Cette page explique comment exécuter des transformations vers BigQuery au lieu de Spark dans Cloud Data Fusion.
Pour en savoir plus, consultez la présentation du pushdown de transformation.
Avant de commencer
Le pushdown de transformation est disponible dans les versions 6.5.0 et ultérieures. Si votre pipeline s'exécute dans un environnement antérieur, vous pouvez mettre à niveau votre instance vers la dernière version.
Activer le pushdown de transformation sur votre pipeline
Console
Pour activer le pushdown de transformation sur un pipeline déployé, procédez comme suit:
Accédez à votre instance :
Dans la console Google Cloud, accédez à la page Cloud Data Fusion.
Pour ouvrir l'instance dans Cloud Data Fusion Studio, cliquez sur Instances, puis sur Afficher l'instance.
Cliquez sur Menu > Liste.
L'onglet "Pipeline déployé" s'ouvre.
Cliquez sur le pipeline déployé souhaité pour l'ouvrir dans Pipeline Studio.
Cliquez sur Configurer > Pushdown de transformation.
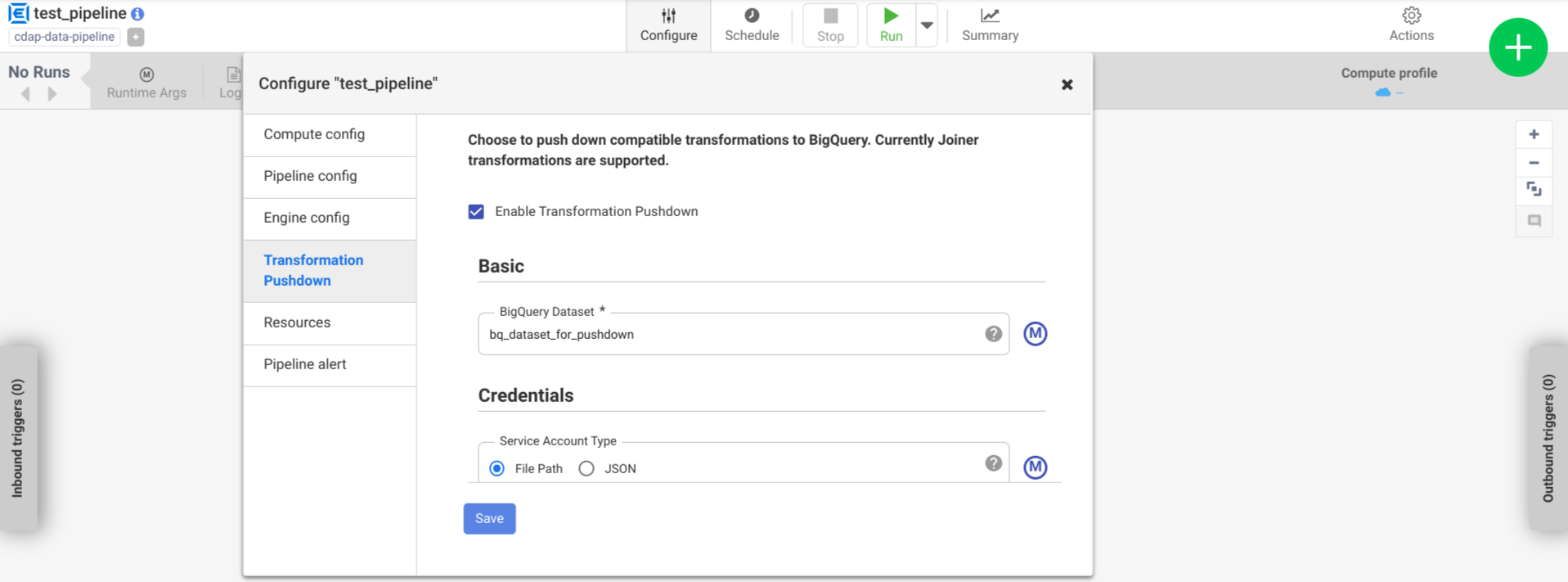
Cliquez sur Activer le pushdown de transformation.
Dans le champ Ensemble de données, saisissez le nom d'un ensemble de données BigQuery.
(Facultatif) Pour utiliser une macro, cliquez sur M. Pour en savoir plus, consultez la section Ensembles de données.
Facultatif: configurez les options, si nécessaire.
Cliquez sur Enregistrer.
