Pour améliorer les performances de vos pipelines de données, vous pouvez transférer certaines opérations de transformation vers BigQuery au lieu d'Apache Spark. Le pushdown de transformation est un paramètre qui permet d'envoyer une opération située dans un pipeline de données Cloud Data Fusion vers BigQuery en tant que moteur d'exécution. Par conséquent, l'opération et ses données sont transférées vers BigQuery, où elles sont exécutées.
La poussée de transformation améliore les performances des pipelines qui comportent plusieurs opérations JOIN complexes ou d'autres transformations compatibles. L'exécution de certaines transformations dans BigQuery peut être plus rapide que dans Spark.
Les transformations non compatibles et toutes les transformations d'aperçu sont exécutées dans Spark.
Transformations compatibles
Le pushdown de transformation est disponible dans Cloud Data Fusion version 6.5.0 et ultérieure, mais certaines des transformations suivantes ne sont compatibles qu'avec les versions ultérieures.
Opérations JOIN
Le pushdown de transformation est disponible pour les opérations
JOINdans Cloud Data Fusion version 6.5.0 et ultérieure.Les opérations
JOINde base (sur les touches) et avancées sont acceptées.Les jointures doivent comporter exactement deux étapes d'entrée pour que l'exécution puisse avoir lieu dans BigQuery.
Les jointures configurées pour charger une ou plusieurs entrées en mémoire sont exécutées dans Spark au lieu de BigQuery, sauf dans les cas suivants:
- Si l'une des entrées de la jointure est déjà transmise.
- Si vous avez configuré la jointure pour qu'elle soit exécutée dans le moteur SQL (voir l'option Étapes pour forcer l'exécution).
Récepteur BigQuery
Le pushdown de transformation est disponible pour le sink BigQuery dans Cloud Data Fusion version 6.7.0 et ultérieure.
Lorsque le sink BigQuery suit une étape exécutée dans BigQuery, l'opération qui écrit des enregistrements dans BigQuery est effectuée directement dans BigQuery.
Pour améliorer les performances avec ce collecteur, vous avez besoin des éléments suivants:
- Le compte de service doit être autorisé à créer et à mettre à jour des tables dans l'ensemble de données utilisé par le récepteur BigQuery.
- Les ensembles de données utilisés pour le pushdown de transformation et le sink BigQuery doivent être stockés dans le même emplacement.
- L'opération doit être l'une des suivantes :
Insert(l'optionTruncate Tablen'est pas prise en charge)UpdateUpsert
Agrégations GROUP BY
Le pushdown de transformation est disponible pour les agrégations GROUP BY dans Cloud Data Fusion version 6.7.0 et ultérieure.
Les agrégations GROUP BY dans BigQuery sont disponibles pour les opérations suivantes:
AvgCollect List(les valeurs nulles sont supprimées du tableau de sortie)Collect Set(les valeurs nulles sont supprimées du tableau de sortie)ConcatConcat DistinctCountCount DistinctCount NullsLogical AndLogical OrMaxMinStandard DeviationSumSum of SquaresCorrected Sum of SquaresVarianceShortest StringLongest String
Les agrégations GROUP BY sont exécutées dans BigQuery dans les cas suivants:
- Il suit une étape qui a déjà été déplacée vers le bas.
- Vous l'avez configuré pour qu'il s'exécute dans le moteur SQL (voir l'option Étapes pour forcer l'exécution).
Dédupliquer les agrégations
Le pushdown de transformation est disponible pour les agrégations dédupliquées dans Cloud Data Fusion version 6.7.0 et ultérieure pour les opérations suivantes:
- Aucune opération de filtrage n'est spécifiée
ANY(valeur non nulle pour le champ souhaité)MIN(valeur minimale du champ spécifié)MAX(valeur maximale du champ spécifié)
Les opérations suivantes ne sont pas acceptées:
FIRSTLAST
Les agrégations de déduplication sont exécutées dans le moteur SQL dans les cas suivants:
- Il suit une étape qui a déjà été déplacée vers le bas.
- Vous l'avez configuré pour qu'il s'exécute dans le moteur SQL (voir l'option Étapes pour forcer l'exécution).
BigQuery Source Pushdown
Le pushdown de source BigQuery est disponible dans les versions Cloud Data Fusion 6.8.0 et ultérieures.
Lorsqu'une source BigQuery suit une étape compatible avec le pushdown BigQuery, le pipeline peut exécuter toutes les étapes compatibles dans BigQuery.
