データ パイプラインのパフォーマンスを改善するには、一部の変換オペレーションを Apache Spark ではなく BigQuery に push します。変換のプッシュダウンとは、Cloud Data Fusion データ パイプラインのオペレーションを実行エンジンとして BigQuery に push できるようにする設定を指します。その結果、オペレーションとそのデータが BigQuery に転送され、そこでオペレーションが実行されます。
変換プッシュダウンを使用すると、複数の複雑な JOIN オペレーションやその他のサポートされている変換を含むパイプラインのパフォーマンスが向上します。BigQuery で一部の変換を実行すると、Spark で実行するよりも高速になる場合があります。
サポートされていない変換とすべてのプレビュー変換は Spark で実行されます。
サポートされている変換
変換のプッシュダウンは Cloud Data Fusion バージョン 6.5.0 以降で使用できますが、次の変換の一部は新しいバージョンでのみサポートされています。
JOIN オペレーション
変換のプッシュダウンは、Cloud Data Fusion バージョン 6.5.0 以降の
JOINオペレーションで使用できます。基本(キーオン)オペレーションと高度な
JOINオペレーションがサポートされています。BigQuery で実行するには、結合に 2 つの入力ステージが必要です。
1 つ以上の入力をメモリに読み込むように構成された結合は、次のケースを除き、BigQuery ではなく Spark で実行されます。
- 結合への入力のいずれかがすでにプッシュダウンされている場合。
- SQL Engine で結合を実行するように構成した場合(強制実行のステージ オプションを参照)。
BigQuery シンク:
変換のプッシュダウンは、Cloud Data Fusion バージョン 6.7.0 以降の BigQuery シンクで使用できます。
BigQuery シンクが BigQuery で実行されたステージに従うと、BigQuery にレコードを書き込むオペレーションが BigQuery で直接実行されます。
このシンクでパフォーマンスを向上させるには、次のものが必要です。
- サービス アカウントには、BigQuery シンクによって使用されるデータセット内のテーブルを作成および更新する権限が必要です。
- 変換のプッシュダウン使用するデータセットと BigQuery シンクは、同じロケーションに保存する必要があります。
- オペレーションは次のいずれかにする必要があります。
Insert(Truncate Tableオプションはサポートされていません)UpdateUpsert
GROUP BY 集計
変換のプッシュダウンは、Cloud Data Fusion バージョン 6.7.0 以降の GROUP BY 集計で使用できます。
BigQuery の GROUP BY 集計は、次のオペレーションに使用できます。
AvgCollect List(null 値は出力配列から削除されます)Collect Set(null 値は出力配列から削除されます)ConcatConcat DistinctCountCount DistinctCount NullsLogical AndLogical OrMaxMinStandard DeviationSumSum of SquaresCorrected Sum of SquaresVarianceShortest StringLongest String
GROUP BY 集計は、次の場合に BigQuery で実行されます。