Configurations facultatives
.| Propriété | Compatible avec les macros | Versions Cloud Data Fusion compatibles | Description |
|---|---|---|---|
| Utiliser la connexion | Non | 6.7.0 et versions ultérieures | Indique si vous souhaitez utiliser une connexion existante. |
| Connexion | Oui | 6.7.0 et versions ultérieures | Nom de la connexion. Cette connexion fournit des informations sur le projet et le compte de service. Facultatif: utilisez la macro de la fonction, ${conn(connection_name)}. |
| ID du projet de l'ensemble de données | Oui | 6.5.0 | Si l'ensemble de données se trouve dans un projet différent de celui dans lequel s'exécute la tâche BigQuery, saisissez l'ID de projet de l'ensemble de données. Si aucune valeur n'est fournie, l'ID de projet dans lequel la tâche s'exécute est utilisé par défaut. |
| ID du projet | Oui | 6.5.0 | ID du Google Cloud projet. |
| Type de compte de service | Oui | 6.5.0 | Sélectionnez l'une des options suivantes:
|
| Chemin d'accès au fichier du compte de service | Oui | 6.5.0 | Chemin d'accès au système de fichiers local de la clé de compte de service utilisée pour l'autorisation. Il est défini sur auto-detect lors de l'exécution sur un cluster Dataproc. Lors de l'exécution sur d'autres clusters, le fichier doit être présent sur tous les nœuds du cluster. La valeur par défaut est auto-detect. |
| Fichier JSON du compte de service | Oui | 6.5.0 | Contenu du fichier JSON du compte de service. |
| Nom de bucket temporaire | Oui | 6.5.0 | Bucket Cloud Storage qui stocke les données temporaires. S'il n'existe pas, il est automatiquement créé, mais il n'est pas automatiquement supprimé. Les données Cloud Storage sont supprimées après leur chargement dans BigQuery. Si cette valeur n'est pas fournie, un bucket unique est créé, puis supprimé une fois l'exécution du pipeline terminée. Le compte de service doit être autorisé à créer des buckets dans le projet configuré. |
| Emplacement | Oui | 6.5.0 | Emplacement où l'ensemble de données BigQuery est créé.
Cette valeur est ignorée si l'ensemble de données ou le bucket temporaire existe déjà. L'emplacement multirégional US est l'emplacement par défaut. |
| Nom de la clé de chiffrement | Oui | 6.5.1/0.18.1 | La clé de chiffrement gérée par le client (CMEK) qui chiffre les données écrites dans un bucket, un ensemble de données ou une table créés par le plug-in. Si le bucket, l'ensemble de données ou la table existent déjà, cette valeur est ignorée. |
| Conserver les tables BigQuery après l'exécution | Oui | 6.5.0 | Indique si toutes les tables temporaires BigQuery créées pendant l'exécution du pipeline doivent être conservées à des fins de débogage et de validation. La valeur par défaut est Non. |
| Valeur TTL de la table temporaire (en heures) | Oui | 6.5.0 | Définissez la valeur TTL de la table pour les tables temporaires BigQuery, en heures. Il est utile comme solution de sécurité en cas d'annulation soudaine du pipeline et d'interruption du processus de nettoyage (par exemple, si le cluster d'exécution est arrêté soudainement). La définition de cette valeur sur 0 désactive la valeur TTL de la table. La valeur par défaut est 72 (trois jours). |
| Priorité du job | Oui | 6.5.0 | Priorité utilisée pour exécuter des tâches BigQuery. Sélectionnez l'une des options suivantes :
|
| Étapes pour forcer le pushdown | Oui | 6.7.0 | Étapes compatibles à exécuter en permanence dans BigQuery. Chaque nom de phase doit figurer sur une ligne distincte. |
| Étapes à suivre pour ignorer le pushdown | Oui | 6.7.0 | Étapes compatibles à ne jamais exécuter dans BigQuery. Chaque nom de scène doit figurer sur une ligne distincte. |
| Utiliser l'API BigQuery Storage Read | Oui | 6.7.0 | Indique si vous devez utiliser l'API BigQuery Storage Read lors de l'extraction d'enregistrements de BigQuery pendant l'exécution du pipeline. Cette option peut améliorer les performances du pushdown de transformation, mais entraîne des coûts supplémentaires. Pour ce faire, Scala 2.12 doit être installé dans l'environnement d'exécution. |
Surveiller les variations de performances dans les journaux
Les journaux d'exécution du pipeline incluent des messages qui montrent les requêtes SQL exécutées dans BigQuery. Vous pouvez surveiller les étapes du pipeline qui sont transmises à BigQuery.
