為改善資料管道的效能,您可以將部分轉換作業推送至 BigQuery,而非 Apache Spark。啟用「轉換下推」設定之後,Cloud Data Fusion 資料管道中的作業就會推送至 BigQuery,做為執行作業引擎。因此,作業及其資料會轉移至 BigQuery,並在該處執行作業。
轉換推送功能可改善包含多個複雜 JOIN 作業或其他支援轉換的管道效能。在 BigQuery 中執行某些轉換作業的速度,可能比在 Spark 中執行更快。
系統會在 Spark 中執行不支援的轉換作業和所有預覽轉換作業。
支援的轉換
轉換推送功能適用於 Cloud Data Fusion 6.5.0 以上版本,但下列部分轉換功能僅支援較新版本。
JOIN 項作業
在 Cloud Data Fusion 6.5.0 以上版本中,轉換推送功能可用於
JOIN作業。支援基本 (按鍵) 和進階
JOIN作業。彙整必須有兩個輸入階段,才能在 BigQuery 中執行。
如要將一或多個輸入載入至記憶體,則會在 Spark 中執行彙整作業,而非在 BigQuery 中執行,除非符合下列情況:
- 如果彙整作業的任何輸入內容已推送至下層。
- 如果您已將彙整作業設定為在 SQL Engine 中執行 (請參閱「要強制執行的階段」選項)。
BigQuery 接收器
在 Cloud Data Fusion 6.7.0 以上版本中,轉換下推功能適用於 BigQuery 匯出端。
如果 BigQuery Sink 會接著在 BigQuery 中執行的階段,則會直接在 BigQuery 中執行將記錄寫入 BigQuery 的作業。
如要透過這個接收器提升效能,您需要:
- 服務帳戶必須具備在 BigQuery 匯出端使用的資料集中建立及更新資料表的權限。
- 用於轉換推送和 BigQuery 接收器的資料集必須儲存在相同的位置。
- 作業必須是下列其中一種:
Insert(不支援Truncate Table選項)UpdateUpsert
GROUP BY 匯總
在 Cloud Data Fusion 6.7.0 以上版本中,轉換推送功能可用於 GROUP BY 匯總。
BigQuery 中的 GROUP BY 匯總可用於下列作業:
AvgCollect List(空值會從輸出陣列中移除)Collect Set(空值會從輸出陣列中移除)ConcatConcat DistinctCountCount DistinctCount NullsLogical AndLogical OrMaxMinStandard DeviationSumSum of SquaresCorrected Sum of SquaresVarianceShortest StringLongest String
在下列情況下,GROUP BY 匯總作業會在 BigQuery 中執行:
- 它會接續已推送的階段。
- 您已將其設為在 SQL Engine 中執行 (請參閱「要強制執行的階段」選項)。
刪除重複的匯總
在 Cloud Data Fusion 6.7.0 以上版本中,轉換推送功能可用於以下作業的去重匯總:
- 未指定篩選器作業
ANY(所需欄位的非空值)MIN(指定欄位的最低值)MAX(指定欄位的最大值)
不支援下列作業:
FIRSTLAST
在下列情況下,SQL 引擎會執行去重匯總作業:
- 它會接續已推送的階段。
- 您已將其設為在 SQL Engine 中執行 (請參閱「要強制執行的階段」選項)。
BigQuery 來源下推
BigQuery 來源推送功能適用於 Cloud Data Fusion 6.8.0 以上版本。
