如果 Dataflow 管道或工作發生問題,這份頁面會列出您可能會看到的錯誤訊息,並提供修正各項錯誤的建議。
記錄類型 dataflow.googleapis.com/worker-startup、dataflow.googleapis.com/harness-startup 和 dataflow.googleapis.com/kubelet 中的錯誤表示工作設定有問題。這些訊息也可以指出導致正常記錄路徑無法運作的狀況。
您的管道在處理資料時可能會擲回例外狀況。這些錯誤中有些是暫時性,例如暫時無法存取外部服務。這些錯誤中有些是永久性,例如已損毀或無法剖析的輸入資料導致錯誤,或在運算期間出現 null 指標。
Dataflow 會以任意組合來處理元素,只要組合中有任何元素擲回錯誤,就會重新嘗試處理整個組合。以批次模式執行時,內含失敗項目的組合可重試四次。如果單一組合失敗達四次,管道程序就會完全失敗。以串流模式執行時,內含失敗項目的組合會無限期重試,而這可能會導致管道永久停滯。
Dataflow 監控介面會回報使用者程式碼中的例外狀況,例如 DoFn 執行個體。如果您使用 BlockingDataflowPipelineRunner 執行管道,主控台或終端機視窗中也會顯示錯誤訊息。
建議您新增例外狀況處理常式以防範程式碼中的錯誤。舉例來說,如果您因為某些元素未能通過在 ParDo 中執行的自訂輸入驗證作業而想加以捨棄,請在 ParDo 中使用 try/catch 區塊來處理例外狀況,並記錄及捨棄元素。如要處理正式環境工作負載,請實作未處理的訊息模式。如要追蹤錯誤次數,請使用匯總轉換。
缺少記錄檔
如果沒有顯示任何作業的記錄,請從所有 Cloud Logging 記錄檔路由器接收器中,移除含有 resource.type="dataflow_step" 的排除篩選器。
如要進一步瞭解如何移除記錄排除條件,請參閱「移除排除條件」指南。
輸出內容重複
執行 Dataflow 工作時,輸出內容包含重複記錄。
如果 Dataflow 工作使用「至少一次」管道串流模式,就可能發生這個問題。這個模式可確保記錄至少處理一次。不過,這個模式可能會產生重複記錄。
如果工作流程無法容許重複記錄,請使用一次性串流模式。這個模式可確保資料在管道中移動時,不會遺失或重複記錄。
如要確認工作使用的串流模式,請參閱「查看工作使用的串流模式」。
如要進一步瞭解串流模式,請參閱「設定管道串流模式」。
管道錯誤
以下各節列出您可能會遇到的常見管道錯誤,以及解決或排解錯誤的步驟。
必須啟用部分 Cloud API
嘗試執行 Dataflow 工作時發生下列錯誤:
Some Cloud APIs need to be enabled for your project in order for Cloud Dataflow to run this job.
發生這個問題的原因是專案中未啟用部分必要 API。
如要解決這個問題並執行 Dataflow 工作,請在專案中啟用下列Google Cloud API:
- Compute Engine API (Compute Engine)
- Cloud Logging API
- Cloud Storage
- Cloud Storage JSON API
- BigQuery API
- Pub/Sub
- Datastore API
如需詳細操作說明,請參閱啟用 API 的「開始使用」一節。 Google Cloud
「@*」和「@N」是預留的分片規格
嘗試執行工作時,記錄檔中會顯示下列錯誤,且工作失敗:
Workflow failed. Causes: "@*" and "@N" are reserved sharding specs. Filepattern must not contain any of them.
如果臨時檔案的 Cloud Storage 路徑 (tempLocation 或 temp_location) 檔案名稱含有 @ 符號,且後面接著數字或星號 (*),就會發生這個錯誤。
如要解決這個問題,請變更檔案名稱,確保 @ 符號後方是支援的字元。
錯誤的要求
執行 Dataflow 工作時,Cloud Monitoring 記錄檔會顯示與下列類似的一系列警告:
Unable to update setup work item STEP_ID error: generic::invalid_argument: Http(400) Bad Request
Update range task returned 'invalid argument'. Assuming lost lease for work with id LEASE_ID
with expiration time: TIMESTAMP, now: TIMESTAMP. Full status: generic::invalid_argument: Http(400) Bad Request
如果工作站狀態資訊因處理延遲而過時或未同步,就會出現錯誤要求警告。儘管出現錯誤要求警告,您的 Dataflow 任務通常仍可順利進行。如果這與您的狀況相符,請忽略警告。
無法在不同位置讀取和寫入
執行 Dataflow 工作時,您可能會在記錄檔中看到下列錯誤:
message:Cannot read and write in different locations: source: SOURCE_REGION, destination: DESTINATION_REGION,reason:invalid
如果來源和目的地位於不同區域,就會發生這個錯誤。如果暫存位置和目的地位於不同區域,也可能發生這種情況。舉例來說,如果工作從 Pub/Sub 讀取資料,然後先寫入 Cloud Storage temp 值區,再寫入 BigQuery 資料表,則 Cloud Storage temp 值區和 BigQuery 資料表必須位於相同區域。
即使單一區域位於多區域位置的範圍內,系統仍會將多區域位置視為與單一區域位置不同。舉例來說,us (multiple regions in the United States) 和 us-central1 是不同區域。
如要解決這個問題,請將目的地、來源和暫存位置設在相同區域。Cloud Storage bucket 位置無法變更,因此您可能需要在正確的區域建立新的 Cloud Storage bucket。
連線逾時
執行 Dataflow 工作時,您可能會在記錄檔中看到下列錯誤:
org.springframework.web.client.ResourceAccessException: I/O error on GET request for CONNECTION_PATH: Connection timed out (Connection timed out); nested exception is java.net.ConnectException: Connection timed out (Connection timed out)
如果 Dataflow 工作站無法建立或維持與資料來源或目的地的連線,就會發生這個問題。
如要解決這個問題,請按照下列疑難排解步驟操作:
找不到這個物件
執行 Dataflow 工作時,您可能會在記錄檔中看到下列錯誤:
..., 'server': 'UploadServer', 'status': '404'}>, <content <No such object:...
如果部分正在執行的 Dataflow 工作使用相同的 temp_location,暫存管道執行時建立的工作檔案,通常就會發生這類錯誤。如果多個並行工作共用相同的 temp_location,這些工作可能會互相干擾臨時資料,並發生競爭狀況。為避免這個問題,建議您為每個職缺使用專屬的 temp_location。
Dataflow 無法判斷待處理工作
從 Pub/Sub 執行串流管道時,會出現下列警告:
Dataflow is unable to determine the backlog for Pub/Sub subscription
當 Dataflow 管道從 Pub/Sub 提取資料時,Dataflow 需要重複向 Pub/Sub 要求資訊。這項資訊包括訂閱項目的待處理項目數量,以及最舊未確認訊息的存在時間。有時,Dataflow 會因內部系統問題而無法從 Pub/Sub 擷取這項資訊,這可能會導致暫時積壓待處理項目。
詳情請參閱「使用 Cloud Pub/Sub 串流」。
DEADLINE_EXCEEDED 或伺服器無回應
執行工作時,您可能會遇到 RPC 逾時例外狀況或下列其中一個錯誤:
DEADLINE_EXCEEDED
或:
Server Unresponsive
這類錯誤通常是因為下列其中一個原因而發生:
用於工作的虛擬私有雲 (VPC) 網路可能缺少防火牆規則。防火牆規則需要啟用管道選項中指定之 VPC 網路上,VM 間的所有 TCP 流量。詳情請參閱 Dataflow 的防火牆規則。
在某些情況下,工作者無法彼此通訊。 執行未使用 Dataflow Shuffle 或 Streaming Engine 的 Dataflow 工作時,工作站必須使用虛擬私有雲網路中的 TCP 通訊埠
12345和12346彼此通訊。在此情況下,錯誤訊息會包含遭封鎖的 Worker Harness 名稱和 TCP 連接埠。錯誤訊息如下列範例所示:DEADLINE_EXCEEDED: (g)RPC timed out when SOURCE_WORKER_HARNESS talking to DESTINATION_WORKER_HARNESS:12346.Rpc to WORKER_HARNESS:12345 completed with error UNAVAILABLE: failed to connect to all addresses Server unresponsive (ping error: Deadline Exceeded, UNKNOWN: Deadline Exceeded...)如要解決這個問題,請使用
gcloud compute firewall-rules createrules 旗標,允許網路流量流向通訊埠12345和12346。以下範例說明 Google Cloud CLI 指令:gcloud compute firewall-rules create FIREWALL_RULE_NAME \ --network NETWORK \ --action allow \ --direction IN \ --target-tags dataflow \ --source-tags dataflow \ --priority 0 \ --rules tcp:12345-12346更改下列內容:
FIREWALL_RULE_NAME:防火牆規則名稱NETWORK:網路名稱
您的工作屬於隨機處理形式。
如要解決這個問題,請進行下列一或多項變更。
Java
- 如果作業未使用服務型 Shuffle,請設定
--experiments=shuffle_mode=service,改用服務型 Dataflow Shuffle。如需詳細資料和適用情形,請參閱「Dataflow Shuffle」。 - 新增更多工作站。執行管道時,請嘗試將
--numWorkers設為更高的值。 - 增加工作站已連接磁碟的大小。執行管道時,請嘗試將
--diskSizeGb設為更高的值。 - 使用採用 SSD 的永久磁碟。執行管道時,請嘗試設定
--workerDiskType="compute.googleapis.com/projects/PROJECT_ID/zones/ZONE/diskTypes/pd-ssd"。
Python
- 如果作業未使用服務型 Shuffle,請設定
--experiments=shuffle_mode=service,改用服務型 Dataflow Shuffle。如需詳細資料和適用情形,請參閱「Dataflow Shuffle」。 - 新增更多工作站。執行管道時,請嘗試將
--num_workers設為更高的值。 - 增加工作站已連接磁碟的大小。執行管道時,請嘗試將
--disk_size_gb設為更高的值。 - 使用採用 SSD 的永久磁碟。執行管道時,請嘗試設定
--worker_disk_type="compute.googleapis.com/projects/PROJECT_ID/zones/ZONE/diskTypes/pd-ssd"。
Go
- 如果作業未使用服務型 Shuffle,請設定
--experiments=shuffle_mode=service,改用服務型 Dataflow Shuffle。如需詳細資料和適用情形,請參閱「Dataflow Shuffle」。 - 新增更多工作站。執行管道時,請嘗試將
--num_workers設為更高的值。 - 增加工作站已連接磁碟的大小。執行管道時,請嘗試將
--disk_size_gb設為更高的值。 - 使用採用 SSD 的永久磁碟。執行管道時,請嘗試設定
--disk_type="compute.googleapis.com/projects/PROJECT_ID/zones/ZONE/diskTypes/pd-ssd"。
- 如果作業未使用服務型 Shuffle,請設定
使用者程式碼中出現編碼錯誤、IOException 或非預期的行為
Apache Beam SDK 和 Dataflow 工作站需要使用某些共同的第三方元件。這些元件會匯入其他依附元件。版本衝突可能會導致服務產生非預期的行為,此外,部分程式庫不具備向前相容性。這表示您在執行程式時,可能需要根據執行的範圍,固定使用清單中的版本。SDK 與工作站依附元件一文包含依附元件及該元件必要版本的清單。
執行 LookupEffectiveGuestPolicies 時發生錯誤
執行 Dataflow 工作時,您可能會在記錄檔中看到下列錯誤:
OSConfigAgent Error policies.go:49: Error running LookupEffectiveGuestPolicies:
error calling LookupEffectiveGuestPolicies: code: "Unauthenticated",
message: "Request is missing required authentication credential.
Expected OAuth 2 access token, login cookie or other valid authentication credential.
如果整個專案都已啟用OS 設定管理,就會發生這個錯誤。
如要解決這個問題,請停用適用於整個專案的 VM 管理員政策。如果無法為整個專案停用 VM 管理員政策,可以放心忽略這項錯誤,並從記錄監控工具中篩除。
Java Runtime Environment 偵測到嚴重錯誤
啟動工作者時發生下列錯誤:
A fatal error has been detected by the Java Runtime Environment
如果管道使用 Java Native Interface (JNI) 執行非 Java 程式碼,且該程式碼或 JNI 繫結包含錯誤,就會發生這個錯誤。
googclient_deliveryattempt 屬性鍵錯誤
Dataflow 工作失敗,並顯示下列其中一個錯誤:
The request contains an attribute key that is not valid (key=googclient_deliveryattempt). Attribute keys must be non-empty and must not begin with 'goog' (case-insensitive).
或:
Invalid extensions name: googclient_deliveryattempt
如果 Dataflow 工作具有下列特徵,就會發生這項錯誤:
- Dataflow 工作使用 Streaming Engine。
- 管道具有 Pub/Sub 接收器。
- 管道會使用提取訂閱。
- 管道會使用其中一個 Pub/Sub 服務 API 發布訊息,而不是使用內建的 Pub/Sub I/O 接收器。
- Pub/Sub 使用 Java 或 C# 用戶端程式庫。
- Pub/Sub 訂閱項目有無效信件主題。
發生這項錯誤的原因是,當您使用 Pub/Sub Java 或 C# 用戶端程式庫,且已為訂閱項目啟用無法傳送的郵件主題時,系統會將傳送嘗試次數放在 googclient_deliveryattempt 訊息屬性中,而不是 delivery_attempt 欄位。詳情請參閱「處理訊息傳送失敗」頁面中的「追蹤傳送嘗試」。
如要解決這個問題,請進行下列一或多項變更。
- 停用 Streaming Engine。
- 請使用內建的 Apache Beam
PubSubIO連接器,而非 Pub/Sub 服務 API。 - 使用其他類型的 Pub/Sub 訂閱項目。
- 移除無法傳送訊息的主題。
- 請勿搭配 Pub/Sub 提取訂閱項目使用 Java 或 C# 用戶端程式庫。如需其他選項,請參閱用戶端程式庫程式碼範例。
- 在管道程式碼中,如果屬性鍵開頭為
goog,請先清除訊息屬性,再發布訊息。
偵測到熱鍵「...」
發生下列錯誤:
A hot key HOT_KEY_NAME was detected in...
如果資料含有熱鍵,就會發生這些錯誤。熱鍵是具備足夠元素,可對管道效能造成負面影響的索引鍵。這些索引鍵限制了 Dataflow 平行處理元素的能力,進而導致執行時間延長。
如要在管道中偵測到快速鍵時,將使用者可理解的鍵盤按鍵列印到記錄檔,請使用快速鍵管道選項。
如要解決這個問題,請檢查資料是否均勻分布。如果某個索引鍵的值過多而不成比例,請考慮採取下列做法:
- 重新輸入資料。套用
ParDo轉換以輸出新的鍵/值組合。 - Java 工作請使用
Combine.PerKey.withHotKeyFanout轉換。 - 如果是 Python 工作,請使用
CombinePerKey.with_hot_key_fanout轉換。 - 啟用 Dataflow Shuffle。
如要在 Dataflow 監控介面中查看快速鍵,請參閱「排解批次工作中的落後者」。
資料目錄中的資料表規格無效
使用 Dataflow SQL 建立 Dataflow SQL 工作時,工作可能會失敗,且記錄檔中會出現下列錯誤:
Invalid table specification in Data Catalog: Could not resolve table in Data Catalog
如果 Dataflow 服務帳戶無法存取 Data Catalog API,就會發生這個錯誤。
如要解決這個問題,請在用於編寫及執行查詢的 Google Cloud 專案中啟用 Data Catalog API。
或者,將 roles/datacatalog.viewer 角色指派給 Dataflow 服務帳戶。
作業圖表過大
工作可能會失敗,並顯示下列錯誤:
The job graph is too large. Please try again with a smaller job graph,
or split your job into two or more smaller jobs.
如果工作圖形大小超過 10 MB,就會發生這個錯誤。管道中的某些狀況可能會導致工作圖表超過上限。常見狀況包括:
Create轉換包含了大量記憶體內資料。- 大型
DoFn執行個體已針對遠端工作站傳輸作業進行序列化。 - 做為匿名內部類別執行個體的
DoFn,(可能無意間) 提取了大量資料進行序列化。 - 有向非循環圖 (DAG) 用於程式設計迴圈,而該迴圈正在列舉大量清單。
如要避免這些狀況,請考慮重組管道。
金鑰提交過大
執行串流工作時,工作站記錄檔會顯示下列錯誤:
KeyCommitTooLargeException
如果未採用 Combine 轉換就將大量資料分組,或是從單一輸入元素產生大量資料,就會在串流情境中發生這個錯誤。
如要減少發生這類錯誤的機率,請使用下列策略:
- 請確保處理單一元素不會導致輸出或狀態修改超出限制。
- 如果多個元素是依據某個鍵分組,請考慮增加鍵空間,減少每個鍵分組的元素。
- 如果系統在短時間內以高頻率發出某個鍵的元素,可能會導致該鍵在時間範圍內產生數 GB 的事件。重新編寫管道,偵測這類鍵,並只發出輸出內容,指出該鍵經常出現在該視窗中。
- 針對可交換和關聯的運算,使用次線性空間
Combine轉換。如果合併器無法縮減空間,請勿使用。舉例來說,如果字串的組合器只是將字串附加在一起,效果會比不使用組合器更差。
拒絕超過 7168K 的郵件
執行透過範本建立的 Dataflow 工作時,工作可能會失敗並顯示下列錯誤:
Error: CommitWork failed: status: APPLICATION_ERROR(3): Pubsub publish requests are limited to 10MB, rejecting message over 7168K (size MESSAGE_SIZE) to avoid exceeding limit with byte64 request encoding.