- すでにプッシュダウンされたステージに従います。
- SQL Engine で実行するように構成した(強制実行のステージ オプションを参照)。
重複除去の集計
変換のプッシュダウンは、以下のオペレーションのために、Cloud Data Fusion バージョン 6.7.0 以降での重複除去の集計に使用できます。
- フィルタ オペレーションが指定されていない
ANY(目的のフィールドの null 以外の値)MIN(指定したフィールドの最小値)MAX(指定したフィールドの最大値)
次のオペレーションはサポートされていません。
FIRSTLAST
重複除去の集計は、次の場合に SQL エンジンで実行されます。
- すでにプッシュダウンされたステージに従います。
- SQL Engine で実行するように構成した(強制実行のステージ オプションを参照)。
BigQuery ソースのプッシュダウン
BigQuery ソースのプッシュダウンは、Cloud Data Fusion バージョン 6.8.0 以降で使用できます。
BigQuery Source が BigQuery プッシュダウンと互換性のあるステージに続く場合、パイプラインは BigQuery 内で互換性のあるすべてのステージを実行できます。
Cloud Data Fusion は、BigQuery 内でパイプラインを実行するために必要なレコードをコピーします。
BigQuery ソース プッシュダウンを使用すると、テーブルのパーティショニングとクラスタリングのプロパティが保持されるため、これらのプロパティを使用して、結合などの追加オペレーションを最適化できます。
その他の要件
BigQuery ソース プッシュダウンを使用するには、次の要件を満たしている必要があります。
BigQuery 変換プッシュダウン用に構成されたサービス アカウントには、BigQuery ソースのデータセット内のテーブルを読み取る権限が必要です。
BigQuery ソースで使用されるデータセットと、変換のプッシュダウン用に構成されたデータセットは、同じロケーションに保存する必要があります。
ウィンドウ集計
変換のプッシュダウンは、Cloud Data Fusion バージョン 6.9 以降のウィンドウ集計で使用できます。BigQuery のウィンドウ集計は、次のオペレーションでサポートされています。
RankDense RankPercent RankN tileRow NumberMedianContinuous PercentileLeadLagFirstLastCumulative distributionAccumulate
ウィンドウ集計は、次の場合に BigQuery で実行されます。
- すでにプッシュダウンされたステージに従います。
- SQL Engine で実行するように構成した(強制プッシュダウンのステージ オプションを参照)。
Wrangler フィルタのプッシュダウン
Wrangler フィルタのプッシュダウンは、Cloud Data Fusion バージョン 6.9 以降で使用できます。
Wrangler プラグインを使用すると、フィルタを push して(Precondition オペレーション)、Spark ではなく BigQuery で実行できます。
フィルタのプッシュダウンは、これもバージョン 6.9 でリリースされた前提条件の SQL モードでのみサポートされています。このモードでは、プラグインは ANSI 標準 SQL の条件式を受け入れます。
前提条件に SQL モードを使用すると、Wrangler プラグインでディレクティブとユーザー定義のディレクティブが無効になります。これは、SQL モードの前提条件では、それらがサポートされていないためです。
