本頁面說明如何在 Cloud Data Fusion 中,將轉換作業執行至 BigQuery 而非 Spark。
詳情請參閱轉換推送總覽。
事前準備
轉換推送功能適用於 6.5.0 以上版本。如果管道在舊版環境中執行,您可以將執行個體升級至最新版本。
在管道中啟用轉換推送功能
控制台
如要在已部署的管道中啟用轉換推送功能,請執行下列操作:
前往您的執行個體:
在 Google Cloud 控制台中,前往 Cloud Data Fusion 頁面。
如要在 Cloud Data Fusion Studio 中開啟執行個體,請依序按一下「Instances」和「View instance」。
依序按一下「選單」圖示 > 「清單」。
系統會開啟已部署管道分頁。
按一下所需的已部署管道,即可在 Pipeline Studio 中開啟。
依序按一下「設定」>「轉換推送」。
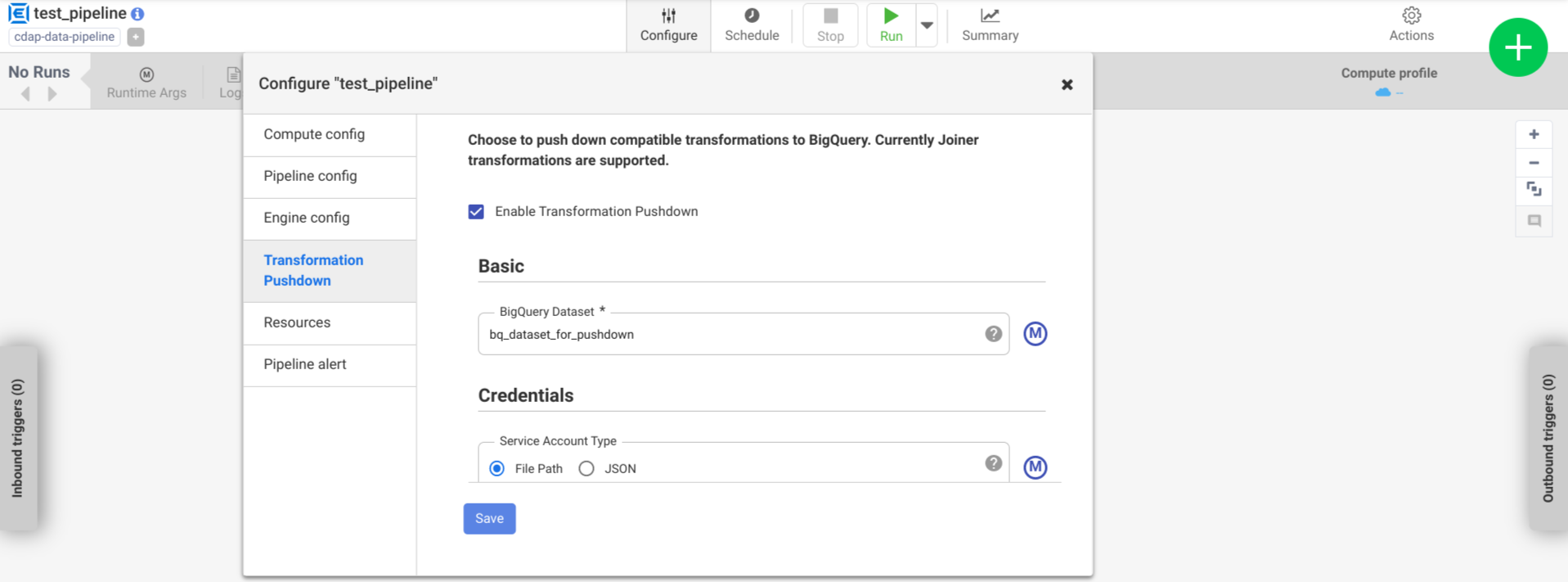
按一下「啟用轉換推送」。
在「資料集」欄位中輸入 BigQuery 資料集名稱。
選用:如要使用巨集,請按一下「M」。詳情請參閱「資料集」。
選用:視需要設定選項。
按一下 [儲存]。
選用設定
.| 屬性 | 支援巨集 | 支援的 Cloud Data Fusion 版本 | 說明 |
|---|---|---|---|
| 使用連線 | 否 | 6.7.0 以上版本 | 是否使用現有連結。 |
| 連線 | 是 | 6.7.0 以上版本 | 連線的名稱。這個連線會提供專案和服務帳戶資訊。 選用:使用巨集函式 ${conn(connection_name)}。 |
| 資料集專案 ID | 是 | 6.5.0 | 如果資料集位於 BigQuery 工作執行的專案以外,請輸入資料集的專案 ID。如果未提供任何值,系統會預設使用執行工作所在的專案 ID。 |
| 專案 ID | 是 | 6.5.0 | Google Cloud 專案 ID。 |
| 服務帳戶類型 | 是 | 6.5.0 | 選取下列其中一個選項:
|
| 服務帳戶檔案路徑 | 是 | 6.5.0 | 本機檔案系統中用於授權的服務帳戶金鑰路徑。在 Dataproc 叢集中執行時,系統會將其設為 auto-detect。在其他叢集中執行時,檔案必須位於叢集中的每個節點。預設為 auto-detect。 |
| 服務帳戶 JSON | 是 | 6.5.0 | 服務帳戶 JSON 檔案的內容。 |
| 臨時值區名稱 | 是 | 6.5.0 | 儲存暫存資料的 Cloud Storage 值區。如果不存在,系統會自動建立,但不會自動刪除。Cloud Storage 資料載入 BigQuery 後會遭到刪除。如果未提供這個值,系統會建立一個專屬值區,然後在管道執行完畢後刪除。服務帳戶必須具備在已設定的專案中建立值區的權限。 |
| 位置 | 是 | 6.5.0 | 建立 BigQuery 資料集的位置。如果資料集或暫時性資料夾已存在,系統會忽略這個值。預設值為 US 多區域。 |
| 加密金鑰名稱 | 是 | 6.5.1/0.18.1 | 客戶管理式加密金鑰 (CMEK):用於加密寫入外掛程式建立的任何 Bucket、資料集或資料表的資料。如果已存在分層、資料集或資料表,系統會忽略這個值。 |
| 在完成後保留 BigQuery 資料表 | 是 | 6.5.0 | 是否保留管道執行期間建立的所有 BigQuery 臨時資料表,以便進行偵錯和驗證。預設值為「否」。 |
| 臨時資料表 TTL (以小時計) | 是 | 6.5.0 | 為 BigQuery 臨時資料表設定資料表 TTL (以小時為單位)。在管道遭到取消,且清理程序遭到中斷的情況下,這項功能可做為安全防護措施 (例如,如果執行叢集突然關閉)。將這個值設為 0 會停用資料表 TTL。預設值為 72 (3 天)。 |
| 工作優先順序 | 是 | 6.5.0 | 用於執行 BigQuery 工作的優先順序。選取下列其中一個選項:
|
| 強制推送的階段 | 是 | 6.7.0 | 一律在 BigQuery 中執行的支援階段。每個階段名稱必須獨立成行。 |
| 略過推送下推的階段 | 是 | 6.7.0 | 在 BigQuery 中永不執行的支援階段。每個階段名稱都必須獨立成行。 |
