Traçabilité des données Cloud Data Fusion
Vous pouvez utiliser la traçabilité des données Cloud Data Fusion pour effectuer les opérations suivantes :
Détecter l'origine des événements de données erronées.
Effectuez une analyse d'impact avant de modifier les données.
Nous vous recommandons d'utiliser l'intégration de la traçabilité des ressources dans Dataplex Universal Catalog. Pour en savoir plus, consultez Afficher la traçabilité dans Dataplex Universal Catalog.
Vous pouvez également afficher la traçabilité au niveau de l'ensemble de données et du champ dans Cloud Data Fusion Studio à l'aide de l'option Métadonnées, qui affiche la traçabilité pour une plage de temps sélectionnée.
La traçabilité au niveau des ensembles de données indique la relation entre les ensembles de données et les pipelines.
La traçabilité au niveau des champs affiche les opérations effectuées sur un ensemble de champs présents dans l'ensemble de données source pour produire un autre ensemble de champs dans l'ensemble de données cible.
À partir de Cloud Data Fusion 6.9.2.4, si vous ne suivez pas la traçabilité dans Cloud Data Fusion, nous vous recommandons de désactiver l'émission de la traçabilité au niveau des champs dans votre instance à l'aide de la méthode patch :
curl -X PATCH -H 'Content-Type: application/json' -H "Authorization: Bearer
$(gcloud auth print-access-token)"
'https://datafusion.googleapis.com/v1beta1/projects/PROJECT_ID/locations/REGION/instances/INSTANCE_ID?updateMask=options'
-d '{ "options": { "metadata.messaging.field.lineage.emission.enabled": "false" } }'
Remplacez les éléments suivants :
PROJECT_ID: ID du projet Google CloudREGION: emplacement du projet Google CloudINSTANCE_ID: ID de l'instance Cloud Data Fusion
Scénario du tutoriel
Dans ce tutoriel, vous travaillez avec deux pipelines :
Le pipeline
Shipment Data Cleansinglit les données d'expédition brutes d'un petit ensemble de données et applique des transformations pour nettoyer les données.Le pipeline
Delayed Shipments USAlit ensuite les données d'expédition nettoyées, les analyse et trouve les expéditions aux États-Unis retardées de plus d'un seuil.
Ces pipelines de tutoriel illustrent un scénario type dans lequel les données brutes sont nettoyées, puis envoyées pour traitement en aval. Entre les données brutes, les données d'expédition nettoyées et les données analytiques, ce parcours des données peut être exploré à l'aide de la fonctionnalité de traçabilité Cloud Data Fusion.
Objectifs
- Produire une traçabilité en exécutant des exemples de pipelines
- Explorer la traçabilité au niveau des ensembles de données et des champs
- Apprendre à transmettre des informations de handshake du pipeline en amont au pipeline en aval.
Coûts
Dans ce document, vous utilisez les composants facturables de Google Cloudsuivants :
- Cloud Data Fusion
- Cloud Storage
- BigQuery
Vous pouvez obtenir une estimation des coûts en fonction de votre utilisation prévue à l'aide du simulateur de coût.
Avant de commencer
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Cloud Data Fusion, Cloud Storage, Dataproc, and BigQuery APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. - Créez une instance Cloud Data Fusion.
- Cliquez sur les liens suivants pour télécharger ces petits exemples d'ensembles de données sur votre ordinateur local :
Ouvrir l'interface utilisateur de Cloud Data Fusion
Lorsque vous utilisez Cloud Data Fusion, vous utilisez à la fois la console Google Cloud et l'interface utilisateur distincte Cloud Data Fusion. Dans la console Google Cloud , vous pouvez créer un projet de console Google Cloud , et créer et supprimer des instances Cloud Data Fusion. Dans l'UI de Cloud Data Fusion, vous pouvez accéder aux fonctionnalités de Cloud Data Fusion à l'aide des différentes pages, telles que la page Traçabilité.
Dans la console Google Cloud , ouvrez la page Instances.
Dans la colonne Actions de l'instance, cliquez sur le lien "Afficher l'instance". L'interface utilisateur de Cloud Data Fusion s'ouvre dans un nouvel onglet du navigateur.
Dans le volet Intégrer, cliquez sur Studio pour ouvrir la page Studio de Cloud Data Fusion.