如果寫入無效信件佇列的訊息超過 7168 KB 的大小限制,就會發生這個錯誤。如要解決這個問題,請啟用串流引擎,這個引擎的檔案大小上限較高。如要啟用 Streaming Engine,請使用下列管道選項。
Java
--enableStreamingEngine=true
Python
--enable_streaming_engine=true
要求實體過大
提交工作時,主控台或終端機視窗會顯示下列其中一個錯誤:
413 Request Entity Too Large
The size of serialized JSON representation of the pipeline exceeds the allowable limit
Failed to create a workflow job: Invalid JSON payload received
Failed to create a workflow job: Request payload exceeds the allowable limit
如果在提交工作時遇到有關 JSON 酬載的錯誤,表示管道的 JSON 表示法超過 20 MB 要求大小的上限。
工作大小與管道的 JSON 表示法相關。管道越大代表要求越大。Dataflow 的要求大小上限為 20 MB。
如要估算管道的 JSON 要求大小,請使用下列選項執行管道:
Java
--dataflowJobFile=PATH_TO_OUTPUT_FILE
Python
--dataflow_job_file=PATH_TO_OUTPUT_FILE
Go
Go 不支援以 JSON 格式輸出工作。
這個指令會將您工作的 JSON 表示法寫入檔案。序列化檔案大小是要求大小的良好估計值,不過這些要求實際上會比預估的更大一點,因為其中隨附一些額外的資訊。
管道中的某些狀況可能會導致 JSON 表示法超過上限。常見狀況包括:
Create轉換包含了大量記憶體內資料。- 大型
DoFn執行個體已針對遠端工作站傳輸作業進行序列化。 - 做為匿名內部類別執行個體的
DoFn,(可能無意間) 提取了大量資料進行序列化。
如要避免這些狀況,請考慮重組管道。
SDK 管道選項或暫存檔案清單超過大小上限
執行管道時,發生下列其中一個錯誤:
SDK pipeline options or staging file list exceeds size limit.
Please keep their length under 256K Bytes each and 512K Bytes in total.
或:
Value for field 'resource.properties.metadata' is too large: maximum size
如果管道因超過 Compute Engine 中繼資料限制而無法啟動,就會發生這些錯誤。這些限制無法變更。 Dataflow 會使用 Compute Engine 中繼資料做為管道選項。Compute Engine 自訂中繼資料限制中說明瞭這項限制。
下列情況可能會導致 JSON 表示法超過上限:
- 要暫存的 JAR 檔案過多。
sdkPipelineOptions要求欄位過大。
如要估算管道的 JSON 要求大小,請使用下列選項執行管道:
Java
--dataflowJobFile=PATH_TO_OUTPUT_FILE
Python
--dataflow_job_file=PATH_TO_OUTPUT_FILE
Go
Go 不支援以 JSON 格式輸出工作。
這項指令的輸出檔案大小不得超過 256 KB。 錯誤訊息中的 512 KB 是指輸出檔案和 Compute Engine VM 執行個體的自訂中繼資料選項總大小。
您可以透過在專案中執行 Dataflow 工作,大致估算 VM 執行個體的自訂中繼資料選項。選擇任何正在執行的 Dataflow 工作。選取 VM 執行個體,然後前往該 VM 的 Compute Engine VM 執行個體詳細資料頁面,檢查是否有自訂中繼資料區段。自訂中繼資料和檔案的總長度應小於 512 KB。由於系統不會為失敗的工作啟動 VM,因此無法準確估算失敗工作的費用。
如果 JAR 清單達到 256 KB 的限制,請檢查並減少任何不必要的 JAR 檔案。如果檔案仍過大,請嘗試使用 uber JAR 執行 Dataflow 工作。如需示範如何建立及使用 uber JAR 的範例,請參閱「建構及部署 Uber JAR」。
如果 sdkPipelineOptions 要求欄位過大,請在執行管道時加入下列選項。Java、Python 和 Go 的管道選項相同。
--experiments=no_display_data_on_gce_metadata
重組鍵過大
工作站記錄檔會顯示下列錯誤:
Shuffle key too large
如果套用對應的 Coder 後,傳送至特定 (Co-)GroupByKey 的序列化鍵過大,就會發生這個錯誤。Dataflow 有序列化洗牌鍵的限制。
如要解決這個問題,請縮減金鑰大小,或使用更節省空間的編碼器。
詳情請參閱 Dataflow 的生產限制。
BoundedSource 物件總數大於允許的上限
以 Java 執行工作時,可能會發生下列其中一項錯誤:
Total number of BoundedSource objects generated by splitIntoBundles() operation is larger than the allowable limit
或:
Total size of the BoundedSource objects generated by splitIntoBundles() operation is larger than the allowable limit
Java
如果您透過 EXPORT 使用 TextIO、AvroIO、BigQueryIO,或某些其他以檔案為基礎的來源,從非常大量的檔案進行讀取,則可能會發生這個錯誤。實際的限制取決於來源的詳細資料,但限制大概是以一個管道中有數萬個檔案而論。舉例來說,在 AvroIO.Read 中嵌入結構化資料可減少檔案數量。
如果您為管道建立了自訂資料來源,而來源的 splitIntoBundles 方法傳回的 BoundedSource 物件清單在序列化後占用超過 20 MB,則可能也會發生這個錯誤。
自訂來源 splitIntoBundles() 作業產生的 BoundedSource 物件,其允許的總大小上限為 20 MB。
如要避開這項限制,請進行下列任一變更:
NameError
使用 Dataflow 服務執行管道時,會發生下列錯誤:
NameError
如果您在本機執行 (例如使用 DirectRunner 執行),就不會發生這個錯誤。
如果 DoFn 使用全域命名空間中的值,但這些值不適用於 Dataflow 工作站,就會發生這個錯誤。
根據預設,在 Dataflow 工作序列化期間,系統不會儲存主要工作階段中定義的全域匯入項目、函式和變數。
如要解決這個問題,請採取下列任一做法。如果您的 DoFn 是在主檔案中定義,並且參照了全域命名空間中的匯入和函數,請將 --save_main_session 管道選項設為 True。這項變更會透過 Pickle 模組將全域命名空間的狀態序列化,並載入 Dataflow 工作站。
如果全域命名空間中存在無法透過 Pickle 模組處理的物件,則會出現 Pickle 模組處理錯誤。如果此錯誤與 Python 發行版本中本應提供的模組有關,請將模組匯入至要使用該模組的本機位置。
例如,您不應使用下列指令:
import re … def myfunc(): # use re module
而應改為使用下列指令:
def myfunc(): import re # use re module
或者,如果您的 DoFn 跨越多個檔案,建議您使用其他方法來封裝工作流程及管理依附元件。
物件適用於值區的保留政策
如果 Dataflow 工作會寫入 Cloud Storage bucket,工作就會失敗,並顯示下列錯誤:
Object 'OBJECT_NAME' is subject to bucket's retention policy or object retention and cannot be deleted or overwritten
您也可能會看到下列錯誤訊息:
Unable to rename "gs://BUCKET"
如果 Dataflow 工作寫入的 Cloud Storage bucket 已啟用物件保留功能,就會發生第一個錯誤。詳情請參閱「啟用及使用物件保留設定」。
如要解決這個問題,請採取下列任一做法:
寫入沒有
temp資料夾保留政策的 Cloud Storage bucket。從工作寫入資料的值區中移除保留政策。詳情請參閱「設定物件的保留設定」。
第二個錯誤可能表示 Cloud Storage 值區已啟用物件保留功能,也可能表示 Dataflow 工作人員服務帳戶沒有寫入 Cloud Storage 值區的權限。
如果看到第二個錯誤,且 Cloud Storage 值區已啟用物件保留功能,請嘗試先前所述的解決方法。如果 Cloud Storage 值區未啟用物件保留功能,請確認 Dataflow 工作站服務帳戶是否具備 Cloud Storage 值區的寫入權限。詳情請參閱「存取 Cloud Storage 值區」。
處理作業停滯或作業進行中
如果 Dataflow 執行 DoFn 所用的時間超出 TIME_INTERVAL 中指定的時間,且沒有傳回回應,系統便會顯示以下訊息。
Java
視版本而定,可能是下列任一記錄訊息:
Processing stuck in step STEP_NAME for at least TIME_INTERVAL
Operation ongoing in bundle BUNDLE_ID for at least TIME_INTERVAL without outputting or completing: at STACK_TRACE
Python
Operation ongoing for over TIME_INTERVAL in state STATE in step STEP_ID without returning. Current Traceback: TRACEBACK
Go
Operation ongoing in transform TRANSFORM_ID for at least TIME_INTERVAL without outputting or completing in state STATE
這個行為有兩個可能的原因:
DoFn程式碼很慢,或是在等待某些緩慢的外部作業完成。- 您的
DoFn程式碼可能是停滯、有死結或速度異常緩慢,而未完成處理。
如要判斷是哪種情況,請展開 Cloud Monitoring 記錄檔項目,查看堆疊追蹤。找出指出 DoFn 程式碼停滯或遇到其他問題的訊息。如果沒有任何訊息,問題可能是 DoFn 程式碼的執行速度。建議使用 Cloud Profiler 或其他工具,調查程式碼的效能。
如果管道的建構基礎是 Java VM (使用 Java 或 Scala),您可以調查程式碼停滯的原因。請按照以下步驟操作來執行整個 JVM 的完整執行緒傾印 (而不是僅執行停滯執行緒的傾印):