変換のプッシュダウンが有効になっている場合、前提条件の SQL モードは、複数の入力がある Wrangler プラグインでサポートされません。複数の入力で使用する場合、SQL フィルタ条件を含むこの Wrangler ステージは Spark で実行されます。
フィルタは、次の場合に BigQuery で実行されます。
- すでにプッシュダウンされたステージに従います。
- SQL Engine で実行するように構成した(強制プッシュダウンのステージ オプションを参照)。
指標
BigQuery で実行されるパイプラインの部分に対して Cloud Data Fusion が提供する指標の詳細については、BigQuery プッシュダウン パイプラインの指標をご覧ください。
変換のプッシュダウンを使用するタイミング
BigQuery で変換を実行するには、次の操作を行います。
- パイプラインでサポートされているステージのレコードを BigQuery に書き込む。
- BigQuery でサポートされるステージを実行する。
- サポートされている変換が実行された後に BigQuery からレコードを読み取ります(BigQuery シンクが続く場合を除く)。
データセットのサイズによっては、ネットワークのオーバーヘッドが大幅に増加し、変換プッシュダウンが有効になっている場合、パイプラインの全体的な実行時間に悪影響を及ぼす可能性があります。
ネットワークオーバーヘッドのため、次のような場合は変換のプッシュダウンをおすすめします。
- サポートされている複数のオペレーションが順番に実行れる(ステージ間にステップがない)。
- BigQuery に変換の実行に関して得られるパフォーマンスが、Spark と比較して、BigQuery との間のデータ レイテンシおよび場合によっては BigQuery から生じるレイテンシを上回る。
仕組み
変換のプッシュダウンを使用するパイプラインを実行すると、Cloud Data Fusion は BigQuery でサポートされている変換ステージを実行します。パイプラインの他のすべてのステージは Spark で実行されます。
変換の実行時:
Cloud Data Fusion は、Cloud Storage にレコードを書き込み、BigQuery 読み込みジョブを実行することで、入力データセットを BigQuery に読み込みます。
JOINオペレーションとサポートされている変換は、SQL ステートメントを使用して BigQuery ジョブとして実行されます。ジョブの実行後に追加の処理が必要な場合は、BigQuery から Spark にレコードをエクスポートできます。ただし、BigQuery シンクに直接コピーを試行オプションが有効で、BigQuery シンクが BigQuery で実行されたステージに従うと、レコードがエクスポート先の BigQuery シンク テーブルに直接書き込まれます。
次の図は、変換のプッシュダウンによって、Spark の代わりに BigQuery でサポートされる変換がどのように実行されるかを示しています。
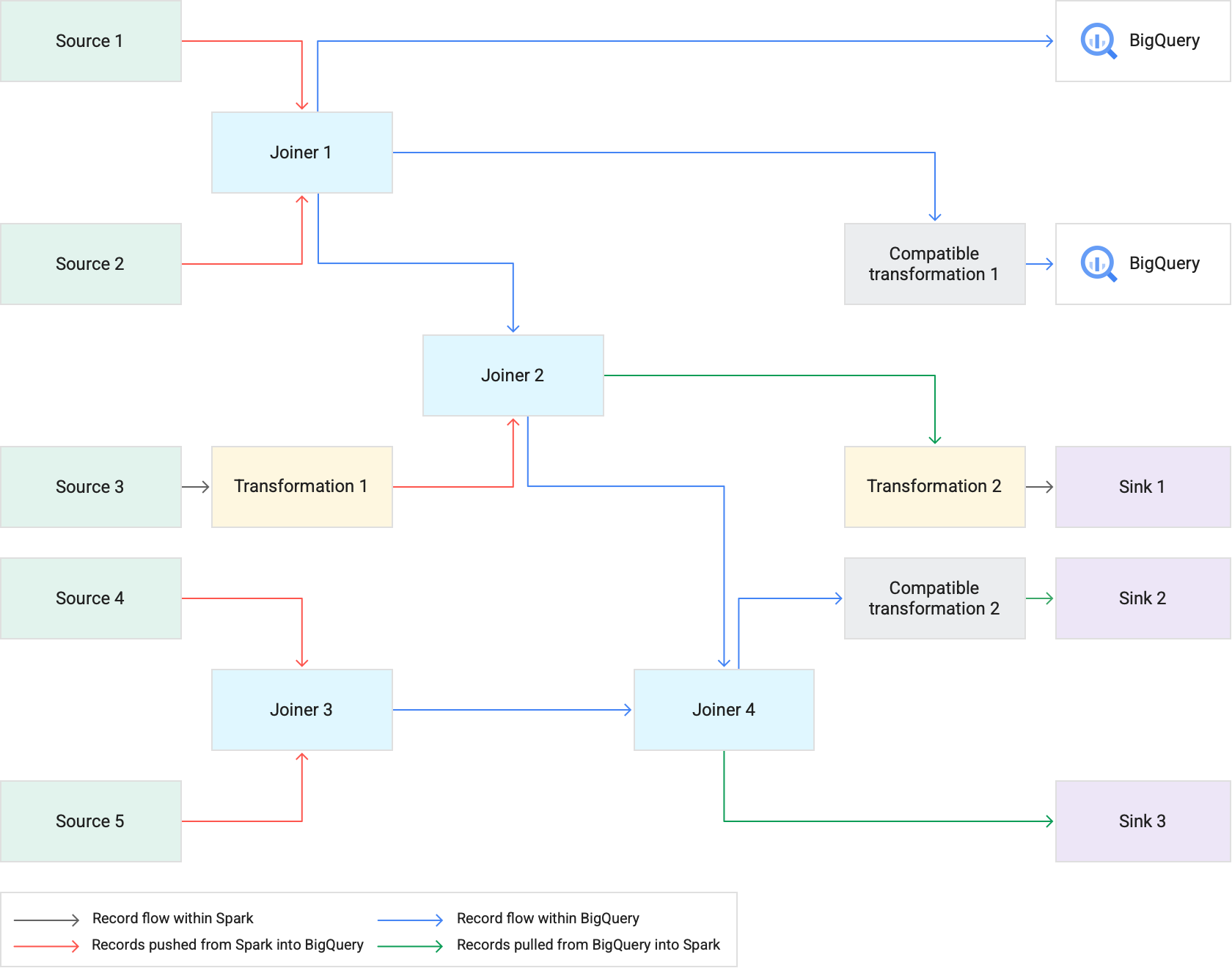
おすすめの方法
クラスタとエグゼキュータのサイズを調整する
パイプラインのリソース管理を最適化するには、次の操作を行います。
ワークロードに適した数のクラスタ ワーカー(ノード)を使用します。つまり、インスタンスで使用可能な CPU とメモリを最大限に活用してプロビジョニングされた Dataproc クラスタを最大限に活用し、大規模なジョブで BigQuery の実行速度を活用します。