Déployer et exécuter des pipelines
Importez les Données d'expédition brutes. Sur la page Studio, cliquez sur Importer ou sur + > Pipeline > Importer, puis sélectionnez et importez le pipeline de nettoyage des données d'expédition que vous avez téléchargé dans Avant de commencer.
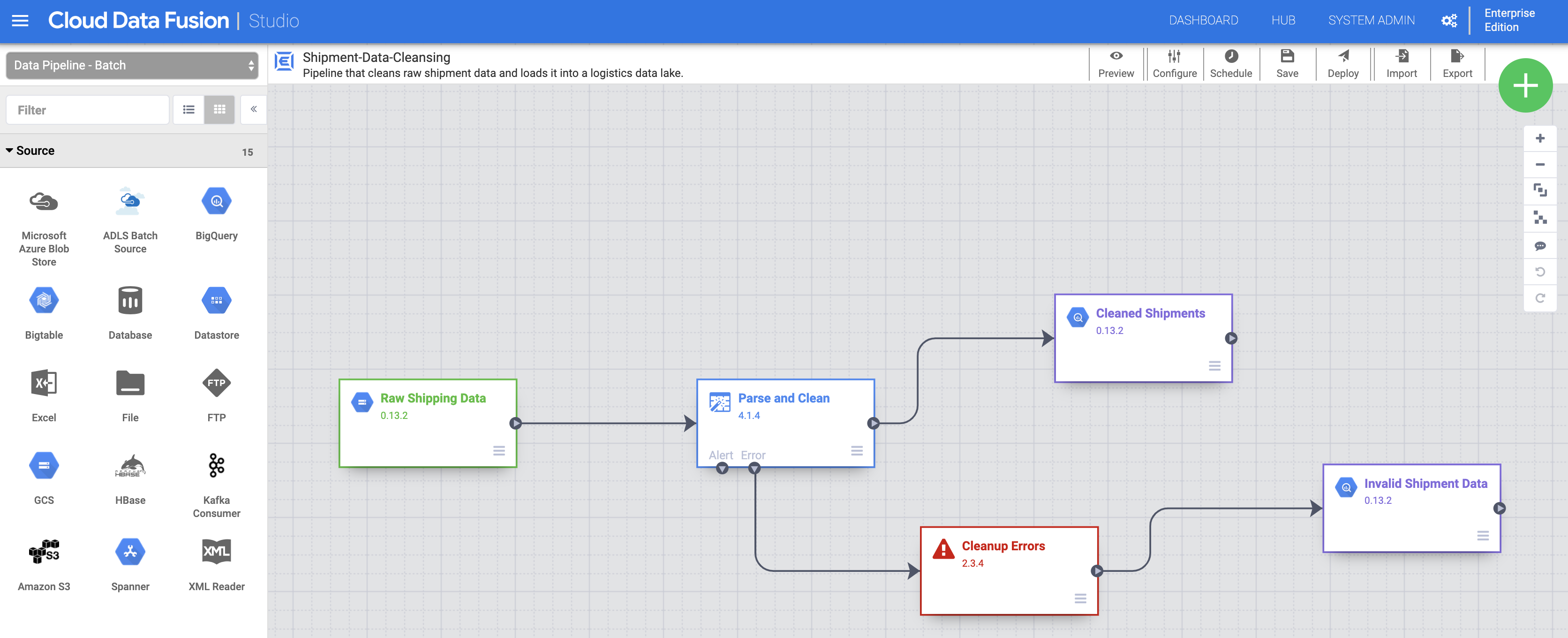
Déployez le pipeline. Cliquez sur "Déployer" en haut à droite de la page Studio. Après le déploiement, la page Pipeline s'ouvre.
Exécutez le pipeline. Cliquez sur "Exécuter" situé en haut au centre de la page Pipeline.
Importez, déployez et exécutez les données et le pipeline des expéditions retardées. Une fois que l'état du nettoyage des données d'expédition indique Réussi, appliquez les étapes précédentes aux données relatives aux expéditions retardées aux États-Unis que vous avez téléchargées à la section Avant de commencer. Revenez à la page Studio pour importer les données, puis déployez et exécutez ce deuxième pipeline à partir de la page Pipeline. Une fois le deuxième pipeline terminé, passez aux étapes restantes.