- 記下記錄檔項目中的工作站名稱。
- 在 Google Cloud 控制台的 Compute Engine 區段,尋找含有所記工作站名稱的 Compute Engine 執行個體。
- 使用 SSH 連線至具備該名稱的執行個體。
執行下列指令:
curl http://localhost:8081/threadz
套裝組合中的作業正在進行
當您執行從 JdbcIO 讀取的管道時,從 JdbcIO 讀取分區的速度緩慢,且工作站記錄檔中會顯示下列訊息:
Operation ongoing in bundle process_bundle-[0-9-]* for PTransform{id=Read from JDBC with Partitions\/JdbcIO.Read\/JdbcIO.ReadAll\/ParDo\(Read\)\/ParMultiDo\(Read\).*, state=process} for at least (0[1-9]h[0-5][0-9]m[0-5][0-9]s) without outputting or completing:
如要解決這個問題,請對管道進行下列一或多項變更:
使用分區來提高工作平行處理程度。讀取更多較小的分割區,以利擴充。
檢查分區資料欄是否為來源中的索引資料欄或實際分區資料欄。在來源資料庫中,針對這個資料欄啟用索引和分區功能,以獲得最佳效能。
使用
lowerBound和upperBound參數略過尋找界線。
Pub/Sub 配額錯誤
從 Pub/Sub 執行串流管道時,會發生下列錯誤:
429 (rateLimitExceeded)
或:
Request was throttled due to user QPS limit being reached
如果專案的 Pub/Sub 配額不足,就會發生這些錯誤。
如要確認專案的配額是否不足,請按照下列步驟檢查用戶端錯誤:
- 前往Google Cloud 控制台。
- 在左側的選單中,選取 [APIs & services] (API 和服務)。
- 在搜尋方塊中,搜尋「Cloud Pub/Sub」。
- 按一下 [Usage] (用量) 分頁標籤。
- 檢查「Response Codes」(回應碼) 區段並尋找
(4xx)用戶端錯誤代碼。
依據機構政策的規定,您無法提出要求
執行管道時發生下列錯誤:
Error trying to get gs://BUCKET_NAME/FOLDER/FILE:
{"code":403,"errors":[{"domain":"global","message":"Request is prohibited by organization's policy","reason":"forbidden"}],
"message":"Request is prohibited by organization's policy"}
如果 Cloud Storage 值區位於服務範圍外,就會發生這項錯誤。
如要解決這個問題,請建立輸出規則,允許存取服務範圍外的值區。
暫存套件…無法存取
過去成功的工作可能會失敗,並出現下列錯誤:
Staged package...is inaccessible
如何解決這個問題:
- 確認用於暫存的 Cloud Storage 值區沒有會導致暫存套件遭到刪除的存留時間設定。
確認 Dataflow 專案的工作人員服務帳戶有權存取用於暫存的 Cloud Storage 值區。權限缺漏的原因可能包括:
- 用於暫存的 Cloud Storage 值區位於其他專案中。
- 用於暫存的 Cloud Storage bucket 已從精細存取權遷移至統一值區層級存取權。由於 IAM 和 ACL 政策不一致,將暫存值區遷移至統一值區層級存取權時,系統會禁止 Cloud Storage 資源使用 ACL。存取控制清單包含 Dataflow 專案的工作站服務帳戶在暫存值區中擁有的權限。
詳情請參閱「存取各項 Google Cloud Platform 專案中的 Cloud Storage 值區」。
工作項目失敗 4 次
批次工作失敗時會發生下列錯誤:
The job failed because a work item has failed 4 times.
如果批次作業中的單一作業造成工作站程式碼失敗四次,就會發生這個錯誤。Dataflow 會讓工作失敗,並顯示這則訊息。
以串流模式執行時,內含失敗項目的組合會無限期重試,而這可能會導致您的管道工作永久停滯。
您無法設定這項失敗門檻。詳情請參閱「管道錯誤和例外狀況處理」。
如要解決這個問題,請在工作的 Cloud Monitoring 記錄檔中,尋找這四個失敗狀況。在工作站記錄檔中,尋找顯示例外狀況或錯誤的錯誤層級或嚴重層級記錄項目。例外狀況或錯誤應至少出現四次。如果記錄只包含與存取外部資源 (例如 MongoDB) 相關的通用逾時錯誤,請確認工作人員服務帳戶有權存取資源的子網路。
輪詢結果檔案逾時
如需完整瞭解如何排解「Timeout in polling result file」錯誤,請參閱「排解 Flex 範本問題」。
Write Correct File/Write/WriteImpl/PreFinalize failed
執行工作時,工作會間歇性失敗,並發生下列錯誤:
Workflow failed. Causes: S27:Write Correct File/Write/WriteImpl/PreFinalize failed., Internal Issue (ID): ID:ID, Unable to expand file pattern gs://BUCKET_NAME/temp/FILE
如果多個同時執行的工作使用同一個子資料夾做為暫存儲存位置,就會發生這項錯誤。
如要解決這個問題,請勿將同一個子資料夾做為多個管道的暫時儲存位置。請為每個管道提供專屬的子資料夾,做為暫時儲存位置。
元素超過 protobuf 訊息大小上限
執行 Dataflow 工作時,如果管道有大型元素,您可能會看到類似下列範例的錯誤:
Exception serializing message!
ValueError: Message org.apache.beam.model.fn_execution.v1.Elements exceeds maximum protobuf size of 2GB
或:
Buffer size ... exceeds GRPC limit 2147483548. This is likely due to a single element that is too large.
您也可能會看到類似以下範例的警告:
Data output stream buffer size ... exceeds 536870912 bytes. This is likely due to a large element in a PCollection.
如果管道含有大型元素,就會發生這些錯誤。
如要解決這個問題,請升級至 Apache Beam 2.57.0 以上版本 (如果您使用 Python SDK)。Python SDK 2.57.0 以上版本可改善大型元素的處理作業,並新增相關記錄。
如果升級後錯誤仍存在,或您未使用 Python SDK,請找出發生錯誤的作業步驟,並嘗試縮減該步驟中元素的大小。
如果管道中的 PCollection 物件含有大型元素,管道的 RAM 需求就會增加。大型元素也可能導致執行階段錯誤,尤其是跨越融合階段界線時。
如果管道不慎具現化大型可疊代項目,就可能發生大型元素。舉例來說,如果管道將 GroupByKey 作業的輸出內容傳遞至不必要的 Reshuffle 作業,清單就會具體化為單一元素。這些清單可能包含每個鍵的大量值。
如果錯誤發生在採用側邊輸入的步驟,請注意,使用側邊輸入可能會造成融合障礙。檢查產生大型元素的轉換和使用該元素的轉換是否屬於同一個階段。
建構管道時,請遵循下列最佳做法:
- 在
PCollections中使用多個小型元素,而非單一大型元素。 - 在外部儲存系統中儲存大型 Blob。您可以透過
PCollections傳遞中繼資料,也可以使用自訂編碼器縮減元素大小。 - 如果必須將可能超過 2 GB 的 PCollection 做為側邊輸入傳遞,請使用可疊代檢視區塊,例如
AsIterable和AsMultiMap。
Dataflow 工作中單一元素的大小上限為 2 GB。詳情請參閱配額與限制。
Dataflow 無法處理受管理轉換...
如果 Dataflow 無法自動升級 I/O 轉換至最新支援版本,使用代管 I/O 的管道可能會失敗,並顯示這項錯誤。錯誤中提供的 URN 和步驟名稱應會指定 Dataflow 無法升級的確切轉換。
如要進一步瞭解這個錯誤,請前往「記錄檔探索工具」,查看 Dataflow 記錄檔名稱 managed-transforms-worker 和 managed-transforms-worker-startup。
如果記錄檔探索工具提供的資訊不足以排解錯誤,請與 Cloud Customer Care 聯絡。
封存工作錯誤
以下章節列出您嘗試使用 API 封存 Dataflow 工作時,可能會遇到的常見錯誤。
未提供任何值
使用 API 封存 Dataflow 作業時,可能會發生下列錯誤:
The field mask specifies an update for the field job_metadata.user_display_properties.archived in job JOB_ID, but no value is provided. To update a field, please provide a field for the respective value.
發生這項錯誤的原因如下:
「
updateMask」欄位指定的路徑格式有誤。 這個問題可能是因為輸入錯誤所致。JobMetadata指定有誤。在JobMetadata欄位中,針對userDisplayProperties,使用鍵/值組合"archived":"true"。
如要解決這個錯誤,請確認傳遞至 API 的指令符合必要格式。詳情請參閱「封存工作」。
API 無法辨識該值
使用 API 封存 Dataflow 作業時,可能會發生下列錯誤:
The API does not recognize the value VALUE for the field job_metadata.user_display_properties.archived for job JOB_ID. REASON: Archived display property can only be set to 'true' or 'false'
如果封存工作鍵/值配對中提供的值不受支援,就會發生這項錯誤。封存工作鍵/值組合支援的值為 "archived":"true" 和 "archived":"false"。
如要解決這個錯誤,請確認傳遞至 API 的指令符合必要格式。詳情請參閱「封存工作」。
無法同時更新狀態和遮罩
使用 API 封存 Dataflow 作業時,可能會發生下列錯誤:
Cannot update both state and mask.
