Cette page explique comment gérer le contrôle des accès lorsque vous déployez et exécutez un pipeline qui utilise des clusters Dataproc dans un autre Google Cloud projet.
Scénario
Par défaut, lorsqu'une instance Cloud Data Fusion est lancée dans un projetGoogle Cloud , elle déploie et exécute des pipelines à l'aide de clusters Dataproc dans le même projet. Toutefois, votre organisation peut vous demander d'utiliser des clusters dans un autre projet. Pour ce cas d'utilisation, vous devez gérer l'accès entre les projets. La page suivante explique comment modifier les configurations de référence (par défaut) et appliquer les contrôles d'accès appropriés.
Avant de commencer
Pour comprendre les solutions de ce cas d'utilisation, vous avez besoin du contexte suivant:
- Connaissances des concepts de base de Cloud Data Fusion
- Connaissances de base sur la gestion de l'authentification et des accès (IAM) pour Cloud Data Fusion
- Connaissances de base sur la mise en réseau Cloud Data Fusion
Hypothèses et champ d'application
Ce cas d'utilisation présente les exigences suivantes :
- Une instance Cloud Data Fusion privée. Pour des raisons de sécurité, une organisation peut vous demander d'utiliser ce type d'instance.
- Une source et un récepteur BigQuery.
- Contrôle des accès avec IAM, et non contrôle des accès basé sur les rôles (RBAC).
Solution
Cette solution compare l'architecture et la configuration de référence et spécifiques au cas d'utilisation.
Architecture
Les diagrammes suivants comparent l'architecture de projet pour créer une instance Cloud Data Fusion et exécuter des pipelines lorsque vous utilisez des clusters dans le même projet (référence) et dans un autre projet via le VPC du projet locataire.
Architecture de référence
Ce schéma présente l'architecture de référence des projets:
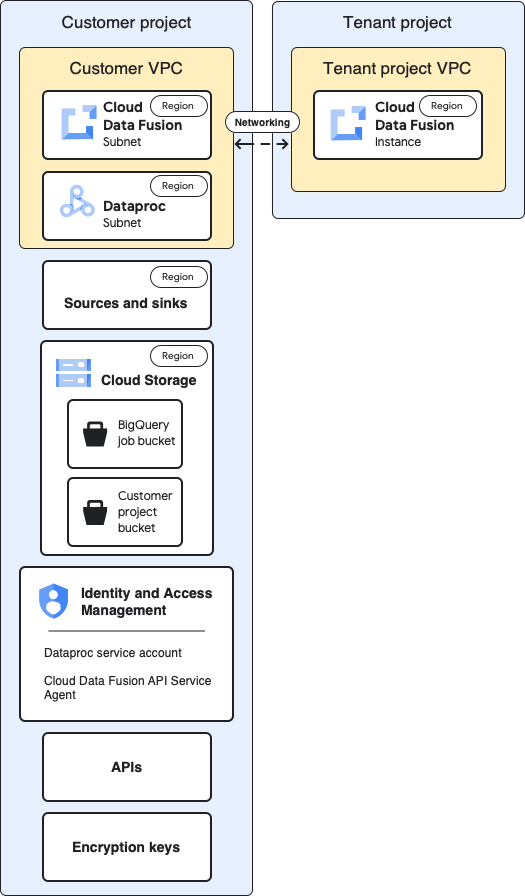
Pour la configuration de référence, vous créez une instance Cloud Data Fusion privée et exécutez un pipeline sans personnalisation supplémentaire:
- Vous utilisez l'un des profils de calcul intégrés
- La source et le récepteur se trouvent dans le même projet que l'instance.
- Aucun rôle supplémentaire n'a été attribué à aucun des comptes de service.
Pour en savoir plus sur les projets de locataires et de clients, consultez la section Mise en réseau.
