您可以使用 Apache Beam SDK 的内置日志记录基础设施在运行流水线时记录信息。您可以使用 Google Cloud 控制台在流水线运行期间和之后监控日志记录信息。
将日志消息添加到流水线
Java
Java 版 Apache Beam SDK 建议您通过开源 Java 简易日志记录门面 (SLF4J) 库记录工作器消息。Java 版 Apache Beam SDK 会实现必需的日志记录基础架构,因此 Java 代码只需导入 SLF4J API。然后实例化日志记录器,即可在流水线代码中启用消息日志记录功能。
对于现有代码和/或库,Java 版 Apache Beam SDK 会设置额外的日志记录基础架构。系统会捕获以下 Java 版日志记录库生成的日志消息:
Python
Python 版 Apache Beam SDK 提供 logging 库软件包,可支持流水线工作器输出日志消息。要使用库函数,您必须导入相应的库:
import logging
Go
Go 版 Apache Beam SDK 提供 log 库软件包,可支持流水线工作器输出日志消息。要使用库函数,您必须导入相应的库:
import "github.com/apache/beam/sdks/v2/go/pkg/beam/log"
工作器日志消息代码示例
Java
以下示例使用 SLF4J 来进行 Dataflow 日志记录。如需详细了解如何配置 SLF4J 来进行 Dataflow 日志记录,请参阅 Java 提示文章。
您可对 Apache Beam WordCount 示例进行修改,令其在处理的文本行中发现“love”一词时输出一条日志消息。在以下示例中,添加的代码以粗体表示(包含了环境代码,用于提供上下文)。
package org.apache.beam.examples; // Import SLF4J packages. import org.slf4j.Logger; import org.slf4j.LoggerFactory; ... public class WordCount { ... static class ExtractWordsFn extends DoFn<String, String> { // Instantiate Logger. // Suggestion: As shown, specify the class name of the containing class // (WordCount). private static final Logger LOG = LoggerFactory.getLogger(WordCount.class); ... @ProcessElement public void processElement(ProcessContext c) { ... // Output each word encountered into the output PCollection. for (String word : words) { if (!word.isEmpty()) { c.output(word); } // Log INFO messages when the word "love" is found. if(word.toLowerCase().equals("love")) { LOG.info("Found " + word.toLowerCase()); } } } } ... // Remaining WordCount example code ...
Python
可以对 Apache Beam wordcount.py 示例进行修改,以在处理的文本行中发现“love”一词时输出日志消息。
# import Python logging module. import logging class ExtractWordsFn(beam.DoFn): def process(self, element): words = re.findall(r'[A-Za-z\']+', element) for word in words: yield word if word.lower() == 'love': # Log using the root logger at info or higher levels logging.info('Found : %s', word.lower()) # Remaining WordCount example code ...
Go
可以对 Apache Beam wordcount.go 示例进行修改,以在处理的文本行中发现“love”一词时输出日志消息。
func (f *extractFn) ProcessElement(ctx context.Context, line string, emit func(string)) { for _, word := range wordRE.FindAllString(line, -1) { // increment the counter for small words if length of words is // less than small_word_length if strings.ToLower(word) == "love" { log.Infof(ctx, "Found : %s", strings.ToLower(word)) } emit(word) } } // Remaining Wordcount example
Java
如果使用默认的 DirectRunnerDirectRunner 在本地运行修改后的 WordCount 流水线,将输出发送至本地文件 (--output=./local-wordcounts),则控制台输出将包含增加的日志消息:
INFO: Executing pipeline using the DirectRunner. ... Feb 11, 2015 1:13:22 PM org.apache.beam.examples.WordCount$ExtractWordsFn processElement INFO: Found love Feb 11, 2015 1:13:22 PM org.apache.beam.examples.WordCount$ExtractWordsFn processElement INFO: Found love Feb 11, 2015 1:13:22 PM org.apache.beam.examples.WordCount$ExtractWordsFn processElement INFO: Found love ... INFO: Pipeline execution complete.