Découvrir des ensembles de données
Vous devez découvrir un ensemble de données avant d'explorer sa traçabilité. Dans le panneau de navigation situé à gauche de l'interface utilisateur de Cloud Data Fusion, sélectionnez Métadonnées pour ouvrir la page de Recherche des métadonnées. Étant donné que l'ensemble de données de nettoyage des données d'expédition spécifiait Expéditions-Nettoyées comme ensemble de données de référence, insérez expédition dans le champ de recherche. Les résultats de recherche incluent cet ensemble de données.
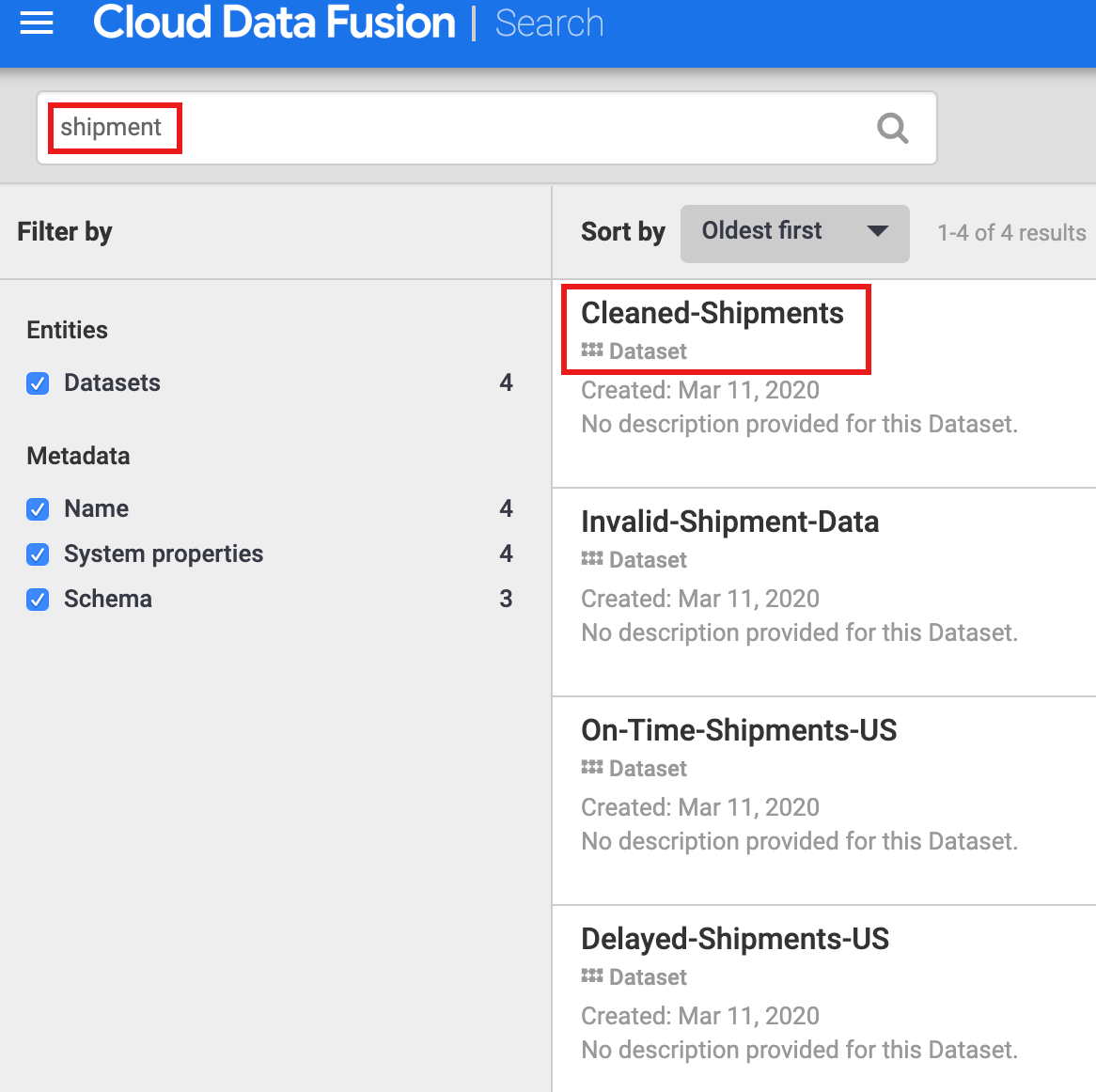
Utiliser des tags pour découvrir des ensembles de données
Une recherche de métadonnées découvre des ensembles de données qui ont été utilisés, traités ou générés par des pipelines Cloud Data Fusion. Les pipelines s'exécutent sur un framework structuré qui génère et collecte des métadonnées techniques et opérationnelles. Les métadonnées techniques incluent le nom, le type, le schéma, les champs, l'heure de création et les informations de traitement de l'ensemble de données. Ces informations techniques sont utilisées par les fonctionnalités de recherche et de traçabilité des métadonnées Cloud Data Fusion.
