アーキテクチャ
次の図は、Workflows を使用したサーバーレスのパイプラインの抽出、読み込み、変換(ELT)のハイレベル アーキテクチャを示しています。

上の図では、さまざまな店舗からセールス イベントを定期的にファイルとして収集し、Cloud Storage バケットにそのファイルを書き込む小売業のプラットフォームについて検討します。イベントは、BigQuery でインポートおよび処理を行うことにより、ビジネス指標を提供するために使用されます。このアーキテクチャには、ファイルを BigQuery にインポートする、信頼性が高いサーバーレスのオーケストレーション システムが用意されており、次の 2 つのモジュールに分けられます。
- ファイルリスト: Firestore コレクションの Cloud Storage バケットに追加された、未処理のファイルのリストを保持します。このモジュールは、Cloud Storage バケットに新しいファイルが追加されると生成される Object Finalize ストレージ イベントによってトリガーされる Cloud Run 関数を介して動作します。ファイル名は、Firestore で
newという名前のコレクションのfiles配列に追加されます。 ワークフロー: スケジュール設定されたワークフローを実行します。Cloud Scheduler では、YAML ベースの構文に従って一連の手順を実行するワークフローがトリガーされ、読み込みがオーケストレートされると、Cloud Run 関数を呼び出して BigQuery 内のデータが変換されます。ワークフローの手順では、Cloud Run 関数を呼び出して次のタスクを実行します。
- BigQuery の読み込みジョブを作成して開始します。
- 読み込みジョブのステータスをポーリングします。
- 変換クエリジョブを作成して開始します。
- 変換ジョブのステータスをポーリングします。
トランザクションを使用して Firestore で新しいファイルのリストを保持すると、ワークフローによってファイルが BigQuery にインポートされるときに、ファイルの見落しが確実になくなります。ワークフローの個別の実行は、ジョブのメタデータとステータスを Firestore に保存することで、べき等になります。
目標
- Firestore データベースを作成します。
- Cloud Run 関数のトリガーが、Firestore の Cloud Storage バケットに追加されたファイルを追跡するようセットアップします。
- Cloud Run 関数をデプロイして、BigQuery ジョブを実行、モニタリングします。
- ワークフローをデプロイして実行し、プロセスを自動化します。
費用
このドキュメントでは、課金対象である次の Google Cloudコンポーネントを使用します。
料金計算ツールを使うと、予想使用量に基づいて費用の見積もりを生成できます。
このドキュメントに記載されているタスクの完了後、作成したリソースを削除すると、それ以上の請求は発生しません。詳細については、クリーンアップをご覧ください。
始める前に
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Cloud Build, Cloud Run functions, Identity and Access Management, Resource Manager, and Workflows APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. [Welcome] ページに移動し、後の手順で使用する プロジェクト ID をメモします。
In the Google Cloud console, activate Cloud Shell.
環境を準備する
環境を準備するには、Firestore データベースを作成し、GitHub リポジトリからコードサンプルをクローニングします。Terraform を使用してリソースを作成し、Workflows YAML ファイルを編集して、ファイル ジェネレータの要件をインストールします。
Firestore データベースを作成する方法は次のとおりです。
Google Cloud コンソールで、[Firestore] ページに移動します。
[ネイティブ モードを選択] をクリックします。
[ロケーションを選択] メニューで、Firestore データベースをホストするリージョンを選択します。物理的なロケーションに近いリージョンを選択することをおすすめします。
[データベースを作成] をクリックします。
Cloud Shell で、ソース リポジトリのクローンを作成します。
cd $HOME && git clone https://github.com/GoogleCloudPlatform/workflows-demos cd workflows-demos/workflows-bigquery-loadCloud Shell で、Terraform を使用して次のリソースを作成します。
terraform init terraform apply \ -var project_id=PROJECT_ID \ -var region=REGION \ -var zone=ZONE \ --auto-approve次のように置き換えます。
PROJECT_ID: 実際の Google Cloud プロジェクト IDREGION: リソースをホストする特定の Google Cloud地理的なロケーション(例:us-central1)ZONE: リソースをホストするリージョン内のロケーション(例:us-central1-b)
次のようなメッセージが表示されます。
Apply complete! Resources: 7 added, 0 changed, 1 destroyed.Terraform を使用すると、大規模に安全で予想通りに、インフラストラクチャを作成、変更、アップグレードできます。プロジェクトに以下のリソースが作成されます。
