本页介绍了如何使用 SAP Landscape Transformation (SLT) 将数据从 SAP 应用实时复制到 Google Cloud 。本文内容适用于 Cloud Data Fusion Hub 中提供的 SAP SLT Replication 和 SAP SLT No RFC Replication 插件。其中介绍了 SAP Source System、SLT、Cloud Storage 和 Cloud Data Fusion 的配置,以便执行以下操作:
- 使用 SAP SLT 将 SAP 元数据和表数据推送到 Google Cloud 。
- 创建一个 Cloud Data Fusion 复制作业,用于从 Cloud Storage 存储分区读取数据。
借助 SAP SLT Replication,您可以持续实时地将数据从 SAP 来源复制到 BigQuery。您无需编写任何代码,即可配置和执行从 SAP 系统开始的数据传输。
Cloud Data Fusion SLT 复制过程如下所示:
- 数据来自 SAP 源系统。
- SLT 跟踪和读取数据并将其推送到 Cloud Storage。
- Cloud Data Fusion 从存储桶拉取数据并将其写入 BigQuery。
您可以从受支持的 SAP 系统(包括 Google Cloud中托管的 SAP 系统)传输数据。
如需了解详情,请参阅 Google Cloud 上的 SAP 概览 Google Cloud 和支持详情。
准备工作
要使用此插件,您需要具备以下方面的领域知识:
- 在 Cloud Data Fusion 中构建流水线
- 使用 IAM 管理访问权限
- 配置 SAP Cloud 和本地企业资源规划 (ERP) 系统
执行配置的管理员和用户
此页面上的任务由在 Google Cloud 或其 SAP 系统中具有以下角色的人员执行:
| 用户类型 | 说明 |
|---|---|
| Google Cloud Admin | 分配有此角色的用户是 Google Cloud 账号的管理员。 |
| Cloud Data Fusion 用户 | 分配有此角色的用户有权设计和运行数据流水线。这些角色至少被授予了 Data Fusion Viewer (roles/datafusion.viewer) 角色。如果您使用的是基于角色的访问权限控制,则可能需要其他角色。 |
| SAP 管理员 | 分配有此角色的用户是 SAP 系统的管理员。他们可以从 SAP 服务网站下载软件。它不是 IAM 角色。 |
| SAP 用户 | 分配有此角色的用户有权连接到 SAP 系统。它不是 IAM 角色。 |
支持的复制操作
SAP SLT Replication 插件支持以下操作:
数据建模:此插件支持所有数据建模操作(记录 insert、delete 和 update)。
数据定义:如 SAP 说明 2055599(需要 SAP 支持登录才能查看)中所述,存在对 SLT 自动复制的源系统表结构更改的限制。插件不支持某些数据定义操作(您需要手动传播这些操作)。
- 支持:
- 添加非键字段(在 SE11 中进行更改后,使用 SE14 激活表)
- 不支持:
- 添加/删除键字段
- 删除非键字段
- 修改数据类型
SAP 要求
您的 SAP 系统中需要有以下项目:
- 您在源 SAP 系统(嵌入式)上或作为专用 SLT 中心系统安装了 SLT Server 2011 SP17 或更高版本。
- 您的源 SAP 系统为 SAP ECC 或 SAP S/4HANA,它支持 DMIS 2011 SP17 或更高版本,例如 DMIS 2018、DMIS 2020。
- 您的 SAP 界面插件必须与您的 SAP NetWeaver 版本兼容。
您的支持包支持
/UI2/CL_JSON类PL 12或更高版本。否则,请根据您的界面插件版本实现适用于/UI2/CL_JSON类corrections的最新 SAP 备注,例如适用于PL12的 SAP 备注 2798102。实施了下列安全措施:
Cloud Data Fusion 要求
- 您需要 Cloud Data Fusion 实例 6.4.0 版或更高版本(任何版本均可)。
- 分配给 Cloud Data Fusion 实例的服务账号具有所需的角色(请参阅向服务账号授予用户权限)。
- 对于专用 Cloud Data Fusion 实例,需要有 VPC 对等互连。
Google Cloud 要求
- 在您的 Google Cloud 项目中启用 Cloud Storage API。
- Cloud Data Fusion 用户必须获得在 Cloud Storage 存储分区中创建文件夹的权限(请参阅 Cloud Storage 的 IAM 角色)。
- 可选:根据贵组织的要求,设置保留政策。
创建存储桶
在创建 SLT 复制作业之前,请创建 Cloud Storage 存储分区。该作业会将数据传输到存储分区,并每 5 分钟刷新一次暂存存储分区。运行该作业时,Cloud Data Fusion 会读取存储分区中的数据并将其写入 BigQuery。