Cloud Data Fusion copie les enregistrements nécessaires à l'exécution du pipeline dans BigQuery.
Lorsque vous utilisez BigQuery Source Pushdown, les propriétés de partitionnement et de clustering de la table sont conservées, ce qui vous permet de les utiliser pour optimiser d'autres opérations, telles que les jointures.
Exigences supplémentaires
Pour utiliser le pushdown de source BigQuery, les conditions suivantes doivent être remplies:
Le compte de service configuré pour le pushdown de transformation BigQuery doit disposer des autorisations nécessaires pour lire les tables de l'ensemble de données de la source BigQuery.
Les ensembles de données utilisés dans la source BigQuery et l'ensemble de données configuré pour le pushdown de transformation doivent être stockés au même emplacement.
Agrégations de périodes
Le pushdown de transformation est disponible pour les agrégations de fenêtre dans les versions 6.9 et ultérieures de Cloud Data Fusion. Les agrégations de fenêtre dans BigQuery sont compatibles avec les opérations suivantes:
RankDense RankPercent RankN tileRow NumberMedianContinuous PercentileLeadLagFirstLastCumulative distributionAccumulate
Les agrégations de fenêtre sont exécutées dans BigQuery dans les cas suivants:
- Il suit une étape qui a déjà été déplacée vers le bas.
- Vous l'avez configuré pour qu'il s'exécute dans le moteur SQL (voir l'option Étapes à forcer le pushdown).
Filtre Wrangler Pushdown
Le pushdown de filtre Wrangler est disponible dans les versions Cloud Data Fusion 6.9 et ultérieures.
Lorsque vous utilisez le plug-in Wrangler, vous pouvez transférer des filtres, appelés opérations Precondition, pour qu'ils soient exécutés dans BigQuery au lieu de Spark.
Le pushdown de filtre n'est compatible qu'avec le mode SQL pour les conditions préalables, qui a également été publié dans la version 6.9. Dans ce mode, le plug-in accepte une expression de précondition en SQL conforme à la norme ANSI.
Si le mode SQL est utilisé pour les conditions préalables, les directives et les directives définies par l'utilisateur sont désactivées pour le plug-in Wrangler, car elles ne sont pas compatibles avec les conditions préalables en mode SQL.
Le mode SQL pour les conditions préalables n'est pas compatible avec les plug-ins Wrangler comportant plusieurs entrées lorsque la fonctionnalité Pushdown de transformation est activée. Si elle est utilisée avec plusieurs entrées, cette étape Wrangler avec des conditions de filtre SQL est exécutée dans Spark.
Les filtres sont exécutés dans BigQuery dans les cas suivants:
- Il suit une étape qui a déjà été déplacée vers le bas.
- Vous l'avez configuré pour qu'il s'exécute dans le moteur SQL (voir l'option Étapes à forcer le pushdown).
Métriques
Pour en savoir plus sur les métriques fournies par Cloud Data Fusion pour la partie du pipeline exécutée dans BigQuery, consultez la section Métriques du pipeline de pushdown BigQuery.
Quand utiliser le pushdown de transformation ?
L'exécution de transformations dans BigQuery implique les étapes suivantes:
- Écrire des enregistrements dans BigQuery pour les étapes compatibles de votre pipeline
- Exécuter des étapes compatibles dans BigQuery
- Lecture des enregistrements de BigQuery une fois les transformations compatibles exécutées, sauf si elles sont suivies d'un sink BigQuery.
Selon la taille de vos ensembles de données, la surcharge réseau peut être considérable, ce qui peut avoir un impact négatif sur le temps d'exécution global du pipeline lorsque le pushdown de transformation est activé.
En raison des frais généraux réseau, nous vous recommandons d'utiliser le pushdown de transformation dans les cas suivants:
- Plusieurs opérations compatibles sont exécutées en séquence (sans étape entre les étapes).
- Les gains de performances de BigQuery qui exécute les transformations, par rapport à Spark, l'emportent sur la latence du transfert de données vers et éventuellement depuis BigQuery.
Fonctionnement
Lorsque vous exécutez un pipeline qui utilise le pushdown de transformation, Cloud Data Fusion exécute les étapes de transformation compatibles dans BigQuery. Toutes les autres étapes du pipeline sont exécutées dans Spark.
