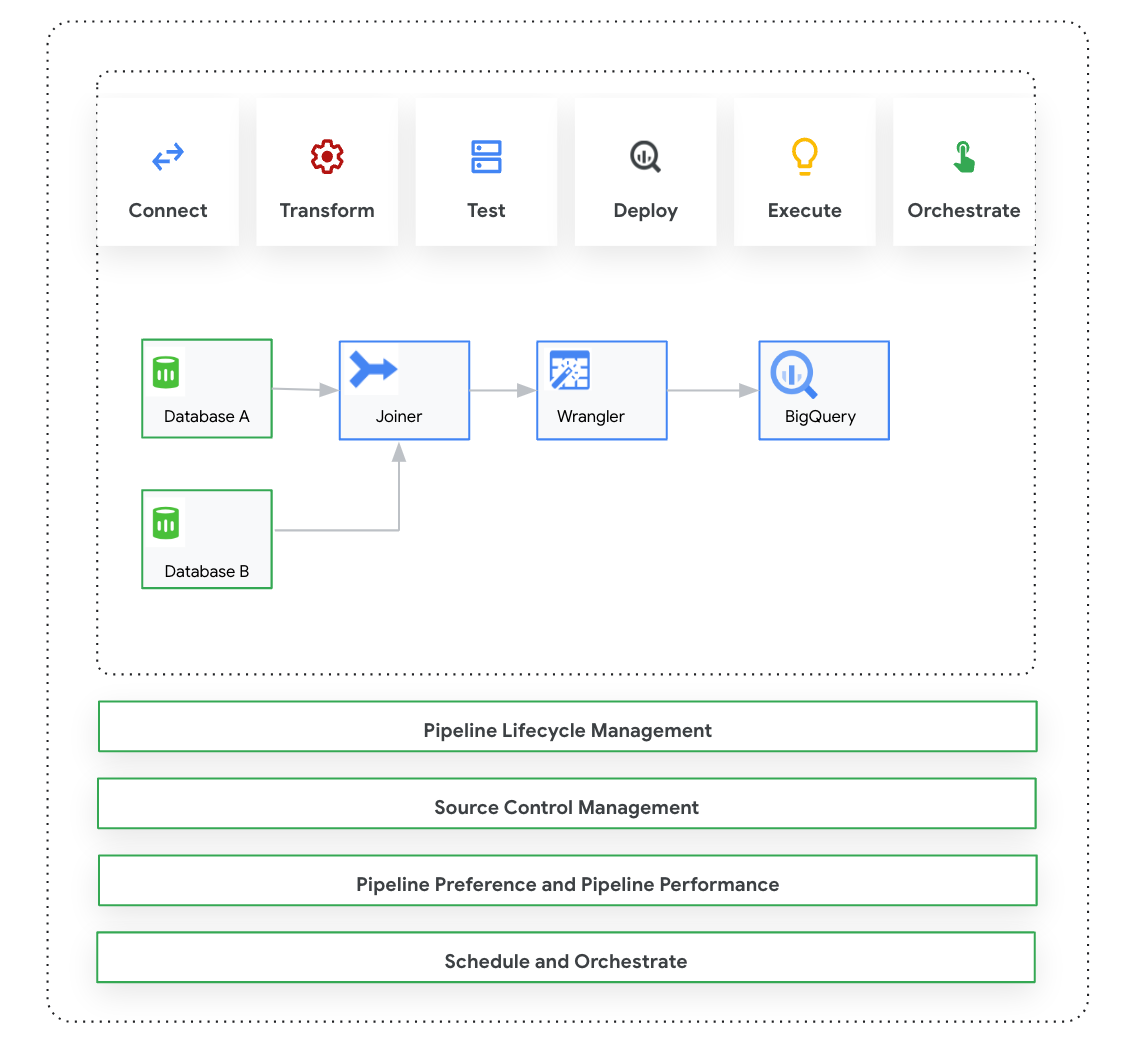
本页介绍了 Cloud Data Fusion Studio,这是一个可视化的“点击和拖动”界面,可用于从预构建插件库构建数据流水线,还可用于配置、执行和管理流水线。在 Studio 中构建流水线通常遵循以下流程:
- 连接到本地数据源或云数据源。
- 准备和转换数据。
- 连接到目的地。
- 测试流水线。
- 执行流水线。
- 安排和触发流水线。
设计和执行流水线后,您可以在 Cloud Data Fusion Pipeline Studio 页面上管理流水线:
- 通过使用偏好设置和运行时参数对流水线进行参数化,以便重复使用流水线。
- 通过自定义计算配置文件、管理资源和微调流水线性能来管理流水线执行。
- 通过修改流水线来管理流水线生命周期。
- 使用 Git 集成管理流水线源代码控制。
准备工作
- 启用 Cloud Data Fusion API。
- 创建 Cloud Data Fusion 实例。
- 了解 Cloud Data Fusion 中的访问权限控制。
- 了解 Cloud Data Fusion 中的关键概念和术语。
Cloud Data Fusion:Studio 概览
该工作室包含以下组件。
管理
借助 Cloud Data Fusion,您可以在每个实例中创建多个命名空间。在 Studio 中,管理员可以集中管理所有命名空间,也可以单独管理每个命名空间。
Studio 提供以下管理员控制功能:
- 系统管理
- 借助 Studio 中的系统管理模块,您可以在系统级别创建新的命名空间并定义中央计算配置文件,这些配置文件适用于该实例中的每个命名空间。如需了解详情,请参阅管理工作室管理。
- 命名空间管理
- 借助 Studio 中的命名空间管理模块,您可以管理特定命名空间的配置。对于每个命名空间,您可以定义计算配置文件、运行时偏好设置、驱动程序、服务账号和 Git 配置。如需了解详情,请参阅管理工作室管理。
Pipeline Design Studio
您可以在 Cloud Data Fusion 网页界面的流水线设计 Studio 中设计和执行流水线。设计和执行数据流水线包括以下步骤:
- 连接到数据源:Cloud Data Fusion 支持连接到本地数据源和云数据源。Studio 界面包含默认的系统插件,这些插件已预安装在 Studio 中。您可以从插件库(称为 Hub)下载其他插件。如需了解详情,请参阅插件概览。
- 数据准备:借助 Cloud Data Fusion 强大的数据准备插件 Wrangler,您可以准备数据。Wrangler 可帮助您在一处查看、探索和转换一小部分数据样本,然后再在 Studio 中对整个数据集运行逻辑。这样,您就可以快速应用转换,了解它们对整个数据集的影响。您可以创建多个转换并将其添加到配方中。如需了解详情,请参阅 Wrangler 概览。
- 转换:转换插件会在数据从来源加载后更改数据。例如,您可以克隆记录、将文件格式更改为 JSON,或使用 JavaScript 插件创建自定义转换。如需了解详情,请参阅插件概览。
- 连接到目标位置:准备好数据并应用转换后,您可以连接到计划将数据加载到的目标位置。Cloud Data Fusion 支持连接到多个目的地。如需了解详情,请参阅插件概览。