如果已在 Google Cloud上安装 SLT
SLT 服务器必须有权在您创建的存储分区中创建和修改 Cloud Storage 对象。
至少向服务账号授予以下角色:
- Service Account Token Creator (
roles/iam.serviceAccountTokenCreator) - Service Usage Consumer (
roles/serviceusage.serviceUsageConsumer) - Storage Object Admin (
roles/storage.objectAdmin)
如果未在 Google Cloud上安装 SLT
在 SAP VM 和Google Cloud 之间安装 Cloud VPN 或 Cloud Interconnect,以允许连接到内部元数据端点(请参阅为本地主机配置专用 Google 访问通道)。
如果无法映射内部元数据:
根据运行 SLT 的基础架构的操作系统安装 Google Cloud CLI。
在启用了 Cloud Storage 的 Google Cloud 项目中创建服务账号。
在 SLT 操作系统上,使用服务账号授予对 Google Cloud 的访问权限。
为服务账号创建 API 密钥,并授权 Cloud Storage 相关范围。
使用 CLI 将 API 密钥导入之前安装的 gcloud CLI 中。
如需启用用于输出访问令牌的 gcloud CLI 命令,请在 SLT 系统中的事务 SM69 工具中配置 SAP 操作系统命令。
输出访问令牌
SAP 管理员配置操作系统命令 SM69,以从 Google Cloud检索访问令牌。
创建一个脚本来输出访问令牌,并配置 SAP 操作系统命令,从而以 <sid>adm 用户身份从 SAP LT Replication Server 主机调用该脚本。
Linux
如需创建操作系统命令,请执行以下操作:
在 SAP LT Replication Server 主机上,在
<sid>adm可访问的目录中,创建一个包含以下行的 bash 脚本:PATH_TO_GCLOUD_CLI/bin/gcloud auth print-access-token SERVICE_ACCOUNT_NAME使用 SAP 界面创建一条外部操作系统命令:
- 输入
SM69事务。 - 点击创建。
- 在外部命令面板的命令部分中,输入命令的名称,例如
ZGOOGLE_CDF_TOKEN。 在定义部分中:
- 在 Operating System Command 字段中,输入
sh作为脚本文件的扩展名。 在操作系统命令的参数字段中,输入以下内容:
/PATH_TO_SCRIPT/FILE_NAME.sh
- 在 Operating System Command 字段中,输入
点击保存。
如需测试脚本,请点击执行。
再次点击执行。
系统会返回一个 Google Cloud 令牌,并将其显示在 SAP 界面面板的底部。
- 输入
Windows
使用 SAP 界面创建一条外部操作系统命令:
- 输入
SM69事务。 - 点击创建。
- 在外部命令面板的命令部分中,输入命令的名称,例如
ZGOOGLE_CDF_TOKEN。 在定义部分中:
- 在操作系统命令字段中输入
cmd /c。 在操作系统命令的参数字段中,输入以下内容:
gcloud auth print-access-token SERVICE_ACCOUNT_NAME
- 在操作系统命令字段中输入
点击保存。
如需测试脚本,请点击执行。
再次点击执行。
系统会返回一个 Google Cloud 令牌,并将其显示在 SAP 界面面板的底部。
SLT 要求
SLT 连接器必须具有以下设置:
- 连接器支持 SAP ECC NW 7.02、DMIS 2011 SP17 及更高版本。
- 在 SLT 和 Cloud Storage 系统之间配置 RFC 或数据库连接。
- 设置 SSL 证书:
- 从 Google Trust Services 代码库下载以下 CA 证书:
- GTS Root R1
- GTS CA 1C3
- 在 SAP 界面中,使用
STRUST事务将根证书和从属证书导入SSL Client (Standard) PSE文件夹。
- 从 Google Trust Services 代码库下载以下 CA 证书:
- 必须为 HTTPS 设置 Internet Communications Manager (ICM)。确保在 SAP SLT 系统中维护并激活 HTTP 和 HTTPS 端口。这可通过事务代码
SMICM > Services进行检查。 - 在托管 SAP SLT 系统的虚拟机上启用对 API 的访问权限。 Google Cloud 这样便可在Google Cloud 服务之间进行私密通信,而无需通过公共互联网进行路由。