Cloud Data Fusion accepte également l'annotation d'ensembles de données avec des métadonnées d'entreprise, telles que des balises et des propriétés clé-valeur, qui peuvent être utilisées comme critères de recherche. Par exemple, pour ajouter et rechercher une annotation de tag d'entreprise sur l'ensemble de données des données d'expédition brutes :
Cliquez sur le bouton Propriétés du nœud des données d'expédition brutes sur la page Pipeline de nettoyage des données d'expédition pour ouvrir la page Propriétés Cloud Storage.
Cliquez sur Afficher les métadonnées pour ouvrir la page Recherche.
Sous Tags d'entreprise, cliquez sur +, puis insérez un nom de tag (les caractères alphanumériques et de soulignement sont autorisés) et appuyez sur Entrée.

Explorer la traçabilité
Traçabilité au niveau de l'ensemble de données
Cliquez sur le nom de l'ensemble de données "Expéditions-Nettoyées" répertorié sur la page de recherche (dans la section Découvrir les ensembles de données), puis sur l'onglet "Traçabilité". Le graphique de traçabilité indique que cet ensemble de données a été généré par le pipeline "Nettoyage-Données-Expédition", qui avait consommé l'ensemble de données "Données-Expédition-Brutes".
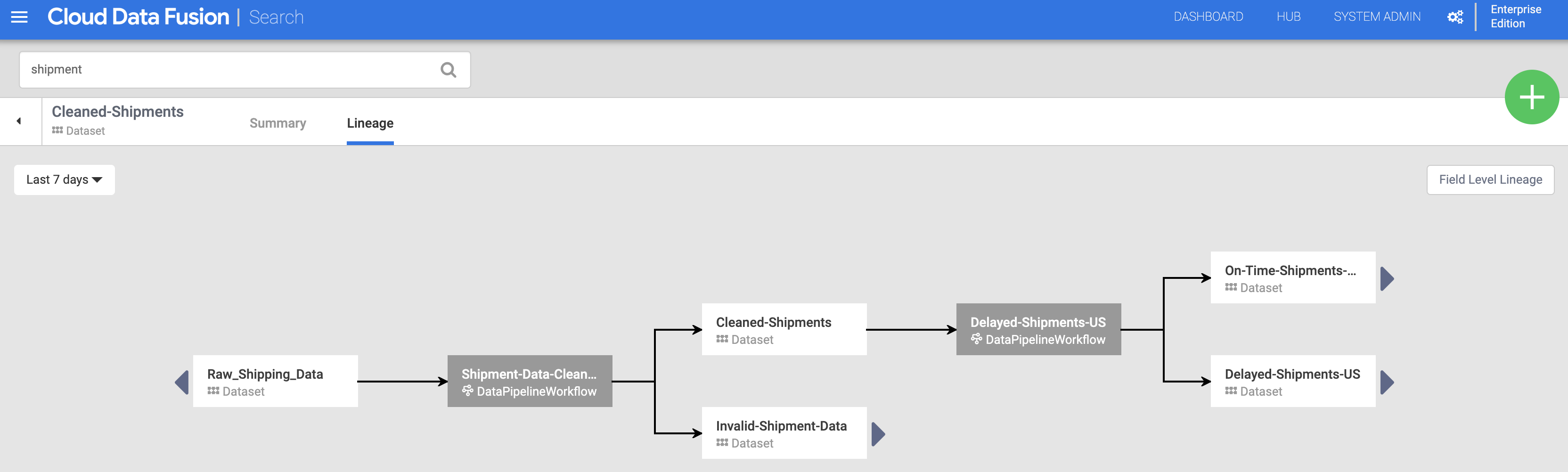
Les flèches de gauche et de droite vous permettent de passer d'une traçabilité d'un ensemble de données à l'autre, qu'elle soit antérieure ou postérieure. Dans cet exemple, le graphique affiche la traçabilité complète de l'ensemble de données "Expéditions-nettoyées".