| 使用 BigQuery Storage Read API | 是 | 6.7.0 | 在管道執行期間,從 BigQuery 擷取記錄時是否要使用 BigQuery Storage Read API。這個選項可以改善轉換推送的效能,但會產生額外費用。這需要在執行環境中安裝 Scala 2.12。 |
在記錄中監控成效變化
管道執行階段記錄包含訊息,顯示在 BigQuery 中執行的 SQL 查詢。您可以監控 pipeline 中哪些階段會推送至 BigQuery。
以下範例顯示管道執行開始時的記錄項目。記錄指出管道中的 JOIN 作業已推送至 BigQuery 執行:
INFO [Driver:i.c.p.g.b.s.BigQuerySQLEngine@190] - Validating join for stage 'Users' can be executed on BigQuery: true
DEBUG [batch-sql-engine-adapter:i.c.c.e.s.b.BatchSQLEngineAdapter@131] - Starting push for dataset 'UserProfile'
DEBUG [batch-sql-engine-adapter:i.c.c.e.s.b.BatchSQLEngineAdapter@131] - Starting push for dataset 'UserDetails'
DEBUG [batch-sql-engine-adapter:i.c.c.e.s.b.BatchSQLEngineAdapter@292] - Starting join for dataset 'Users'
INFO [Driver:i.c.p.g.b.s.BigQuerySQLEngine@190] - Validating join for stage 'UserPurchases' can be executed on BigQuery: true
DEBUG [batch-sql-engine-adapter:i.c.c.e.s.b.BatchSQLEngineAdapter@131] - Starting push for dataset 'Purchases'
DEBUG [batch-sql-engine-adapter:i.c.c.e.s.b.BatchSQLEngineAdapter@292] - Starting join for dataset 'UserPurchases'
INFO [Driver:i.c.p.g.b.s.BigQuerySQLEngine@190] - Validating join for stage 'MostPopularNames' can be executed on BigQuery: true
DEBUG [batch-sql-engine-adapter:i.c.c.e.s.b.BatchSQLEngineAdapter@131] - Starting push for dataset 'FirstNameCounts'
DEBUG [batch-sql-engine-adapter:i.c.c.e.s.b.BatchSQLEngineAdapter@292] - Starting join for dataset 'MostPopularNames'
DEBUG [batch-sql-engine-adapter:i.c.c.e.s.b.BatchSQLEngineAdapter@193] - Starting pull for dataset 'MostPopularNames'
以下範例顯示會為推送執行作業中涉及的每個資料集指派的資料表名稱:
INFO [batch-sql-engine-adapter:i.c.p.g.b.s.BigQuerySQLEngine@145] - Executing Push operation for dataset Purchases stored in table <TABLE_ID>
INFO [batch-sql-engine-adapter:i.c.p.g.b.s.BigQuerySQLEngine@145] - Executing Push operation for dataset UserDetails stored in table <TABLE_ID>
