このページでは、Cloud Storage から BigQuery にデータを移行するときに、 Google Cloudリソースへのアクセスを名前空間レベルで制御するユースケースについて説明します。
Google Cloud リソースへのアクセスを制御するために、Cloud Data Fusion の名前空間はデフォルトで Cloud Data Fusion API サービス エージェントを使用します。
データの分離を適切に行うには、カスタマイズされた IAM サービス アカウント(Per Namespace Service Account と呼ばれる)を各名前空間に関連付けます。カスタマイズされた IAM サービス アカウントは名前空間ごとに異なる場合があり、パイプラインのプレビュー、Wrangler、パイプラインの検証など、Cloud Data Fusion でのパイプライン設計時のオペレーションのために、名前空間の間のGoogle Cloud リソースへのアクセスを制御できます。
詳細については、名前空間サービス アカウントを使用したアクセス制御をご覧ください。
シナリオ
このユースケースでは、マーケティング部門が Cloud Data Fusion を使用して Cloud Storage から BigQuery にデータを移行します。
マーケティング部門には A、B、C の 3 つのチームがあります。 目標は、各チーム(A、B、C)に対応する Cloud Data Fusion 名前空間を使用して、Cloud Storage のデータアクセスを制御する構造化アプローチを確立することです。
解決策
次の手順では、名前空間サービス アカウントを使用して Google Cloud リソースへのアクセスを制御し、異なるチームのデータストア間での不正アクセスを防ぐ方法を示します。
Identity and Access Management サービス アカウントを各名前空間に関連付ける
チームごとに、名前空間に IAM サービス アカウントを構成します(名前空間サービス アカウントを構成するをご覧ください)。
チーム A 用のカスタマイズされたサービス アカウントを追加して、アクセス制御を設定します(例:
team-a@pipeline-design-time-project.iam.gserviceaccount.com)。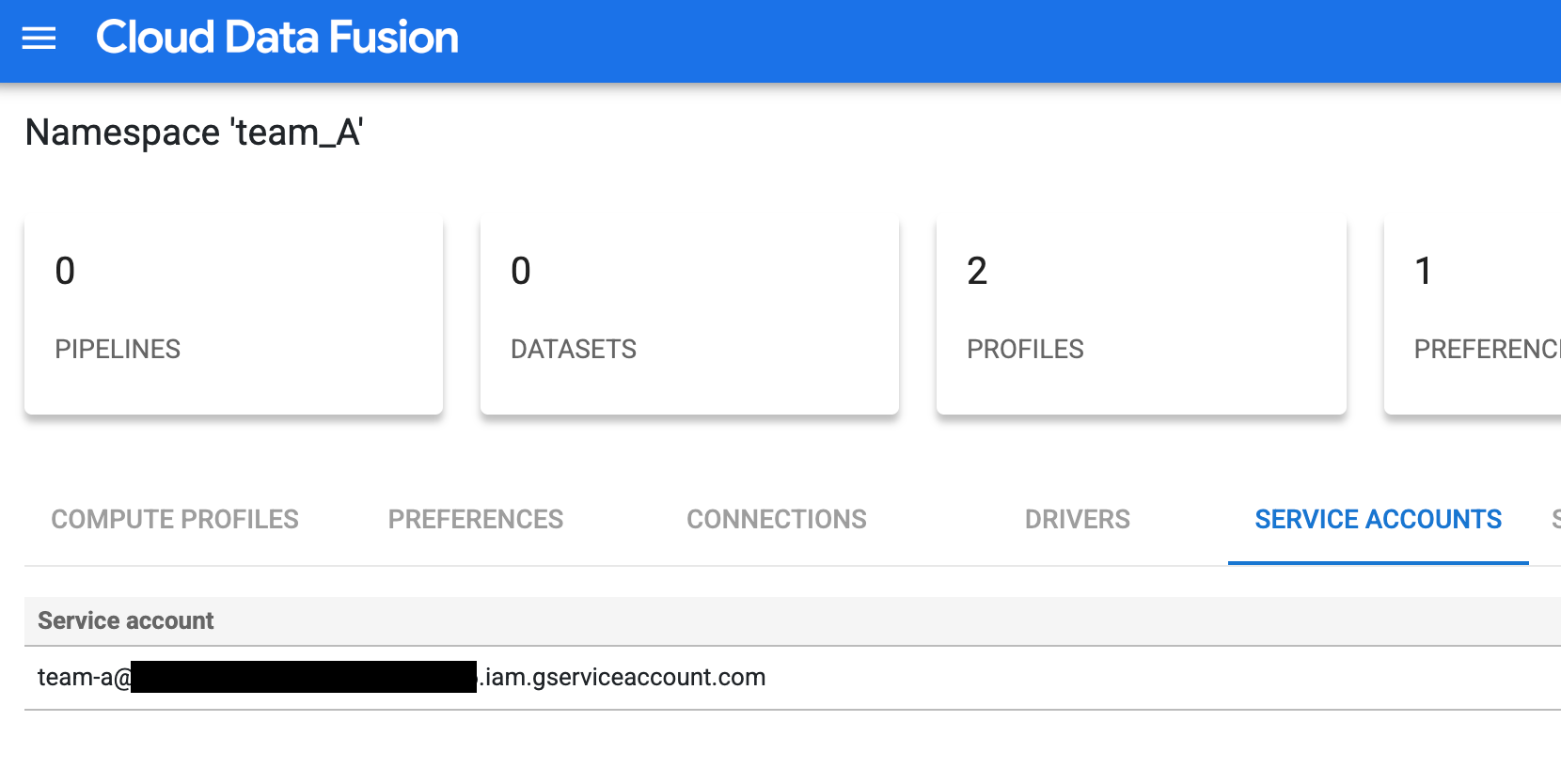
図 1: チーム A 用のカスタマイズされたサービス アカウントを追加します。 チーム B と C の構成手順を繰り返して、同様のカスタマイズされたサービス アカウントを使用してアクセス制御を設定します。
Cloud Storage バケットへのアクセスを制限する
