Cette page explique comment activer la réplication en temps réel des données à partir d'applications SAP vers Google Cloud à l'aide de SAP Landscape Transformation (SLT). Le contenu s'applique aux plug-ins SAP SLT Replication (Réplication SAP SLT) et SAP SLT No RFC Replication (Réplication SAP SLT sans RFC), qui sont disponibles dans le hub Cloud Data Fusion. Il présente les configurations du système source SAP, de SLT, de Cloud Storage et de Cloud Data Fusion pour effectuer les opérations suivantes:
- Transférez les métadonnées SAP et les données de table vers Google Cloud à l'aide de SAP SLT.
- Créez une tâche de réplication Cloud Data Fusion qui lit les données d'un bucket Cloud Storage.
La réplication SAP SLT vous permet de répliquer vos données de manière continue et en temps réel à partir de sources SAP dans BigQuery. Vous pouvez configurer et exécuter des transferts de données à partir de systèmes SAP sans aucun codage.
Le processus de réplication SLT Cloud Data Fusion est le suivant:
- Les données proviennent d'un système source SAP.
- Le service suit et lit les données, puis les transfère vers Cloud Storage.
- Cloud Data Fusion extrait les données du bucket de stockage et les écrit dans BigQuery.
Vous pouvez transférer des données à partir de systèmes SAP compatibles, y compris des systèmes SAP hébergés dans Google Cloud.
Pour en savoir plus, consultez la présentation de SAP sur Google Cloud et les informations d'assistance.
Avant de commencer
Pour utiliser ce plug-in, vous devez connaître les domaines suivants :
- Créer des pipelines dans Cloud Data Fusion
- Gestion des accès avec IAM
- Configurer SAP Cloud et les systèmes ERP sur site
Les administrateurs et les utilisateurs qui effectuent les configurations
Les tâches de cette page sont effectuées par des personnes disposant des rôles suivants dans Google Cloud ou dans leur système SAP:
| Type d’utilisateur | Description |
|---|---|
| Administrateur Google Cloud | Les utilisateurs auxquels ce rôle est attribué sont des administrateurs de compte Google Cloud. |
| Utilisateur Cloud Data Fusion | Les utilisateurs auxquels ce rôle est attribué sont autorisés à concevoir et à exécuter des pipelines de données. Ils disposent au minimum du rôle Lecteur Data Fusion (
roles/datafusion.viewer). Si vous utilisez le contrôle des accès basé sur les rôles, vous aurez peut-être besoin de rôles supplémentaires.
|
| Administrateur SAP | Les utilisateurs auxquels ce rôle est attribué sont les administrateurs du système SAP. Ils ont accès à la page de téléchargement du logiciel à partir du site de service SAP. Il ne s'agit pas d'un rôle IAM. |
| Utilisateur SAP | Les utilisateurs auxquels ce rôle est attribué sont autorisés à se connecter à un système SAP. Il ne s'agit pas d'un rôle IAM. |
Opérations de réplication compatibles
Le plug-in SAP SLT Replication est compatible avec les opérations suivantes:
Modélisation des données: toutes les opérations de modélisation des données (enregistrement insert, delete et update) sont compatibles avec ce plug-in.
Définition des données: comme décrit dans la note SAP 2055599 (connexion à l'assistance SAP requise pour la consulter), il existe des limites concernant les modifications de la structure de table du système source qui sont répliquées automatiquement par SLT. Certaines opérations de définition de données ne sont pas prises en charge par le plug-in (vous devez les propager manuellement).
- Compatible :
- Ajouter un champ non clé (après avoir effectué des modifications dans SE11, activez la table à l'aide de SE14)
- Non compatible :
- Ajouter/Supprimer un champ de clé
- Supprimer un champ non clé
- Modifier les types de données
Exigences concernant SAP
Les éléments suivants sont requis dans votre système SAP:
- Vous avez installé SLT Server version 2011 SP17 ou ultérieure sur le système SAP source (intégré) ou en tant que système de hub SLT dédié.
- Votre système SAP source est SAP ECC ou SAP S/4HANA, qui est compatible avec DMIS 2011 SP17 ou version ultérieure, comme DMIS 2018 ou DMIS 2020.
- Votre module complémentaire d'interface utilisateur SAP doit être compatible avec votre version de SAP NetWeaver.
Votre formule d'assistance est compatible avec la classe
/UI2/CL_JSONPL 12ou une version ultérieure. Dans le cas contraire, implémentez la dernière note SAP pour la classe/UI2/CL_JSONcorrectionsen fonction de la version de votre module complémentaire d'interface utilisateur, comme la note SAP 2798102 pourPL12.Les mesures de sécurité suivantes sont en place:
Exigences concernant Cloud Data Fusion
- Vous avez besoin d'une instance Cloud Data Fusion, version 6.4.0 ou ultérieure, n'importe quelle édition.
- Le compte de service attribué à l'instance Cloud Data Fusion dispose des rôles requis (voir Accorder l'autorisation de l'utilisateur du compte de service).
- Pour les instances Cloud Data Fusion privées, l'appairage de VPC est obligatoire.
Configuration requise pourGoogle Cloud
- Activez l'API Cloud Storage dans votre Google Cloud projet.
- L'utilisateur Cloud Data Fusion doit être autorisé à créer des dossiers dans le bucket Cloud Storage (voir la section Rôles IAM pour Cloud Storage).
- Facultatif: Définissez la règle de conservation, si nécessaire pour votre organisation.
Créer le bucket de stockage
Avant de créer une tâche de réplication SLT, créez le bucket Cloud Storage. La tâche transfère les données vers le bucket et actualise le bucket de préproduction toutes les cinq minutes. Lorsque vous exécutez la tâche, Cloud Data Fusion lit les données du bucket de stockage et les écrit dans BigQuery.
Si SLT est installé sur Google Cloud
Le serveur SLT doit être autorisé à créer et à modifier des objets Cloud Storage dans le bucket que vous avez créé.
Attribuez au moins les rôles suivants au compte de service:
- Créateur de jetons du compte de service (
roles/iam.serviceAccountTokenCreator) - Consommateur Service Usage (
roles/serviceusage.serviceUsageConsumer) - Administrateur des objets de l'espace de stockage (
roles/storage.objectAdmin)
Si SLT n'est pas installé sur Google Cloud
Installez Cloud VPN ou Cloud Interconnect entre la VM SAP etGoogle Cloud pour autoriser la connexion à un point de terminaison de métadonnées interne (voir la section Configurer l'Accès privé à Google pour les hôtes sur site).