如果 BigQuery 來源接著 BigQuery 推送相容的階段,管道就能在 BigQuery 中執行所有相容的階段。
Cloud Data Fusion 會複製執行 BigQuery 內管道所需的記錄。
使用 BigQuery 來源推送功能時,系統會保留資料表分割和叢集屬性,讓您使用這些屬性來進一步改善作業 (例如彙整)。
額外規定
如要使用 BigQuery 來源下推功能,必須符合下列條件:
為 BigQuery 轉換推送功能設定的服務帳戶必須具備讀取 BigQuery 來源資料集資料表的權限。
在 BigQuery 來源中使用的資料集,以及為轉換推送功能設定的資料集,必須儲存在相同的位置。
時段匯總
在 Cloud Data Fusion 6.9 以上版本中,您可以為視窗匯總作業使用轉換推送功能。BigQuery 中的時間區塊匯總功能支援下列作業:
RankDense RankPercent RankN tileRow NumberMedianContinuous PercentileLeadLagFirstLastCumulative distributionAccumulate
在下列情況下,BigQuery 會執行時間窗口匯總:
- 它會接續已推送的階段。
- 您已將其設為在 SQL Engine 中執行 (請參閱「要強制推送的階段」選項)。
Wrangler 篩選器推送
Wrangler 篩選器推送功能適用於 Cloud Data Fusion 6.9 以上版本。
使用 Wrangler 外掛程式時,您可以將篩選器 (稱為 Precondition 運算) 推送至 BigQuery 執行,而非在 Spark 中執行。
篩選器推送功能僅支援先決條件的 SQL 模式,這也是在 6.9 版中發布的功能。在這個模式下,外掛程式會接受 ANSI 標準 SQL 中的前置條件運算式。
如果 SQL 模式用於前置條件,則會停用 Wrangler 外掛程式的指令和使用者定義的指令,因為 SQL 模式不支援前置條件。
啟用轉換推送功能後,如果 Wrangler 外掛程式有多個輸入內容,則不支援預設條件的 SQL 模式。如果與多個輸入內容搭配使用,這個含有 SQL 篩選條件的 Wrangler 階段會在 Spark 中執行。
在下列情況下,BigQuery 會執行篩選器:
- 它會接續已推送的階段。
- 您已將其設為在 SQL Engine 中執行 (請參閱「要強制推送的階段」選項)。
指標
如要進一步瞭解 Cloud Data Fusion 為在 BigQuery 中執行的管道部分提供的各種指標,請參閱「BigQuery 下推管道指標」。
使用轉換推送功能的時機
在 BigQuery 中執行轉換作業時,需要進行以下操作:
- 將記錄寫入 BigQuery,適用於管道中支援的階段。
- 在 BigQuery 中執行支援的階段。
- 在執行支援的轉換作業後,從 BigQuery 讀取記錄 (除非後續有 BigQuery Sink)。
視資料集大小而定,可能會產生大量網路額外負擔,這可能會對啟用轉換推送功能時的整體管道執行時間造成負面影響。
由於網路開銷,我們建議在下列情況下使用轉換推送功能:
- 系統會依序執行多個支援的作業 (各階段之間沒有步驟)。
- 相較於 Spark,BigQuery 執行轉換作業所帶來的效能提升,會抵銷資料移入 BigQuery 和可能從 BigQuery 移出的延遲時間。
運作方式
當您執行使用轉換下推功能的管道時,Cloud Data Fusion 會在 BigQuery 中執行支援的轉換階段。管道中的所有其他階段都會在 Spark 中執行。