適切な権限を付与して、Cloud Storage バケットへのアクセスを制限します。
- IAM サービス アカウントに、プロジェクト内の Cloud Storage バケットの一覧表示に必要な
storage.buckets.list権限を付与します。 詳細については、バケットの一覧表示をご覧ください。 IAM サービス アカウントに、特定のバケット内のオブジェクトにアクセスする権限を付与します。
たとえば、Storage オブジェクト閲覧者ロールを、バケット
team_a1の名前空間team_Aに関連付けられた IAM サービス アカウントに付与します。この権限により、チーム A は分離された設計時の環境で、バケット内のオブジェクトとマネージド フォルダおよびそのメタデータを表示して一覧表示できます。![[バケット] の詳細ページでロールを付与します。](https://cloud.google.com/static/data-fusion/docs/images/use-case/grant-access-to-team-a1.png?hl=ja)
図 2: Cloud Storage の [バケット] ページで、チームをプリンシパルとして追加し、Storage オブジェクトのユーザーロールを割り当てます。
それぞれの名前空間に Cloud Storage 接続を作成する
各チームの名前空間に Cloud Storage 接続を作成します。
Google Cloud コンソールで、Cloud Data Fusion の [インスタンス] ページに移動し、Cloud Data Fusion ウェブ インターフェースでインスタンスを開きます。
[システム管理者] > [設定] > [名前空間] をクリックします。
使用する名前空間(チーム A の名前空間など)をクリックします。
[接続] タブをクリックし、[ネットワークを追加] をクリックします。
[GCS] を選択し、接続を構成します。
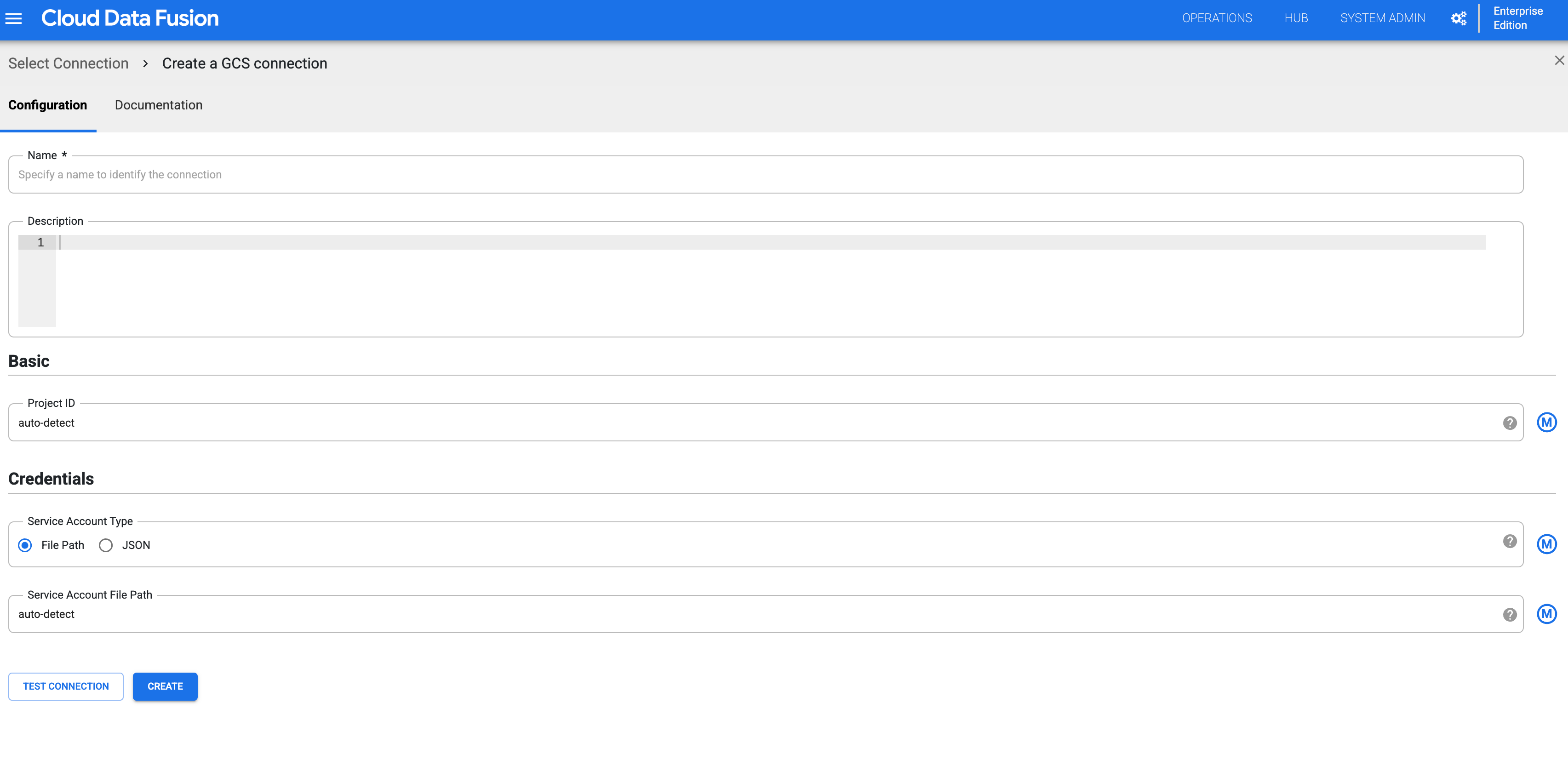
図 3: 名前空間の Cloud Storage 接続を構成します。 上記の手順を繰り返して、すべての名前空間に Cloud Storage 接続を作成します。各チームは、設計時のオペレーションのために、そのリソースの分離されたコピーを操作できます。
各名前空間の設計時の分離を検証する
チーム A は、それぞれの名前空間の Cloud Storage バケットにアクセスして、設計時の分離を検証できます。
Google Cloud コンソールで、Cloud Data Fusion の [インスタンス] ページに移動し、Cloud Data Fusion ウェブ インターフェースでインスタンスを開きます。
[システム管理者] > [設定] > [名前空間] をクリックします。