Si les métadonnées internes ne peuvent pas être mappées:
Installez Google Cloud CLI en fonction du système d'exploitation de l'infrastructure sur laquelle SLT s'exécute.
Créez un compte de service dans le projet Google Cloud où Cloud Storage est activé.
Sur le système d'exploitation SLT, autorisez l'accès à Google Cloud avec un compte de service.
Créez une clé API pour le compte de service et autorisez le champ d'application associé à Cloud Storage.
Importez la clé API dans la gcloud CLI installée précédemment à l'aide de la CLI.
Pour activer la commande de la CLI gcloud qui imprime le jeton d'accès, configurez la commande du système d'exploitation SAP dans l'outil de transaction SM69 du système SLT.
Imprimer un jeton d'accès
L'administrateur SAP configure la commande du système d'exploitation, SM69, qui récupère un jeton d'accès à partir de Google Cloud.
Créez un script pour imprimer un jeton d'accès et configurez une commande de système d'exploitation SAP pour appeler le script en tant qu'utilisateur <sid>adm à partir de l'hôte SAP LT Replication Server.
Linux
Pour créer une commande d'OS:
Sur l'hôte SAP LT Replication Server, dans un répertoire accessible à
<sid>adm, créez un script bash contenant les lignes suivantes:PATH_TO_GCLOUD_CLI/bin/gcloud auth print-access-token SERVICE_ACCOUNT_NAMEÀ l'aide de l'interface utilisateur SAP, créez une commande de système d'exploitation externe:
- Saisissez la transaction
SM69. - Cliquez sur Créer.
- Dans la section Commande du panneau Commande externe, saisissez le nom de la commande, par exemple
ZGOOGLE_CDF_TOKEN. Dans la section Définition :
- Dans le champ Commande de système d'exploitation, saisissez
shcomme extension de fichier de script. Dans le champ Paramètres pour la commande de système d'exploitation, saisissez :
/PATH_TO_SCRIPT/FILE_NAME.sh
- Dans le champ Commande de système d'exploitation, saisissez
Cliquez sur Enregistrer.
Pour tester le script, cliquez sur Exécuter.
Cliquez à nouveau sur Exécuter.
Un jeton Google Cloud est renvoyé et affiché au bas du panneau de l'interface utilisateur de SAP.
- Saisissez la transaction
Windows
À l'aide de l'interface utilisateur SAP, créez une commande de système d'exploitation externe:
- Saisissez la transaction
SM69. - Cliquez sur Créer.
- Dans la section Commande du panneau Commande externe, saisissez le nom de la commande, par exemple
ZGOOGLE_CDF_TOKEN. Dans la section Définition :
- Dans le champ Commande de système d'exploitation, saisissez
cmd /c. Dans le champ Paramètres pour la commande de système d'exploitation, saisissez :
gcloud auth print-access-token SERVICE_ACCOUNT_NAME
- Dans le champ Commande de système d'exploitation, saisissez
Cliquez sur Enregistrer.
Pour tester le script, cliquez sur Exécuter.
Cliquez à nouveau sur Exécuter.
Un jeton Google Cloud est renvoyé et affiché en bas du panneau de l'interface utilisateur de SAP.
Exigences concernant les SLT
Le connecteur SLT doit être configuré comme suit:
- Le connecteur est compatible avec SAP ECC NW 7.02, DMIS 2011 SP17 et versions ultérieures.
- Configurez une connexion RFC ou de base de données entre SLT et le système Cloud Storage.
- Configurez les certificats SSL :
- Téléchargez les certificats CA suivants à partir du dépôt Google Trust Services :
- GTS Root R1
- GTS CA 1C3
- Dans l'interface utilisateur SAP, utilisez la transaction
STRUSTpour importer le certificat racine et le certificat subordonné dans le dossierSSL Client (Standard) PSE.
- Téléchargez les certificats CA suivants à partir du dépôt Google Trust Services :
- Le gestionnaire de communication Internet (ICM) doit être configuré pour le protocole HTTPS. Assurez-vous que les ports HTTP et HTTPS sont gérés et activés dans le système SAP SLT.
Vous pouvez le vérifier à l'aide du code de transaction
SMICM > Services. - Activez l'accès aux API Google Cloud sur la VM où le système SAP SLT est hébergé. Cela permet une communication privée entre les servicesGoogle Cloud sans passer par l'Internet public.
- Assurez-vous que le réseau peut prendre en charge le volume et la vitesse requis pour le transfert de données entre l'infrastructure SAP et Cloud Storage. Pour une installation réussie, nous vous recommandons d'utiliser Cloud VPN et/ou Cloud Interconnect. Le débit de l'API de streaming dépend des quotas client accordés à votre projet Cloud Storage.
Configurer le serveur de réplication SLT
L'utilisateur SAP effectue les étapes suivantes.
Dans les étapes suivantes, vous allez connecter le serveur SLT au système source et au bucket dans Cloud Storage, en spécifiant le système source, les tables de données à répliquer et le bucket de stockage cible.
Configurer le SDK ABAP Google
Pour configurer SLT pour la réplication des données (une fois par instance Cloud Data Fusion), procédez comme suit:
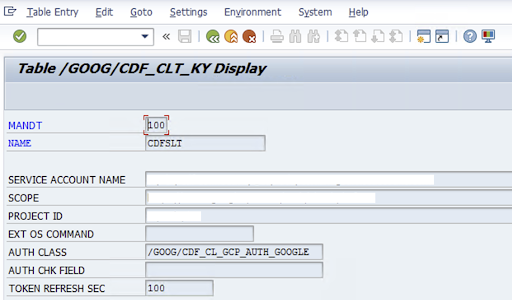
Pour configurer le connecteur SLT, l'utilisateur SAP saisit les informations suivantes sur la clé de compte de service pour transférer des données vers Cloud Storage dans l'écran de configuration (transaction SAP
/GOOG/CDF_SETTINGS). Google Cloud Configurez les propriétés suivantes dans la table /GOOG/CDF_CLT_KY à l'aide de la transaction SE16 et notez cette clé:- NAME: nom de votre clé de compte de service (par exemple,
CDFSLT) - SERVICE ACCOUNT NAME (NOM DU COMPTE DE SERVICE) : nom du compte de service IAM
- CHAMP D'APPLICATION: champ d'application du compte de service
- PROJECT ID: ID de votre Google Cloud projet
- Facultatif: Commande du système d'exploitation EXT: n'utilisez ce champ que si SLT n'est pas installé sur Google Cloud
AUTH CLASS: si la commande de l'OS est configurée dans le tableau
/GOOG/CDF_CLT_KY, utilisez la valeur fixe:/GOOG/CDF_CL_GCP_AUTH.TOKEN REFRESH SEC: durée d'actualisation du jeton d'autorisation
- NAME: nom de votre clé de compte de service (par exemple,
Configurer la réplication
Créez une configuration de duplication dans le code de transaction: LTRC.
