En esta página, se describe cómo ejecutar una canalización en Cloud Data Fusion en un clúster existente de Dataproc.
De forma predeterminada, Cloud Data Fusion crea clústeres efímeros para cada canalización: crea un clúster al comienzo de la ejecución de la canalización y, luego, lo borra cuando la finaliza. Aunque este comportamiento ahorra costos porque garantiza que solo se creen recursos cuando sea necesario, este comportamiento predeterminado podría no ser conveniente en las siguientes situaciones:
Si el tiempo que lleva crear un clúster nuevo para cada canalización es adecuado para tu caso de uso.
Si tu organización requiere que la creación del clúster se administre de forma centralizada. Por ejemplo, cuando deseas aplicar ciertas políticas para todos los clústeres de Dataproc.
En estos casos, ejecuta las canalizaciones en un clúster existente con los siguientes pasos.
Antes de comenzar
Debes tener lo siguiente:
Una instancia de Cloud Data Fusion.
Un clúster de Dataproc existente.
Si ejecutas las canalizaciones en la versión 6.2 de Cloud Data Fusion, usa una imagen de Dataproc anterior que se ejecute con Hadoop 2.x (por ejemplo, 1.5-debian10) o actualiza a la versión más reciente de Cloud Data Fusion.
Conéctate al clúster existente
En las versiones 6.2.1 y posteriores de Cloud Data Fusion, puedes conectarte a un clúster existente de Dataproc cuando creas un perfil nuevo de Compute Engine.
Ve a tu instancia:
En la consola de Google Cloud, ve a la página de Cloud Data Fusion.
Para abrir la instancia en Cloud Data Fusion Studio, haz clic en Instancias y, luego, en Ver instancia.
Haz clic en Administrador del sistema.
Haz clic en la pestaña Configuración.
Haz clic en Perfiles de procesamiento del sistema.
Haz clic en Crear un perfil nuevo. Se abrirá una página de aprovisionadores.
Haga clic en Existing Dataproc.
Ingresa la información del perfil, el clúster y la supervisión.
Haz clic en Crear.
Configura tu canalización para usar el perfil personalizado
Ve a tu instancia:
En la consola de Google Cloud, ve a la página de Cloud Data Fusion.
Para abrir la instancia en Cloud Data Fusion Studio, haz clic en Instancias y, luego, en Ver instancia.
Ve a tu canalización en la página de Studio.
Haz clic en Configurar.
Haz clic en Compute config.
Haz clic en el perfil que creaste.
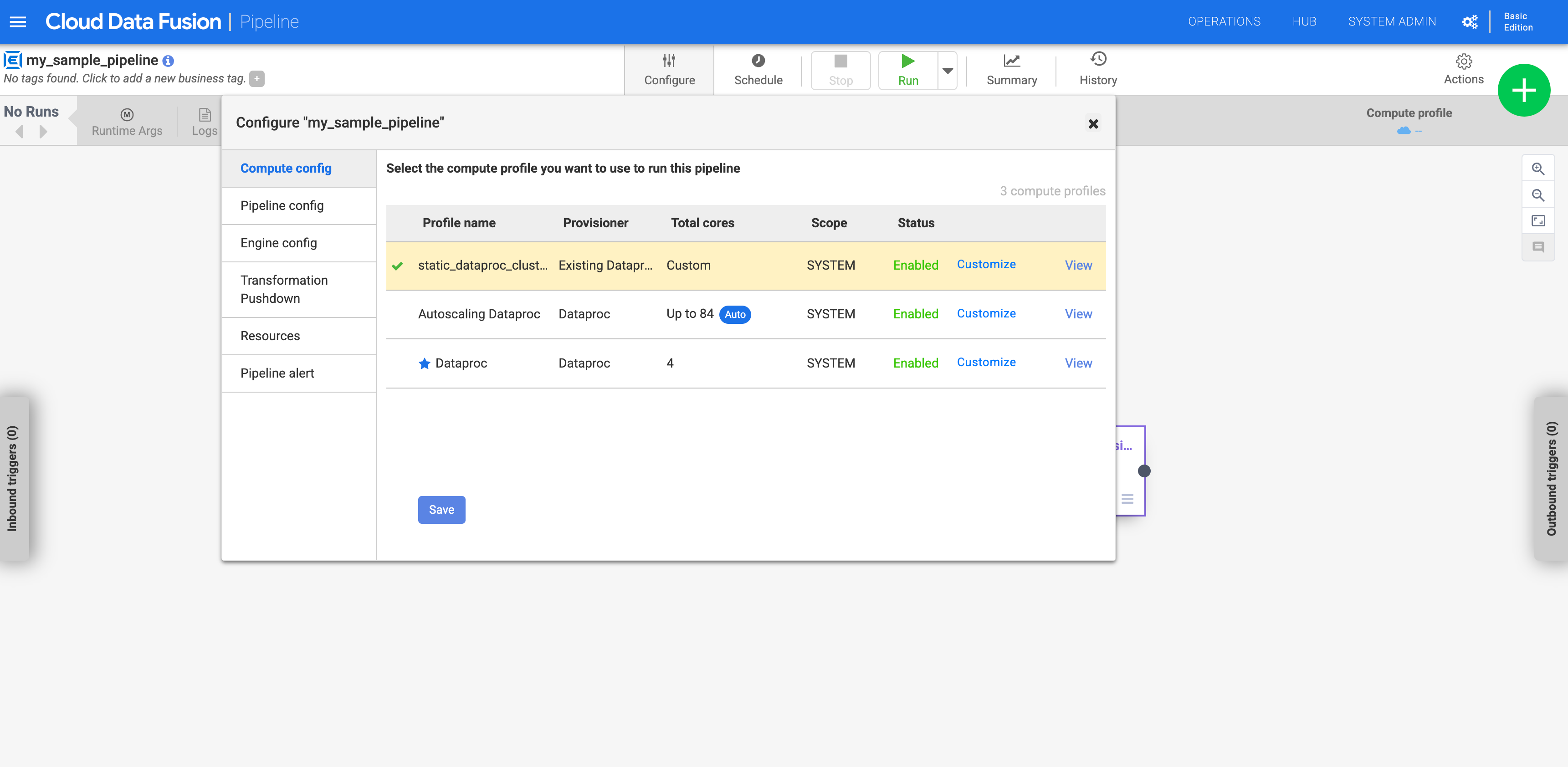
Figura 1: Haz clic en el perfil personalizado Ejecutar la canalización Se ejecuta en el clúster de Dataproc existente.
¿Qué sigue?
- Obtén más información para configurar clústeres.
- Soluciona problemas relacionados con la eliminación de clústeres.