本頁面說明如何在 Cloud Data Fusion 複製工作中傳遞執行階段引數。
將 Debezium 引數傳遞至複製工作
如要將引數從 Debezium 應用程式傳遞至 Cloud Data Fusion 中的 MySQL 或 SQL Server 複製工作,請使用前置字串 source.connector 指定執行階段引數。
控制台
前往您的執行個體:
在 Google Cloud 控制台中,前往 Cloud Data Fusion 頁面。
如要在 Cloud Data Fusion Studio 中開啟執行個體,請依序按一下「Instances」和「View instance」。
依序按一下 「選單」圖示 >「控制中心」。
找出複寫工作的「應用程式」,然後按一下 「偏好設定」。「Preferences」視窗隨即開啟。
在「Key」欄位中,請在複本工作執行階段引數前方加上前置字串
source.connector。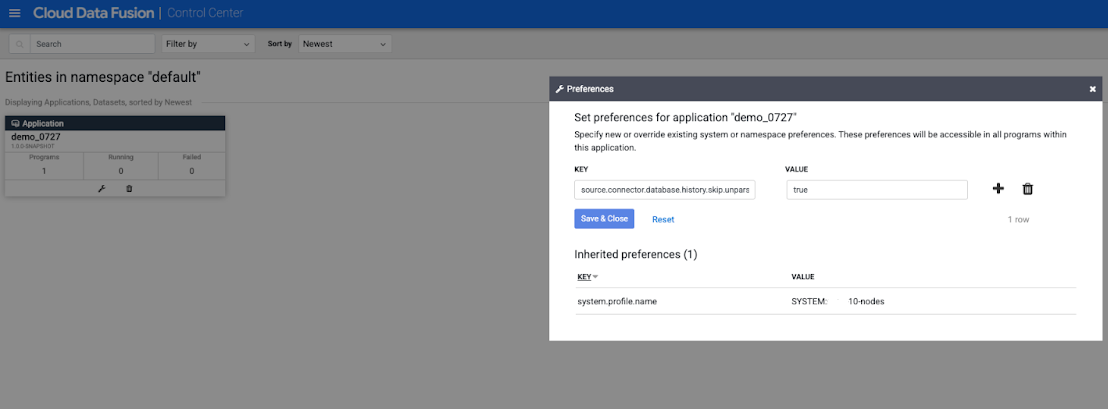
按一下「Save & Close」。
REST API
如要使用 REST API 設定執行階段引數,請參閱 CDAP 偏好設定微服務參考資料。
設定 JDBC 參數
如要將 JDBC 參數傳遞至 MySQL 或 SQL Server 複製工作,請指定前面加上 source.connector.database 的執行階段引數。
舉例來說,如要將 JDBC 參數 sessionVariables 設為 MAX_EXECUTION_TIME=43200000,請使用鍵 source.connector.database.sessionVariables 和值 MAX_EXECUTION_TIME=43200000設定執行階段引數。
如要設定多個 JDBC 參數,請為每個參數設定執行階段引數。舉例來說,如要設定 JDBC 參數 encrypt=true&trustServerCertificate=true,請傳遞下列引數:
| 鍵 | 值 |
|---|---|
source.connector.database.encrypt |
true |
source.connector.database.trustServerCertificate |
true |
設定主鍵參數
要複製的來源資料表必須具備主鍵。只有在 Oracle 是來源資料庫時,才需要嚴格遵守這項規定。針對 SQL Server 和 MySQL 來源,您可以指定自訂主鍵,即使來源資料表沒有主鍵也一樣。
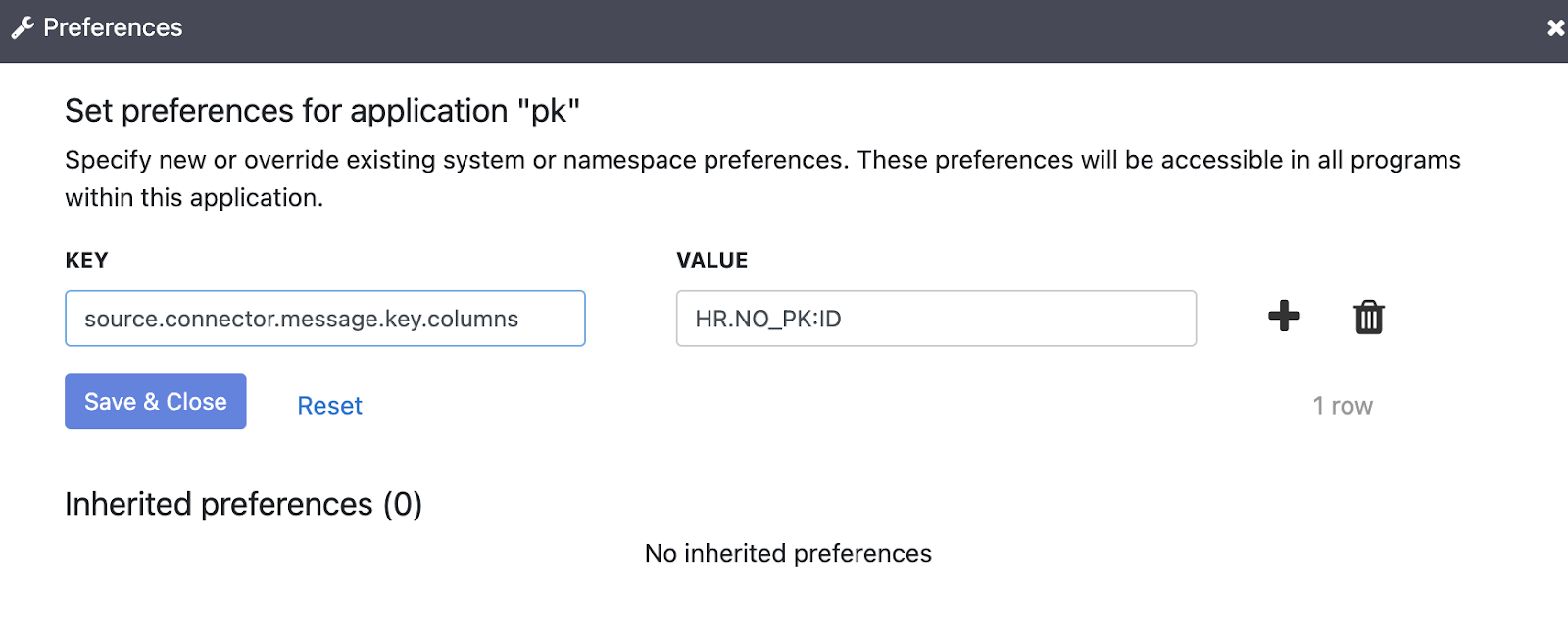
使用以下執行階段引數設定 key 參數:
source.connector.message.key.columns = SCHEMA.TABLE:KEY_COLUMN
更改下列內容:
- SCHEMA:來源結構定義的名稱。
- TABLE:來源資料表名稱。
- KEY_COLUMN:包含安全金鑰的資料欄。
您可以使用 key 屬性為多個資料表設定主鍵。以下範例說明如何為資料表 inventory.customers 和 purchase.orders 設定索引鍵:
source.connector.message.key.columns = inventory.customers:pk1,pk2;purchase.orders:pk3,pk4
在 SQL Server 複製作業中,為快照設定隔離模式
如要進一步瞭解隔離模式的執行階段引數,請參閱「SQL Server 複製作業中的隔離等級」。
後續步驟
- 進一步瞭解 Cloud Data Fusion 中的複寫功能。
- 請參閱 Replication API 參考資料。