在 Cloud Data Fusion 中创建数据流水线时,您需要使用一系列阶段(称为节点)来移动和管理从源流向接收器的数据。每个节点都包含一个插件,这是一个可自定义的模块,可扩展 Cloud Data Fusion 的功能。
您可以前往 Studio 页面,在 Cloud Data Fusion 网页界面中找到这些插件。如需查看更多插件,请点击 Hub。
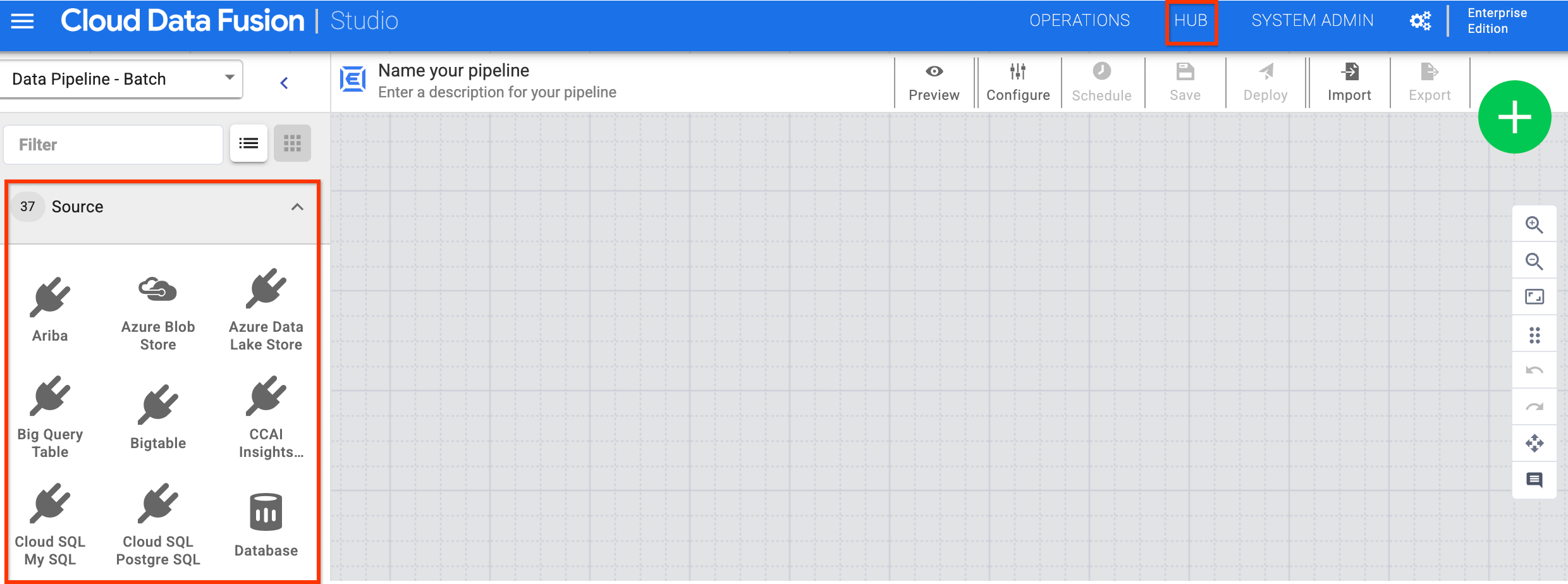
插件类型
插件分为以下几类:
- 来源
- 转换
- 分析
- 接收器
- 条件和操作
- 错误处理程序和提醒
来源
来源插件会连接到数据流水线读取数据的数据库、文件或实时流。您可以使用网页界面为数据流水线设置来源,因此无需担心编写低层级连接代码。
转换
转换插件会在从来源提取数据后更改数据。例如,您可以克隆记录、将文件格式更改为 JSON,或使用 JavaScript 插件创建自定义转换。
分析
分析插件用于执行聚合,例如对不同来源的数据进行联接,以及运行分析和机器学习操作。
接收器
接收器插件会将数据写入 Cloud Storage、BigQuery、Spanner、关系型数据库、文件系统和大型机等资源。您可以使用 Cloud Data Fusion 网页界面或 REST API 查询写入到接收器的数据。
条件和操作
使用条件和操作插件可安排在工作流中执行的操作,这些操作不会直接操纵工作流中的数据。例如:
- 使用数据库插件安排在流水线结束时运行数据库命令。
- 使用“文件移动”插件触发在 Cloud Storage 中移动文件的操作。
错误处理程序和提醒
当阶段遇到 null 值、逻辑错误或其他错误来源时,您可以使用错误处理程序插件捕获错误。您可以使用这些插件在转换或分析插件之后查找输出中的错误。您可以将错误写入数据库以进行分析。