L'exemple suivant montre les entrées de journal lorsque l'exécution du pipeline commence. Les journaux indiquent que les opérations JOIN de votre pipeline ont été transférées à BigQuery pour exécution:
INFO [Driver:i.c.p.g.b.s.BigQuerySQLEngine@190] - Validating join for stage 'Users' can be executed on BigQuery: true
DEBUG [batch-sql-engine-adapter:i.c.c.e.s.b.BatchSQLEngineAdapter@131] - Starting push for dataset 'UserProfile'
DEBUG [batch-sql-engine-adapter:i.c.c.e.s.b.BatchSQLEngineAdapter@131] - Starting push for dataset 'UserDetails'
DEBUG [batch-sql-engine-adapter:i.c.c.e.s.b.BatchSQLEngineAdapter@292] - Starting join for dataset 'Users'
INFO [Driver:i.c.p.g.b.s.BigQuerySQLEngine@190] - Validating join for stage 'UserPurchases' can be executed on BigQuery: true
DEBUG [batch-sql-engine-adapter:i.c.c.e.s.b.BatchSQLEngineAdapter@131] - Starting push for dataset 'Purchases'
DEBUG [batch-sql-engine-adapter:i.c.c.e.s.b.BatchSQLEngineAdapter@292] - Starting join for dataset 'UserPurchases'
INFO [Driver:i.c.p.g.b.s.BigQuerySQLEngine@190] - Validating join for stage 'MostPopularNames' can be executed on BigQuery: true
DEBUG [batch-sql-engine-adapter:i.c.c.e.s.b.BatchSQLEngineAdapter@131] - Starting push for dataset 'FirstNameCounts'
DEBUG [batch-sql-engine-adapter:i.c.c.e.s.b.BatchSQLEngineAdapter@292] - Starting join for dataset 'MostPopularNames'
DEBUG [batch-sql-engine-adapter:i.c.c.e.s.b.BatchSQLEngineAdapter@193] - Starting pull for dataset 'MostPopularNames'
L'exemple suivant présente les noms de table qui seront attribués à chacun des ensembles de données impliqués dans l'exécution du pushdown:
INFO [batch-sql-engine-adapter:i.c.p.g.b.s.BigQuerySQLEngine@145] - Executing Push operation for dataset Purchases stored in table <TABLE_ID>
INFO [batch-sql-engine-adapter:i.c.p.g.b.s.BigQuerySQLEngine@145] - Executing Push operation for dataset UserDetails stored in table <TABLE_ID>
INFO [batch-sql-engine-adapter:i.c.p.g.b.s.BigQuerySQLEngine@145] - Executing Push operation for dataset FirstNameCounts stored in table <TABLE_ID>
INFO [batch-sql-engine-adapter:i.c.p.g.b.s.BigQuerySQLEngine@145] - Executing Push operation for dataset UserProfile stored in table <TABLE_ID>
À mesure que l'exécution se poursuit, les journaux indiquent la fin des étapes de transfert et, à terme, l'exécution des opérations JOIN. Exemple :
DEBUG [batch-sql-engine-adapter:i.c.c.e.s.b.BatchSQLEngineAdapter@133] - Completed push for dataset 'UserProfile'
DEBUG [batch-sql-engine-adapter:i.c.c.e.s.b.BatchSQLEngineAdapter@133] - Completed push for dataset 'UserDetails'
DEBUG [batch-sql-engine-adapter:i.c.p.g.b.s.BigQuerySQLEngine@235] - Executing join operation for dataset Users
INFO [batch-sql-engine-adapter:i.c.p.g.b.s.BigQueryJoinDataset@118] - Creating table `<TABLE_ID>` using job: <JOB_ID> with SQL statement: SELECT `UserDetails`.id AS `id` , `UserDetails`.first_name AS `first_name` , `UserDetails`.last_name AS `last_name` , `UserDetails`.email AS `email` , `UserProfile`.phone AS `phone` , `UserProfile`.profession AS `profession` , `UserProfile`.age AS `age` , `UserProfile`.address AS `address` , `UserProfile`.score AS `score` FROM `your_project.your_dataset.<DATASET_ID>` AS `UserProfile` LEFT JOIN `your_project.your_dataset.<DATASET_ID>` AS `UserDetails` ON `UserProfile`.id = `UserDetails`.id
INFO [batch-sql-engine-adapter:i.c.p.g.b.s.BigQueryJoinDataset@151] - Created BigQuery table `<TABLE_ID>
INFO [batch-sql-engine-adapter:i.c.p.g.b.s.BigQuerySQLEngine@245] - Executed join operation for dataset Users
Une fois toutes les étapes terminées, un message indique que l'opération Pull est terminée. Cela indique que le processus d'exportation BigQuery a été déclenché et que les enregistrements commencent à être lus dans le pipeline après le début de cette tâche d'exportation. Exemple :
DEBUG [batch-sql-engine-adapter:i.c.c.e.s.b.BatchSQLEngineAdapter@196] - Completed pull for dataset 'MostPopularNames'
Si l'exécution du pipeline rencontre des erreurs, elles sont décrites dans les journaux.
Pour en savoir plus sur l'exécution des opérations JOIN BigQuery, telles que l'utilisation des ressources, le temps d'exécution et les causes d'erreur, vous pouvez afficher les données de la tâche BigQuery à l'aide de l'ID de tâche, qui apparaît dans les journaux de la tâche.
Examiner les métriques du pipeline
Pour en savoir plus sur les métriques fournies par Cloud Data Fusion pour la partie du pipeline exécutée dans BigQuery, consultez la section Métriques du pipeline de pushdown BigQuery.
Étape suivante
- En savoir plus sur le pushdown de transformation dans Cloud Data Fusion