默认情况下,只有标记为 INFO 及更高级别的日志行将发送至 Cloud Logging。如需更改此行为,请参阅设置流水线工作器日志级别。
Python
如果使用默认的 DirectRunnerDirectRunner 在本地运行修改后的 WordCount 流水线,将输出发送至本地文件 (--output=./local-wordcounts),则控制台输出将包含增加的日志消息:
INFO:root:Found : love INFO:root:Found : love INFO:root:Found : love
默认情况下,只有标记为 INFO 及更高级别的日志行将发送至 Cloud Logging。如需更改此行为,请参阅设置流水线工作器日志级别。
请勿使用 logging.config 函数覆盖日志记录配置,因为这可能会停用将流水线日志传输到 Dataflow 和 Cloud Logging 的预配置日志处理程序。
Go
如果使用默认的 DirectRunnerDirectRunner 在本地运行修改后的 WordCount 流水线,将输出发送至本地文件 (--output=./local-wordcounts),则控制台输出将包含增加的日志消息:
2022/05/26 11:36:44 Found : love 2022/05/26 11:36:44 Found : love 2022/05/26 11:36:44 Found : love
默认情况下,只有标记为 INFO 及更高级别的日志行将发送至 Cloud Logging。
控制日志量
您还可以通过更改流水线日志级别来减少生成的日志量。如果您不想继续注入部分或全部 Dataflow 日志,请添加 Logging 排除项以排除 Dataflow 日志。然后,将日志导出到其他目标位置,例如 BigQuery、Cloud Storage 或 Pub/Sub。如需了解详情,请参阅控制 Dataflow 日志注入。
日志记录限制
每个工作器每 30 秒最多只能发送 15000 条工作器日志消息。如果达到此限制,系统会添加一条工作器日志消息,表示日志记录受到限制:
Throttling logger worker. It used up its 30s quota for logs in only 12.345s
日志存储和保留
操作日志存储在 _Default 日志存储桶中。Logging API 服务名称为 dataflow.googleapis.com。如需详细了解 Cloud Logging 中使用的 Google Cloud 受监控的资源类型和服务,请参阅受监控的资源和服务。
如需详细了解 Logging 将保留日志条目多长时间,请参阅配额和限制:日志保留期限中的保留期限信息。
如需了解如何查看操作日志,请参阅监控和查看流水线日志。
监控和查看流水线日志
当您在 Dataflow 服务上运行流水线时,可以使用 Dataflow 监控界面查看流水线发出的日志。
Dataflow 工作器日志示例
修改后的 WordCount 流水线可以使用下列选项在云端运行:
Java
