Para mejorar el rendimiento de tus canalizaciones de datos, puedes enviar algunas operaciones de transformación a BigQuery en lugar de a Apache Spark. El envío de transformaciones hace referencia a un parámetro de configuración que permite que una operación en una canalización de datos de Cloud Data Fusion se envíe a BigQuery como un motor de ejecución. Como resultado, la operación y sus datos se transfieren a BigQuery, y la operación se realiza allí.
La transferencia de transformaciones mejora el rendimiento de las canalizaciones que tienen varias operaciones JOIN complejas o alguna otra transformación admitida. Ejecutar algunas transformaciones en BigQuery puede ser más rápido que ejecutarlas en Spark.
Las transformaciones no admitidas y todas las transformaciones de vista previa se ejecutan en Spark.
Transformaciones compatibles
El envío de transformaciones está disponible en Cloud Data Fusion 6.5.0 y versiones posteriores, pero algunas de las siguientes transformaciones solo son compatibles con versiones posteriores.
JOIN operaciones
El envío de transformaciones está disponible para las operaciones
JOINen Cloud Data Fusion 6.5.0 y versiones posteriores.Se admiten operaciones
JOINbásicas (en las teclas) y avanzadas.Las uniones deben tener exactamente dos etapas de entrada para que la ejecución se realice en BigQuery.
Las uniones configuradas para cargar una o más entradas en la memoria se ejecutan en Spark en lugar de en BigQuery, excepto en los siguientes casos:
- Si alguna de las entradas de la unión ya se envió.
- Si configuraste la unión para que se ejecute en el motor de SQL (consulta la opción Etapas para forzar la ejecución).
Receptor de BigQuery
El envío de transformaciones está disponible para el destino de BigQuery en Cloud Data Fusion 6.7.0 y versiones posteriores.
Cuando el sink de BigQuery sigue una etapa que se ejecutó en BigQuery, la operación que escribe registros en BigQuery se realiza directamente en BigQuery.
Para mejorar el rendimiento con este sumidero, necesitas lo siguiente:
- La cuenta de servicio debe tener permiso para crear y actualizar tablas en el conjunto de datos que usa el receptor de BigQuery.
- Los conjuntos de datos que se usan para la transferencia de transformación y el sink de BigQuery deben almacenarse en la misma ubicación.
- La operación debe ser una de las siguientes:
Insert(no se admite la opciónTruncate Table)UpdateUpsert
Agrupaciones de GROUP BY
El envío de transformaciones está disponible para las agregaciones de GROUP BY en Cloud Data Fusion 6.7.0 y versiones posteriores.
Las agregaciones de GROUP BY en BigQuery están disponibles para las siguientes operaciones:
AvgCollect List(los valores nulos se quitan del array de salida)Collect Set(los valores nulos se quitan del array de salida)ConcatConcat DistinctCountCount DistinctCount NullsLogical AndLogical OrMaxMinStandard DeviationSumSum of SquaresCorrected Sum of SquaresVarianceShortest StringLongest String
Las agregaciones de GROUP BY se ejecutan en BigQuery en los siguientes
casos:
- Sigue una etapa que ya se envió.
- La configuraste para que se ejecute en SQL Engine (consulta la opción Stages to force execution).
Anula la duplicación de las agregaciones
El envío de transformaciones está disponible para las agregaciones de eliminación de duplicados en Cloud Data Fusion 6.7.0 y versiones posteriores para las siguientes operaciones:
- No se especifica ninguna operación de filtro
ANY(un valor no nulo para el campo deseado)MIN(el valor mínimo para el campo especificado)MAX(el valor máximo para el campo especificado)
No se admiten las siguientes operaciones:
FIRSTLAST
Las agregaciones sin duplicados se ejecutan en el motor de SQL en los siguientes casos:
- Sigue una etapa que ya se envió.
- La configuraste para que se ejecute en SQL Engine (consulta la opción Stages to force execution).
Pushdown de fuentes de BigQuery
El envío de fuentes de BigQuery está disponible en Cloud Data Fusion 6.8.0 y versiones posteriores.
Cuando una fuente de BigQuery sigue una etapa que es compatible con la transferencia de datos a BigQuery, la canalización puede ejecutar todas las etapas compatibles dentro de BigQuery.
