Cloud Profiler 是具有統計功能的低負擔分析器,可持續從實際工作環境中的應用程式收集 CPU 使用狀況和記憶體分配資訊;詳情請參閱「剖析概念」。如要排解或監控管道效能,請使用 Dataflow 與 Cloud Profiler 的整合功能,找出耗用最多資源的管道程式碼部分。
如需建構或執行 Dataflow 管道的疑難排解提示和偵錯策略,請參閱「管道疑難排解和偵錯」。
事前準備
瞭解剖析概念,並熟悉 Profiler 介面。如要瞭解如何開始使用 Profiler 介面,請參閱「選取要分析的剖析資料」。
您必須先為專案啟用 Cloud Profiler API,才能啟動作業。
首次造訪 Profiler 頁面時,系統會自動啟用這項功能。或者,您也可以使用 Google Cloud CLI gcloud 指令列工具或 Google Cloud 控制台啟用 Cloud Profiler API。
如要使用 Cloud Profiler,專案必須有足夠的配額。此外,Dataflow 作業的工作站服務帳戶必須具備適當的權限,才能使用分析器。舉例來說,如要建立設定檔,工作站服務帳戶必須具備 cloudprofiler.profiles.create 權限,這項權限包含在 Cloud Profiler 代理程式 (roles/cloudprofiler.agent) IAM 角色中。詳情請參閱「使用身分與存取權管理功能控管存取權」一文。
為 Dataflow 管道啟用 Cloud Profiler
Cloud Profiler 適用於以 Apache Beam SDK for Java 和 Python 2.33.0 以上版本編寫的 Dataflow 管道。Python 管道必須使用 Dataflow Runner v2。您可以在管道啟動時啟用 Cloud Profiler。預期管道的 CPU 和記憶體攤銷費用會低於 1%。
Java
如要啟用 CPU 剖析功能,請使用下列選項啟動管道。
--dataflowServiceOptions=enable_google_cloud_profiler
如要啟用堆積分析,請使用下列選項啟動管道。堆積剖析功能需要 Java 11 以上版本。
--dataflowServiceOptions=enable_google_cloud_profiler
--dataflowServiceOptions=enable_google_cloud_heap_sampling
Python
如要使用 Cloud Profiler,Python 管道必須透過 Dataflow Runner v2 執行。
如要啟用 CPU 剖析功能,請使用下列選項啟動管道。Python 尚不支援堆積剖析功能。