如果您嘗試在同一個 API 呼叫中更新工作狀態和封存狀態,就會發生這個錯誤。您無法在同一個 API 呼叫中,同時更新工作狀態和 updateMask 查詢參數。
如要解決這個錯誤,請在另一個 API 呼叫中更新工作狀態。請先更新工作狀態,再更新工作封存狀態。
無法修改工作流程
使用 API 封存 Dataflow 作業時,可能會發生下列錯誤:
Workflow modification failed.
嘗試封存正在執行的工作時,通常會發生這個錯誤。
如要解決這個錯誤,請等待工作完成後再封存。 完成的工作會處於下列其中一種工作狀態:
JOB_STATE_CANCELLEDJOB_STATE_DRAINEDJOB_STATE_DONEJOB_STATE_FAILEDJOB_STATE_UPDATED
詳情請參閱「偵測 Dataflow 工作完成情況」。
容器映像檔錯誤
以下各節說明使用自訂容器時可能會遇到的常見錯誤,以及解決或排解錯誤的步驟。錯誤通常會以以下訊息做為前置字元:
Unable to pull container image due to error: DETAILED_ERROR_MESSAGE
「containeranalysis.occurrences.list」權限遭拒
記錄檔中會顯示以下錯誤:
Error getting old patchz discovery occurrences: generic::permission_denied: permission "containeranalysis.occurrences.list" denied for project "PROJECT_ID", entity ID "" [region="REGION" projectNum=PROJECT_NUMBER projectID="PROJECT_ID"]
安全漏洞掃描需要 Container Analysis API。
詳情請參閱 Artifact Analysis 說明文件中的「OS scanning overview」和「Configuring access control」。
Error syncing pod ... failed to "StartContainer"
啟動工作者時發生下列錯誤:
Error syncing pod POD_ID, skipping: [failed to "StartContainer" for CONTAINER_NAME with CrashLoopBackOff: "back-off 5m0s restarting failed container=CONTAINER_NAME pod=POD_NAME].
Pod 是在 Dataflow 工作站上執行的同位群組 Docker 容器。如果 Pod 中的其中一個 Docker 容器無法啟動,就會發生這個錯誤。如果無法復原,Dataflow 工作站就無法啟動,Dataflow 批次工作最終會失敗,並顯示下列錯誤訊息:
The Dataflow job appears to be stuck because no worker activity has been seen in the last 1h.
如果其中一個容器在啟動期間持續當機,通常就會發生這個錯誤。
如要瞭解根本原因,請尋找失敗前擷取的記錄。如要分析記錄,請使用記錄檔探索工具。在 Logs Explorer 中,將記錄檔限制為從工作站發出的記錄檔項目,其中包含容器啟動錯誤。如要限制記錄項目,請完成下列步驟:
- 在記錄檔探索工具中,找出
Error syncing pod記錄項目。 - 如要查看與記錄項目相關聯的標籤,請展開記錄項目。
- 按一下與
resource_name相關聯的標籤,然後點選「顯示相符的項目」。
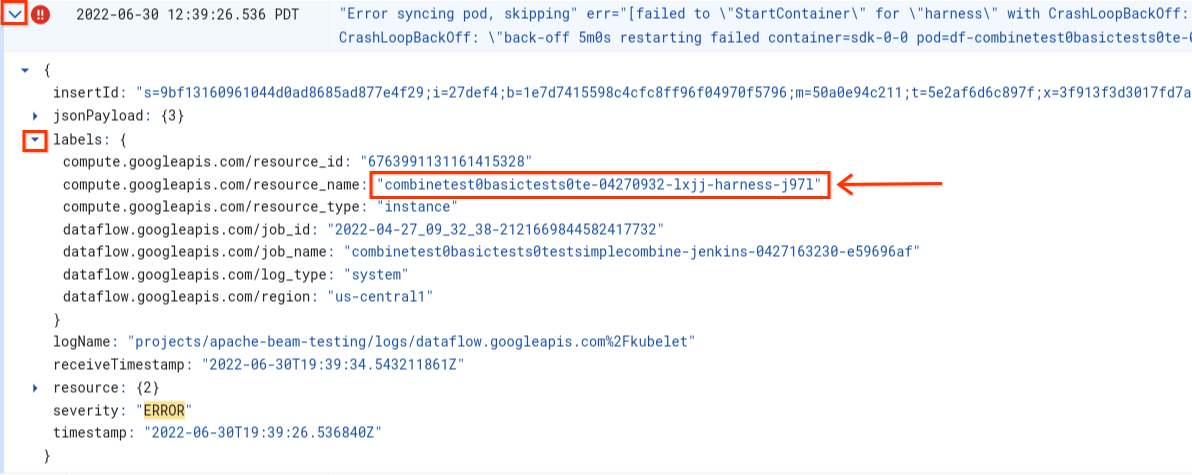
在記錄檔探索工具中,Dataflow 記錄會整理成數個記錄串流。系統會在名為 kubelet 的記錄檔中發出 Error syncing pod 訊息。不過,失敗容器的記錄可能位於不同的記錄串流。每個容器都有名稱。請參閱下表,判斷哪個記錄串流可能包含與失敗容器相關的記錄。
| 容器名稱 | 記錄檔名稱 |
|---|---|
| sdk、sdk0、sdk1、sdk-0-0 和類似項目 | docker |
| 胸背帶 | harness、harness-startup |
| python、java-batch、java-streaming | worker-startup、worker |
| 構件 | 構件 |
查詢 Logs Explorer 時,請確認查詢包含查詢建構工具介面中的相關記錄名稱,或未對記錄名稱設下限制。
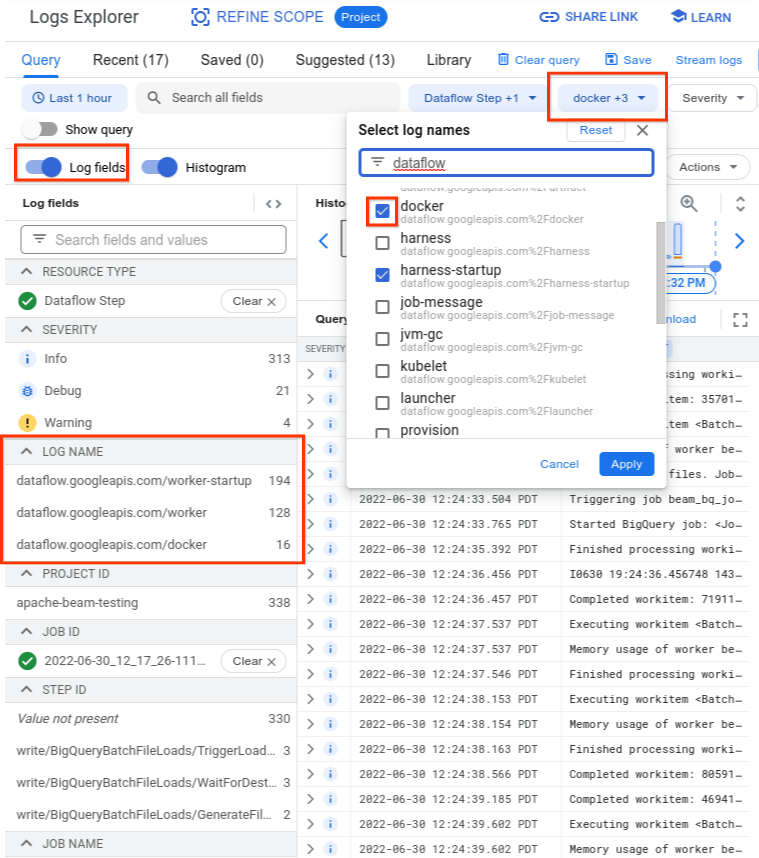
選取相關記錄後,查詢結果可能如下所示:
resource.type="dataflow_step"
resource.labels.job_id="2022-06-29_08_02_54-JOB_ID"
labels."compute.googleapis.com/resource_name"="testpipeline-jenkins-0629-DATE-cyhg-harness-8crw"
logName=("projects/apache-beam-testing/logs/dataflow.googleapis.com%2Fdocker"
OR
"projects/apache-beam-testing/logs/dataflow.googleapis.com%2Fworker-startup"
OR
"projects/apache-beam-testing/logs/dataflow.googleapis.com%2Fworker")
因為回報容器故障徵兆的記錄有時會回報為 INFO,因此請在分析中加入 INFO 記錄。
容器失敗的常見原因包括:
- 您的 Python pipeline 有額外的依附元件,會在執行階段安裝,但安裝失敗。您可能會看到類似
pip install failed with error的錯誤。發生這個問題的原因可能是需求衝突,或是網路設定受限,導致 Dataflow 工作站無法透過網際網路從公開存放區提取外部依附元件。 工作站在管道執行作業期間因記憶體不足而失敗。您可能會看到下列其中一則錯誤訊息:
java.lang.OutOfMemoryError: Java heap spaceShutting down JVM after 8 consecutive periods of measured GC thrashing. Memory is used/total/max = 24453/42043/42043 MB, GC last/max = 58.97/99.89 %, #pushbacks=82, gc thrashing=true. Heap dump not written.