--project=WordCountExample --output=gs://<bucket-name>/counts --runner=DataflowRunner --tempLocation=gs://<bucket-name>/temp --stagingLocation=gs://<bucket-name>/binaries
Python
--project=WordCountExample --output=gs://<bucket-name>/counts --runner=DataflowRunner --staging_location=gs://<bucket-name>/binaries
Go
--project=WordCountExample --output=gs://<bucket-name>/counts --runner=DataflowRunner --staging_location=gs://<bucket-name>/binaries
查看日志
WordCount 云端流水线使用阻塞式执行方式,因此流水线执行期间会输出控制台消息。作业开始后,流水线将向Google Cloud 控制台输出一个指向控制台页面的链接,后跟流水线作业 ID:
INFO: To access the Dataflow monitoring console, please navigate to https://console.developers.google.com/dataflow/job/2017-04-13_13_58_10-6217777367720337669 Submitted job: 2017-04-13_13_58_10-6217777367720337669
控制台网址指向 Dataflow 监控界面,其中显示已提交作业的摘要页面。页面左侧显示一个动态执行图,右侧显示摘要信息。点击底部面板上的 keyboard_capslock,以展开日志面板。
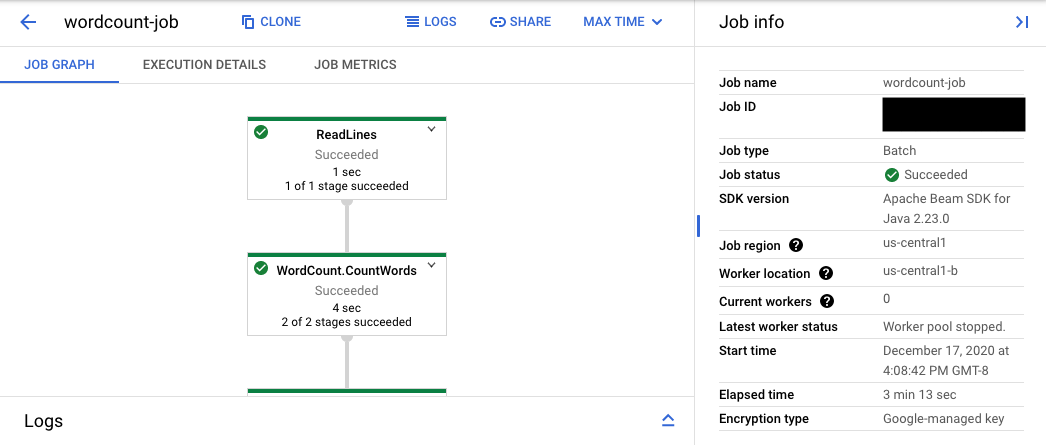
日志面板默认显示报告作业的整体状态的作业日志。您可以通过点击信息arrow_drop_down 和 filter_list过滤日志来过滤日志面板中显示的消息。
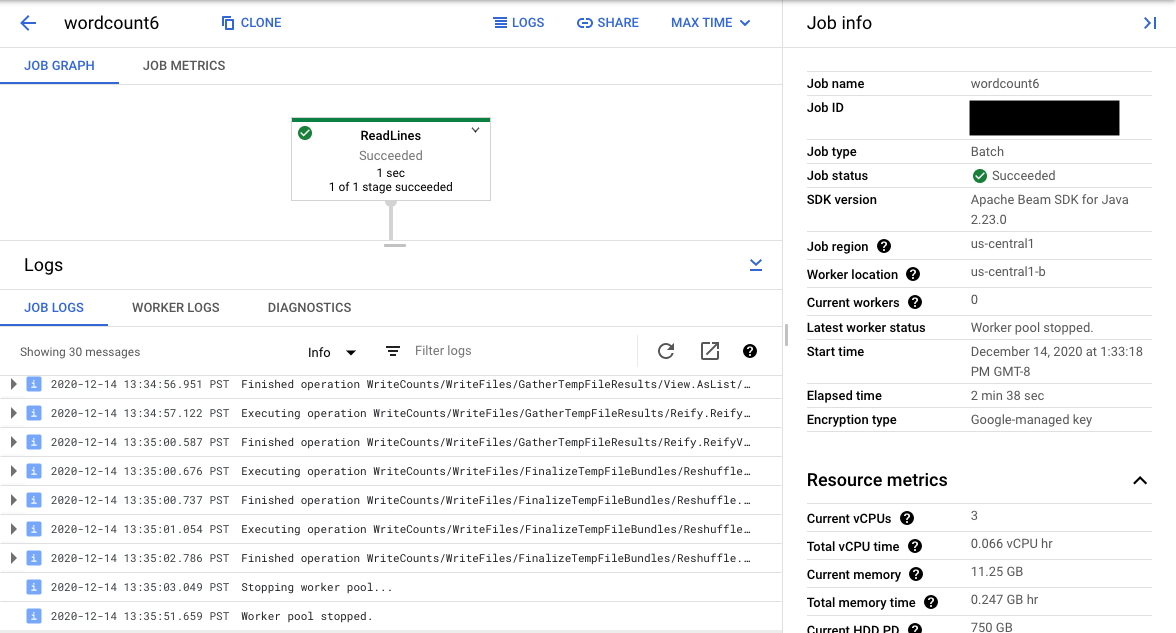
选择图表中的流水线步骤可将视图更改为由您的代码生成的步骤日志,以及在流水线步骤中运行的生成的代码。
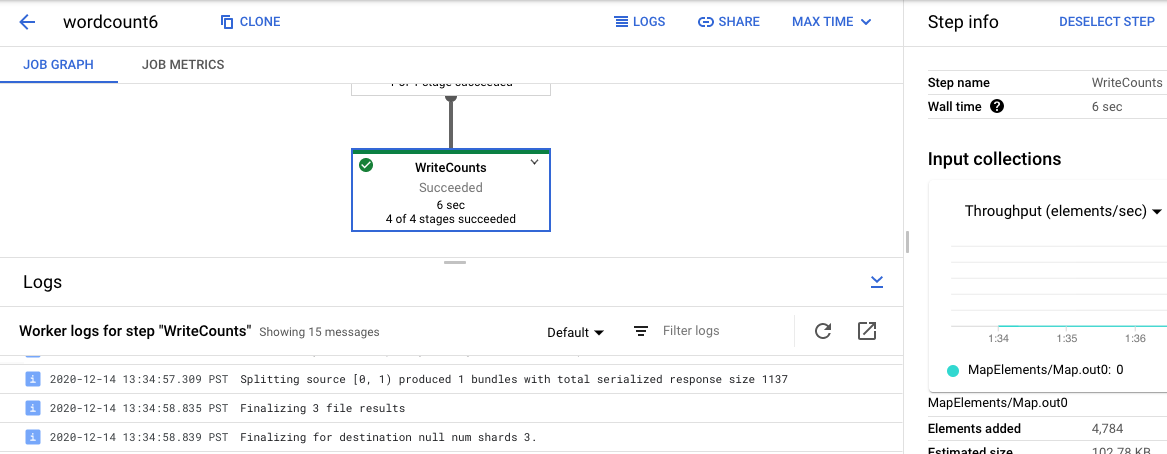
如需返回作业日志,请点击图表外部区域或使用右侧面板中的取消选择步骤按钮来清除步骤。
前往 Logs Explorer
如需打开 Logs Explorer 并选择不同的日志类型,请在日志面板中点击在 Logs Explorer 中查看(外部链接按钮)。
在 Logs Explorer 中,如需查看包含不同日志类型的面板,请点击日志字段切换开关。
在 Logs Explorer 页面上,查询可能会按作业步骤或按日志类型过滤日志。如需移除过滤条件,请点击显示查询切换开关,然后修改查询。
如需查看某个作业可用的所有日志,请按照以下步骤操作:
在查询字段中,输入以下查询:
resource.type="dataflow_step" resource.labels.job_id="JOB_ID"将 JOB_ID 替换为您的作业的 ID。
点击运行查询。
如果您使用此查询但未看到作业的日志,请点击修改时间。
调整开始时间和结束时间,然后点击应用。
日志类型
Logs Explorer 还包含流水线的基础设施日志。使用错误和警告日志来诊断所观察到的流水线问题。基础设施日志中与流水线问题无关的错误和警告不一定表示存在问题。
下面汇总了可从 Logs Explorer 页面查看的不同日志类型:
- job-message 日志包含 Dataflow 的各个组件生成的作业级消息。相关示例包括自动扩缩配置、工作器启动或关停的时间、作业步骤进度以及作业错误。源自崩溃用户代码以及 worker 日志中出现的工作器级错误也会记录到 job-message 日志中。
- worker 日志由 Dataflow 工作器生成。工作器负责完成大多数流水线工作(例如将
ParDo应用到数据)。Worker 日志包含由您的代码和 Dataflow 记录的消息。 - worker-startup 日志存在于大多数 Dataflow 作业中,可捕获与启动过程相关的消息。启动过程包括从 Cloud Storage 下载作业的 jar 文件,然后启动工作器。如果启动工作器时出现问题,则建议查看此日志。
- 自动化测试框架日志包含来自 Runner v2 运行程序自动化测试框架的消息。
- shuffler 日志中包含的消息来自负责整合并行流水线操作结果的工作器。
- system 日志中包含来自工作器虚拟机主机操作系统的消息。在某些情况下,它们可能会捕获进程崩溃或内存不足 (OOM) 事件。
- docker 和 kubelet 日志包含与在 Dataflow 工作器上使用的这些公开技术相关的消息。
- nvidia-mps 日志包含有关 NVIDIA 多进程服务 (MPS) 操作的消息。
设置流水线工作器日志级别
Java
Java 版 Apache Beam SDK 在工作器上设置的默认 SLF4J 日志记录级别为 INFO,因此级别为 INFO 或更高级别(INFO、WARN、ERROR)的所有日志消息都将发出。您可以设置其他默认日志级别,以支持较低的 SLF4J 日志记录级别(TRACE 或 DEBUG),也可以为代码中不同的软件包或类设置不同的日志级别。
提供了以下流水线选项,可让您通过命令行或以编程方式设置工作器日志级别:
--defaultSdkHarnessLogLevel=<level>:用于为所有日志记录器设置指定的默认级别。例如,以下命令行选项将替换默认的 DataflowINFO日志级别,并将其设置为DEBUG:
--defaultSdkHarnessLogLevel=DEBUG--sdkHarnessLogLevelOverrides={"<package or class>":"<level>"}:使用此选项可为指定的软件包或类设置日志记录级别。例如,如需替换org.apache.beam.runners.dataflow包的默认流水线日志级别,并将其设置为TRACE,请使用以下选项:
--sdkHarnessLogLevelOverrides='{"org.apache.beam.runners.dataflow":"TRACE"}'
如需进行多项替换,请提供 JSON 映射:
(--sdkHarnessLogLevelOverrides={"<package/class>":"<level>","<package/class>":"<level>",...})。- 如果流水线使用 Apache Beam SDK 2.50.0 及更低版本,但没有 Runner v2,则不支持
defaultSdkHarnessLogLevel和sdkHarnessLogLevelOverrides流水线选项。在这种情况下,请使用--defaultWorkerLogLevel=<level>和--workerLogLevelOverrides={"<package or class>":"<level>"}流水线选项。如需进行多项替换,请提供 JSON 映射:
(--workerLogLevelOverrides={"<package/class>":"<level>","<package/class>":"<level>",...})
以下示例以编程方式设置流水线日志记录选项,其默认值可通过命令行进行替换:
PipelineOptions options = ... SdkHarnessOptions loggingOptions = options.as(SdkHarnessOptions.class); // Overrides the default log level on the worker to emit logs at TRACE or higher. loggingOptions.setDefaultSdkHarnessLogLevel(LogLevel.TRACE); // Overrides the Foo class and "org.apache.beam.runners.dataflow" package to emit logs at WARN or higher. loggingOptions.getSdkHarnessLogLevelOverrides() .addOverrideForClass(Foo.class, LogLevel.WARN) .addOverrideForPackage(Package.getPackage("org.apache.beam.runners.dataflow"), LogLevel.WARN);
Python
Python 版 Apache Beam SDK 在工作器上设置的默认日志记录级别为 INFO。这意味着,INFO 级别或更高级别(即 INFO、WARNING、ERROR、CRITICAL)的所有日志消息都会发出。您可以设置其他默认日志级别,以支持较低的日志记录级别 (DEBUG),也可以为代码中不同的模块设置不同的日志级别。
系统提供了两个流水线选项,可让您通过命令行或以程序化方式设置工作器日志级别:
--default_sdk_harness_log_level=<level>:用于为所有日志记录器设置指定的默认级别。例如,以下命令行选项会替换默认的 Dataflow 日志级别(即INFO),并将其设置为DEBUG:
--default_sdk_harness_log_level=DEBUG--sdk_harness_log_level_overrides={\"<module>\":\"<level>\"}:使用此选项可为指定的模块设置日志记录级别。例如,如需替换apache_beam.runners.dataflow模块的默认流水线日志级别,并将其设置为DEBUG,请使用以下选项:
--sdk_harness_log_level_overrides={\"apache_beam.runners.dataflow\":\"DEBUG\"}
如需进行多项替换,请提供 JSON 映射:
(--sdk_harness_log_level_overrides={\"<module>\":\"<level>\",\"<module>\":\"<level>\",...})。
以下示例使用 WorkerOptions 类以编程方式设置可通过命令行替换的流水线日志记录选项:
from apache_beam.options.pipeline_options import PipelineOptions, WorkerOptions pipeline_args = [ '--project=PROJECT_NAME', '--job_name=JOB_NAME', '--staging_location=gs://STORAGE_BUCKET/staging/', '--temp_location=gs://STORAGE_BUCKET/tmp/', '--region=DATAFLOW_REGION', '--runner=DataflowRunner' ] pipeline_options = PipelineOptions(pipeline_args) worker_options = pipeline_options.view_as(WorkerOptions) worker_options.default_sdk_harness_log_level = 'WARNING' # Note: In Apache Beam SDK 2.42.0 and earlier versions, use ['{"apache_beam.runners.dataflow":"WARNING"}'] worker_options.sdk_harness_log_level_overrides = {"apache_beam.runners.dataflow":"WARNING"} # Pass in pipeline options during pipeline creation. with beam.Pipeline(options=pipeline_options) as pipeline:
请替换以下内容:
PROJECT_NAME:项目的名称JOB_NAME:作业的名称STORAGE_BUCKET:Cloud Storage 名称DATAFLOW_REGION:要在其中部署 Dataflow 作业的区域--region标志会替换元数据服务器、本地客户端或环境变量中设置的默认区域。
Go
Go 版 Apache Beam SDK 未提供此功能。
查看已发布 BigQuery 作业的日志
在 Dataflow 流水线中使用 BigQuery 时,系统会启动 BigQuery 作业,以代表您执行各种操作。这些操作可能包括加载数据、导出数据和其他类似任务。为了进行问题排查和监控,Dataflow 监控界面在日志面板中提供了有关这些 BigQuery 作业的详细信息。
日志面板中显示的 BigQuery 作业信息是从 BigQuery 系统表中存储和加载的,因此查询底层 BigQuery 表时会产生结算费用。
查看 BigQuery 作业详情
如需查看 BigQuery 作业信息,您的流水线必须使用 Apache Beam 2.24.0 或更高版本。
如需列出 BigQuery 作业,请打开 BigQuery 作业标签页并选择 BigQuery 作业的位置。接下来,点击加载 BigQuery 作业并确认对话框。查询完成后,系统会显示作业列表。
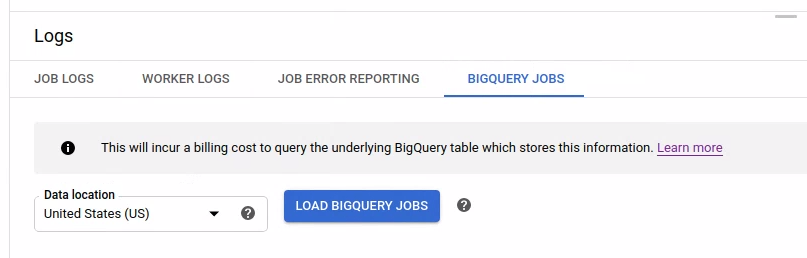
提供了有关每个作业的基本信息,包括作业 ID、类型、时长和其他详细信息。
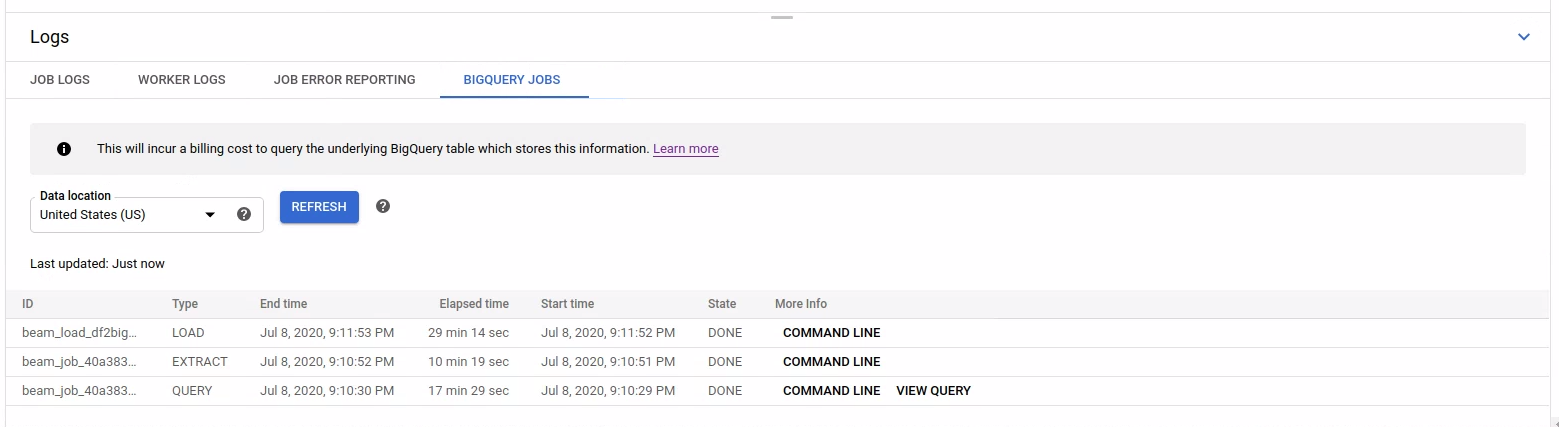
如需详细了解特定作业,请点击更多信息列中的命令行。
在命令行的模态窗口中,复制 bq jobs describe 命令,然后在本地或 Cloud Shell 中运行它。
gcloud alpha bq jobs describe BIGQUERY_JOB_ID
bq jobs describe 命令会输出 JobStatistics,可在诊断慢速或卡住的 BigQuery 作业时提供更多有用详情。
或者,当您将 BigQueryIO 与 SQL 查询结合使用时,系统会发起查询作业。如需查看作业使用的 SQL 查询,请点击更多信息列中的查看查询。
查看诊断结果
日志窗格的诊断标签页会收集并显示流水线中生成的某些日志条目。这些条目包括指示流水线可能存在问题的消息以及包含堆栈轨迹的错误消息。系统会对收集的日志条目进行重复信息删除,然后合并到错误组中。
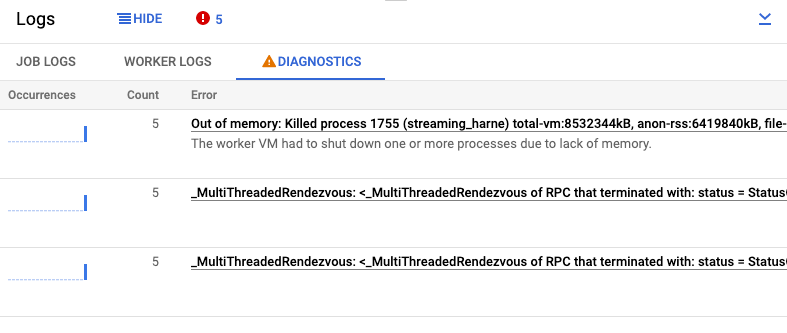
错误报告包含以下信息:
- 带有错误消息的错误列表
- 每个错误发生的次数
- 直方图,指示每个错误发生的时间
- 最近发生该错误的时间
- 错误首次发生的时间
- 错误的状态
如需查看特定错误的错误报告,请点击错误列下的说明。随即将显示错误报告页面。如果错误是服务错误,系统会显示问题排查指南链接。

如需详细了解该页面,请参阅查看和过滤错误。
忽略错误
如需忽略错误消息,请按照以下步骤操作:
- 打开诊断标签页。
- 点击要忽略的错误。
- 打开解决状态菜单。状态具有以下标签:未结、已确认、已解决或已忽略。
- 选择已忽略。