- 确保网络可以支持 SAP 基础架构与 Cloud Storage 之间所需的数据传输量和速度。为了成功安装,建议使用 Cloud VPN 和/或 Cloud Interconnect。Streaming API 的吞吐量取决于已授予您的 Cloud Storage 项目的客户端配额。
配置 SLT 复制服务器
SAP 用户执行以下步骤。
在以下步骤中,您将 SLT 服务器连接到源系统和 Cloud Storage 中的存储桶,指定源系统、要复制的数据表以及目标存储桶。
配置 Google ABAP SDK
如需配置 SLT 以进行数据复制(每个 Cloud Data Fusion 实例一次),请按以下步骤操作:
如需配置 SLT 连接器,SAP 用户会在配置屏幕 (SAP Transaction
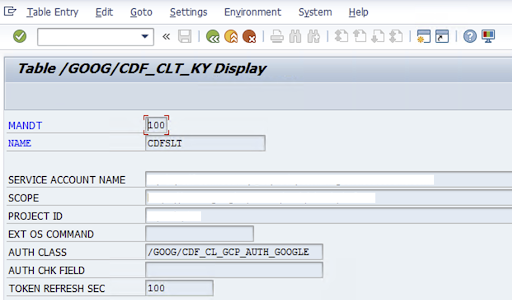
/GOOG/CDF_SETTINGS) 中输入有关 Google Cloud 服务账号密钥的以下信息,以将数据传输到 Cloud Storage。使用事务 SE16 配置表 /GOOG/CDF_CLT_KY 中的以下属性,并记下此键:- NAME:您的服务账号密钥的名称(例如
CDFSLT) - SERVICE ACCOUNT NAME:IAM 服务账号名称
- SCOPE:服务账号的范围
- PROJECT ID: Google Cloud 项目的 ID
- 可选:EXT OS 命令:如果未在 Google Cloud上安装 SLT,则使用此字段
AUTH CLASS:如果操作系统命令是在表
/GOOG/CDF_CLT_KY中设置的,请使用固定值:/GOOG/CDF_CL_GCP_AUTH。TOKEN REFRESH SEC:授权令牌刷新的时长
- NAME:您的服务账号密钥的名称(例如
创建复制配置
在事务代码中创建复制配置:LTRC。
- 在继续进行 LTRC 配置之前,请确保已在 SLT 和 Source SAP 系统之间建立 RFC 连接。
- 对于一个 SLT 配置,可能会为复制分配多个 SAP 表。
转到事务代码
LTRC并点击新配置。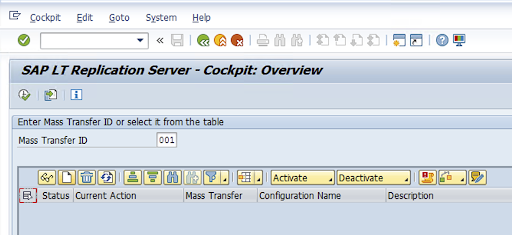
输入配置名称和说明,然后点击下一步。
指定 SAP Source 系统 RFC 连接,然后点击下一步。
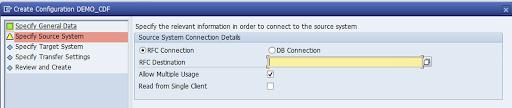
在“目标系统连接详细信息”中,选择其他。
展开 RFC 通信场景字段,选择 SLT SDK,然后点击下一步。
前往指定传输设置窗口,然后输入应用名称:
ZGOOGLE_CDF。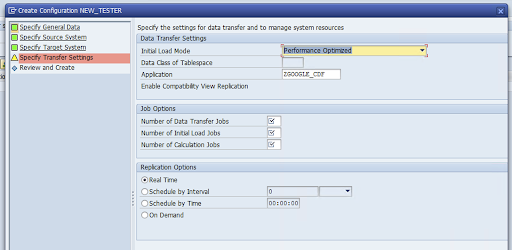
输入数据传输作业数量、初始加载作业数量和计算作业数量。如需详细了解性能,请参阅 SAP LT Replication Server 性能优化指南。
点击实时 > 下一步。
检查配置,然后点击保存。记下批量传输 ID 以完成以下步骤。
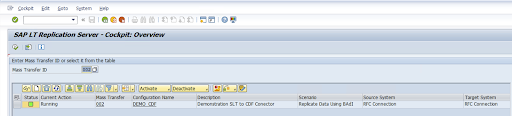
如需维护批量传输 ID 和 SAP 表的详细信息,请运行 SAP 事务:
/GOOG/CDF_SETTINGS。点击执行 (Execute),或按
F8。点击“附加行”图标以创建新条目。
输入批量传输 ID、批量传输密钥、GCP 密钥名称和目标 GCS 存储分区。选中有效复选框,然后保存更改。
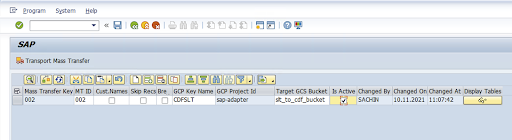
在配置名称列中选择配置,然后点击数据预配。
可选:自定义表和字段名称。
点击自定义名称,然后保存。
点击显示。
点击附加行或创建按钮以创建新条目。
输入要在 BigQuery 中使用的 SAP 表名称和外部表名称,然后保存更改。
点击显示字段列中的查看按钮,以维护表格字段的映射。
系统会打开一个页面,其中显示建议的映射。可选:修改临时字段名称和字段说明,然后保存映射。
前往 LTRC 事务。
在配置名称列中选择相应值,然后点击数据预配。
在数据库中的表名称字段中输入表名称,然后选择复制场景。
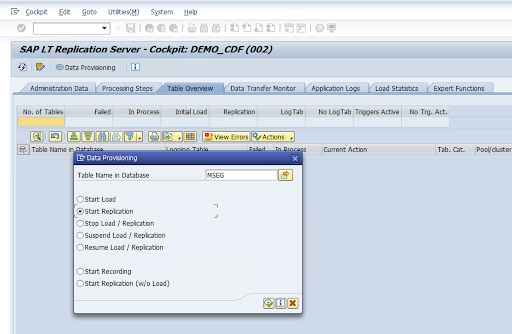
点击 Execute。这会触发 SLT SDK 实现,并开始将数据转移到 Cloud Storage 中的目标存储分区。
安装 SAP 传输文件
如需在 Cloud Data Fusion 中设计和运行复制作业,SAP 组件会以归档为 zip 文件的 SAP 传输文件的形式提供。在在 Cloud Data Fusion Hub 中部署插件后,即可下载该插件。
如需安装 SAP 传输,请按以下步骤操作:
第 1 步:上传传输请求文件
- 登录 SAP 实例的操作系统。
- 使用 SAP 事务代码
AL11获取DIR_TRANS文件夹的路径。路径通常为/usr/sap/trans/。 - 将 cofile 复制到
DIR_TRANS/cofiles文件夹。 - 将数据文件复制到