Traçabilité au niveau des champs
La traçabilité au niveau des champs de Cloud Data Fusion montre la relation entre les champs d'un ensemble de données et les transformations effectuées sur un ensemble de champs pour produire un autre ensemble de champs. Comme pour la traçabilité au niveau des ensembles de données, la traçabilité au niveau des champs est référencée dans le temps et ses résultats évoluent avec le temps.
En reprenant depuis l'étape Traçabilité au niveau des ensembles de données, cliquez sur le bouton "Traçabilité au niveau des champs" situé en haut à droite du graphique de traçabilité au niveau de l'ensemble de données "Expéditions nettoyées" pour afficher le graphique de traçabilité au niveau du champ.
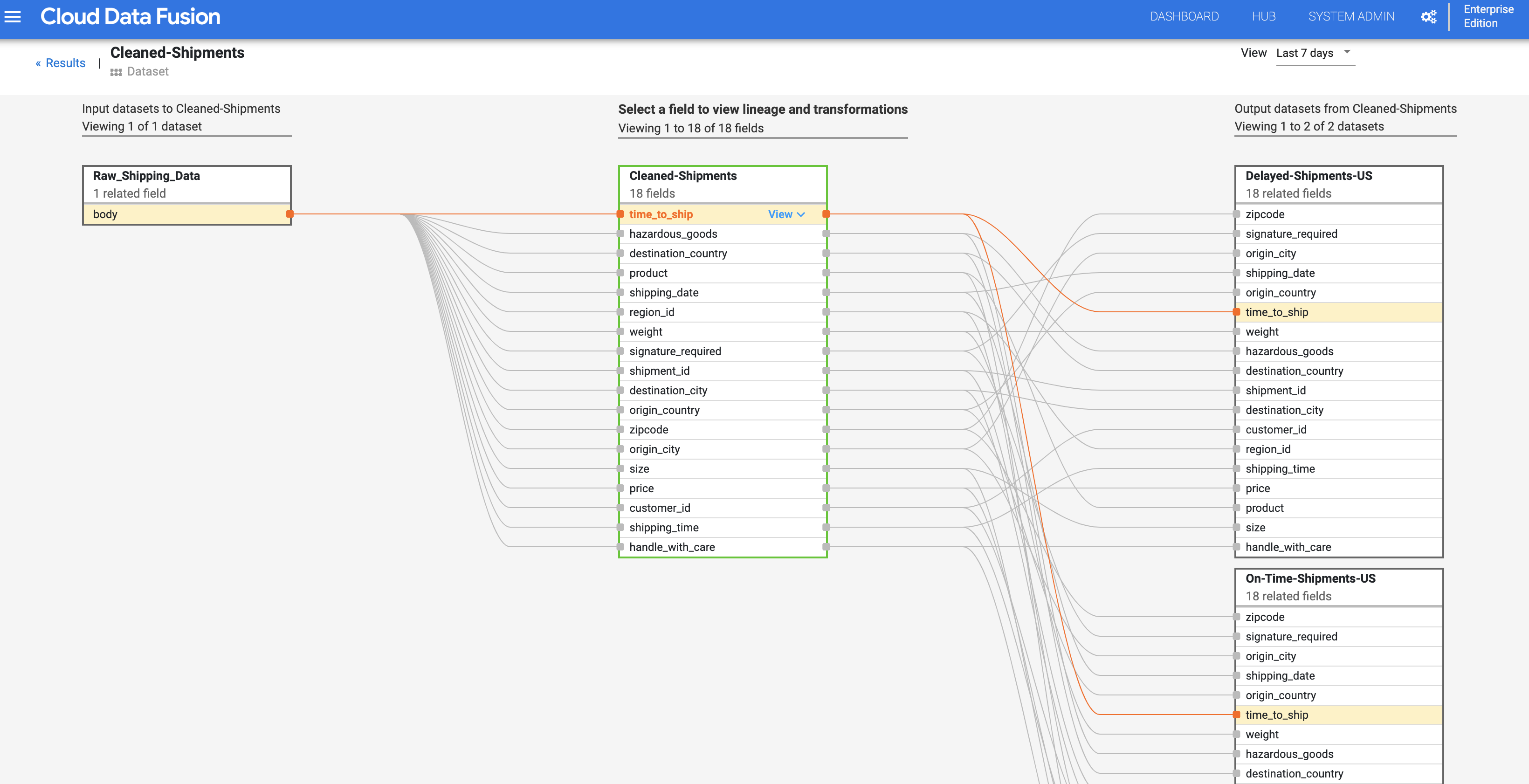
Le graphique de traçabilité au niveau du champ affiche les connexions entre les champs. Vous pouvez sélectionner un champ pour afficher sa traçabilité. Sélectionnez Afficher > Épingler le champ pour afficher uniquement la traçabilité de ce champ.
