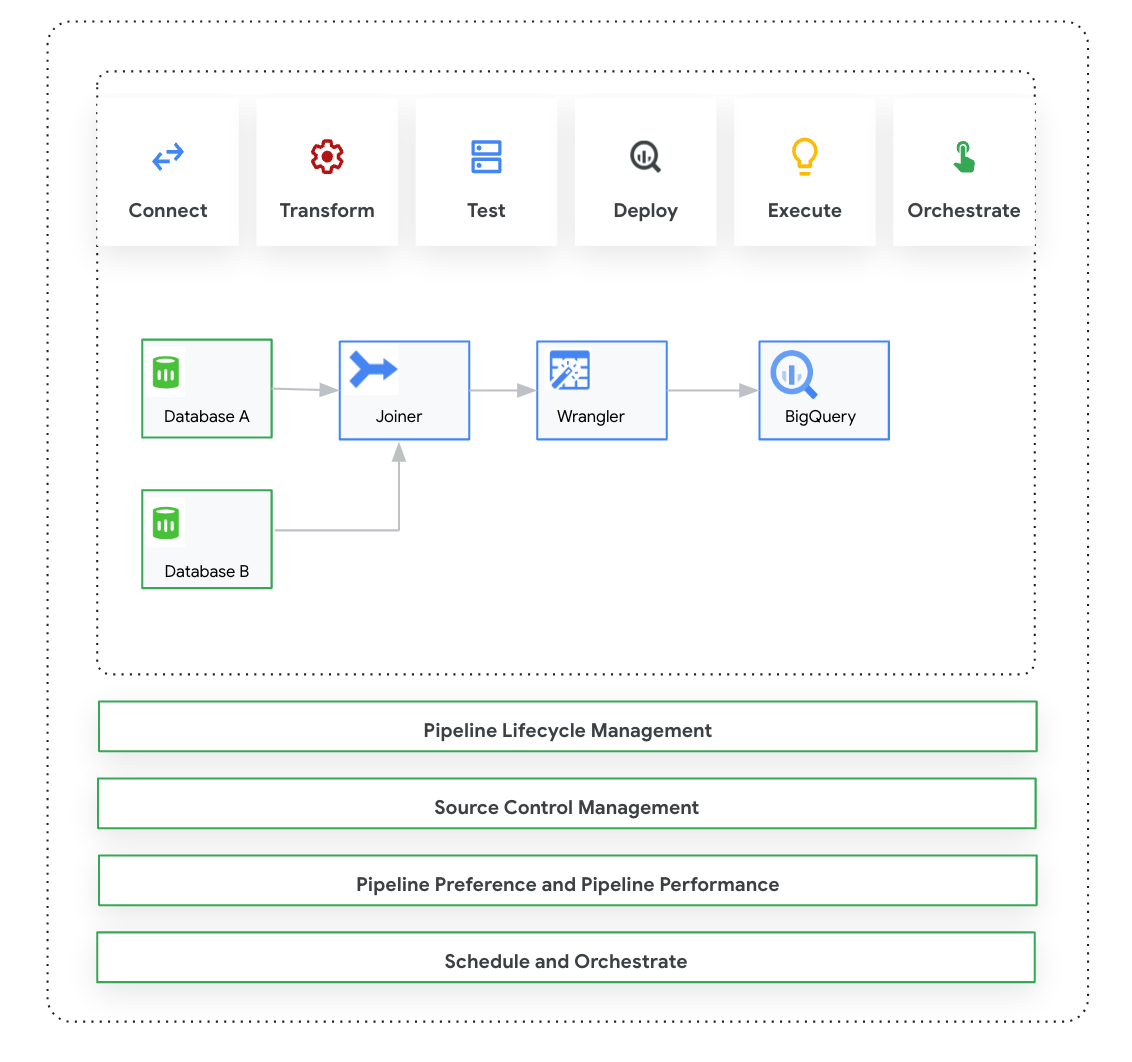
Cette page présente Cloud Data Fusion: Studio, une interface visuelle basée sur le glisser-déposer permettant de créer des pipelines de données à partir d'une bibliothèque de plug-ins prédéfinis et d'une interface dans laquelle vous configurez, exécutez et gérez vos pipelines. La création d'un pipeline dans Studio suit généralement ce processus:
- Connectez-vous à une source de données sur site ou dans le cloud.