Cloud Data Fusion copia los registros necesarios para ejecutar la canalización en BigQuery.
Cuando usas la transferencia de datos de origen a BigQuery, se conservan las propiedades de particionamiento y agregación de tablas, lo que te permite usarlas para optimizar otras operaciones, como las uniones.
Requisitos adicionales
Para usar la transferencia de datos de fuentes de BigQuery, se deben cumplir los siguientes requisitos:
La cuenta de servicio configurada para la transferencia de transformación de BigQuery debe tener permisos para leer tablas en el conjunto de datos de la fuente de BigQuery.
Los conjuntos de datos que se usan en la fuente de BigQuery y el conjunto de datos configurado para la transferencia de transformación deben almacenarse en la misma ubicación.
Agregaciones de ventanas
El envío de transformaciones está disponible para las agregaciones de ventanas en Cloud Data Fusion 6.9 y versiones posteriores. Las agregaciones de ventanas en BigQuery son compatibles con las siguientes operaciones:
RankDense RankPercent RankN tileRow NumberMedianContinuous PercentileLeadLagFirstLastCumulative distributionAccumulate
Las agregaciones de ventanas se ejecutan en BigQuery en los siguientes casos:
- Sigue una etapa que ya se envió.
- Lo configuraste para que se ejecute en SQL Engine (consulta la opción Stages to force pushdown).
Pushdown de filtros de Wrangler
El envío de filtros de Wrangler está disponible en Cloud Data Fusion 6.9 y versiones posteriores.
Cuando usas el complemento Wrangler, puedes enviar filtros, conocidos como operaciones Precondition, para que se ejecuten en BigQuery en lugar de en Spark.
La implementación de filtros solo es compatible con el modo SQL para las condiciones previas, que también se lanzó en la versión 6.9. En este modo, el plug-in acepta una expresión de precondición en SQL estándar ANSI.
Si se usa el modo SQL para las condiciones previas, las Directivas y las Directivas definidas por el usuario están inhabilitadas para el complemento Wrangler, ya que no son compatibles con las condiciones previas en el modo SQL.
El modo SQL para condiciones previas no es compatible con los complementos de Wrangler con varias entradas cuando la transferencia de transformación está habilitada. Si se usa con varias entradas, esta etapa de Wrangler con condiciones de filtro de SQL se ejecuta en Spark.
Los filtros se ejecutan en BigQuery en los siguientes casos:
- Sigue una etapa que ya se envió.
- Lo configuraste para que se ejecute en SQL Engine (consulta la opción Stages to force pushdown).
Métricas
Para obtener más información sobre las métricas que proporciona Cloud Data Fusion para la parte de la canalización que se ejecuta en BigQuery, consulta Métricas de canalización de transferencia de BigQuery.
Cuándo usar el envío de transformaciones
Ejecutar transformaciones en BigQuery implica lo siguiente:
- Escritura de registros en BigQuery para las etapas compatibles en tu canalización
- Ejecutar etapas compatibles en BigQuery
- Leer registros de BigQuery después de que se ejecuten las transformaciones compatibles, a menos que se los siga con un sumidero de BigQuery
Según el tamaño de tus conjuntos de datos, puede haber una sobrecarga considerable en la red, lo que puede tener un impacto negativo en el tiempo de ejecución general de la canalización cuando el envío de transformaciones está habilitado.
Debido a la sobrecarga de red, recomendamos la transferencia de transformación en los siguientes casos:
- Se ejecutan varias operaciones compatibles en secuencia (sin pasos entre las etapas).
- Las ganancias de rendimiento de BigQuery que ejecutan las transformaciones, en comparación con Spark, superan la latencia del movimiento de datos hacia BigQuery y, posiblemente, hacia afuera.