Lorsque vous exécutez des transformations:
Cloud Data Fusion charge les ensembles de données d'entrée dans BigQuery en écrivant les enregistrements dans Cloud Storage, puis en exécutant une tâche de chargement BigQuery.
Les opérations
JOINet les transformations compatibles sont ensuite exécutées en tant que tâches BigQuery à l'aide d'instructions SQL.Si un traitement ultérieur est nécessaire après l'exécution des tâches, les enregistrements peuvent être exportés de BigQuery vers Spark. Toutefois, si l'option Tentative de copie directe vers les cibles BigQuery est activée et que la cible BigQuery suit une étape exécutée dans BigQuery, les enregistrements sont écrits directement dans la table de destination de la cible BigQuery.
Le diagramme suivant montre comment le pushdown de transformation exécute les transformations compatibles dans BigQuery au lieu de Spark.
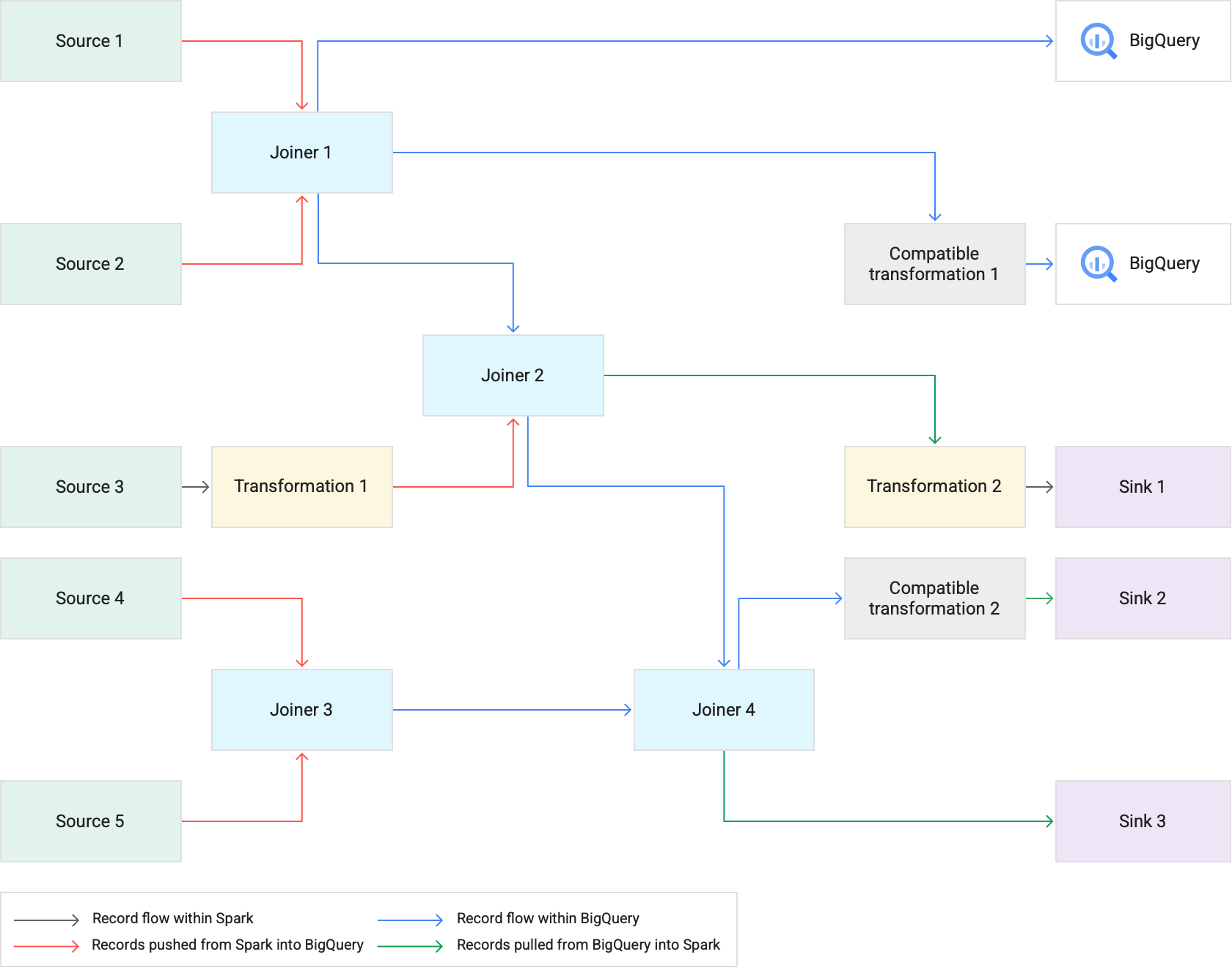
Bonnes pratiques
Ajuster la taille des clusters et des exécuteurs
Pour optimiser la gestion des ressources dans votre pipeline, procédez comme suit:
Utilisez le nombre approprié de nœuds de calcul du cluster pour une charge de travail. En d'autres termes, exploitez tout le potentiel du cluster Dataproc provisionné en utilisant pleinement le processeur et la mémoire disponibles pour votre instance, tout en bénéficiant de la vitesse d'exécution de BigQuery pour les tâches volumineuses.