- Préparer et transformer vos données
- Connectez-vous à la destination.
- Testez votre pipeline.
- Exécutez votre pipeline.
- Planifiez et déclenchez vos pipelines.
Après avoir conçu et exécuté le pipeline, vous pouvez le gérer sur la page Pipeline Studio de Cloud Data Fusion:
- Réutilisez les pipelines en les paramétrant avec des préférences et des arguments d'exécution.
- Gérez l'exécution du pipeline en personnalisant les profils de calcul, en gérant les ressources et en ajustant les performances du pipeline.
- Gérez le cycle de vie des pipelines en les modifiant.
- Gérez le contrôle des sources du pipeline à l'aide de l'intégration Git.
Avant de commencer
- Activez l'API Cloud Data Fusion.
- Créez une instance Cloud Data Fusion.
- Découvrez le contrôle des accès dans Cloud Data Fusion.
- Découvrez les concepts et termes clés de Cloud Data Fusion.
Cloud Data Fusion: présentation de Studio
Le Studio comprend les composants suivants :
Administration
Cloud Data Fusion vous permet d'avoir plusieurs espaces de noms dans chaque instance. Dans Studio, les administrateurs peuvent gérer tous les espaces de noms de manière centralisée ou individuellement.
Studio propose les commandes d'administration suivantes:
- Administrateur(trice) système
- Le module System Admin (Administration système) de Studio vous permet de créer des espaces de noms et de définir les configurations centrales du profil de calcul au niveau du système, qui s'appliquent à chaque espace de noms de cette instance. Pour en savoir plus, consultez Gérer l'administration de Studio.
- Administration de l'espace de noms
- Le module Administration de l'espace de noms de Studio vous permet de gérer les configurations de l'espace de noms spécifique. Pour chaque espace de noms, vous pouvez définir des profils de calcul, des préférences d'exécution, des pilotes, des comptes de service et des configurations git. Pour en savoir plus, consultez Gérer l'administration de Studio.
Pipeline Design Studio
Vous concevez et exécutez des pipelines dans Pipeline Design Studio dans l'interface Web de Cloud Data Fusion. La conception et l'exécution de pipelines de données incluent les étapes suivantes:
- Se connecter à une source: Cloud Data Fusion permet de se connecter à des sources de données sur site et dans le cloud. L'interface Studio comporte des plug-ins système par défaut, qui sont préinstallés dans Studio. Vous pouvez télécharger des plug-ins supplémentaires à partir d'un dépôt de plug-ins, appelé Hub. Pour en savoir plus, consultez la présentation des plug-ins.
- Préparation des données: Cloud Data Fusion vous permet de préparer vos données à l'aide de son puissant plug-in de préparation des données: Wrangler. Wrangler vous aide à afficher, explorer et transformer un petit échantillon de vos données en un seul endroit avant d'exécuter la logique sur l'ensemble de données complet dans Studio. Vous pouvez ainsi appliquer rapidement des transformations pour comprendre leur impact sur l'ensemble des données. Vous pouvez créer plusieurs transformations et les ajouter à une recette. Pour en savoir plus, consultez la présentation de Wrangler.
- Transformer: les plug-ins de transformation modifient les données après leur chargement à partir d'une source. Par exemple, vous pouvez cloner un enregistrement, définir le format de fichier sur JSON ou utiliser le plug-in JavaScript pour créer une transformation personnalisée. Pour en savoir plus, consultez la présentation des plug-ins.
- Se connecter à une destination: après avoir préparé les données et appliqué des transformations, vous pouvez vous connecter à la destination où vous prévoyez de charger les données. Cloud Data Fusion prend en charge les connexions à plusieurs destinations. Pour en savoir plus, consultez la section Présentation des plug-ins.
- Aperçu: après avoir conçu le pipeline, vous exécutez un job d'aperçu pour déboguer les problèmes avant de déployer et d'exécuter un pipeline. Si vous rencontrez des erreurs, vous pouvez les corriger en mode Brouillon. Studio utilise les 100 premières lignes de votre ensemble de données source pour générer l'aperçu. Studio affiche l'état et la durée de la tâche d'aperçu. Vous pouvez arrêter la tâche à tout moment. Vous pouvez également surveiller les événements de journal pendant l'exécution de la tâche d'aperçu. Pour en savoir plus, consultez la section Aperçu des données.