Cómo funciona
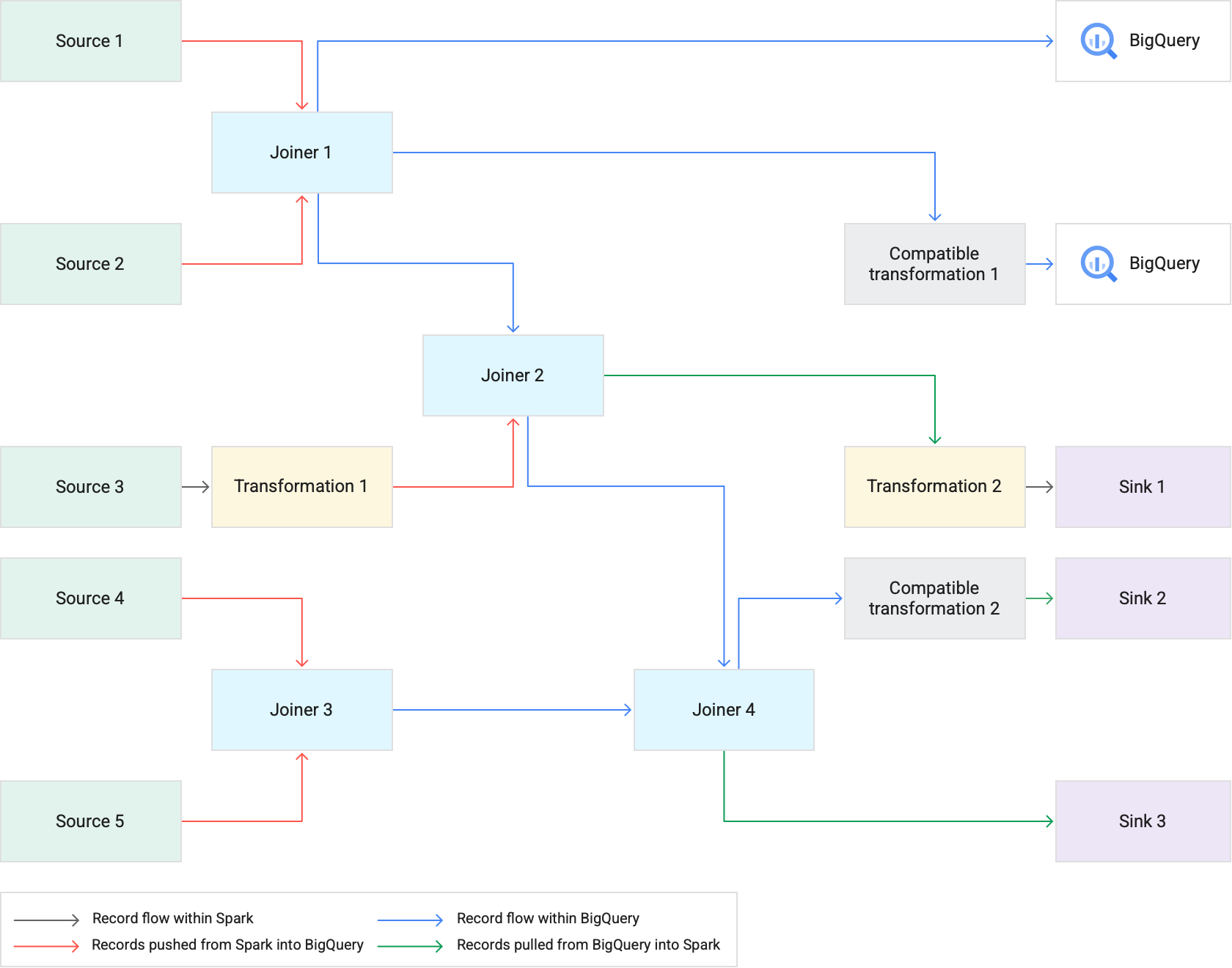
Cuando ejecutas una canalización que usa el envío de transformaciones, Cloud Data Fusion ejecuta las etapas de transformación compatibles en BigQuery. Todas las demás etapas de la canalización se ejecutan en Spark.
Cuando se ejecutan transformaciones, ocurre lo siguiente:
Cloud Data Fusion carga los conjuntos de datos de entrada en BigQuery escribiendo registros en Cloud Storage y, luego, ejecutando un trabajo de carga de BigQuery.
Las operaciones
JOINy las transformaciones compatibles se ejecutan como trabajos de BigQuery mediante instrucciones de SQL.Si se necesita un procesamiento adicional después de que se ejecutan las tareas, los registros se pueden exportar de BigQuery a Spark. Sin embargo, si la opción Intentar copia directa en los receptores de BigQuery está habilitada y el receptor de BigQuery sigue una etapa que se ejecutó en BigQuery, los registros se escriben directamente en la tabla de destino del receptor de BigQuery.