名前空間を選択します(チーム A の名前空間
team_Aなど)。[メニュー > Wrangler] をクリックします。
[GCS] をクリックします。
バケットリストで、
team_a1バケットをクリックします。チーム A の名前空間には
storage.buckets.list権限があるため、バケットのリストを表示できます。チーム A の名前空間には Storage オブジェクト閲覧者のロールがあるため、バケットをクリックするとバケットの内容を表示できます。
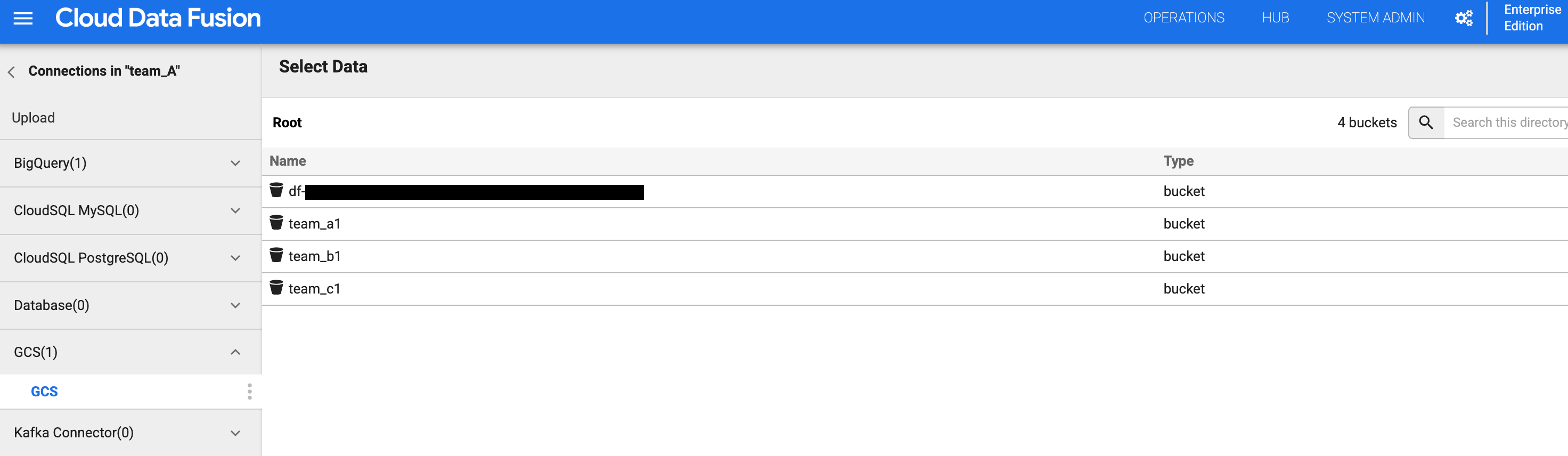
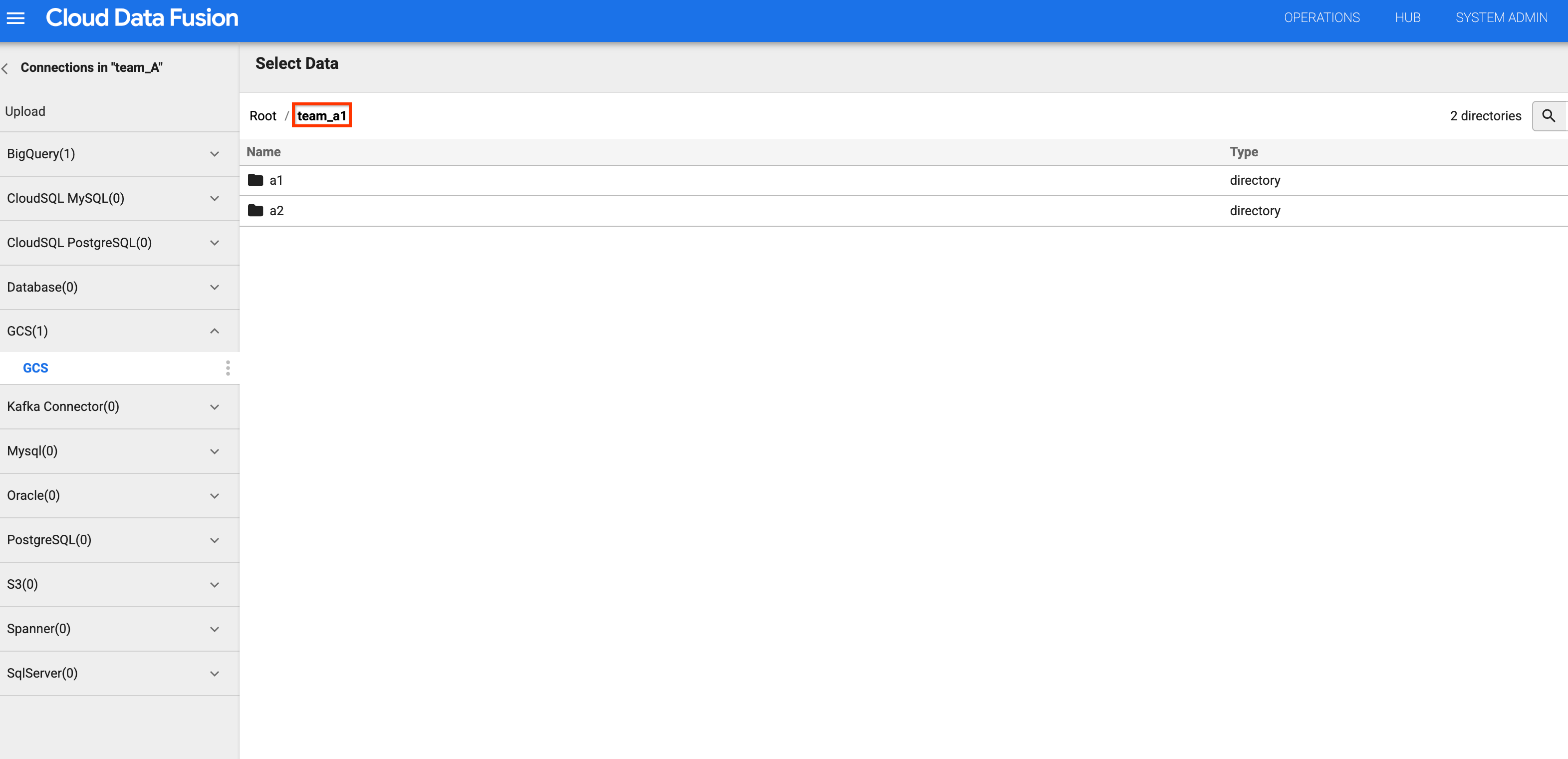
図 4 と 5: チーム A が適切なストレージ バケットにアクセスできることを確認します。 バケットリストに戻り、
team_b1バケットまたはteam_c1バケットをクリックします。 名前空間サービス アカウントを使用してチーム A 用の設計時リソースが分離されているため、アクセスは制限されます。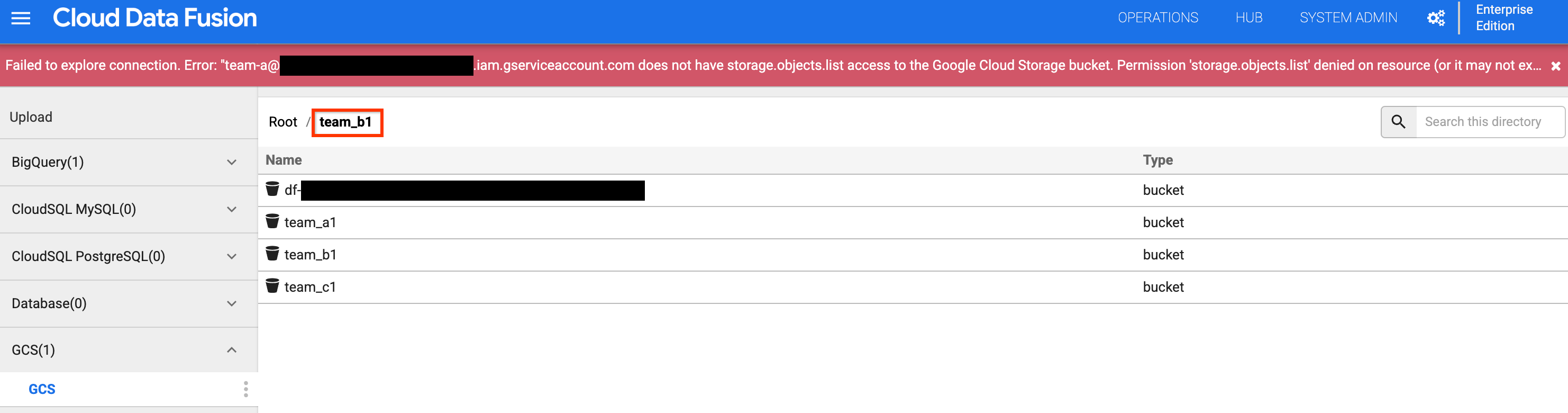
図 6: チーム A がチーム B とチーム C のストレージ バケットにアクセスできないことを確認します。
次のステップ
- Cloud Data Fusion のセキュリティ機能の詳細を確認する。