Améliorez le parallélisme de vos pipelines à l'aide de clusters d'autoscaling.
Ajustez les configurations de ressources lors des étapes de votre pipeline où les enregistrements sont transférés ou extraits de BigQuery pendant l'exécution du pipeline.
Recommandé: Essayez d'augmenter le nombre de cœurs de processeur pour les ressources de l'exécuteur (dans la limite du nombre de cœurs de processeur utilisés par le nœud de calcul). Les exécuteurs optimisent l'utilisation du processeur lors des étapes de sérialisation et de désérialisation lorsque les données entrent et sortent de BigQuery. Pour en savoir plus, consultez la section Dimensionnement des clusters.
L'exécution de transformations dans BigQuery présente l'avantage de permettre l'exécution de vos pipelines sur des clusters Dataproc plus petits. Si les jointures sont les opérations les plus gourmandes en ressources de votre pipeline, vous pouvez tester des tailles de cluster plus petites, car les opérations JOIN intensives sont effectuées dans BigQuery), ce qui vous permet de réduire potentiellement vos coûts de calcul globaux.
Récupérez des données plus rapidement avec l'API BigQuery Storage Read
Une fois que BigQuery a exécuté les transformations, votre pipeline peut avoir des étapes supplémentaires à exécuter dans Spark. Dans la version 6.7.0 et ultérieure de Cloud Data Fusion, le pushdown de transformation est compatible avec l'API BigQuery Storage Read, ce qui améliore la latence et accélère les opérations de lecture dans Spark. Cela peut réduire le temps d'exécution global du pipeline.
L'API lit les enregistrements en parallèle. Nous vous recommandons donc d'ajuster les tailles d'exécuteur en conséquence. Si des opérations gourmandes en ressources sont exécutées dans BigQuery, réduisez l'allocation de mémoire pour les exécuteurs afin d'améliorer le parallélisme lors de l'exécution du pipeline (voir la section Ajuster les tailles de cluster et d'exécuteur).
L'API BigQuery Storage Read est désactivée par défaut. Vous pouvez l'activer dans les environnements d'exécution où Scala 2.12 est installé (y compris Dataproc 2.0 et Dataproc 1.5).
Considérer la taille de l'ensemble de données
Examinez les tailles des ensembles de données dans les opérations JOIN. Pour les opérations JOIN qui génèrent un nombre important d'enregistrements de sortie, par exemple quelque chose qui ressemble à une opération JOIN croisée, la taille de l'ensemble de données obtenu peut être supérieure à plusieurs ordres de grandeur à l'ensemble de données d'entrée. Prenez également en compte la surcharge du retrait de ces enregistrements dans Spark lors de l'exécution de traitement Spark supplémentaire de ces enregistrements (par exemple, une transformation ou un récepteur) dans le contexte des performances globales du pipeline.
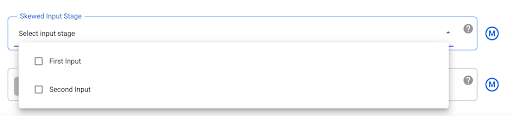
Atténuer les données asymétriques
Les opérations JOIN pour des données fortement biaisées peuvent entraîner le dépassement des limites d'utilisation des ressources par la tâche BigQuery, ce qui entraîne l'échec de l'opération JOIN. Pour éviter cela, accédez aux paramètres du plug-in Joiner et identifiez l'entrée déformée dans le champ Étape d'entrée déformée. Cela permet à Cloud Data Fusion d'organiser les entrées de manière à réduire le risque que l'instruction BigQuery dépasse les limites.
Étape suivante
- Découvrez comment activer le pushdown de transformation dans Cloud Data Fusion.