Architecture de cas d'utilisation
Ce diagramme montre l'architecture du projet lorsque vous utilisez des clusters dans un autre projet:
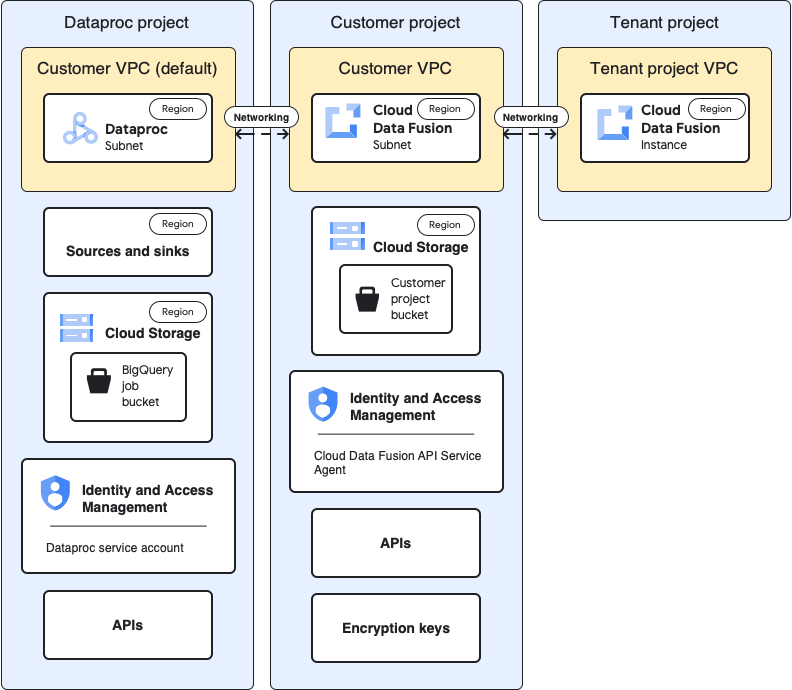
Configurations
Les sections suivantes comparent les configurations de référence aux configurations spécifiques au cas d'utilisation pour utiliser des clusters Dataproc dans un autre projet via le VPC par défaut du projet de locataire.
Dans les descriptions des cas d'utilisation suivantes, l'projet client est l'endroit où l'instance Cloud Data Fusion s'exécute, et le projet Dataproc est l'endroit où le cluster Dataproc est lancé.
VPC et instance du projet locataire
| Référence | Cas d'utilisation |
|---|---|
Dans le diagramme d'architecture de référence précédent, le projet de locataire contient les composants suivants :
|
Aucune configuration supplémentaire n'est requise pour ce cas d'utilisation. |
Projet client
| Référence | Cas d'utilisation |
|---|---|
| Votre projet Google Cloud est l'endroit où vous déployez et exécutez des pipelines. Par défaut, les clusters Dataproc sont lancés dans ce projet lorsque vous exécutez vos pipelines. | Dans ce cas d'utilisation, vous gérez deux projets. Sur cette page, le projet client fait référence à l'emplacement où s'exécute l'instance Cloud Data Fusion. Le projet Dataproc fait référence à l'emplacement de lancement des clusters Dataproc. |
VPC du client
| Référence | Cas d'utilisation |
|---|---|
Du point de vue du client, c'est le VPC du client où Cloud Data Fusion se trouve logiquement. En résumé :Vous trouverez les détails du VPC client sur la page "Réseaux VPC" de votre projet. |
Aucune configuration supplémentaire n'est requise pour ce cas d'utilisation. |
Sous-réseau Cloud Data Fusion
| Référence | Cas d'utilisation |
|---|---|
Du point de vue du client, c'est dans ce sous-réseau que Cloud Data Fusion se trouve. En résumé: La région de ce sous-réseau est la même que l'emplacement de l'instance Cloud Data Fusion dans le projet du locataire. |
Aucune configuration supplémentaire n'est requise pour ce cas d'utilisation. |
Sous-réseau Dataproc
| Référence | Cas d'utilisation |
|---|---|
Sous-réseau dans lequel les clusters Dataproc sont lancés lorsque vous exécutez un pipeline. Points à retenir:
|
Il s'agit d'un nouveau sous-réseau dans lequel les clusters Dataproc sont lancés lorsque vous exécutez un pipeline. Points à retenir:
|
Sources et récepteurs
| Référence | Cas d'utilisation |
|---|---|
Sources à partir desquelles les données sont extraites et récepteurs dans lesquels les données sont chargées, tels que les sources et les récepteurs BigQuery. Point clé à retenir:
|
Les configurations de contrôle des accès spécifiques au cas d'utilisation de cette page sont destinées aux sources et aux destinations BigQuery. |
Cloud Storage
| Référence | Cas d'utilisation |
|---|---|
Bucket de stockage du projet client qui permet de transférer des fichiers entre Cloud Data Fusion et Dataproc. Points à retenir:
|
Aucune configuration supplémentaire n'est requise pour ce cas d'utilisation. |
Buckets temporaires utilisés par la source et le récepteur
| Référence | Cas d'utilisation |
|---|---|
Les buckets temporaires créés par les plug-ins pour vos sources et récepteurs, tels que les tâches de chargement lancées par le plug-in BigQuery Sink. Points à retenir:
|
Pour ce cas d'utilisation, le bucket peut être créé dans n'importe quel projet. |
Buckets qui sont des sources ou des récepteurs de données pour les plug-ins
