Para reduzir o tempo de início dos pipelines, as instâncias do Cloud Data Fusion versão 6.8.0 e 6.8.1 armazenam em cache os artefactos necessários para iniciar um pipeline num cluster do Dataproc num contentor do Cloud Storage.
Um destes artefactos em cache é application.jar. Consoante a ordem em que executa os pipelines, alguns pipelines podem falhar com o seguinte erro:
Unsupported program type: Spark
Por exemplo, depois de criar uma nova instância 6.8.1 (ou atualizar para a versão 6.8.1), a primeira vez que executar um pipeline que contenha apenas ações, a execução é bem-sucedida. No entanto, as execuções de pipeline seguintes, que incluem origens ou destinos, podem falhar com este erro.
Recomendação
Para resolver este problema, faça uma das seguintes ações:
- Recomendado: atualize a instância para a versão 6.8.2 ou posterior do Cloud Data Fusion.
- Desative o armazenamento em cache do Cloud Storage através de uma preferência ou de um argumento de tempo de execução.
Pode desativar o armazenamento em cache para qualquer um dos seguintes elementos:
- Para todos os pipelines numa instância.
- Para um determinado espaço de nomes.
- Para os perfis do Dataproc específicos que contêm os pipelines com falhas.
- Apenas para os pipelines com falhas.
Desative o armazenamento em cache do Cloud Storage para todos os pipelines numa instância
Para desativar o armazenamento em cache do Cloud Storage para todos os pipelines numa instância, siga estes passos:
Consola
- Aceda à sua instância:
Na Google Cloud consola, aceda à página do Cloud Data Fusion.
Para abrir a instância no Cloud Data Fusion Studio, clique em Instâncias e, de seguida, em Ver instância.
Clique em Administrador do sistema > Preferências do sistema e defina o valor de
system.profile.properties.gcsCacheEnabledcomofalse.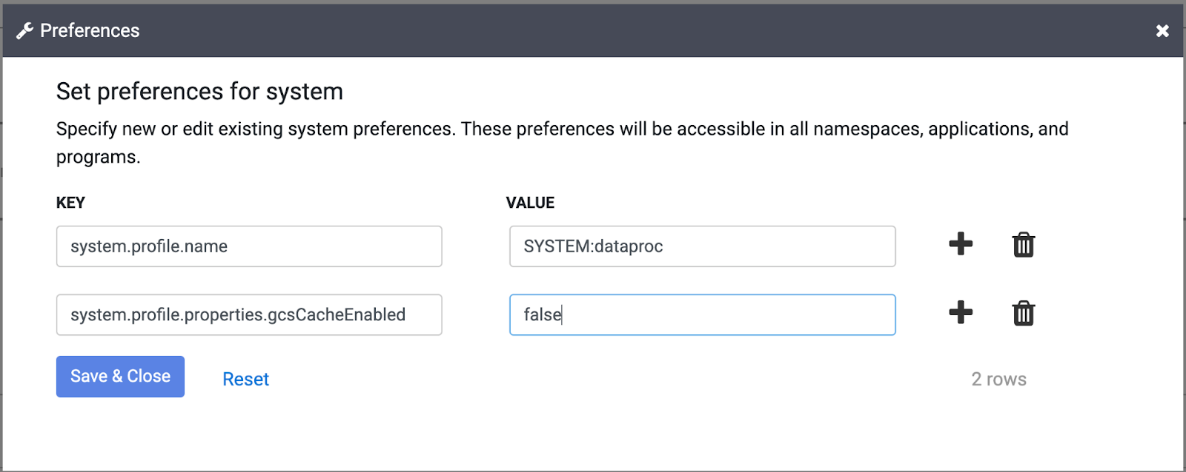
API REST
Para definir system.profile.properties.gcsCacheEnabled como false, consulte o artigo
Definir preferências.
Desative o armazenamento em cache do Cloud Storage para um determinado namespace
Para desativar o armazenamento em cache do Cloud Storage para um determinado espaço de nomes, siga estes passos:
Consola
- Aceda à sua instância:
Na Google Cloud consola, aceda à página do Cloud Data Fusion.
Para abrir a instância no Cloud Data Fusion Studio, clique em Instâncias e, de seguida, em Ver instância.
- Clique em Administrador do sistema > Espaços de nomes e selecione o seu espaço de nomes.