- Avant de procéder à la configuration de LTRC, assurez-vous que la connexion RFC entre SLT et le système SAP source est établie.
- Pour une configuration SLT, plusieurs tables SAP peuvent être attribuées à la réplication.
Accédez au code de transaction
LTRC, puis cliquez sur Nouvelle configuration.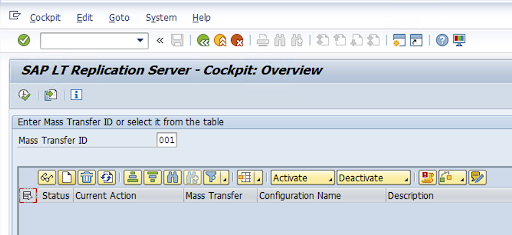
Saisissez le nom de la configuration et la description, puis cliquez sur Suivant.
Spécifiez la connexion RFC du système source SAP, puis cliquez sur Next (Suivant).
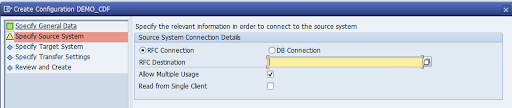
Dans les détails de la connexion au système cible, sélectionnez Autre.
Développez le champ Scénario pour la communication RFC, sélectionnez SDK SLT, puis cliquez sur Suivant.
Accédez à la fenêtre Spécifier les paramètres de transfert et saisissez le nom de l'application:
ZGOOGLE_CDF.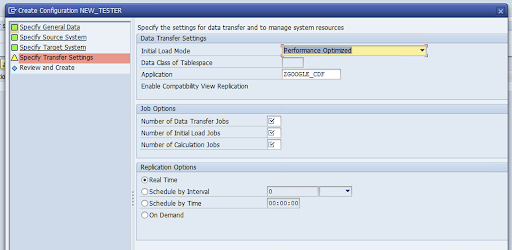
Saisissez le nombre de tâches de transfert de données, le nombre de tâches de chargement initiales et le nombre de tâches de calcul. Pour en savoir plus sur les performances, consultez le guide d'optimisation des performances de SAP LT Replication Server.
Cliquez sur Temps réel > Suivant.
Vérifiez la configuration, puis cliquez sur Enregistrer. Notez l'ID de transfert de masse pour les étapes suivantes.
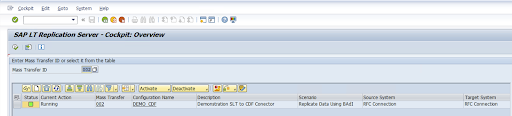
Pour conserver l'ID de transfert de masse et les informations sur la table SAP, exécutez la transaction SAP:
/GOOG/CDF_SETTINGS.Cliquez sur Exécuter ou appuyez sur
F8.Créez une entrée en cliquant sur l'icône Ajouter une ligne.
Saisissez l'ID de transfert de masse, la clé de transfert de masse, le nom de la clé GCP et le bucket GCS cible. Cochez la case Est actif, puis enregistrez les modifications.
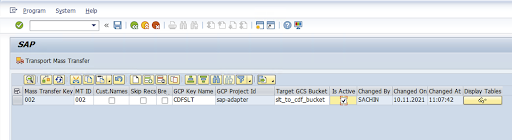
Sélectionnez la configuration dans la colonne Nom de la configuration, puis cliquez sur Provisionnement de données.
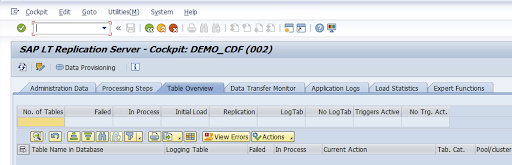
Facultatif: Personnalisez les noms de la table et des champs.
Cliquez sur Noms personnalisés, puis enregistrez.
Cliquez sur Affichage.
Créez une entrée en cliquant sur les boutons Ajouter une ligne ou Créer.
Saisissez le nom de la table SAP et le nom de la table externe à utiliser dans BigQuery, puis enregistrez les modifications.
Cliquez sur le bouton Afficher dans la colonne Champs à afficher pour conserver le mappage des champs de tableau.
Une page s'ouvre avec des suggestions de mappages. (Facultatif) Modifiez les champs Nom du champ temporaire et Description du champ, puis enregistrez les mises en correspondance.
Accédez à la transaction LTRC.
Sélectionnez la valeur dans la colonne Nom de la configuration, puis cliquez sur Provisionnement de données.
Saisissez le nom de la table dans le champ Nom de la table dans la base de données, puis sélectionnez le scénario de réplication.
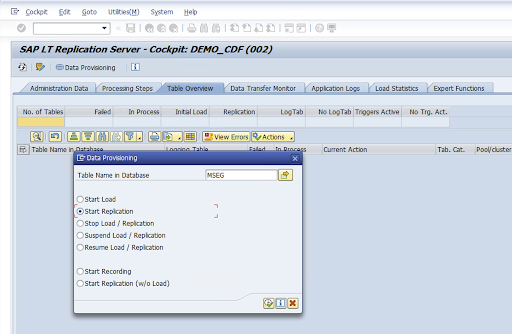
Cliquez sur Exécuter. Cela déclenche l'implémentation du SDK SLT et commence à transférer les données vers le bucket cible dans Cloud Storage.
Installer des fichiers de transport SAP
Pour concevoir et exécuter des tâches de réplication dans Cloud Data Fusion, les composants SAP sont fournis sous forme de fichiers de transport SAP archivés dans un fichier ZIP. Le téléchargement est disponible lorsque vous déployez le plug-in dans le hub Cloud Data Fusion.
Pour installer les transports SAP, procédez comme suit:
Étape 1 : Importer les fichiers de requête de transport
- Connectez-vous au système d'exploitation de l'instance SAP.