DIR_TRANS/data文件夹。 - 将数据和 cofile 的用户和组设置为
<sid>adm和sapsys。
第 2 步:导入传输请求文件
SAP 管理员可以使用 SAP 传输管理系统或操作系统导入传输请求文件:
SAP 传输管理系统
- 以 SAP 管理员身份登录 SAP 系统。
- 输入事务 STMS。
- 点击概览 > 导入。
- 在“队列”列中,双击当前 SID。
- 依次点击 Extras > 其他请求 > 添加。
- 选择传输请求 ID,然后点击继续。
- 在导入队列中选择传输请求,然后点击请求>导入。
- 输入客户端编号。
在选项标签页上,选择覆盖原始内容和忽略无效组件版本(如果有)。
可选:如需稍后重新导入传输,请点击将传输请求保留在队列中以供稍后导入和再次导入传输请求。这对于 SAP 系统升级和备份恢复非常有用。
点击继续。
使用事务(如
SE80和PFCG)验证函数模块和授权角色是否已成功导入。
操作系统
- 以 SAP 管理员身份登录 SAP 系统。
向导入缓冲区添加请求:
tp addtobuffer TRANSPORT_REQUEST_ID SID例如:
tp addtobuffer IB1K903958 DD1导入传输请求:
tp import TRANSPORT_REQUEST_ID SID client=NNN U1238将
NNN替换为客户端编号。例如:tp import IB1K903958 DD1 client=800 U1238使用适当的事务(如
SE80和PFCG)验证函数模块和授权角色是否已成功导入。
必需的 SAP 授权
如要在 Cloud Data Fusion 中运行数据流水线,您需要 SAP 用户。SAP 用户必须是“通信”或“对话”类型。为防止使用 SAP 对话框资源,建议使用“通信”类型。SAP 管理员可以使用 SAP 事务代码 SU01 创建用户。
需要 SAP 授权才能维护和配置 SAP 的连接器(SAP 标准和新连接器授权对象的组合)。您可以根据组织的安全政策维护授权对象。以下列表介绍了连接器所需的一些重要授权:
授权对象:授权对象
ZGOOGCDFMT作为 Transport Request 角色的一部分交付。创建角色:使用事务代码
PFCG来创建角色。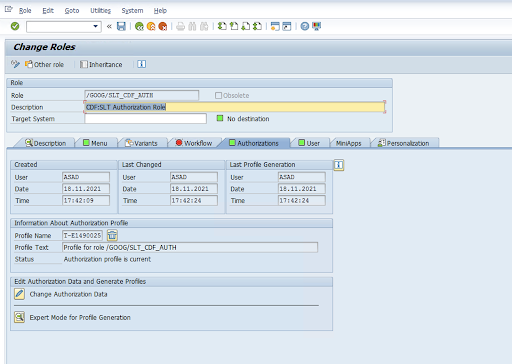
对于标准 SAP 授权对象,您的组织拥有自己的安全机制来管理权限。
对于自定义授权对象,请在授权对象
ZGOOGCDFMT的授权字段中提供值。对于精细的访问权限控制,
ZGOOGCDFMT提供了基于授权组的授权。具有授权组的完整访问权限、部分访问权限或无访问权限的用户将根据在其角色中分配的授权组获得访问权限。/GOOG/SLT_CDF_AUTH:拥有所有授权群组的访问权限的角色。如需限制特定授权组的访问权限,请在配置中维护授权组 FICDF。
为来源创建 RFC 目标
在开始配置之前,请确保在来源和目标之间建立 RFC 连接。
转到事务代码
SM59。依次点击创建 > 连接类型 3(ABAP 连接)。
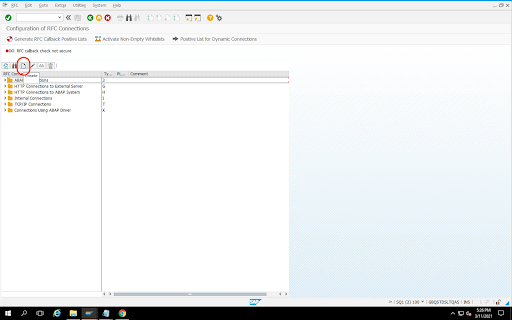
在技术设置窗口中,输入有关 RFC 目标的详细信息。
点击登录和安全标签页以保留 RFC 凭据(RFC 用户和密码)。
点击保存。
点击连接测试。测试成功后,您可以继续操作。
验证 RFC 授权测试是否成功。
依次点击实用程序 > 测试 > 授权测试。
配置插件
如需配置该插件,请按照以下步骤从 Hub 部署该插件、创建复制作业,然后配置源和目标。
在 Cloud Data Fusion 中部署插件
Cloud Data Fusion 用户执行以下步骤。
在运行 Cloud Data Fusion 复制作业之前,请先部署 SAP SLT Replication 插件:
前往您的实例:
在 Google Cloud 控制台中,前往 Cloud Data Fusion 实例页面。
在新实例或现有实例中启用复制功能:
- 对于新实例,请点击创建实例,输入实例名称,点击添加加速器,选中复制复选框,然后点击保存。
- 对于现有实例,请参阅在现有实例上启用复制功能。
点击查看实例,在 Cloud Data Fusion 网页界面中打开该实例。
点击 Hub。
前往 SAP 标签页,点击 SAP SLT,然后点击 SAP SLT Replication 插件或 SAP SLT No RFC Replication 插件。
点击部署。
创建复制作业
SAP SLT Replication 插件使用 Cloud Storage API 暂存桶读取 SAP 表的内容。
如需为数据传输作业创建复制作业,请按以下步骤操作:
在打开的 Cloud Data Fusion 实例中,依次点击首页 > 复制 > 创建复制作业。如果没有 Replication 选项,请为实例启用复制功能。
为复制作业输入唯一的名称和说明。
点击下一步。
配置来源
在以下字段中输入值以配置来源:
- 项目 ID:您的 Google Cloud 项目的 ID(此字段已预先填充)