| Référence | Cas d'utilisation |
|---|---|
| Les buckets client, que vous spécifiez dans les configurations des plug-ins, tels que le plug-in Cloud Storage et le plug-in FTP vers Cloud Storage. | Aucune configuration supplémentaire n'est requise pour ce cas d'utilisation. |
IAM: agent de service de l'API Cloud Data Fusion
| Référence | Cas d'utilisation |
|---|---|
Lorsque l'API Cloud Data Fusion est activée, le rôle Agent de service de l'API Cloud Data Fusion ( Points à retenir:
|
Pour ce cas d'utilisation, attribuez le rôle Agent de service de l'API Cloud Data Fusion au compte de service du projet Dataproc. Attribuez ensuite les rôles suivants dans ce projet:
|
IAM: compte de service Dataproc
| Référence | Cas d'utilisation |
|---|---|
Compte de service utilisé pour exécuter le pipeline en tant que tâche dans le cluster Dataproc. Par défaut, il s'agit du compte de service Compute Engine. Facultatif: dans la configuration de référence, vous pouvez remplacer le compte de service par défaut par un autre compte de service du même projet. Attribuez les rôles IAM suivants au nouveau compte de service:
|
Cet exemple de cas d'utilisation suppose que vous utilisez le compte de service Compute Engine par défaut ( Attribuez les rôles suivants au compte de service Compute Engine par défaut du projet Dataproc.
Attribuez le rôle "Utilisateur du compte de service" au compte de service Cloud Data Fusion sur le compte de service Compute Engine par défaut du projet Dataproc. Cette action doit être effectuée dans le projet Dataproc. Ajoutez le compte de service Compute Engine par défaut du projet Dataproc au projet Cloud Data Fusion. Attribuez également les rôles suivants:
|
API
| Référence | Cas d'utilisation |
|---|---|
Lorsque vous activez l'API Cloud Data Fusion, les API suivantes sont également activées. Pour en savoir plus sur ces API, accédez à la page "API et services" de votre projet.
Lorsque vous activez l'API Cloud Data Fusion, les comptes de service suivants sont automatiquement ajoutés à votre projet:
|
Pour ce cas d'utilisation, activez les API suivantes dans le projet contenant le projet Dataproc:
|
Clés de chiffrement
| Référence | Cas d'utilisation |
|---|---|
Dans la configuration de référence, les clés de chiffrement peuvent être gérées par Google ou CMEK . Points à retenir: Si vous utilisez CMEK, votre configuration de référence nécessite les éléments suivants:
Selon les services utilisés dans votre pipeline, tels que BigQuery ou Cloud Storage, les comptes de service doivent également se voir attribuer le rôle Chiffreur/Déchiffreur de CryptoKey Cloud KMS:
|
Si vous n'utilisez pas de CMEK, aucune modification supplémentaire n'est requise pour ce cas d'utilisation. Si vous utilisez le chiffrement CMEK, le rôle "Chiffreur/Déchiffreur de CryptoKey Cloud KMS" doit être fourni au compte de service suivant au niveau de la clé dans le projet où il est créé:
En fonction des services utilisés dans votre pipeline, tels que BigQuery ou Cloud Storage, d'autres comptes de service doivent également se voir attribuer le rôle Chiffreur/Déchiffreur de CryptoKey Cloud KMS au niveau de la clé. Exemple :
|
Une fois ces configurations spécifiques au cas d'utilisation effectuées, votre pipeline de données peut commencer à s'exécuter sur des clusters d'un autre projet.
Étape suivante
- En savoir plus sur la mise en réseau dans Cloud Data Fusion
- Consultez la documentation de référence sur les rôles IAM de base et prédéfinis.