- Utilisez le code de transaction SAP
AL11pour obtenir le chemin d'accès du dossierDIR_TRANS. Le chemin d'accès est généralement/usr/sap/trans/. - Copiez les fichiers cofile dans le dossier
DIR_TRANS/cofiles. - Copiez les fichiers de données dans le dossier
DIR_TRANS/data. - Définissez l'utilisateur et le groupe de données et de cofichier sur
<sid>admetsapsys.
Étape 2 : Importer les fichiers de requête de transport
L'administrateur SAP peut importer les fichiers de requête de transport à l'aide du système de gestion des transports SAP ou du système d'exploitation:
Système de gestion des transports SAP
- Connectez-vous au système SAP en tant qu'administrateur SAP.
- Saisissez le code STMS de la transaction.
- Cliquez sur Présentation > Importations.
- Dans la colonne Queue (File d'attente), double-cliquez sur le SID actuel.
- Cliquez sur Extras > Autres requêtes > Ajouter.
- Sélectionnez l'ID de la requête de transport, puis cliquez sur Continuer.
- Sélectionnez la demande de transport dans la file d'attente d'importation, puis cliquez sur Demander > Importer.
- Saisissez le numéro client.
Dans l'onglet Options, sélectionnez Écraser les versions d'origine et Ignorer la version de composant non valide (si disponible).
Facultatif: Pour réimporter les transports ultérieurement, cliquez sur Laisser des requêtes de transport en file d'attente pour une importation ultérieure et Importer à nouveau les requêtes de transport. Cette fonctionnalité est utile pour les mises à niveau du système SAP et les restaurations de sauvegarde.
Cliquez sur Continuer.
Vérifiez que le module de fonction et les rôles d'autorisation ont bien été importés à l'aide de transactions, telles que
SE80etPFCG.
Système d'exploitation
- Connectez-vous au système SAP en tant qu'administrateur SAP.
Ajoutez des requêtes au tampon d'importation:
tp addtobuffer TRANSPORT_REQUEST_ID SIDPar exemple :
tp addtobuffer IB1K903958 DD1Importez les requêtes de transport:
tp import TRANSPORT_REQUEST_ID SID client=NNN U1238Remplacez
NNNpar le numéro client. Exemple :tp import IB1K903958 DD1 client=800 U1238.Vérifiez que le module de fonction et les rôles d'autorisation ont bien été importés à l'aide des transactions appropriées, telles que
SE80etPFCG.
Autorisations SAP requises
Pour exécuter un pipeline de données dans Cloud Data Fusion, vous avez besoin d'un utilisateur SAP. L'utilisateur SAP doit être de type Communications ou Dialog. Pour éviter d'utiliser les ressources de boîte de dialogue SAP, le type Communications est recommandé. L'administrateur SAP peut créer des utilisateurs à l'aide du code de transaction SAP SU01.
Les autorisations SAP sont requises pour gérer et configurer le connecteur pour SAP, une combinaison d'objets d'autorisation standard SAP et de nouveaux objets d'autorisation de connecteur. Vous gérez les objets d'autorisation en fonction des règles de sécurité de votre organisation. La liste suivante décrit certaines autorisations importantes requises pour le connecteur:
Objet d'autorisation: l'objet d'autorisation
ZGOOGCDFMTest fourni dans le rôle de requête de transport.Création de rôle: créez un rôle à l'aide du code de transaction
PFCG.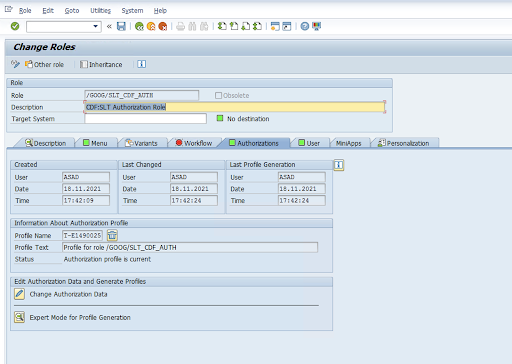
Pour les objets d'autorisation SAP standards, votre organisation gère les autorisations avec son propre mécanisme de sécurité.
Pour les objets d'autorisation personnalisés, indiquez des valeurs dans les champs d'autorisation pour les objets d'autorisation
ZGOOGCDFMT.Pour un contrôle précis des accès,
ZGOOGCDFMTfournit une autorisation basée sur des groupes d'autorisation. Les utilisateurs disposant d'un accès complet, partiel ou nul aux groupes d'autorisation sont autorisés en fonction du groupe d'autorisation attribué à leur rôle./GOOG/SLT_CDF_AUTH: rôle avec accès à tous les groupes d'autorisation. Pour limiter l'accès à un groupe d'autorisation spécifique, conservez le FICDF du groupe d'autorisation dans la configuration.
Créer une destination RFC pour la source
Avant de commencer la configuration, assurez-vous que la connexion RFC est établie entre la source et la destination.
Accédez au code de transaction
SM59.Cliquez sur Créer > Type de connexion 3 (connexion ABAP).
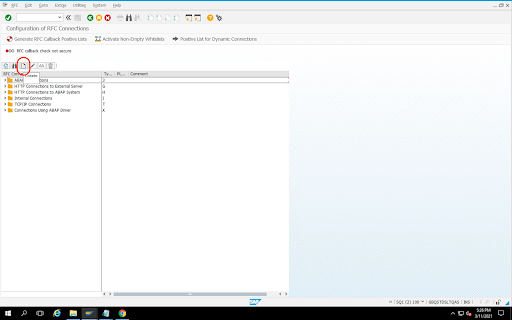
Dans la fenêtre Paramètres techniques, saisissez les informations sur la destination RFC.
Cliquez sur l'onglet Logon and Security (Connexion et sécurité) pour gérer les identifiants RFC (nom d'utilisateur et mot de passe RFC).
Cliquez sur Enregistrer.
Cliquez sur Test de connexion. Une fois le test réussi, vous pouvez continuer.
Vérifiez que le test d'autorisation RFC a réussi.
Cliquez sur Utilitaires > Test > Test d'autorisation.
Configurer le plug-in
Pour configurer le plug-in, déployez-le à partir du hub, créez une tâche de réplication et configurez la source et la cible en suivant les étapes ci-dessous.
Déployer le plug-in dans Cloud Data Fusion
L'utilisateur Cloud Data Fusion effectue les étapes suivantes.