Clique em Preferências > Editar e defina o valor de
system.profile.properties.gcsCacheEnabledcomofalse.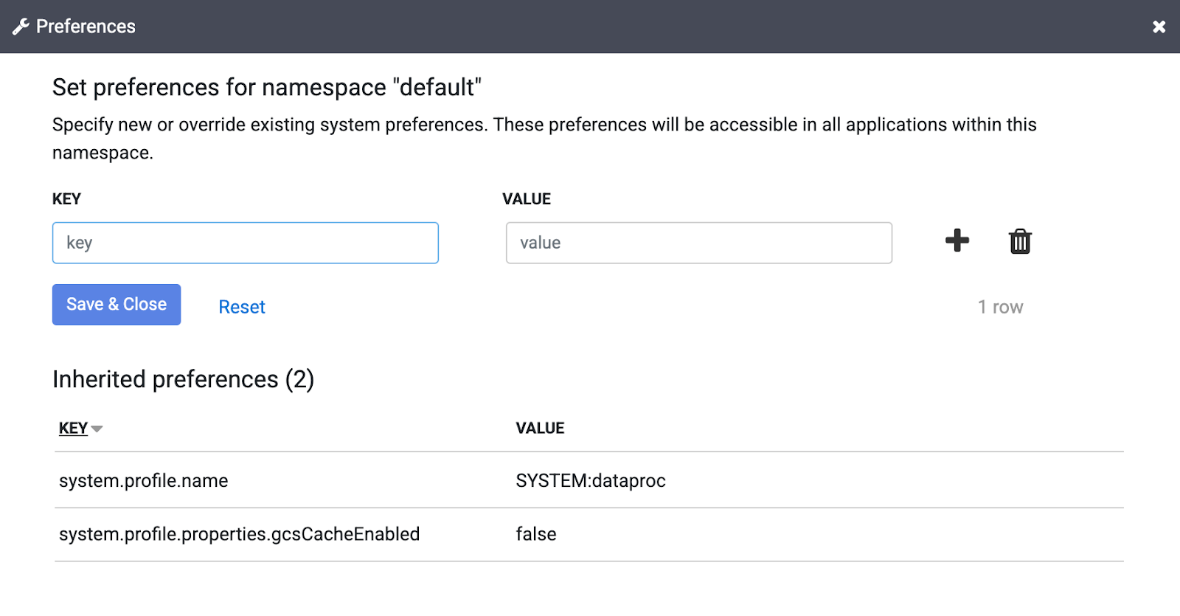
API REST
Para definir esta opção através da API REST, consulte o artigo Definir preferências.
Desative o armazenamento em cache do Cloud Storage para um perfil do Dataproc
Para desativar o armazenamento em cache do Cloud Storage para os perfis do Dataproc específicos que contêm os pipelines com falhas, siga estes passos:
Consola
- Defina
gcsCacheEnabledcomofalseno perfil do Dataproc.
Desative a colocação em cache do Cloud Storage apenas para os pipelines com falhas
Para desativar o armazenamento em cache do Cloud Storage apenas para os pipelines com falhas, siga estes passos:
Consola
- Aceda à sua instância:
Na Google Cloud consola, aceda à página do Cloud Data Fusion.
Para abrir a instância no Cloud Data Fusion Studio, clique em Instâncias e, de seguida, em Ver instância.
- Clique em Lista e selecione o pipeline com falhas.
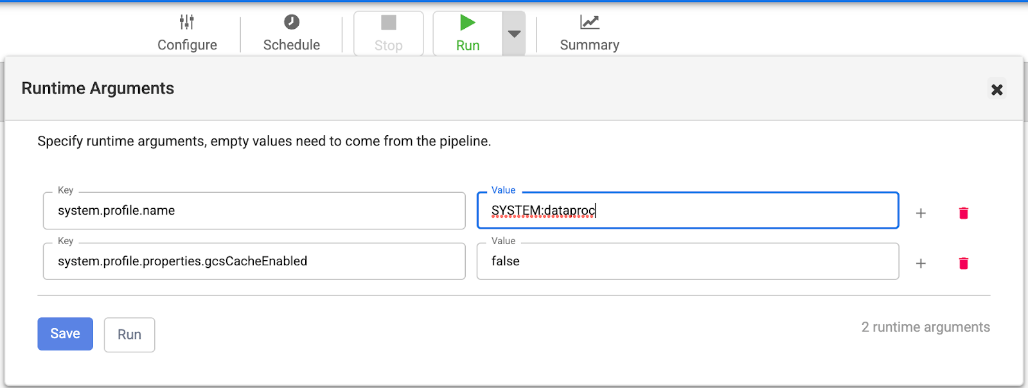
- Clique em
Expandir junto a Executar e defina o argumento de tempo de execução
system.profile.properties.gcsCacheEnabledcomofalse. - Repita o processo para quaisquer outros pipelines com falhas.
API REST
É possível desativar o armazenamento em cache do Cloud Storage quando inicia um pipeline através da API REST e também especificando opcionalmente argumentos de tempo de execução como um mapa JSON no corpo do pedido. Para mais informações, consulte o artigo Inicie um programa.