--dataflow_service_options=enable_google_cloud_profiler
Go
如要啟用 CPU 和堆積分析,請使用下列選項啟動管道。
--dataflow_service_options=enable_google_cloud_profiler
如果您是從 Dataflow 範本部署管道,並想啟用 Cloud Profiler,請將 enable_google_cloud_profiler 和 enable_google_cloud_heap_sampling 標記指定為額外實驗。
控制台
如果您使用 Google 提供的範本,可以在 Dataflow「Create job from template」(利用範本建立工作) 頁面的「Additional experiments」(其他實驗) 欄位中指定標記。
gcloud
如果您使用 Google Cloud CLI 執行範本,請視範本類型使用 gcloud
dataflow jobs run 或 gcloud dataflow flex-template run,並使用 --additional-experiments 選項指定旗標。
API
如果您使用 REST API 執行範本,請視範本類型,透過執行階段環境的 additionalExperiments 欄位 (RuntimeEnvironment 或 FlexTemplateRuntimeEnvironment) 指定旗標。
查看剖析資料
如果已啟用 Cloud Profiler,工作頁面會顯示 Profiler 頁面的連結。

您也可以在 Profiler 頁面中找到 Dataflow 管道的剖析資料。「服務」是工作名稱,「版本」是工作 ID。

使用 Cloud Profiler
「剖析器」頁面包含火焰圖,顯示在工作站上執行的每個影格的統計資料。在水平方向,您可以查看每個影格的執行時間 (以 CPU 作業時間為單位)。在垂直方向,您可以看到堆疊追蹤和並行執行的程式碼。 堆疊追蹤記錄主要都是執行器基礎架構程式碼。為了進行偵錯,我們通常會關注使用者程式碼的執行情況,這類資訊通常位於圖表底部的提示附近。 您可以尋找標記影格來識別使用者程式碼,這些影格代表已知只會呼叫使用者程式碼的執行器程式碼。 如果是 Beam ParDo 執行器,系統會建立動態介面卡層,以叫用使用者提供的 DoFn 方法簽章。這個層可識別為帶有 invokeProcessElement 後置字串的影格。下圖顯示如何尋找標記影格。
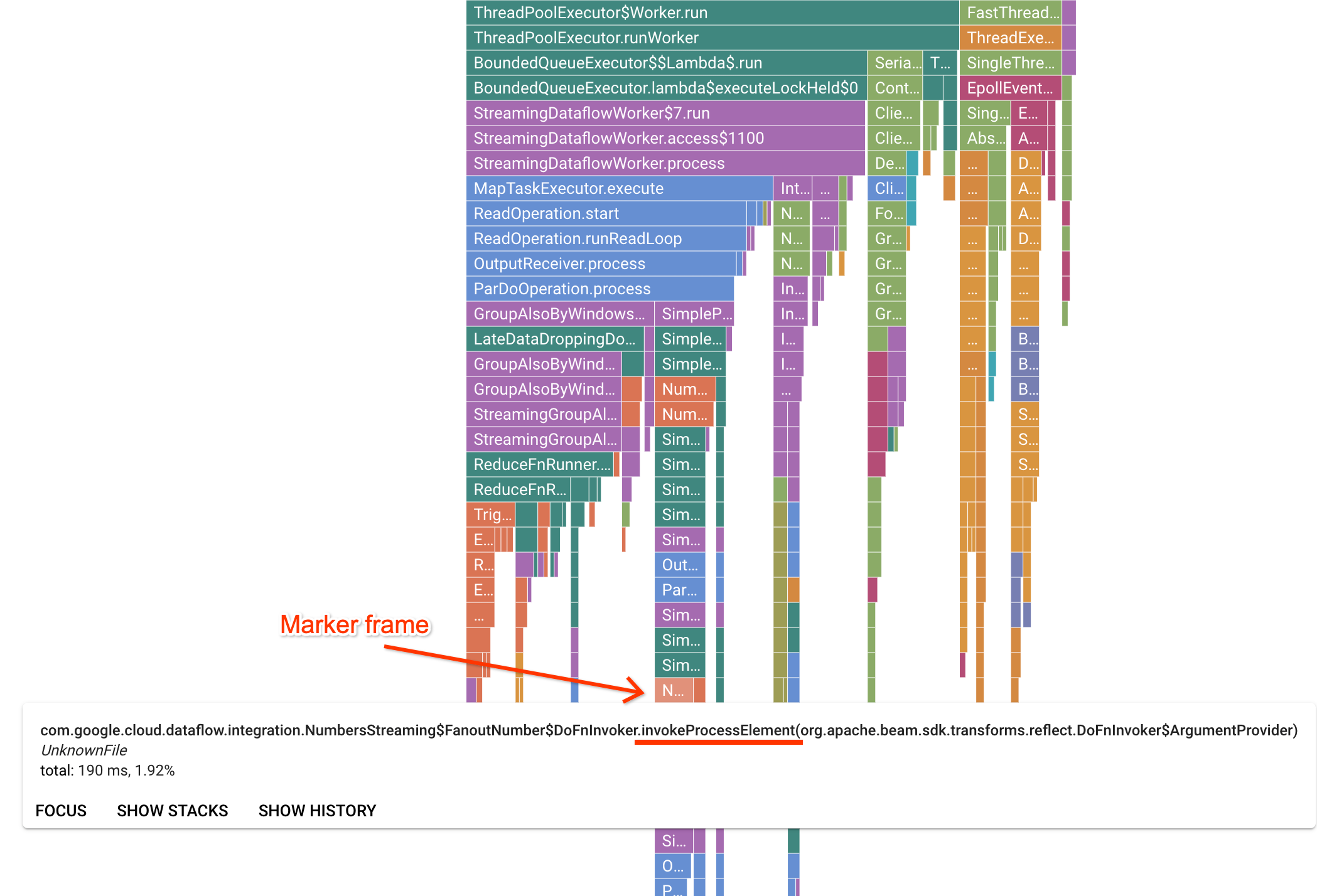
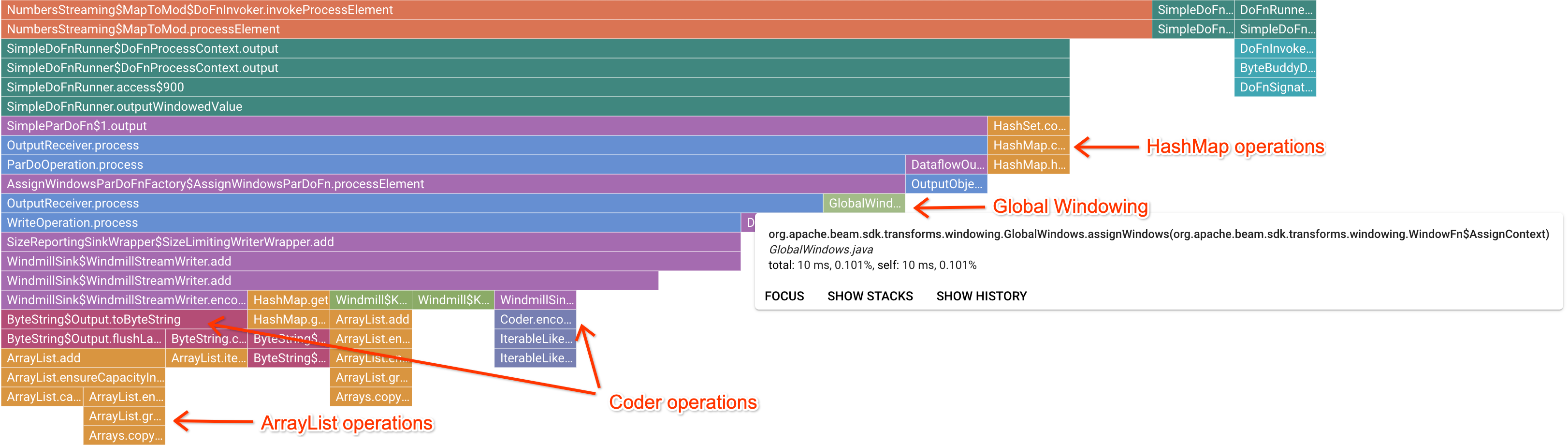