En el siguiente diagrama, se muestra cómo el envío de transformaciones ejecuta las transformaciones compatibles en BigQuery en lugar de en Spark.
Prácticas recomendadas
Ajusta los tamaños de los clústeres y ejecutores
Para optimizar la administración de recursos en tu canalización, haz lo siguiente:
Usa la cantidad correcta de trabajadores (nodos) del clúster para una carga de trabajo. En otras palabras, aprovecha al máximo el clúster de Dataproc aprovisionado mediante el uso completo de la CPU y la memoria disponibles para tu instancia, a la vez que aprovechas la velocidad de ejecución de BigQuery para las tareas grandes.
Mejora el paralelismo en tus canalizaciones mediante clústeres de ajuste de escala automático.
Ajusta la configuración de tus recursos en las etapas de tu canalización en las que se envían o extraen registros de BigQuery durante la ejecución de tu canalización.
Recomendado: Experimenta con un aumento en la cantidad de núcleos de CPU para tus recursos de ejecutor (hasta la cantidad de núcleos de CPU que usa tu nodo trabajador). Los ejecutores optimizan el uso de la CPU durante los pasos de serialización y deserialización a medida que los datos entran y salen de BigQuery. Para obtener más información, consulta Tamaño del clúster.
Un beneficio de ejecutar transformaciones en BigQuery es que tus canalizaciones pueden ejecutarse en clústeres más pequeños de Dataproc. Si las uniones son las operaciones que consumen más recursos en tu canalización, puedes experimentar con tamaños de clúster más pequeños, ya que las operaciones pesadas de JOIN ahora se realizan en BigQuery, lo que te permite poder reducir los costos generales de procesamiento.
Recupera datos más rápido con la API de BigQuery Storage Read
Después de que BigQuery ejecute las transformaciones, es posible que tu canalización tenga etapas adicionales para ejecutar en Spark. En la versión 6.7.0 y posteriores de Cloud Data Fusion, la transferencia de transformaciones admite la API de lectura de almacenamiento de BigQuery, lo que mejora la latencia y genera operaciones de lectura más rápidas en Spark. Puede reducir el tiempo de ejecución general de la canalización.
La API lee registros en paralelo, por lo que te recomendamos que ajustes los tamaños del ejecutor según corresponda. Si se ejecutan operaciones que consumen muchos recursos en BigQuery, reduce la asignación de memoria para los ejecutores para mejorar el paralelismo cuando se ejecuta la canalización (consulta Cómo ajustar el tamaño del clúster y del ejecutor).
La API de lectura de BigQuery Storage está inhabilitada de forma predeterminada. Puedes habilitarlo en entornos de ejecución en los que esté instalado Scala 2.12 (incluidos Dataproc 2.0 y Dataproc 1.5).
Considera el tamaño del conjunto de datos
Considera los tamaños de los conjuntos de datos en las operaciones JOIN. En el caso de las operaciones JOIN que generan una cantidad considerable de registros de resultados, como algo que se parece a una operación JOIN cruzada, el tamaño del conjunto de datos resultante podría ser mucho mayor que el del conjunto de datos de entrada. Además, considera la sobrecarga de extraer estos registros en Spark cuando se produce un procesamiento adicional de parte de Spark de estos registros (como una transformación o un receptor) en el contexto del rendimiento general de la canalización.
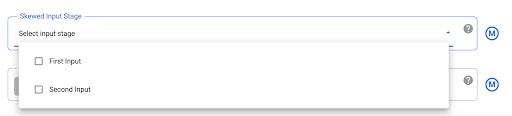
Mitiga los datos sesgados
Las operaciones JOIN para datos muy sesgados pueden hacer que el trabajo de BigQuery supere los límites de uso de recursos, lo que hace que falle la operación JOIN. Para evitarlo, ve a la configuración del plugin Joiner y, luego, identifica la entrada sesgada en el campo Skewed Input Stage. Esto permite que Cloud Data Fusion organice las entradas de una manera que reduzca el riesgo de que la sentencia de BigQuery exceda los límites.
¿Qué sigue?
- Obtén información para habilitar el envío de transformaciones en Cloud Data Fusion.