如要偵錯記憶體不足的問題,請參閱「排解 Dataflow 記憶體不足錯誤」。
Dataflow 無法提取容器映像檔。詳情請參閱「Image pull request failed with error」。
使用的容器與工作站 VM 的 CPU 架構不相容。 在安全帶啟動記錄中,您可能會看到類似下列的錯誤:
exec /opt/apache/beam/boot: exec format error. 如要檢查容器映像檔的架構,請執行docker image inspect $IMAGE:$TAG並找出Architecture關鍵字。如果顯示Error: No such image: $IMAGE:$TAG,您可能需要先執行docker pull $IMAGE:$TAG來提取映像檔。如要瞭解如何建構多架構映像檔,請參閱「建構多架構容器映像檔」。
找出導致容器失敗的錯誤後,請嘗試解決錯誤,然後重新提交管道。
提取圖片要求失敗,並顯示錯誤
工作站啟動期間,工作站或工作記錄檔會顯示下列其中一個錯誤:
Image pull request failed with error
pull access denied for IMAGE_NAME
manifest for IMAGE_NAME not found: manifest unknown: Failed to fetch
Get IMAGE_NAME: Service Unavailable
如果工作站無法提取 Docker 容器映像檔,導致無法啟動,就會發生這些錯誤。這個問題會在下列情況發生:
- 自訂 SDK 容器映像檔網址不正確
- 工作站缺少憑證或網路存取權,無法存取遠端映像檔
如何解決這個問題:
- 如果作業使用自訂容器映像檔,請確認映像檔網址正確無誤,且具有有效的標記或摘要。Dataflow 工作站也需要存取映像檔。
- 從未經驗證的電腦執行
docker pull $image,確認公開映像檔可在本機上提取。
私人圖片或私人工作者:
- 如果您使用 Container Registry 託管容器映像檔,建議改用 Artifact Registry。自 2023 年 5 月 15 日起,Container Registry 已淘汰。如果您使用 Container Registry,可以改用 Artifact Registry。如果映像檔所在的專案與執行 Google Cloud Platform 工作的專案不同,請為預設的 Google Cloud Platform 服務帳戶設定存取權控制。
- 如果使用共用虛擬私有雲 (VPC),請確保工作站可以存取自訂容器存放區主機。
- 使用
ssh連線至正在執行的工作站 VM,然後執行docker pull $image,直接確認工作站設定是否正確。
如果工作站因這個錯誤連續多次失敗,且工作已在工作中啟動,工作可能會失敗,並顯示類似下列訊息的錯誤:
Job appears to be stuck.
如果在工作執行期間移除圖片存取權 (移除圖片本身,或撤銷 Dataflow 工作站服務帳戶憑證或存取圖片的網際網路存取權),Dataflow 只會記錄錯誤。Dataflow 不會導致工作失敗。 此外,Dataflow 也會避免長時間執行的串流管道失敗,以免管道狀態遺失。
其他可能發生的錯誤包括存放區配額問題或服務中斷。如果提取公開映像檔時超出 Docker Hub 配額,或是第三方存放區發生一般中斷問題,建議使用 Artifact Registry 做為映像檔存放區。
SystemError:不明的運算碼
提交工作後,Python 自訂容器管道可能會立即失敗,並顯示下列錯誤:
SystemError: unknown opcode
此外,堆疊追蹤記錄可能包含
apache_beam/internal/pickler.py
如要解決這個問題,請確認您在本機使用的 Python 版本與容器映像檔中的版本相符 (包括主要和次要版本)。修補程式版本 (例如 3.6.7 與 3.6.8) 的差異不會造成相容性問題。次要版本差異 (例如 3.6.8 與 3.8.2) 可能會導致管道失敗。
升級串流管道時發生錯誤
如要瞭解如何解決使用平行取代作業等功能升級串流管道時發生的錯誤,請參閱「排解串流管道升級問題」。
Runner v2 裝備更新
Runner v2 工作的工作記錄中會顯示以下資訊訊息
The Dataflow RunnerV2 container image of this job's workers will be ready for update in 7 days.
也就是說,在訊息首次傳送後的 7 天內,系統會在某個時間點自動更新執行器安全帶程序版本,導致處理作業短暫暫停。如要控管暫停時間,請參閱「更新現有管道」,啟動替換工作,該工作會使用最新版執行器架構。
工作站錯誤
以下各節將說明您可能會遇到的常見工作人員錯誤,以及解決或排解錯誤的步驟。
從 Java 工作站控管工具對 Python DoFn 進行的呼叫失敗,並顯示錯誤
如果從 Java 工作站控管工具對 Python DoFn 進行的呼叫失敗,則會顯示相關的錯誤訊息。
如要調查錯誤,請展開 Cloud Monitoring 錯誤記錄檔項目,並查看錯誤訊息和回溯。其中會顯示失敗的是哪個程式碼,您就可以視需要進行修正。如果您認為這是 Apache Beam 或 Dataflow 中的錯誤,請回報錯誤。
EOFError:marshal data too short
工作站記錄中會顯示下列錯誤:
EOFError: marshal data too short
如果 Python 管道工作者磁碟空間不足,有時就會發生這個錯誤。
如要解決這個問題,請參閱「裝置沒有足夠的空間」。
無法連結磁碟
當您嘗試啟動使用C3 VM 和永久磁碟的 Dataflow 工作時,工作會失敗,並顯示下列一或多個錯誤:
Failed to attach disk(s), status: generic::invalid_argument: One or more operations had an error
Can not allocate sha384 (reason: -2), Spectre V2 : WARNING: Unprivileged eBPF is enabled with eIBRS on...
如果使用 C3 VM,但永久磁碟類型不受支援,就會發生這些錯誤。詳情請參閱 C3 支援的磁碟類型。
如要搭配 Dataflow 工作使用 C3 VM,請選擇pd-ssd工作站磁碟類型。詳情請參閱「工作人員層級選項」。
Java
--workerDiskType=pd-ssd
Python
--worker_disk_type=pd-ssd
Go
disk_type=pd-ssd
裝置沒有足夠的空間
如果工作耗盡磁碟空間,工作站記錄中可能會顯示下列錯誤:
No space left on device
這個錯誤可能是由下列其中一項原因造成:
- 工作站永久儲存空間沒有可用空間,可能原因如下:
- 作業會在執行階段下載大型依附元件
- 工作使用大型自訂容器
- 工作將大量暫時資料寫入本機磁碟
- 使用 Dataflow Shuffle 時,Dataflow 會設定較低的預設磁碟大小。因此,如果工作是從以工作站為基礎的隨機播放功能移轉,就可能會發生這項錯誤。
- 工作站開機磁碟已滿,因為每秒記錄的項目超過 50 個。
如要解決這個問題,請按照下列疑難排解步驟操作:
如要查看與單一工作人員相關聯的磁碟資源,請查詢與工作相關聯的工作人員 VM 的 VM 執行個體詳細資料。作業系統、二進位檔、記錄檔和容器會佔用部分磁碟空間。
如要增加永久磁碟或開機磁碟空間,請調整磁碟大小管道選項。
使用 Cloud Monitoring 追蹤工作人員 VM 執行個體的磁碟空間用量。 如需設定方式的操作說明,請參閱「接收來自 Monitoring 代理程式的工作站 VM 指標」。
如要找出開機磁碟空間問題,請查看工作站 VM 執行個體的序列埠輸出內容,並尋找類似下列訊息:
Failed to open system journal: No space left on device
如果有多個工作站 VM 執行個體,可以建立指令碼,一次在所有執行個體上執行 gcloud compute instances get-serial-port-output。你可以改為查看該輸出內容。
Python 管道程序在工作站閒置一小時後失敗
在具有多個 CPU 核心的工作站上,使用 Python 適用的 Apache Beam SDK 和 Dataflow Runner V2 時,請使用 Apache Beam SDK 2.35.0 以上版本。如果工作使用自訂容器,請使用 Apache Beam SDK 2.46.0 以上版本。
建議您預先建構 Python 容器。這個步驟可以縮短 VM 啟動時間,並提升水平自動調度效能。如要使用這項功能,請在專案中啟用 Cloud Build API,並使用下列參數提交管道:
‑‑prebuild_sdk_container_engine=cloud_build。
詳情請參閱 Dataflow Runner V2。
您也可以使用自訂容器映像檔,並預先安裝所有依附元件。
RESOURCE_POOL_EXHAUSTED
建立 Google Cloud Platform 資源時,發生下列錯誤:
Startup of the worker pool in zone ZONE_NAME failed to bring up any of the desired NUMBER workers.