Avant de pouvoir exécuter la tâche de réplication Cloud Data Fusion, déployez le plug-in SAP SLT Replication:
Accédez à votre instance:
Dans la console Google Cloud , accédez à la page Instances de Cloud Data Fusion.
Activez la réplication dans une instance nouvelle ou existante:
- Pour créer une instance, cliquez sur Créer une instance, saisissez un nom d'instance, cliquez sur Ajouter des accélérateurs, cochez la case Réplication, puis cliquez sur Enregistrer.
- Pour une instance existante, consultez la section Activer la réplication sur une instance existante.
Cliquez sur Afficher l'instance pour ouvrir l'instance dans l'interface Web de Cloud Data Fusion.
Cliquez sur Hub.
Accédez à l'onglet SAP, cliquez sur SAP SLT, puis sur Plug-in de réplication SAP SLT ou Plug-in de réplication SAP SLT sans RFC.
Cliquez sur Déployer.
Créer un job de réplication
Le plug-in SAP SLT Replication lit le contenu des tables SAP à l'aide d'un bucket de préproduction de l'API Cloud Storage.
Pour créer une tâche de réplication pour votre transfert de données, procédez comme suit:
Dans votre instance Cloud Data Fusion ouverte, cliquez sur Accueil > Réplication > Créer une tâche de réplication. Si l'option Replication (Réplication) n'est pas disponible, activez la réplication pour l'instance.
Saisissez un nom et une description uniques pour la tâche de réplication.
Cliquez sur Suivant.
Configurer la source
Configurez la source en saisissant des valeurs dans les champs suivants:
- ID du projet: ID de votre Google Cloud projet (ce champ est prérempli)
Chemin d'accès GCS de la réplication de données: chemin d'accès Cloud Storage contenant les données à répliquer. Il doit s'agir du même chemin que celui configuré dans les tâches SAP SLT. En interne, le chemin d'accès fourni est concaténé avec
Mass Transfer IDetSource Table Name:Format :
gs://<base-path>/<mass-transfer-id>/<source-table-name>Exemple :
gs://slt_bucket/012/MARAGUID: GUID SLT, identifiant unique attribué à l'ID de transfert groupé SAP SLT.
ID de transfert de masse: l'ID de transfert de masse SLT est un identifiant unique attribué à la configuration dans SAP SLT.
Chemin d'accès GCS de la bibliothèque SAP JCo: chemin d'accès au stockage contenant les fichiers de bibliothèque SAP JCo importés par l'utilisateur. Vous pouvez télécharger les bibliothèques JCo SAP à partir du portail d'assistance SAP. (Supprimé dans la version 0.10.0 du plug-in.)
Hôte du serveur SLT: nom d'hôte ou adresse IP du serveur SLT. (Supprimé dans la version 0.10.0 du plug-in.)
Numéro de système SAP: numéro de système d'installation fourni par l'administrateur système (par exemple,
00). (Supprimé dans la version 0.10.0 du plug-in.)Client SAP: client SAP à utiliser (par exemple,
100). (Supprimé dans la version 0.10.0 du plug-in.)Langage SAP: langage de connexion SAP (par exemple,
EN). (Supprimé dans la version 0.10.0 du plug-in.)Nom d'utilisateur de connexion SAP: nom d'utilisateur SAP. (Supprimé dans la version 0.10.0 du plug-in.)
- Recommandé: Si le nom d'utilisateur de connexion SAP change régulièrement, utilisez une macro.
Mot de passe d'ouverture de session SAP (M): mot de passe utilisateur SAP pour l'authentification des utilisateurs.
- Recommandation: Utilisez des macros sécurisées pour les valeurs sensibles, telles que les mots de passe. (Supprimé dans la version 0.10.0 du plug-in.)
Suspendre la réplication SLT lorsque la tâche CDF s'arrête: tente d'arrêter la tâche de réplication SLT (pour les tables concernées) lorsque la tâche de réplication Cloud Data Fusion s'arrête. Peut échouer si la tâche dans Cloud Data Fusion s'arrête de manière inattendue.
Répliquer les données existantes: indique si les données existantes des tables sources doivent être répliquées. Par défaut, les tâches répliquent les données existantes des tables sources. Si la valeur est
false, toutes les données existantes dans les tables sources sont ignorées et seules les modifications qui se produisent après le début de la tâche sont répliquées.Clé de compte de service: clé à utiliser lors de l'interaction avec Cloud Storage. Le compte de service doit être autorisé à écrire dans Cloud Storage. Lorsqu'il s'exécute sur une VM Google Cloud , ce paramètre doit être défini sur
auto-detectpour utiliser le compte de service associé à la VM.
Cliquez sur Suivant.
Configurer la cible
Pour écrire des données dans BigQuery, le plug-in nécessite un accès en écriture à BigQuery et à un bucket de préproduction. Les événements de modification sont d'abord écrits par lots de SLT vers Cloud Storage. Elles sont ensuite chargées dans des tables de préproduction dans BigQuery. Les modifications apportées à la table de préproduction sont fusionnées dans la table cible finale à l'aide d'une requête de fusion BigQuery.
La table cible finale inclut toutes les colonnes d'origine de la table source, ainsi qu'une colonne _sequence_num supplémentaire. Le numéro de séquence garantit que les données ne sont pas dupliquées ni manquées en cas de défaillance du réplicateur.
Configurez la source en saisissant des valeurs dans les champs suivants:
- ID de projet: projet de l'ensemble de données BigQuery. Lors de l'exécution sur un cluster Dataproc, ce champ peut être laissé vide, ce qui utilisera le projet du cluster.
- Identifiants: consultez Identifiants.
- Clé de compte de service: contenu de la clé de compte de service à utiliser lors de l'interaction avec Cloud Storage et BigQuery. Lorsqu'il s'exécute sur un cluster Dataproc, ce champ doit être laissé vide, ce qui utilise le compte de service du cluster.
- Nom de l'ensemble de données: nom de l'ensemble de données à créer dans BigQuery. Il est facultatif et, par défaut, le nom de l'ensemble de données est identique à celui de la base de données source. Un nom valide ne doit contenir que des lettres, des chiffres et des traits de soulignement. Sa longueur maximale est de 1 024 caractères. Tous les caractères non valides sont remplacés par un trait de soulignement dans le nom final de l'ensemble de données, et les caractères dépassant la limite de longueur sont tronqués.