執行轉換作業時:
Cloud Data Fusion 會將記錄寫入 Cloud Storage,然後執行 BigQuery 載入工作,將輸入資料集載入 BigQuery。
JOIN作業和支援的轉換作業會以 BigQuery 工作形式使用 SQL 陳述式執行。如果在執行工作後需要進一步處理,記錄可從 BigQuery 匯出至 Spark。不過,如果啟用「Attempt direct copy to BigQuery sinks」選項,且 BigQuery Sink 會追蹤在 BigQuery 中執行的階段,則記錄會直接寫入目的地 BigQuery Sink 表格。
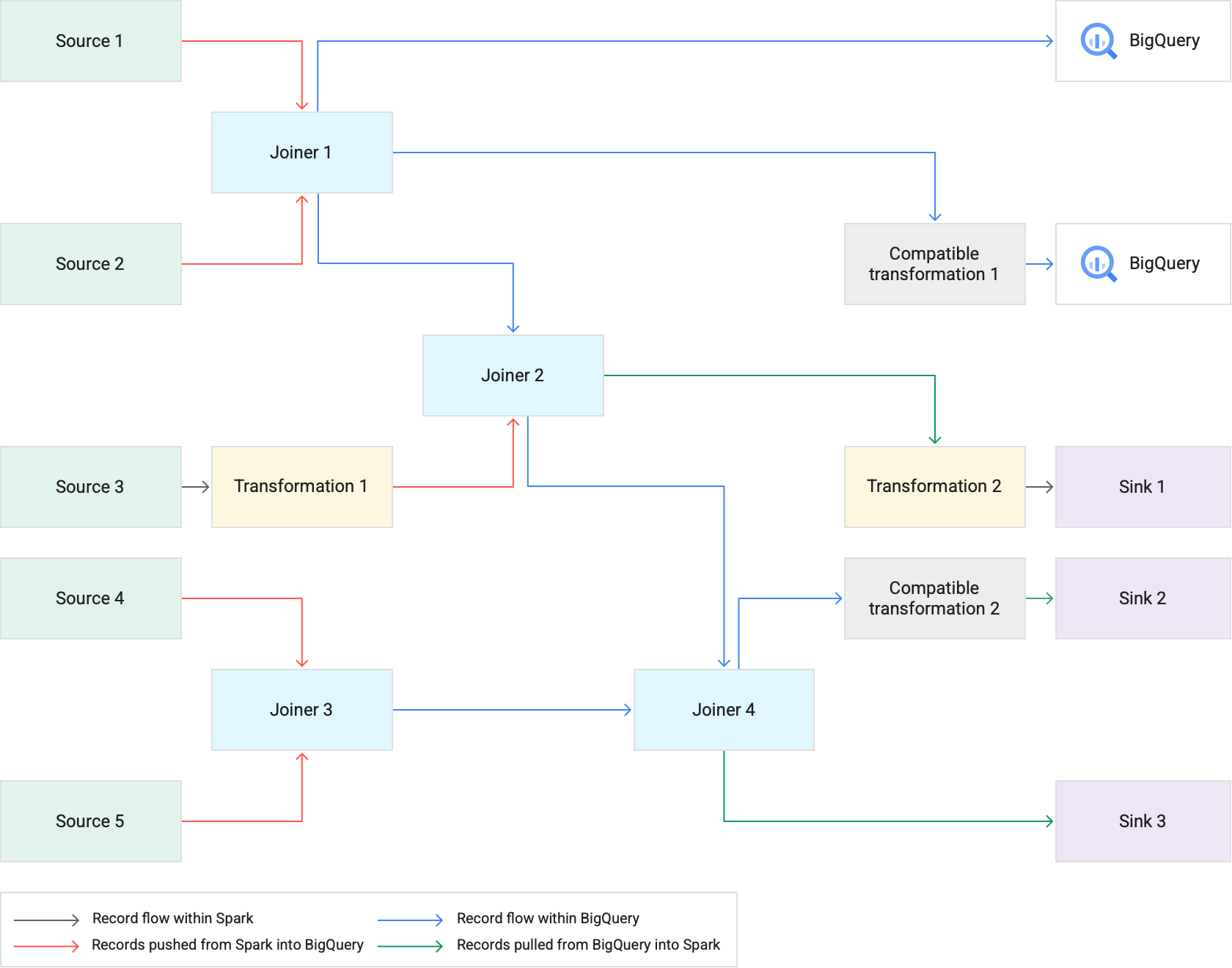
下圖說明轉換下推如何在 BigQuery 中執行支援的轉換,而非在 Spark 中執行。
最佳做法
調整叢集和執行緒大小
如要改善管道中的資源管理,請執行下列操作:
為工作負載使用正確的叢集工作站 (節點) 數量。換句話說,您可以充分利用執行個體的可用 CPU 和記憶體,充分發揮已佈建 Dataproc 叢集的效益,同時享有 BigQuery 執行大型工作時的執行速度。
使用自動調整資源叢集,改善管道中的平行處理作業。
在 pipeline 執行期間,在記錄從 BigQuery 推送或拉取的管道階段調整資源設定。
建議:請嘗試增加執行緒資源的 CPU 核心數量 (最多可達工作站節點使用的 CPU 核心數量)。執行緒會在資料進出 BigQuery 時,在序列化和反序列化步驟中最佳化 CPU 使用情形。詳情請參閱「叢集大小」。
在 BigQuery 中執行轉換作業的好處是,管道可以在較小的 Dataproc 叢集上執行。如果管道中資源密集度最高的作業是彙整,您可以嘗試使用較小的叢集大小,因為現在是在 BigQuery 中執行密集的 JOIN 作業,因此可以降低整體運算成本。
運用 BigQuery Storage Read API 更快擷取資料
BigQuery 執行轉換作業後,管道可能會有其他階段要在 Spark 中執行。在 Cloud Data Fusion 6.7.0 以上版本中,轉換下推功能支援 BigQuery Storage Read API,可縮短延遲時間,並加快 Spark 中的讀取作業。這麼做可以縮短管道的整體執行時間。
API 會並行讀取記錄,因此建議您據此調整執行緒大小。如果在 BigQuery 中執行資源密集的作業,請減少執行緒的記憶體配置,以便在管道執行時改善平行處理 (請參閱「調整叢集和執行緒大小」)。
BigQuery Storage Read API 預設為停用狀態。您可以在已安裝 Scala 2.12 的執行環境中啟用此功能 (包括 Dataproc 2.0 和 Dataproc 1.5)。
考量資料集大小
請考量 JOIN 作業中的資料集大小。對於產生大量輸出記錄的 JOIN 作業 (例如類似交叉 JOIN 作業的作業),產生的資料集大小可能會比輸入資料集大上好幾個數量級。此外,請考量在整體管道效能方面,當這些記錄發生額外的 Spark 處理作業 (例如轉換或匯出) 時,將這些記錄拉回 Spark 的額外負擔。
降低資料偏差
針對資料偏差嚴重的問題執行 JOIN 作業,可能會導致 BigQuery 工作超出資源使用率限制,進而導致 JOIN 作業失敗。如要避免這種情況,請前往 Joiner 外掛程式設定,並在「Skewed Input Stage」欄位中找出偏差的輸入內容。這樣一來,Cloud Data Fusion 就能以減少 BigQuery 陳述式超出限制的風險的方式安排輸入內容。