数据复制 GCS 路径:包含要复制的数据的 Cloud Storage 路径。它必须是在 SAP SLT 作业中配置的路径。在内部,提供的路径会与
Mass Transfer ID和Source Table Name串联:格式:
gs://<base-path>/<mass-transfer-id>/<source-table-name>示例:
gs://slt_bucket/012/MARAGUID:SLT GUID,这是分配给 SAP SLT 批量传输 ID 的唯一标识符。
批量传输 ID:SLT 批量传输 ID 是分配给 SAP SLT 中的配置的唯一标识符。
SAP JCo 库 GCS 路径:包含用户上传的 SAP JCo 库文件的存储路径。SAP JCo 库可以从 SAP 支持门户下载。(在插件版本 0.10.0 中已移除。)
SLT 服务器主机:SLT 服务器主机名或 IP 地址。(在插件版本 0.10.0 中已移除。)
SAP 系统编号:系统管理员提供的安装系统编号(例如
00)。(在插件版本 0.10.0 中已移除。)SAP 客户端:要使用的 SAP 客户端(例如
100)。(已在插件版本 0.10.0 中移除。)SAP 语言:SAP 登录语言(例如
EN)。(已在插件版本 0.10.0 中移除。)SAP 登录用户名:SAP 用户名。(在插件版本 0.10.0 中已移除。)
- 推荐:如果 SAP 登录用户名定期更改,请使用宏。
SAP 登录密码 (M):用于用户身份验证的 SAP 用户密码。
- 推荐:对密码等敏感值使用安全宏。(在插件版本 0.10.0 中已移除。)
CDF 作业停止时暂停 SLT Replication:在 Cloud Data Fusion 复制作业停止时,尝试停止 SLT Replication 作业(针对相关表)。如果 Cloud Data Fusion 中的作业意外停止,可能会失败。
复制现有数据:指示是否从源表复制现有数据。默认情况下,这些作业会复制源表中的现有数据。如果设置为
false,系统会忽略源表中的所有现有数据,并且仅复制作业启动后发生的更改。服务账号密钥:与 Cloud Storage 交互时使用的密钥。该服务账号必须有权写入 Cloud Storage。在虚拟机上运行时,此值应设置为
auto-detect,以使用关联到虚拟机的服务账号。 Google Cloud
点击下一步。
配置目标
如需将数据写入 BigQuery,该插件需要对 BigQuery 和暂存存储分区的写入权限。更改事件首先从 SLT 批量写入 Cloud Storage。然后,它们会加载到 BigQuery 中的暂存表中。使用 BigQuery 合并查询将暂存表中的更改合并到最终目标表中。
最终目标表包含源表中的全部原始列和一个额外的 _sequence_num 列。序列号可确保数据在复制器故障场景中不会重复或缺失。
在以下字段中输入值以配置来源:
- 项目 ID:BigQuery 数据集的项目。在 Dataproc 集群上运行时,您可以将此项留空,这会导致使用集群的项目。
- 凭据:请参阅凭据。
- 服务账号密钥:与 Cloud Storage 和 BigQuery 交互时要使用的服务账号密钥的内容。在 Dataproc 集群上运行时,应将此项留空,这会导致使用集群的服务账号。
- 数据集名称:要在 BigQuery 中创建的数据集的名称。它是可选的,并且在默认情况下,数据集名称与源数据库名称相同。有效名称只能包含字母、数字和下划线,且最大长度为 1024 个字符。在最终数据集名称中,任何无效字符都将替换为下划线,而任何超出长度限制的字符都将被截断。
- 加密密钥名称:用于保护由此目标创建的资源的客户管理的加密密钥 (CMEK)。加密密钥名称必须为如下形式:
projects/<project-id>/locations/<key-location>/keyRings/<key-ring-name>/cryptoKeys/<key-name>。 - 位置:BigQuery 数据集和 Cloud Storage 暂存存储桶的创建位置。例如,
us-east1表示区域存储桶,us表示多区域存储桶(请参阅位置)。如果指定了现有存储桶,则会忽略此值,因为暂存存储桶和 BigQuery 数据集会在该存储桶所在的位置创建。 暂存存储桶:在将更改事件在加载到暂存表之前,将这些事件写入到其中的存储桶。更改将写入包含复制器名称和命名空间的目录。在同一实例中的多个复制器中使用同一存储分区是安全的。如果复制器由多个实例共享,请确保命名空间和名称具有唯一性,否则行为未定义。存储桶必须与 BigQuery 数据集位于同一位置。如果未提供存储桶,则系统会为名为
df-rbq-<namespace-name>-<job-name>-<deployment-timestamp>的每个作业创建一个新的存储桶。加载间隔(秒):将数据批加载到 BigQuery 之前等待的秒数。
暂存表前缀:更改会首先写入暂存表,然后再合并到最终表。暂存表名称的生成方式是将此前缀附加到目标表名称。
