.ParDo(s, &MyMetricsDoFn{}, input) } func executePipelineAndGetMetrics(ctx context.Context, p *beam.Pipeline) (metrics.QueryResults, error) { pr, err := beam.Run(ctx, runner, p) if err != nil { return metrics.QueryResults{}, err } // Request the metric called "counter1" in namespace called "namespace" ms := pr.Metrics().Query(func(r beam.MetricResult) bool { return r.Namespace() == "namespace" && r.Name() == "counter1" }) // Print the metric value - there should be only one line because there is // only one metric called "counter1" in the namespace called "namespace" for _, c := range ms.Counters() { fmt.Println(c.Namespace(), "-", c.Name(), ":", c.Committed) } return ms, nil } type MyMetricsDoFn struct { counter beam.Counter } func init() { beam.RegisterType(reflect.TypeOf((*MyMetricsDoFn)(nil))) } func (fn *MyMetricsDoFn) Setup() { // While metrics can be defined in package scope or dynamically // it's most efficient to include them in the DoFn. fn.counter = beam.NewCounter("namespace", "counter1") } func (fn *MyMetricsDoFn) ProcessElement(ctx context.Context, v beam.V, emit func(beam.V)) { // count the elements fn.counter.Inc(ctx, 1) emit(v) }
对流水线运行缓慢或缺少输出等进行问题排查
请参阅以下页面:
常见错误和操作流程
如果您知道导致流水线失败的错误,请参阅排查 Dataflow 错误页面,以了解错误排查指南。