Gérer les configurations de pipeline: après avoir prévisualisé les données, vous pouvez déployer le pipeline et gérer les configurations de pipeline suivantes:
- Configuration de calcul: vous pouvez modifier le profil de calcul qui exécute le pipeline. Par exemple, vous souhaitez exécuter le pipeline sur un cluster Dataproc personnalisé plutôt que sur le cluster Dataproc par défaut.
- Configuration du pipeline: pour chaque pipeline, vous pouvez activer ou désactiver l'instrumentation, comme les métriques de chronométrage. Par défaut, l'instrumentation est activée.
- Configuration du moteur: Spark est le moteur d'exécution par défaut. Vous pouvez transmettre des paramètres personnalisés pour Spark.
- Ressources: vous pouvez spécifier la mémoire et le nombre de processeurs pour le pilote et l'exécutant Spark. Le pilote orchestre la tâche Spark. L'exécuteur gère le traitement des données dans Spark.
- Alerte de pipeline: vous pouvez configurer le pipeline pour qu'il envoie des alertes et démarre des tâches de post-traitement une fois l'exécution du pipeline terminée. Vous créez des alertes de pipeline lorsque vous concevez le pipeline. Une fois le pipeline déployé, vous pouvez afficher les alertes. Pour modifier les paramètres d'alerte, vous pouvez modifier le pipeline.
- Pushdown de transformation: vous pouvez activer le pushdown de transformation si vous souhaitez qu'un pipeline exécute certaines transformations dans BigQuery.
Pour en savoir plus, consultez Gérer les configurations de pipeline.
Réutiliser des pipelines à l'aide de macros, de préférences et d'arguments d'exécution : Cloud Data Fusion vous permet de réutiliser des pipelines de données. Avec les pipelines de données réutilisables, vous pouvez disposer d'un seul pipeline pouvant appliquer un modèle d'intégration de données à différents cas d'utilisation et ensembles de données. Les pipelines réutilisables offrent une meilleure gestion. Ils vous permettent de définir la majeure partie de la configuration d'un pipeline au moment de l'exécution, au lieu de la coder en dur au moment de la conception. Dans Pipeline Design Studio, vous pouvez utiliser des macros pour ajouter des variables aux configurations de plug-in afin de spécifier les substitutions de variables au moment de l'exécution. Pour en savoir plus, consultez la section Gérer les macros, les préférences et les arguments d'exécution.
Exécuter: une fois que vous avez examiné les configurations du pipeline, vous pouvez lancer son exécution. Vous pouvez voir l'état changer au cours des phases de l'exécution du pipeline, par exemple le provisionnement, le démarrage, l'exécution et la réussite.
Planification et orchestration: les pipelines de données par lot peuvent être configurés pour s'exécuter selon une planification et une fréquence spécifiées. Une fois que vous avez créé et déployé un pipeline, vous pouvez créer une planification. Dans Pipeline Design Studio, vous pouvez orchestrer des pipelines en créant un déclencheur sur un pipeline de données par lot pour qu'il s'exécute une fois qu'un ou plusieurs pipelines ont été exécutés. Il s'agit des pipelines en aval et en amont. Vous créez un déclencheur sur le pipeline en aval afin qu'il s'exécute en fonction de la fin d'un ou de plusieurs pipelines en amont.
Recommandation: Vous pouvez également utiliser Composer pour orchestrer des pipelines dans Cloud Data Fusion. Pour en savoir plus, consultez les pages Planifier des pipelines et Orchestrer des pipelines.
Modifier des pipelines: Cloud Data Fusion vous permet de modifier un pipeline déployé. Lorsque vous modifiez un pipeline déployé, une nouvelle version du pipeline est créée avec le même nom et est marquée comme dernière version. Cela vous permet de développer des pipelines de manière itérative plutôt que de dupliquer des pipelines, ce qui crée un nouveau pipeline avec un nom différent. Pour en savoir plus, consultez la section Modifier des pipelines.
Gestion du contrôle des sources: Cloud Data Fusion vous permet de mieux gérer les pipelines entre le développement et la production grâce à la gestion du contrôle des sources des pipelines à l'aide de GitHub.
Journalisation et surveillance: pour surveiller les métriques et les journaux du pipeline, nous vous recommandons d'activer le service de journalisation Stackdriver pour utiliser Cloud Logging avec votre pipeline Cloud Data Fusion.
Étape suivante
- Découvrez comment gérer l'administration de Studio.