- Nom de la clé de chiffrement: clé de chiffrement gérée par le client (CMEK) utilisée pour sécuriser les ressources créées par cette cible. Le nom de la clé de chiffrement doit être au format
projects/<project-id>/locations/<key-location>/keyRings/<key-ring-name>/cryptoKeys/<key-name>. - Emplacement: emplacement où l'ensemble de données BigQuery et le bucket de préproduction Cloud Storage sont créés. Par exemple,
us-east1pour les buckets régionaux,uspour les buckets multirégionaux (voir la section Emplacements). Cette valeur est ignorée si un bucket existant est spécifié, car le bucket de préproduction et l'ensemble de données BigQuery sont créés au même emplacement que ce bucket. Bucket de préproduction: bucket dans lequel les événements de modification sont écrits avant d'être chargés dans des tables de préproduction. Les modifications sont écrites dans un répertoire contenant le nom et l'espace de noms du réplicateur. Vous pouvez utiliser le même bucket sur plusieurs réplicateurs au sein de la même instance. S'il est partagé par des réplicateurs sur plusieurs instances, assurez-vous que l'espace de noms et le nom sont uniques, sinon le comportement n'est pas défini. Le bucket doit se trouver au même emplacement que l'ensemble de données BigQuery. S'il n'est pas fourni, un bucket est créé pour chaque tâche et nommé
df-rbq-<namespace-name>-<job-name>-<deployment-timestamp>.Intervalle de chargement (en secondes): nombre de secondes à attendre avant de charger un lot de données dans BigQuery.
Préfixe de la table de préproduction: les modifications sont d'abord écrites dans une table de préproduction avant d'être fusionnées dans la table finale. Les noms des tables de préproduction sont générés en ajoutant ce préfixe au nom de la table cible.
Require Manual Drop Intervention (Exiger une intervention manuelle pour supprimer) : indique si une action administrative manuelle est requise pour supprimer des tables et des ensembles de données lorsqu'un événement de suppression de table ou de base de données est détecté. Lorsque cette valeur est définie sur "true", le réplicateur ne supprime pas de table ni d'ensemble de données. À la place, il échoue et réessaie jusqu'à ce que la table ou l'ensemble de données n'existe plus. Si l'ensemble de données ou la table n'existent pas, aucune intervention manuelle n'est requise. L'événement est ignoré comme d'habitude.
Enable Soft Deletes (Activer la suppression douce) : si cette valeur est définie sur "true", lorsqu'un événement de suppression est reçu par la cible, la colonne
_is_deletedde l'enregistrement est définie surtrue. Sinon, l'enregistrement est supprimé de la table BigQuery. Cette configuration n'a aucun effet pour une source qui génère des événements dans le désordre, et les enregistrements sont toujours supprimés de manière temporaire de la table BigQuery.
Cliquez sur Suivant.
Identifiants
Si le plug-in est exécuté sur un cluster Dataproc, la clé du compte de service doit être définie sur la détection automatique. Les identifiants sont automatiquement lus à partir de l'environnement du cluster.
Si le plug-in n'est pas exécuté sur un cluster Dataproc, le chemin d'accès à une clé de compte de service doit être fourni. La clé du compte de service se trouve sur la page IAM de la console Google Cloud . Assurez-vous que la clé de compte est autorisée à accéder à BigQuery. Le fichier de clé du compte de service doit être disponible sur chaque nœud de votre cluster et être lisible par tous les utilisateurs exécutant la tâche.
Limites
- Les tables doivent disposer d'une clé primaire pour être répliquées.
- Les opérations de renommage de table ne sont pas acceptées.
- Les modifications de table sont partiellement compatibles.
- Vous pouvez modifier une colonne non nullable existante en colonne nullable.
- Vous pouvez ajouter des colonnes nullables à une table existante.
- Tout autre type de modification du schéma de table échouera.
- Les modifications apportées à la clé primaire ne seront pas refusées, mais les données existantes ne seront pas réécrites pour respecter l'unicité de la nouvelle clé primaire.
Sélectionner des tables et des transformations
À l'étape Sélectionner des tables et des transformations, une liste des tables sélectionnées pour la réplication dans le système SLT s'affiche.
- Sélectionnez les tables à répliquer.
- Facultatif: sélectionnez des opérations de schéma supplémentaires, telles que Insertions, Mises à jour ou Suppressions.
- Pour afficher le schéma, cliquez sur Colonnes à répliquer pour une table.
Facultatif: Pour renommer des colonnes du schéma, procédez comme suit:
- Lorsque vous consultez le schéma, cliquez sur Transformer > Renommer.
- Dans le champ Renommer, saisissez un nouveau nom, puis cliquez sur Appliquer.
- Pour enregistrer le nouveau nom, cliquez sur Actualiser, puis sur Enregistrer.
Cliquez sur Suivant.
Facultatif: Configurer les propriétés avancées
Si vous connaissez la quantité de données que vous répliquez en une heure, vous pouvez sélectionner l'option appropriée.
Examiner l'évaluation
L'étape Examiner l'évaluation recherche les problèmes de schéma, les fonctionnalités manquantes ou les problèmes de connectivité qui se produisent pendant la réplication.
Sur la page Examiner l'évaluation, cliquez sur Afficher les mises en correspondance.
Si des problèmes surviennent, vous devez les résoudre pour pouvoir continuer.
Facultatif: Si vous avez renommé des colonnes lorsque vous avez sélectionné vos tables et transformations, vérifiez que les nouveaux noms sont corrects à cette étape.
Cliquez sur Suivant.
Afficher le résumé et déployer la tâche de réplication
Sur la page Examiner les détails de la tâche de réplication, examinez les paramètres, puis cliquez sur Déployer la tâche de réplication.
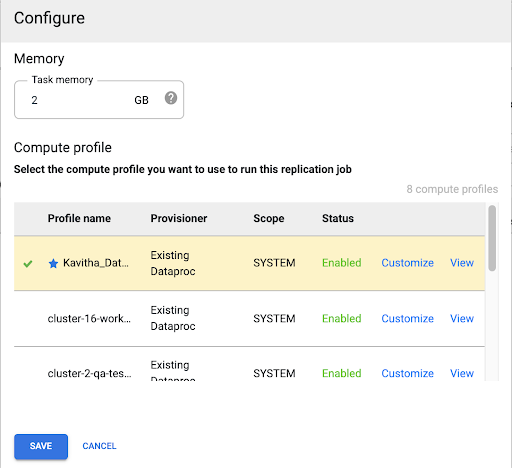
Sélectionner un profil Compute Engine
Après avoir déployé la tâche de réplication, cliquez sur Configurer depuis n'importe quelle page de l'interface Web Cloud Data Fusion.