需要手动删除干预:当遇到删除表或删除数据库事件时,是否要求手动管理操作以删除表和数据集。设置为 true 时,复制器不会删除表或数据集。相反,它会失败并重试,直到表或数据集不存在为止。如果数据集或表不存在,则不需要手动干预。事件会照常跳过。
启用软删除:如果设置为 true,当目标收到删除事件时,记录的
_is_deleted列会设置为true。否则,系统会从 BigQuery 表中删除该记录。对于以无序方式生成事件的来源,此配置将不执行任何操作,并且系统始终会从 BigQuery 表中软删除记录。
点击下一步。
凭据
如果插件在 Dataproc 集群上运行,则应将服务账号密钥设置为自动检测。系统会自动从集群环境中读取凭据。
如果插件未在 Dataproc 集群上运行,则必须提供服务账号密钥的路径。服务账号密钥可在 Google Cloud 控制台的 IAM 页面中找到。确保该账号密钥有权访问 BigQuery。服务账号密钥文件必须在集群中的每个节点上可用,并且必须可供所有运行作业的用户读取。
限制
- 表必须具有要复制的主键。
- 不支持表重命名操作。
- 支持部分表更改。
- 现有的不可为 Null 的列可以更改为可为 Null 的列。
- 可为新的表添加新的可为 Null 的列。
- 对表架构进行的其他类型的更改将失败。
- 更改主键不会失败,但不会重写现有数据以遵循新的主键的唯一性。
选择表和转换
在选择表和转换步骤中,系统会显示要在 SLT 系统中复制的表列表。
- 选择要复制的表。
- 可选:选择其他架构操作,例如插入、更新或删除。
- 如需查看架构,请点击表的要复制的列。
可选:如需重命名架构中的列,请按以下步骤操作:
- 查看架构时,依次点击转换 > 重命名。
- 在重命名字段中,输入新名称,然后点击应用。
- 如需保存新名称,请依次点击刷新和保存。
点击下一步。
可选:配置高级属性
如果您知道一小时内要复制的数据量,则可以选择合适的选项。
查看评估
审核评估步骤会扫描复制期间发生的架构问题、缺少的功能或连接问题。
在查看评估页面上,点击查看映射。
如果出现任何问题,必须先解决问题,然后才能继续操作。
可选:如果您在选择表和转换时重命名了列,请在此步骤中验证新名称是否正确。
点击下一步。
查看摘要并部署复制作业
在查看复制作业详细信息页面上,查看设置并点击部署复制作业。
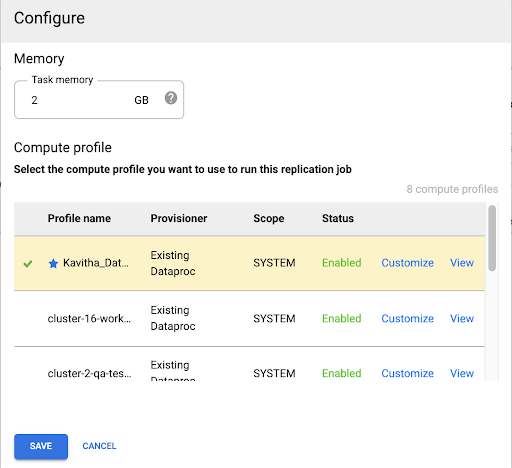
选择 Compute Engine 配置文件
部署复制作业后,从 Cloud Data Fusion 网页界面的任意页面点击配置。
选择要用于运行此复制作业的 Compute Engine 配置文件。
点击保存。
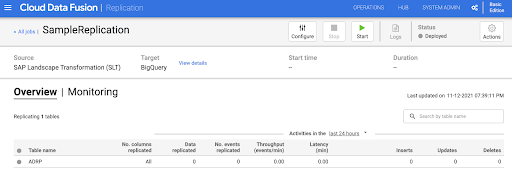
启动复制作业
- 如需运行复制作业,请点击开始。
可选:优化性能
默认情况下,该插件会配置为实现最佳性能。如需进行其他优化,请参阅运行时参数。
SLT 和 Cloud Data Fusion 通信的性能取决于以下因素:
- 源系统上的 SLT,而不是专用中央 SLT 系统(首选选项)
- SLT 系统上的后台作业处理
- 源 SAP 系统上的对话工作流程
- 分配给 LTRC 管理标签页中每个批量传输 ID 的后台作业进程数
- LTRS 设置
- SLT 系统的硬件(CPU 和内存)
- 使用的数据库(例如 HANA、Sybase 或 DB2)
- 互联网带宽(SAP 系统和通过互联网的Google Cloud 之间的连接)
- 系统上已存在的利用率(负载)
- 表中的列数。列越多,复制速度就越慢,延迟时间也会增加。
对于初始加载,建议使用 LTRS 设置中的以下读取类型:
| SLT 系统 | 源系统 | 表类型 | 推荐的读取类型 [初始负载] |
|---|---|---|---|
| SLT 3.0 独立 [DMIS 2018_1_752 SP 2] |
S/4 HANA 1909 | 透明(中/小) 透明(大) 聚簇表 |
1 次范围计算 1 次范围计算 4 个发送方队列 |
| SLT 嵌入式 [S4CORE 104 HANA 1909] |
不适用 | 透明(中/小) 透明(大) 聚簇表 |
1 次范围计算 1 次范围计算 4 个发送方队列 |
| SLT 2.0 独立 [DMIS 2011_1_731 SP 17] |
ECC NW 7.02 | 透明(中/小) 透明(大) 聚簇表 |
5 个发送者队列 5 个发送者队列 4 个发送者队列 |
| SLT 嵌入式 [DMIS 2011_1_700 SP 17] |
不适用 | 透明(中/小) 透明(大) 聚簇表 |
5 个发送者队列 5 个发送者队列 4 个发送者队列 |
- 对于复制,请使用“无范围”来提升性能:
- 只有在具有高延迟的日志记录表中生成积压时,才能使用范围。
- 使用 1 范围计算:对于 SLT 2.0 和非 HANA 系统,不建议使用初始负载的读取类型。