- 预览:设计流水线后,为了在部署和运行流水线之前调试问题,您可以运行预览作业。如果您遇到任何错误,可以在草稿模式下进行修正。Data Studio 会使用来源数据集的前 100 行生成预览。Studio 会显示预览作业的状态和时长。您可以随时停止作业。 您还可以在预览作业运行时监控日志事件。如需了解详情,请参阅预览数据。
管理流水线配置:预览数据后,您可以部署流水线并管理以下流水线配置:
- 计算配置:您可以更改运行流水线的计算配置文件,例如,您希望针对自定义 Dataproc 集群(而非默认 Dataproc 集群)运行流水线。
- 流水线配置:对于每个流水线,您可以启用或停用插桩(例如时间指标)。默认情况下,插桩功能处于启用状态。
- 引擎配置:Spark 是默认的执行引擎。您可以为 Spark 传递自定义参数。
- 资源:您可以为 Spark 驱动程序和执行程序指定内存和 CPU 数量。驱动程序会编排 Spark 作业。执行器会处理 Spark 中的数据处理。
- 流水线提醒:您可以将流水线配置为在流水线运行完成后发送提醒并启动后处理任务。您可以在设计流水线时创建流水线提醒。部署流水线后,您可以查看提醒。如需更改提醒设置,您可以修改相应流水线。
- 转换推送:如果您希望流水线在 BigQuery 中执行特定转换,可以启用转换推送。
如需了解详情,请参阅管理数据流配置。
使用宏、偏好设置和运行时参数重复使用流水线:Cloud Data Fusion 让您可以重复使用数据流水线。借助可重复使用的数据流水线,您可以使用单个流水线将数据集成模式应用于各种用例和数据集。可重复使用的流水线可提高可管理性。借助这些参数,您可以在执行时设置流水线的大部分配置,而不是在设计时对其进行硬编码。在 Pipeline Design Studio 中,您可以使用宏将变量添加到插件配置,以便在运行时指定变量替换项。如需了解详情,请参阅管理宏、偏好设置和运行时参数。
执行:查看流水线配置后,您可以启动流水线执行。您可以查看流水线运行各阶段的状态变化,例如预配、启动、运行和成功。
安排和协调:批量数据流水线可设置为按指定的时间安排和频率运行。创建并部署流水线后,您可以创建时间安排。在 Pipeline Design Studio 中,您可以通过在批量数据流水线上创建触发器来协调流水线,以便在一个或多个流水线运行完成时运行该触发器。这称为下游和上游流水线。您可以在下游流水线上创建触发器,以便根据一个或多个上游流水线的完成情况运行。
建议:您还可以使用 Composer 在 Cloud Data Fusion 中编排流水线。如需了解详情,请参阅安排流水线作业时间和编排流水线。
修改流水线:借助 Cloud Data Fusion,您可以修改已部署的流水线。修改已部署的流水线时,系统会创建一个同名的新版本流水线,并将其标记为最新版本。这样,您就可以迭代开发流水线,而不是复制流水线(这会创建一个具有不同名称的新流水线)。如需了解详情,请参阅修改流水线。
源代码控制管理:借助 Cloud Data Fusion,您可以使用 GitHub 对流水线进行源代码控制管理,从而更好地管理开发环境和生产环境之间的流水线。
日志记录和监控:如需监控流水线指标和日志,建议您启用 Stackdriver 日志记录服务,以便将 Cloud Logging 与 Cloud Data Fusion 流水线搭配使用。
后续步骤
- 详细了解如何管理 Studio 管理。