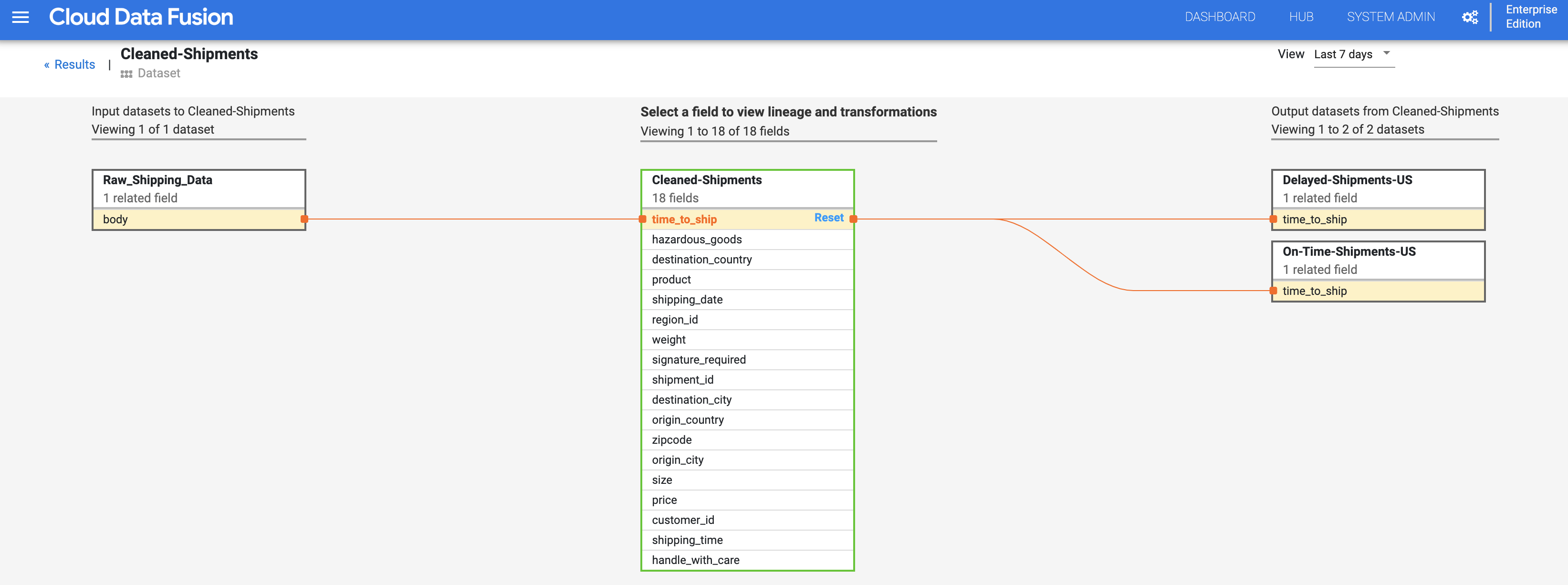
Sélectionnez Afficher > Voir l'impact pour effectuer une analyse d'impact.