- 使用 1 范围计算:初始加载的读取类型可能会导致 BigQuery 中出现重复记录。
- 使用独立的 SLT 系统时,性能始终会更好。
- 如果源系统的资源利用率较高,则始终建议使用独立的 SLT 系统。
运行时参数
snapshot.thread.count:传递要开始并行执行SNAPSHOT/INITIAL数据加载的线程数。默认情况下,它使用运行复制作业的 Dataproc 集群中可用的 vCPU 数量。建议:仅在需要精确控制并发线程数(例如,为了减少集群上的使用情况)时设置此参数。
poll.file.count:传递要从 Web 界面中的数据复制 GCS 路径字段中提供的 Cloud Storage 路径轮询的文件数量。默认情况下,该值为每次轮询500,但可以根据集群配置进行增加或减少。建议:仅当您对复制延迟有严格要求时,才应设置此参数。值越低,延迟时间可能会越短。您可以使用它来提高吞吐量(如果无响应,请使用高于默认值的值)。
bad.files.base.path:传递要将复制期间发现的所有错误或有缺陷的数据文件复制到的 Cloud Storage 基本路径。如果对数据审核有严格的要求,并且必须使用特定位置来记录失败的传输,此方法会非常有用。默认情况下,系统会从 Web 界面中的数据复制 Cloud Storage 路径字段中提供的 Cloud Storage 路径复制所有有缺陷的文件。
有缺陷的数据文件的最终路径模式:
gs://BASE_FILE_PATH/MASS_TRANSFER_ID/SOURCE_TABLE_NAME/bad_files/REPLICATION_JOB_NAME/REPLICATION_JOB_ID/BAD_FILE_NAME
示例:
gs://slt_to_cdf_bucket/001/MARA/bad_files/MaraRepl/05f97349-7398-11ec-9443-8 ac0640fc83c/20220205_1901205168830_DATA_INIT.xml
文件无效的标准包括 XML 文件损坏或无效、缺少主键值或字段数据类型不匹配问题。
支持详情
支持的 SAP 产品和版本
- SAP_BASIS 702 版本,SP 级别 0016 及更高级别。
- SAP_ABA 702 版本,SP 级别 0016 及更高级别。
- DMIS 2011_1_700 版本,SP 级别 0017 及更高版本。
支持的 SLT 版本
支持 SLT 版本 2 和 3。
支持的 SAP 部署模型
SLT 作为独立系统或嵌入在源系统上。
开始使用 SLT 之前需要实现的 SAP 说明
如果您的支持包不包含适用于 PL12 或更高版本的 /UI2/CL_JSON 类更正,请实现适用于 /UI2/CL_JSON 类更正的最新 SAP 备注,例如适用于 PL12 的 SAP 备注 2798102。
建议:根据中央或来源系统条件实现 CNV_NOTE_ANALYZER_SLT 报告建议的 SAP 说明。如需了解详情,请参阅 SAP 说明 3016862(需要 SAP 登录)。
如果SAP 已设置完毕,则无需实现任何其他备注。如有任何具体错误或问题,请参阅您的 SLT 版本的中央 SAP 备注。
数据量或记录宽度限制
提取的数据量和记录宽度没有定义限制。
SAP SLT Replication 插件的预期吞吐量
对于根据优化性能中的指南配置的环境,插件可以提取大约 13 GB/小时的初始负载和 3 GB/小时的复制数据 (CDC)。实际性能可能会因 Cloud Data Fusion 和 SAP 系统负载或网络流量而异。
支持 SAP 增量(更改的数据)提取
支持 SAP 增量提取。
必需:Cloud Data Fusion 实例的租户对等互连
如果使用内部 IP 地址创建 Cloud Data Fusion 实例,则需要进行租户对等互连。如需详细了解租户对等互连,请参阅创建专用实例。
问题排查
复制作业不断重启
如果复制作业自动重启,请增加复制作业集群内存并重新运行复制作业。
BigQuery 接收器中存在重复项
如果您在 SAP SLT Replication 插件的高级设置中定义了并行作业数量,那么当表很大时,系统会发生错误,导致 BigQuery 接收器中出现重复列。
如需防止此问题,请移除用于加载数据的并行作业。
错误场景
下表列出了一些常见的错误消息(引号中的文本将在运行时替换为实际值):
| 消息 ID | 消息 | 建议采取的措施 |
|---|---|---|
CDF_SAP_SLT_01402 |
Service account type is not defined for
SERVICE_ACCT_NAME_FROM_UI. |
确保提供的 Cloud Storage 路径正确无误。 |
CDF_SAP_SLT_01403 |
Service account key provided is not valid due to error:
ROOT_CAUSE. Please provide a valid service account key for