Sélectionnez le profil Compute Engine que vous souhaitez utiliser pour exécuter cette tâche de réplication.
Cliquez sur Enregistrer.
Démarrer la tâche de réplication
- Pour exécuter la tâche de réplication, cliquez sur Démarrer.
Facultatif: Optimiser les performances
Par défaut, le plug-in est configuré pour des performances optimales. Pour en savoir plus sur les optimisations supplémentaires, consultez la section Arguments d'exécution.
Les performances de la communication SLT et Cloud Data Fusion dépendent des facteurs suivants:
- SLT sur le système source par rapport à un système SLT central dédié (option recommandée)
- Traitement des tâches en arrière-plan sur le système SLT
- Processus de travail de boîte de dialogue sur le système SAP source
- Nombre de processus de tâche en arrière-plan alloués à chaque ID de transfert de masse dans l'onglet Administration LTRC
- Paramètres LTRS
- Matériel (processeur et mémoire) du système SLT
- La base de données utilisée (par exemple, HANA, Sybase ou DB2)
- La bande passante Internet (connectivité entre le système SAP etGoogle Cloud via Internet)
- Utilisation (charge) préexistante sur le système
- Nombre de colonnes dans la table. Avec un plus grand nombre de colonnes, la réplication devient lente et la latence peut augmenter.
Les types de lecture suivants dans les paramètres LTRS sont recommandés pour les chargements initiaux:
| Système SLT | Système source | Type de table | Type de lecture recommandé [charge initiale] |
|---|---|---|---|
| SLT 3.0 autonome [DMIS 2018_1_752 SP 2] |
S/4 HANA 1909 | Transparent (petit/moyen) Transparent (grand) Tableau des clusters |
1 calcul de plage 1 calcul de plage 4 files d'attente d'expéditeurs |
| SLT intégré [S4CORE 104 HANA 1909] |
N/A | Transparent (petit/moyen) Transparent (grand) Tableau des clusters |
1 calcul de plage 1 calcul de plage 4 files d'attente d'expéditeurs |
| SLT 2.0 autonome [DMIS 2011_1_731 SP 17] |
ECC NW 7.02 | Transparent (petit/moyen) Transparent (grand) Tableau des clusters |
File d'attente des expéditeurs 5 File d'attente des expéditeurs 5 File d'attente des expéditeurs 4 |
| SLT intégré [DMIS 2011_1_700 SP 17] |
N/A | Transparent (petit/moyen) Transparent (grand) Tableau des clusters |
File d'attente des expéditeurs 5 File d'attente des expéditeurs 5 File d'attente des expéditeurs 4 |
- Pour la réplication, utilisez "Aucune plage" pour améliorer les performances :
- Les plages ne doivent être utilisées que lorsque des retards sont générés dans une table de journalisation avec une latence élevée.
- Utilisation d'un seul calcul de plage: le type de lecture pour la charge initiale n'est pas recommandé pour les systèmes SLT 2.0 et non HANA.
- Utilisation d'un seul calcul de plage: le type de lecture pour le chargement initial peut entraîner des enregistrements en double dans BigQuery.
- Les performances sont toujours meilleures lorsqu'un système SLT autonome est utilisé.
- Un système SLT autonome est toujours recommandé si l'utilisation des ressources du système source est déjà élevée.
Arguments d'exécution
snapshot.thread.count: transmet le nombre de threads à démarrer pour effectuer la charge de donnéesSNAPSHOT/INITIALen parallèle. Par défaut, il utilise le nombre de vCPU disponibles dans le cluster Dataproc où la tâche de réplication s'exécute.Recommandation: ne définissez ce paramètre que lorsque vous avez besoin d'un contrôle précis du nombre de threads parallèles (par exemple, pour réduire l'utilisation du cluster).
poll.file.count: transmet le nombre de fichiers à interroger à partir du chemin d'accès Cloud Storage fourni dans le champ Chemin d'accès GCS de la réplication de données de l'interface Web. Par défaut, la valeur est500par requête, mais en fonction de la configuration du cluster, elle peut être augmentée ou diminuée.Recommandation: Ne définissez ce paramètre que si vous avez des exigences strictes concernant le délai de réplication. Des valeurs plus faibles peuvent réduire le délai. Vous pouvez l'utiliser pour améliorer le débit (si l'appareil ne répond pas, utilisez des valeurs supérieures à la valeur par défaut).
bad.files.base.path: transmet le chemin d'accès Cloud Storage de base où tous les fichiers de données erronés ou défectueux détectés lors de la réplication sont copiés. Cela est utile lorsque des exigences strictes sont imposées pour l'audit des données et qu'un emplacement spécifique doit être utilisé pour enregistrer les transferts échoués.Par défaut, tous les fichiers défectueux sont copiés à partir du chemin Cloud Storage fourni dans le champ Chemin Cloud Storage de la réplication de données de l'interface Web.
Modèle de chemin d'accès final des fichiers de données défectueux:
gs://BASE_FILE_PATH/MASS_TRANSFER_ID/SOURCE_TABLE_NAME/bad_files/REPLICATION_JOB_NAME/REPLICATION_JOB_ID/BAD_FILE_NAME
Exemple :
gs://slt_to_cdf_bucket/001/MARA/bad_files/MaraRepl/05f97349-7398-11ec-9443-8 ac0640fc83c/20220205_1901205168830_DATA_INIT.xml
Les critères d'un fichier incorrect sont un fichier XML corrompu ou non valide, des valeurs PK manquantes ou un problème de non-concordance entre le type de données de champ.
Informations relatives à l'assistance
Produits et versions SAP compatibles
- Version SAP_BASIS 702, niveau de SP 0016 ou version ultérieure
- Version SAP_ABA 702, niveau de SP 0016 ou version ultérieure.
- Version DMIS 2011_1_700, niveau de correctif 0017 ou version ultérieure
Versions SLT compatibles
Les versions 2 et 3 de SLT sont compatibles.
Modèles de déploiement SAP compatibles
SLT en tant que système autonome ou intégré au système source.
Notes SAP à implémenter avant de commencer à utiliser le SLT
Si votre package d'assistance n'inclut pas de corrections de classe /UI2/CL_JSON pour PL 12 ou version ultérieure, implémentez la dernière note SAP pour les corrections de classe /UI2/CL_JSON, par exemple la note SAP 2798102 pour PL 12.