點選感興趣的標記框架後,火焰圖會著重顯示該堆疊追蹤記錄,讓您清楚瞭解長時間執行的使用者程式碼。最慢的作業可能表示瓶頸形成的位置,並提供最佳化機會。在下列範例中,您可以看到系統正在使用 ByteArrayCoder 搭配全域時間區間。在本例中,與 ArrayList 和 HashMap 作業相比,編碼器佔用大量 CPU 時間,因此可能是最佳化作業的好選擇。
排解 Cloud Profiler 問題
如果您啟用 Cloud Profiler,但管道未產生剖析資料,可能是下列其中一個原因所致。
您的管道使用舊版 Apache Beam SDK。如要使用 Cloud Profiler,您必須使用 Apache Beam SDK 2.33.0 以上版本。您可以在作業頁面查看管道的 Apache Beam SDK 版本。如果工作是透過 Dataflow 範本建立,範本必須使用支援的 SDK 版本。
您的專案 Cloud Profiler 配額即將用盡,您可以從專案的配額頁面查看配額用量。如果超出 Cloud Profiler 配額,可能會發生
Failed to collect and upload profile whose profile type is WALL等錯誤。如果已達到配額,Cloud Profiler 服務會拒絕剖析資料。如要進一步瞭解 Cloud Profiler 配額,請參閱「配額與限制」。工作執行時間不夠長,無法產生 Cloud Profiler 的資料。 如果工作執行時間較短 (例如不到五分鐘),Cloud Profiler 可能無法取得足夠的剖析資料來產生結果。
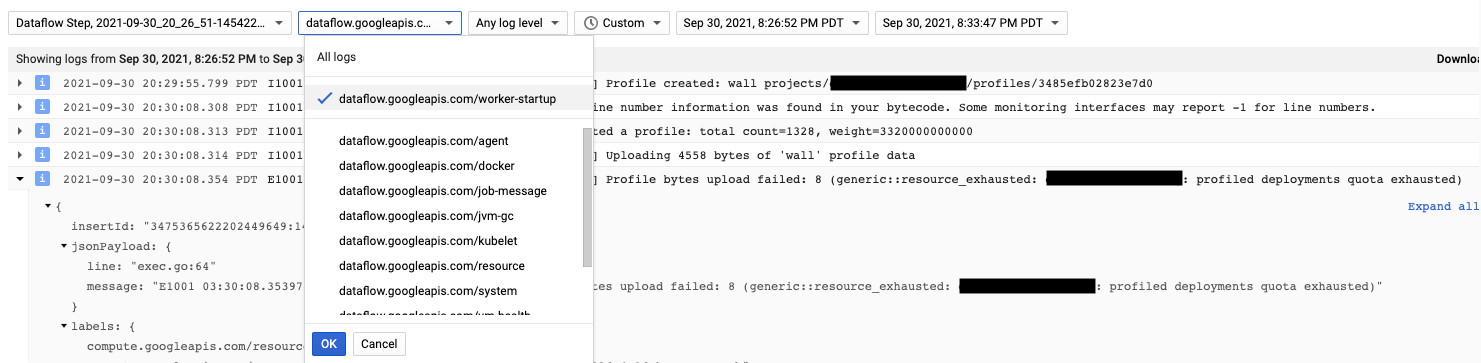
Cloud Profiler 代理程式會在 Dataflow 工作站啟動時安裝。Cloud Profiler 產生的記錄訊息會顯示在 dataflow.googleapis.com/worker-startup 記錄類型中。
有時系統會產生剖析資料,但 Cloud Profiler 不會顯示任何輸出內容。分析器會顯示類似 There were
profiles collected for the specified time range, but none match the current
filters 的訊息。
如要解決這個問題,請嘗試下列疑難排解步驟。
請確認 Profiler 中的時間範圍和結束時間包含作業的經過時間。
確認您在分析器中選取了正確的工作。「Service」是您的工作名稱。
確認
job_name管道選項的值與 Dataflow 工作頁面上的工作名稱相同。如果您在載入 Profiler 代理程式時指定了 service-name 引數,請確認服務名稱設定正確。