service account type : SERVICE_ACCT_NAME_FROM_UI. |
请查看消息中显示的根本原因,并采取相应措施。 |
CDF_SAP_SLT_01404 |
Mass Transfer ID could not be found. Please ensure that it exists
in given GCS Bucket. |
检查给定的批量传输 ID 是否采用正确的格式。 |
CDF_SAP_SLT_01502 |
The specified data replication GCS path 'slt_to_cdf_bucket_1' or
Mass Transfer ID '05C' could not be found. Please ensure that it exists in
GCS. |
确保提供的 Cloud Storage 路径正确无误。 |
CDF_SAP_SLT_01400 |
Metadata file not found. The META_INIT.json file is not present or
file is present with invalid format. |
请查看消息中显示的根本原因,并采取相应措施。 |
CDF_SAP_SLT_03408 |
Failed to start the event reader. |
请查看消息中显示的根本原因,并采取相应措施。 |
CDF_SAP_SLT_03409 |
Error while processing TABLE_NAME file for source table
gs://CLOUD_STORAGE_BUCKET_NAME/MT_ID/TABLE_NAME
/FILE_NAME. Root cause: ROOT_CAUSE. |
请查看消息中显示的根本原因,并采取相应措施。 |
CDF_SAP_SLT_03410 |
Failed to replicate data for source table TABLE_NAME
from file: gs://CLOUD_STORAGE_BUCKET_NAME/MT_ID/
TABLE_NAME/FILE_NAME. Root cause:
ROOT_CAUSE. |
请查看消息中显示的根本原因,并采取相应措施。 |
CDF_SAP_SLT_03411 |
Failed data replication for source table TABLE_NAME.
Root cause: ROOT_CAUSE. |
请查看消息中显示的根本原因,并采取相应措施。 |
CDF_SAP_SLT_03412 |
Failed to create target table for source table
TABLE_NAME. Root cause: ROOT_CAUSE. |
请查看消息中显示的根本原因,并采取相应措施。 |
数据类型映射
下表显示了在 SAP 应用和 Cloud Data Fusion 中使用的数据类型之间的映射。
| SAP 数据类型 | ABAP 类型 | 说明 (SAP) | Cloud Data Fusion 数据类型 |
|---|---|---|---|
| 数字 | |||
| INT1 | b | 1 个字节的整数 | int |
| INT2 | 秒 | 2 个字节的整数 | int |
| INT4 | i | 4 个字节的整数 | int |
| INT8 | 8 | 8 个字节的整数 | long |
| DEC | p | 打包成采用 BCD 格式的数字 (DEC) | decimal |
| DF16_DEC DF16_RAW |
a | 十进制浮点 8 字节 IEEE 754r | decimal |
| DF34_DEC DF34_RAW |
e | 十进制浮点 16 字节 IEEE 754r | decimal |
| FLTP | f | 二进制浮点数 | double |
| 字符 | |||
| CHAR LCHR |
c | 字符串 | string |
| SSTRING GEOM_EWKB |
字符串 | 字符串 | string |
| STRING GEOM_EWKB |
字符串 | 字符串 CLOB | bytes |
| NUMC ACCP |
n | 数字文本 | string |
| Byte | |||
| RAW LRAW |
x | 二进制数据 | bytes |
| RAWSTRING | xstring | 字节字符串 BLOB | bytes |
| 日期/时间 | |||
| DATS | d | 日期 | date |
| Tims | t | 时间 | time |
| 时间戳 | utcl | ( Utclong ) TimeStamp |
timestamp |
后续步骤
- 详细了解 Cloud Data Fusion。
- 详细了解 SAP on Google Cloud。