Recommandation: Implémentez les notes SAP recommandées par le rapport CNV_NOTE_ANALYZER_SLT en fonction de la condition du système central ou source. Pour en savoir plus, consultez la note SAP 3016862 (connexion SAP requise).
Si SAP est déjà configuré, aucune note supplémentaire ne doit être implémentée. Pour toute erreur ou tout problème spécifique, consultez la note SAP centrale de votre version SLT.
Limites concernant le volume de données ou la largeur des enregistrements
Le volume de données extrait et la largeur des enregistrements ne sont pas limités.
Débit attendu pour le plug-in SAP SLT Replication
Pour un environnement configuré conformément aux consignes de la section Optimiser les performances, le plug-in peut extraire environ 13 Go par heure pour le chargement initial et 3 Go par heure pour la réplication (CDC). Les performances réelles peuvent varier en fonction de la charge du système Cloud Data Fusion et SAP, ou du trafic réseau.
Prise en charge de l'extraction delta (données modifiées) SAP
L'extraction delta SAP est compatible.
Obligatoire: mise en relation de locataires pour les instances Cloud Data Fusion
Le peering de locataire est obligatoire lorsque l'instance Cloud Data Fusion est créée avec une adresse IP interne. Pour en savoir plus sur le peering de locataires, consultez la section Créer une instance privée.
Résoudre les problèmes
La tâche de réplication redémarre sans cesse
Si la tâche de réplication continue de redémarrer automatiquement, augmentez la mémoire du cluster de la tâche de réplication et réexécutez la tâche de réplication.
Dupliques dans le récepteur BigQuery
Si vous définissez le nombre de tâches parallèles dans les paramètres avancés du plug-in de réplication SAP SLT, une erreur se produit lorsque vos tables sont volumineuses, ce qui entraîne des colonnes en double dans le récepteur BigQuery.
Pour éviter ce problème, supprimez les tâches parallèles pour le chargement de données.
Scénarios d'erreur
Le tableau suivant répertorie certains messages d'erreur courants (le texte entre guillemets sera remplacé par les valeurs réelles au moment de l'exécution):
| ID du message | Message | Action recommandée |
|---|---|---|
CDF_SAP_SLT_01402 |
Service account type is not defined for
SERVICE_ACCT_NAME_FROM_UI. |
Assurez-vous que le chemin d'accès Cloud Storage fourni est correct. |
CDF_SAP_SLT_01403 |
Service account key provided is not valid due to error:
ROOT_CAUSE. Please provide a valid service account key for
service account type : SERVICE_ACCT_NAME_FROM_UI. |
Vérifiez la cause fondamentale affichée dans le message et prenez les mesures appropriées. |
CDF_SAP_SLT_01404 |
Mass Transfer ID could not be found. Please ensure that it exists
in given GCS Bucket. |
Vérifiez que l'ID de transfert de masse indiqué est au bon format. |
CDF_SAP_SLT_01502 |
The specified data replication GCS path 'slt_to_cdf_bucket_1' or
Mass Transfer ID '05C' could not be found. Please ensure that it exists in
GCS. |
Assurez-vous que le chemin d'accès à Cloud Storage fourni est correct. |
CDF_SAP_SLT_01400 |
Metadata file not found. The META_INIT.json file is not present or
file is present with invalid format. |
Vérifiez la cause fondamentale affichée dans le message et prenez les mesures appropriées. |
CDF_SAP_SLT_03408 |
Failed to start the event reader. |
Vérifiez la cause fondamentale affichée dans le message et prenez les mesures appropriées. |
CDF_SAP_SLT_03409 |
Error while processing TABLE_NAME file for source table
gs://CLOUD_STORAGE_BUCKET_NAME/MT_ID/TABLE_NAME
/FILE_NAME. Root cause: ROOT_CAUSE. |
Vérifiez la cause fondamentale affichée dans le message et prenez les mesures appropriées. |
CDF_SAP_SLT_03410 |
Failed to replicate data for source table TABLE_NAME
from file: gs://CLOUD_STORAGE_BUCKET_NAME/MT_ID/
TABLE_NAME/FILE_NAME. Root cause:
ROOT_CAUSE. |
Vérifiez la cause fondamentale affichée dans le message et prenez les mesures appropriées. |
CDF_SAP_SLT_03411 |
Failed data replication for source table TABLE_NAME.
Root cause: ROOT_CAUSE. |
Vérifiez la cause fondamentale affichée dans le message et prenez les mesures appropriées. |
CDF_SAP_SLT_03412 |
Failed to create target table for source table
TABLE_NAME. Root cause: ROOT_CAUSE. |
Vérifiez la cause fondamentale affichée dans le message et prenez les mesures appropriées. |
Mappage des types de données
Le tableau suivant présente le mappage entre les types de données utilisés dans les applications SAP et Cloud Data Fusion.
| Type de données SAP | Type ABAP | Description (SAP) | Type de données Cloud Data Fusion |
|---|---|---|---|
| Numérique | |||
| INT1 | b | Entier à 1 octet | int |
| INT2 | s | Entier à 2 octets | int |
| INT4 | i | Entier à 4 octets | int |
| INT8 | 8 | Entier à 8 octets | long |
| DÉC | p | Nombre compressé au format BCD (DEC) | decimal |
| DF16_DEC DF16_RAW |
a | Virgule flottante décimale 8 octets IEEE 754r | decimal |
| DF34_DEC DF34_RAW |
e | Virgule flottante décimale 16 octets IEEE 754r | decimal |
| FLTP | f | Nombre à virgule flottante binaire | double |
| Caractère | |||
| CHAR LCHR |
c | Chaîne de caractères | string |
| SSTRING GEOM_EWKB |
chaîne | Chaîne de caractères | string |
| Chaîne GEOM_EWKB |
chaîne | Chaîne de caractères CLOB | bytes |
| NUMC ACCP |
n | Texte numérique | string |
| Byte | |||
| RAW LRAW |
x | Données binaires | bytes |
| RAWSTRING | xstring | BLOB de chaîne d'octets | bytes |
| Date/Heure | |||
| DATS | j | Date | date |
| Tims | t | Heure | time |
| TIMESTAMP | utcl | ( Utclong ) Code temporel |
timestamp |
Étape suivante
- Apprenez-en plus sur Cloud Data Fusion.
- En savoir plus sur SAP sur Google Cloud