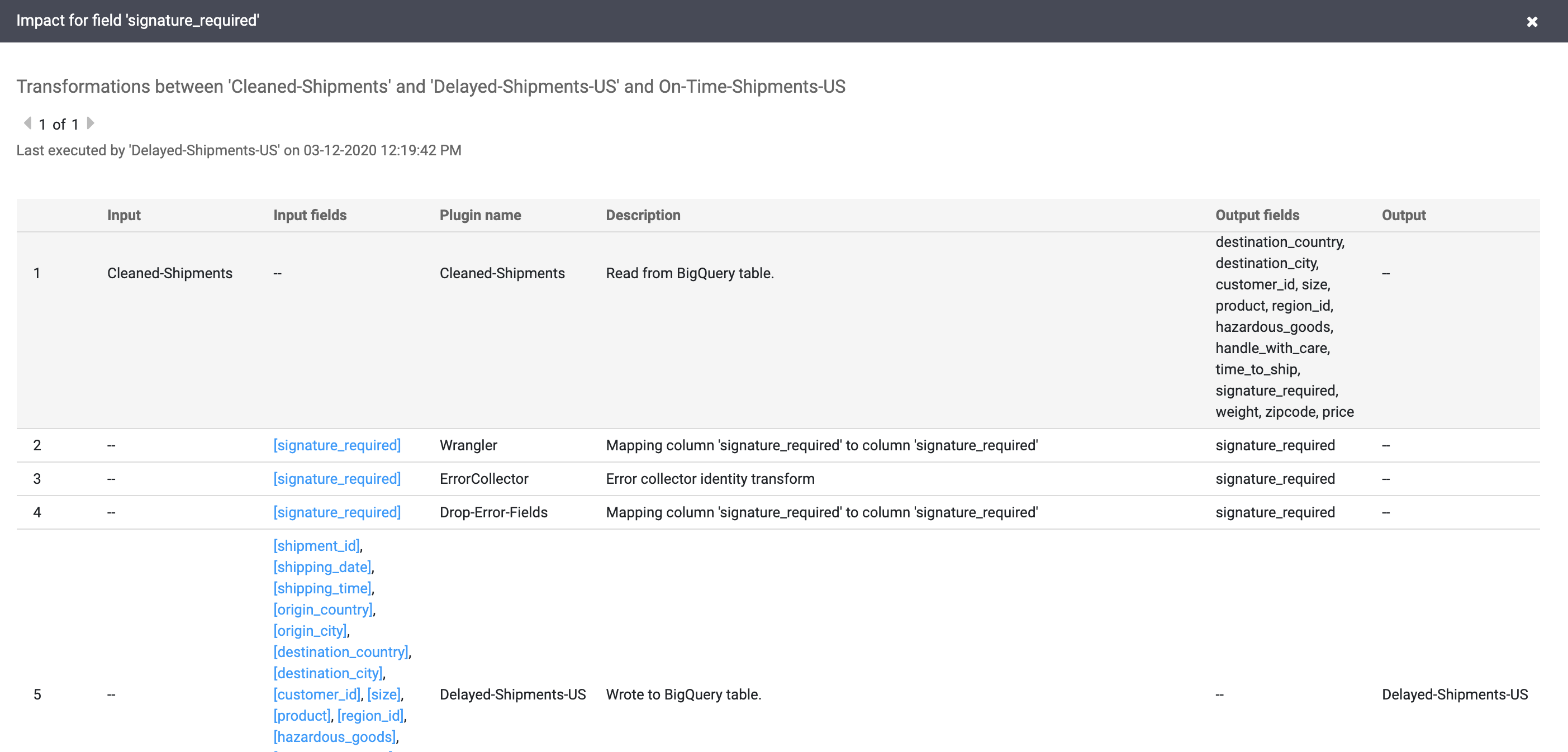
Les liens de cause et d'impact indiquent les transformations effectuées des deux côtés d'un champ dans un format lisible. Ces informations peuvent être essentielles pour la création de rapports et la gouvernance.
Effectuer un nettoyage
Pour éviter que les ressources utilisées lors de ce tutoriel soient facturées sur votre compte Google Cloud, supprimez le projet contenant les ressources, ou conservez le projet et supprimez les ressources individuelles.
Une fois le tutoriel terminé, nettoyez les ressources que vous avez créées surGoogle Cloud afin qu'elles ne soient plus comptabilisées dans votre quota et qu'elles ne vous soient plus facturées. Dans les sections suivantes, nous allons voir comment supprimer ou désactiver ces ressources.
Supprimer l'ensemble de données du tutoriel
Ce tutoriel crée un ensemble de données logistics_demo avec plusieurs tables dans votre projet.
Vous pouvez supprimer l'ensemble de données depuis l'interface utilisateur Web de BigQuery dans la console Google Cloud .
Supprimer l'instance Cloud Data Fusion
Suivez les instructions pour supprimer votre instance Cloud Data Fusion.
Supprimer le projet
Le moyen le plus simple d'empêcher la facturation est de supprimer le projet que vous avez créé pour ce tutoriel.
Pour supprimer le projet :
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
Étapes suivantes
- Consultez les guides d'utilisation
- Suivez un autre tutoriel