ZONE_RESOURCE_POOL_EXHAUSTED_WITH_DETAILS: Instance 'INSTANCE_NAME' creation failed: The zone 'projects/PROJECT_ID/zones/ZONE_NAME' does not have enough resources available to fulfill the request. '(resource type:RESOURCE_TYPE)'.
特定區域的特定資源暫時缺貨時,就會發生這個錯誤。
如要解決這個問題,您可以等待,或是在其他區域建立相同的資源。
為解決這個問題,請為工作實作重試迴圈,這樣一來,發生缺貨錯誤時,工作就會自動重試,直到資源可用為止。如要建立重試迴圈,請實作下列工作流程:
- 建立 Dataflow 工作,並取得工作 ID。
- 輪詢工作狀態,直到工作狀態為
RUNNING或FAILED為止。- 如果工作狀態為
RUNNING,請結束重試迴圈。 - 如果工作狀態為
FAILED,請使用 Cloud Logging API 查詢工作記錄檔中的字串ZONE_RESOURCE_POOL_EXHAUSTED_WITH_DETAILS。詳情請參閱「處理管道記錄」。- 如果記錄檔不含該字串,請退出重試迴圈。
- 如果記錄包含該字串,請建立 Dataflow 工作、取得工作 ID,然後重新啟動重試迴圈。
- 如果工作狀態為
最佳做法是將資源分散到多個區域和地區,以容許工作中斷情形。
搭載客體加速器的執行個體不支援即時遷移
提交工作時,Dataflow pipeline 失敗並顯示下列錯誤:
UNSUPPORTED_OPERATION: Instance <worker_instance_name> creation failed:
Instances with guest accelerators do not support live migration
如果您要求使用具備硬體加速器的工作站機器類型,但未將 Dataflow 設定為使用加速器,就可能會發生這項錯誤。
使用 --worker_accelerator Dataflow
服務選項或
accelerator
資源提示,要求使用硬體加速器。
如果您使用 Flex 範本,可以透過 --additionalExperiments 選項提供 Dataflow 服務選項。如果操作正確,您可以在Google Cloud 控制台的工作資訊面板中找到 worker_accelerator 選項。
專案配額 ... 或存取權控管政策禁止這項作業
發生下列錯誤:
Startup of the worker pool in zone ZONE_NAME failed to bring up any of the desired NUMBER workers. The project quota may have been exceeded or access control policies may be preventing the operation; review the Cloud Logging 'VM Instance' log for diagnostics.
發生這項錯誤的原因如下:
- 您已超過 Dataflow 工作站建立作業所依據的其中一個 Compute Engine 配額。
- 貴機構已設定限制,禁止 VM 執行個體建立程序中的某些環節,例如使用的帳戶或目標區域。
如要解決這個問題,請按照下列疑難排解步驟操作:
查看 VM 執行個體記錄
- 前往 Cloud Logging 檢視器
- 在「受稽核的資源」下拉式清單中,選取「VM 執行個體」。
- 在「所有記錄」下拉式清單中,選取「compute.googleapis.com/activity_log」。
- 掃描記錄,找出與 VM 執行個體建立失敗相關的項目。
查看 Compute Engine 配額用量
如要查看 Compute Engine 資源用量與目標區域的 Dataflow 配額比較結果,請執行下列指令:
gcloud compute regions describe [REGION]請查看下列資源的結果,確認是否有任何資源超出配額:
- CPU
- DISKS_TOTAL_GB
- IN_USE_ADDRESSES
- INSTANCE_GROUPS
- 執行個體
- REGIONAL_INSTANCE_GROUP_MANAGERS
如有需要,請申請調整配額。
查看機構政策限制
- 前往機構政策頁面
- 請檢查是否有任何限制,可能會限制您使用的帳戶 (預設為 Dataflow 服務帳戶) 或目標區域建立 VM 執行個體。
- 如果您有禁止使用外部 IP 位址的政策,請為這項工作關閉外部 IP 位址。如要進一步瞭解如何關閉外部 IP 位址,請參閱「設定網際網路存取權與防火牆規則」。
等待工作人員更新時逾時
如果 Dataflow 工作失敗,會發生下列錯誤:
Root cause: Timed out waiting for an update from the worker. For more information, see https://cloud.google.com/dataflow/docs/guides/common-errors#worker-lost-contact.
造成這項錯誤的原因有很多,包括:
工作人員超載
有時,當 worker 記憶體或交換空間不足時,會發生逾時錯誤。如要解決這個問題,請先嘗試重新執行工作。如果作業仍失敗並發生相同錯誤,請嘗試使用記憶體和磁碟空間較大的工作人員。舉例來說,請新增下列管道啟動選項:
--worker_machine_type=m1-ultramem-40 --disk_size_gb=500
變更工作人員類型可能會影響帳單費用。詳情請參閱「排解 Dataflow 記憶體不足錯誤」。
如果資料含有熱鍵,也可能發生這個錯誤。在這種情況下,工作執行期間,部分 worker 的 CPU 使用率大多偏高。不過,工作站數量未達允許上限。如要進一步瞭解快速鍵和可能的解決方案,請參閱「撰寫 Dataflow 管道時考量可擴充性」。
如需這個問題的其他解決方案,請參閱「偵測到熱鍵 ...」。
Python:全域直譯器鎖定 (GIL)
如果 Python 程式碼使用 Python 擴充機制呼叫 C/C++ 程式碼,請檢查擴充功能程式碼是否在不存取 Python 狀態的運算密集型程式碼部分,釋放 Python 全域解譯器鎖定 (GIL)。如果 GIL 長時間未釋出,您可能會看到類似 Unable to retrieve status info from SDK harness <...> within allowed time 和 SDK worker appears to be permanently unresponsive. Aborting the SDK 的錯誤訊息。
可促進與擴充功能互動的程式庫 (例如 Cython 和 PyBind) 具有控制 GIL 狀態的基元。您也可以使用 Py_BEGIN_ALLOW_THREADS 和 Py_END_ALLOW_THREADS 巨集,手動釋放 GIL 並重新取得,然後將控制權傳回 Python 解譯器。詳情請參閱 Python 說明文件中的「執行緒狀態和全域直譯器鎖定」。
您或許可以擷取在執行中的 Dataflow worker 上保留 GIL 的執行緒堆疊追蹤,方法如下:
# SSH into a running Dataflow worker VM that is currently a straggler, for example:
gcloud compute ssh --zone "us-central1-a" "worker-that-emits-unable-to-retrieve-status-messages" --project "project-id"
# Install nerdctl to inspect a running container with ptrace privileges.
wget https://github.com/containerd/nerdctl/releases/download/v2.0.2/nerdctl-2.0.2-linux-amd64.tar.gz
sudo tar Cxzvvf /var/lib/toolbox nerdctl-2.0.2-linux-amd64.tar.gz
alias nerdctl="sudo /var/lib/toolbox/nerdctl -n k8s.io"
# Find a container running the Python SDK harness.
CONTAINER_ID=`nerdctl ps | grep sdk-0-0 | awk '{print $1}'`
# Start a shell in the running container.
nerdctl exec --privileged -it $CONTAINER_ID /bin/bash
# Inspect python processes in the running container.
ps -A | grep python
PYTHON_PID=$(ps -A | grep python | head -1 | awk '{print $1}')