INFO [batch-sql-engine-adapter:i.c.p.g.b.s.BigQuerySQLEngine@145] - Executing Push operation for dataset FirstNameCounts stored in table <TABLE_ID>
INFO [batch-sql-engine-adapter:i.c.p.g.b.s.BigQuerySQLEngine@145] - Executing Push operation for dataset UserProfile stored in table <TABLE_ID>
隨著執行作業持續進行,記錄會顯示推送階段的完成情形,並最終執行 JOIN 作業。例如:
DEBUG [batch-sql-engine-adapter:i.c.c.e.s.b.BatchSQLEngineAdapter@133] - Completed push for dataset 'UserProfile'
DEBUG [batch-sql-engine-adapter:i.c.c.e.s.b.BatchSQLEngineAdapter@133] - Completed push for dataset 'UserDetails'
DEBUG [batch-sql-engine-adapter:i.c.p.g.b.s.BigQuerySQLEngine@235] - Executing join operation for dataset Users
INFO [batch-sql-engine-adapter:i.c.p.g.b.s.BigQueryJoinDataset@118] - Creating table `<TABLE_ID>` using job: <JOB_ID> with SQL statement: SELECT `UserDetails`.id AS `id` , `UserDetails`.first_name AS `first_name` , `UserDetails`.last_name AS `last_name` , `UserDetails`.email AS `email` , `UserProfile`.phone AS `phone` , `UserProfile`.profession AS `profession` , `UserProfile`.age AS `age` , `UserProfile`.address AS `address` , `UserProfile`.score AS `score` FROM `your_project.your_dataset.<DATASET_ID>` AS `UserProfile` LEFT JOIN `your_project.your_dataset.<DATASET_ID>` AS `UserDetails` ON `UserProfile`.id = `UserDetails`.id
INFO [batch-sql-engine-adapter:i.c.p.g.b.s.BigQueryJoinDataset@151] - Created BigQuery table `<TABLE_ID>
INFO [batch-sql-engine-adapter:i.c.p.g.b.s.BigQuerySQLEngine@245] - Executed join operation for dataset Users
所有階段都完成後,系統會顯示訊息,指出 Pull 作業已完成。這表示 BigQuery 匯出程序已觸發,且系統會在匯出工作開始後開始將記錄讀取至管道。例如:
DEBUG [batch-sql-engine-adapter:i.c.c.e.s.b.BatchSQLEngineAdapter@196] - Completed pull for dataset 'MostPopularNames'
如果管道執行作業發生錯誤,記錄檔會說明這些錯誤。
如要進一步瞭解 BigQuery JOIN 作業的執行情形,例如資源使用率、執行時間和錯誤原因,您可以使用工作 ID 查看 BigQuery 工作資料,工作 ID 會顯示在工作記錄中。
查看管道指標
如要進一步瞭解 Cloud Data Fusion 為在 BigQuery 中執行的管道部分提供的各種指標,請參閱「BigQuery 下推管道指標」。
後續步驟
- 進一步瞭解 Cloud Data Fusion 中的轉換推送。