自動スケーリング クラスタを使用して、パイプラインの並列処理を向上させます。
パイプラインの実行中に BigQuery からレコードが push または pull されるパイプラインのステージで、リソース構成を調整します。
推奨: エグゼキュータのリソースの CPU コア数を増やしてみてください(ワーカーノードで使用する CPU コア数まで)。 エグゼキュータは、BigQuery との間でデータがやり取りされる際のシリアル化と逆シリアル化のステップで CPU 使用量を最適化します。詳細については、クラスタのサイズ設定をご覧ください。
BigQuery で変換を実行する利点は、パイプラインを小さな Dataproc クラスタで実行できることです。結合がパイプラインで最もリソース消費量の多いオペレーションである場合は、より小さいクラスタサイズで試すことができます。負荷の大きい JOIN オペレーションが BigQuery で実行されるため、全体的なコンピューティング費用を削減できます。
BigQuery Storage Read API を使用してデータをより速く取得する
BigQuery が変換を実行した後、パイプラインには Spark で実行する追加のステージがある場合があります。Cloud Data Fusion バージョン 6.7.0 以降では、変換のプッシュダウンは BigQuery Storage Read API をサポートしています。これにより、レイテンシが改善され、Spark への読み取りオペレーションが高速化されます。これにより、パイプラインの全体的な実行時間が短縮されます。
API はレコードを並行して読み取るため、それに応じてエグゼキュータのサイズを調整することをおすすめします。リソース消費量の多いオペレーションが BigQuery で実行される場合は、エグゼキュータのメモリ割り当てを減らして、パイプラインの実行時の並列処理を改善します(クラスタとエグゼキュータのサイズを調整するをご覧ください)。
BigQuery Storage Read API はデフォルトで無効になっています。Scala 2.12 がインストールされている実行環境(Dataproc 2.0 や Dataproc 1.5 など)で有効にできます。
データセットのサイズを考慮する
JOIN オペレーションのデータセットのサイズを検討します。クロス出力の JOIN オペレーションに似ているものなど、かなりの数の出力レコードを生成する JOIN オペレーションの場合、生成されるデータセットのサイズは入力データセットよりも大きくなります。また、全体的なパイプライン パフォーマンスのコンテキストで、これらのレコードに対する Spark の追加処理(変換やシンクなど)が発生したときに、これらのレコードを Spark に戻すオーバーヘッドも検討します。
偏りのあるデータを軽減する
偏りのあるデータに対する JOIN オペレーションにより、BigQuery ジョブがリソース使用率の上限を超え、JOIN オペレーションが失敗する可能性があります。これを防ぐには、Joiner プラグインの設定に移動し、[偏りのある入力ステージ] フィールドで偏りのある入力を特定します。これにより、BigQuery ステートメントが制限を超えるリスクを軽減するように、Cloud Data Fusion が入力を配置できます。
![Joiner プラグインの設定の [偏りのある入力ステージ] フィールドで、偏りのあるデータを特定します。](https://cloud.google.com/static/data-fusion/docs/images/concepts/skewed-input-option.png?authuser=9&hl=ja)