# Use pystack to retrieve stacktraces from the python process.
pip install pystack
pystack remote --native $PYTHON_PID
# Find which thread holds the GIL and inspect the stacktrace.
pystack remote --native $PYTHON_PID | grep -iF "Has the GIL" -A 100
# Alternately, use inspect with gdb.
apt update && apt install -y gdb
gdb --quiet \
--eval-command="set pagination off" \
--eval-command="thread apply all bt" \
--eval-command "set confirm off" \
--eval-command="quit" -p $PYTHON_PID
在 Python 管道中,根據預設設定,Dataflow 會假設在工作站上執行的每個 Python 程序,都能有效率地使用一個 vCPU 核心。如果管道程式碼規避 GIL 限制 (例如使用以 C++ 實作的程式庫),處理元素可能會使用多個 vCPU 核心的資源,而工作人員可能無法取得足夠的 CPU 資源。如要解決這個問題,請減少工作站上的執行緒數量。
長時間執行的 DoFn 設定
如果您未使用 Runner v2,長時間呼叫 DoFn.Setup 可能會導致下列錯誤:
Timed out waiting for an update from the worker
一般來說,請避免在 DoFn.Setup 中執行耗時的作業。
發布至主題時發生暫時性錯誤
如果串流工作使用「至少一次」串流模式,並發布至 Pub/Sub 接收器,工作記錄中會顯示下列錯誤:
There were transient errors publishing to topic
如果工作正常執行,這項錯誤不會造成影響,可以忽略。 Dataflow 會自動重試傳送 Pub/Sub 訊息,並延遲一段時間。
金鑰的權杖不符,因此無法擷取資料
如果出現下列錯誤,表示正在處理的工作項目已重新指派給其他工作者:
Unable to fetch data due to token mismatch for key
這種情況最常發生在自動調整規模期間,但隨時都可能發生。系統會重試任何受影響的工作。您可以忽略這項錯誤。
Java 依附元件問題
不相容的類別和程式庫可能會導致 Java 依附元件問題。如果管道發生 Java 依附元件問題,可能會出現下列其中一個錯誤:
NoClassDefFoundError:如果執行階段無法使用整個類別,就會發生這項錯誤。原因可能是設定問題,或是 Beam 的 protobuf 版本與用戶端產生的 proto 不相容 (例如這個問題)。NoSuchMethodError:如果類別路徑中的類別使用不含正確方法或方法簽章已變更的版本,就會發生這項錯誤。NoSuchFieldError:如果類別路徑中的類別使用的版本沒有執行階段所需的欄位,就會發生這個錯誤。FATAL ERROR in native method:如果無法正常載入內建依附元件,就會發生這個錯誤。使用 uber JAR (shaded) 時,請勿在同一個 JAR 中加入使用簽章的程式庫 (例如 Conscrypt)。
如果管道包含使用者專屬的程式碼和設定,程式碼就不能混用不同版本的程式庫。 如果您使用依附元件管理程式庫,建議使用 Google Cloud Platform 程式庫 BOM。
如果您使用 Apache Beam SDK,請使用 beam-sdks-java-io-google-cloud-platform-bom 匯入正確的程式庫 BOM:
Maven
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.apache.beam</groupId>
<artifactId>beam-sdks-java-google-cloud-platform-bom</artifactId>
<version>BEAM_VERSION</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
Gradle
dependencies {
implementation(platform("org.apache.beam:beam-sdks-java-google-cloud-platform-bom:BEAM_VERSION"))
}
詳情請參閱「在 Dataflow 中管理管道依附元件」。
JDK 17 以上版本中的 InaccessibleObjectException
使用 Java Platform, Standard Edition Development Kit (JDK) 17 以上版本執行管道時,工作站記錄檔中可能會出現下列錯誤:
Unable to make protected METHOD accessible:
module java.MODULE does not "opens java.MODULE" to ...
發生這個問題的原因是,從 Java 第 9 版開始,如要存取 JDK 內部項目,必須使用開放式模組 Java 虛擬機器 (JVM) 選項。在 Java 16 以上版本中,如要存取 JDK 內部項目,一律需要開放式模組 JVM 選項。
如要解決這個問題,請將模組傳遞至要開啟的 Dataflow 管道時,使用 jdkAddOpenModules 管道選項的 MODULE/PACKAGE=TARGET_MODULE(,TARGET_MODULE)* 格式。這個格式可存取必要的程式庫。
舉例來說,如果錯誤是 module java.base does not "opens java.lang" to unnamed module @...,請在執行管道時加入下列管道選項:
--jdkAddOpenModules=java.base/java.lang=ALL-UNNAMED
詳情請參閱 DataflowPipelineOptions 類別說明文件。
回報工作項目進度時發生錯誤
如果是 Java 管道,且您未使用 Running V2,可能會看到下列錯誤:
Error reporting workitem progress update to Dataflow service: ...
這個錯誤是由工作項目進度更新期間 (例如分割來源時) 未處理的例外狀況所導致。在多數情況下,如果 Apache Beam 使用者程式碼擲回未處理的例外狀況,工作項目就會失敗,導致管道失敗。不過,Source.split 中的例外狀況會遭到抑制,因為該部分程式碼位於工作項目之外。因此系統只會記錄錯誤記錄。
如果這個錯誤只是偶爾發生,通常不會造成影響。不過,建議您在 Source.split 程式碼中妥善處理例外狀況。
BigQuery 連接器錯誤
以下各節列出您可能會遇到的常見 BigQuery 連接器錯誤,以及解決或排解錯誤的步驟。
quotaExceeded
使用 BigQuery 連接器透過串流插入作業寫入 BigQuery 時,寫入輸送量會低於預期,且可能會發生下列錯誤:
quotaExceeded
如果管道超過可用的 BigQuery 串流插入配額,可能會導致總處理量緩慢。如果是,Dataflow 工作人員記錄中會顯示 BigQuery 的配額相關錯誤訊息 (請尋找 quotaExceeded 錯誤)。
如果看到 quotaExceeded 錯誤,請按照下列步驟解決問題:
- 使用 Java 適用的 Apache Beam SDK 時,請設定 BigQuery 接收器選項
ignoreInsertIds()。 - 使用 Python 適用的 Apache Beam SDK 時,請使用
ignore_insert_ids選項。
完成這些設定後,您就能享有每專案每秒 1 GB 的 BigQuery 串流插入輸送量。如要進一步瞭解自動訊息重複資料刪除功能相關注意事項,請參閱 BigQuery 說明文件。如要將 BigQuery 串流插入配額提高至 1 GBps 以上,請透過 Google Cloud 控制台提出要求。
如果工作人員記錄中沒有配額相關錯誤,問題可能是預設的組合或批次處理相關參數,無法為管道提供足夠的平行處理能力來擴充規模。您可以調整多項 Dataflow BigQuery 連接器相關設定,在透過串流插入功能寫入 BigQuery 時,達到預期效能。舉例來說,如果是 Apache Beam Java SDK,請調整 numStreamingKeys,使其符合工作站數量上限,並考慮增加 insertBundleParallelism,將 BigQuery 連接器設定為使用更多平行執行緒寫入 BigQuery。
如要瞭解 Apache Beam SDK for Java 提供的設定,請參閱 BigQueryPipelineOptions;如要瞭解 Apache Beam SDK for Python 提供的設定,請參閱 WriteToBigQuery 轉換。
rateLimitExceeded
使用 BigQuery 連接器時,發生下列錯誤:
rateLimitExceeded
如果在短時間內傳送過多 API 要求,BigQuery 就會發生這個錯誤。BigQuery 有短期配額限制。
您的 Dataflow 管道可能會暫時超過這類配額。在這種情況下,Dataflow 管道傳送至 BigQuery 的 API 要求可能會失敗,導致工作人員記錄中出現 rateLimitExceeded 錯誤。
Dataflow 會重試這類失敗,因此您可以放心忽略這些錯誤。如果您認為管道受到 rateLimitExceeded 錯誤影響,請與 Cloud Customer Care 聯絡。
其他錯誤
以下各節列出您可能會遇到的其他錯誤,以及解決或排解錯誤的步驟。
無法分配 sha384
工作正常執行,但工作記錄中顯示下列錯誤:
ima: Can not allocate sha384 (reason: -2)
如果工作正常執行,這項錯誤不會造成影響,可以忽略。 工作站 VM 基本映像檔有時會產生這則訊息。 Dataflow 會自動回應並解決基礎問題。
我們已收到要求,希望將這則訊息的層級從 WARN 變更為 INFO。詳情請參閱「將 Dataflow 系統啟動錯誤記錄層級調降為 WARN 或 INFO」。
初始化動態外掛程式探測器時發生錯誤
工作正常執行,但工作記錄中顯示下列錯誤:
Error initializing dynamic plugin prober" err="error (re-)creating driver directory: mkdir /usr/libexec/kubernetes: read-only file system
如果工作正常執行,這項錯誤不會造成影響,可以忽略。 如果 Dataflow 工作嘗試建立目錄,但沒有必要的寫入權限,就會發生這項錯誤,導致工作失敗。如果工作成功,表示不需要該目錄,或是 Dataflow 已解決根本問題。
我們已收到要求,希望將這則訊息的層級從 WARN 變更為 INFO。詳情請參閱「將 Dataflow 系統啟動錯誤記錄層級調降為 WARN 或 INFO」。
找不到以下物件:pipeline.pb
使用 JOB_VIEW_ALL 選項列出工作時,發生下列錯誤:
No such object: BUCKET_NAME/PATH/pipeline.pb
如果從工作暫存檔案中刪除 pipeline.pb 檔案,就可能發生這個錯誤。
略過 Pod 同步
工作正常執行,但您在工作記錄中看到下列其中一項錯誤:
Skipping pod synchronization" err="container runtime status check may not have completed yet"
或:
Skipping pod synchronization" err="[container runtime status check may not have completed yet, PLEG is not healthy: pleg has yet to be successful]"
如果工作正常執行,這些錯誤不會造成影響,您可以忽略。
如果 Kubernetes kubelet 正在等待容器執行階段初始化,因此略過 Pod 同步作業,就會顯示 container runtime status check may not have completed yet 訊息。發生這種情況的原因有很多,例如容器執行階段最近啟動或重新啟動。
如果訊息包含 PLEG is not healthy: pleg has yet to be successful,表示 kubelet 正在等待 Pod 生命週期事件產生器 (PLEG) 恢復正常,然後再同步處理 Pod。PLEG 負責產生 kubelet 用來追蹤 Pod 狀態的事件。
我們已收到要求,希望將這則訊息的層級從 WARN 變更為 INFO。詳情請參閱「將 Dataflow 系統啟動錯誤記錄層級調降為 WARN 或 INFO」。
建議
如需 Dataflow 深入分析結果產生的建議,請參閱「深入分析」。