- リソースへの安全なアクセスを確保するために必要な権限を持つサービス アカウント。
serverless_elt_datasetという名前の BigQuery データセットと、受信ファイルを読み込むword_countという名前のテーブル。- 入力ファイルをステージングするための
${project_id}-ordersbucketという名前の Cloud Storage バケット。 - 次の 5 つの Cloud Run 関数
file_add_handlerによって、Cloud Storage バケットに追加されたファイルの名前が Firestore コレクションに追加されます。create_jobによって、新しい BigQuery 読み込みジョブが作成され、Firebase コレクション内のファイルがジョブに関連付けられます。create_queryによって、新しい BigQuery クエリジョブが作成されます。poll_bigquery_jobによって、BigQuery ジョブのステータスが取得されます。run_bigquery_jobによって、BigQuery ジョブが開始されます。
前の手順でデプロイした
create_job、create_query、poll_job、run_bigquery_jobの各 Cloud Run functions の URL を取得します。gcloud functions describe create_job | grep url gcloud functions describe poll_bigquery_job | grep url gcloud functions describe run_bigquery_job | grep url gcloud functions describe create_query | grep url
出力は次のようになります。
url: https://REGION-PROJECT_ID.cloudfunctions.net/create_job url: https://REGION-PROJECT_ID.cloudfunctions.net/poll_bigquery_job url: https://REGION-PROJECT_ID.cloudfunctions.net/run_bigquery_job url: https://REGION-PROJECT_ID.cloudfunctions.net/create_query
これらの URL はワークフローのデプロイ時に必要になるため、メモしておきます。
ワークフローを作成してデプロイする
Cloud Shell で、ワークフロー
workflow.yamlのソースファイルを開きます。次のように置き換えます。
CREATE_JOB_URL: 新しいジョブを作成する関数の URLPOLL_BIGQUERY_JOB_URL: 実行中のジョブのステータスをポーリングする関数の URLRUN_BIGQUERY_JOB_URL: BigQuery 読み込みジョブを開始する関数の URLCREATE_QUERY_URL: BigQuery クエリジョブを開始する関数の URLBQ_REGION: データが保存される BigQuery リージョン(例:US)BQ_DATASET_TABLE_NAME: BigQuery データセット テーブル名(PROJECT_ID.serverless_elt_dataset.word_count形式)
workflowファイルをデプロイします。gcloud workflows deploy WORKFLOW_NAME \ --location=WORKFLOW_REGION \ --description='WORKFLOW_DESCRIPTION' \ --service-account=workflow-runner@PROJECT_ID.iam.gserviceaccount.com \ --source=workflow.yaml以下を置き換えます。
WORKFLOW_NAME: ワークフローの固有の名前WORKFLOW_REGION: ワークフローがデプロイされているリージョン(例:us-central1)WORKFLOW_DESCRIPTION: ワークフローの説明
Python 3 仮想環境を作成し、ファイル生成ツールの要件をインストールします。
sudo apt-get install -y python3-venv python3 -m venv env . env/bin/activate cd generator pip install -r requirements.txt
インポートするファイルを生成する
gen.pyPython スクリプトは、Avro 形式でランダムなコンテンツを生成します。スキーマは BigQueryword_countテーブルと同じです。これらの Avro ファイルは、指定された Cloud Storage バケットにコピーされます。Cloud Shell で、以下のファイルを生成します。
python gen.py -p PROJECT_ID \ -o PROJECT_ID-ordersbucket \ -n RECORDS_PER_FILE \ -f NUM_FILES \ -x FILE_PREFIX以下を置き換えます。
RECORDS_PER_FILE: 単一のファイル内のレコード数NUM_FILES: アップロードされるファイルの総数FILE_PREFIX: 生成されたファイルの名前の接頭辞
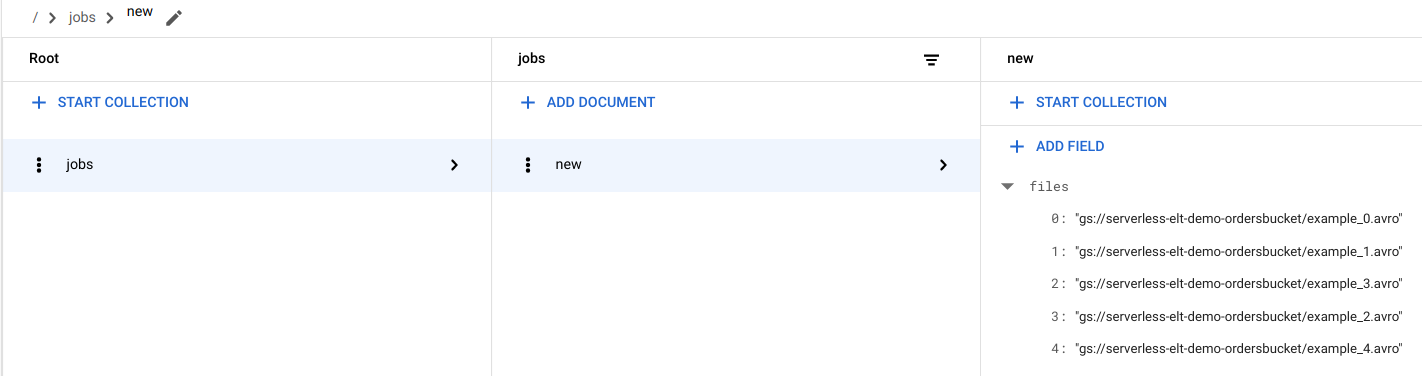
Firestore でファイル エントリを確認する
ファイルが Cloud Storage にコピーされると、
handle_new_fileCloud Run 関数がトリガーされます。この関数によって、Firestorejobsコレクション内のnewドキュメントのファイルリスト配列にファイルリストが追加されます。ファイルリストを表示するには、 Google Cloud コンソールで Firestore の [データ] ページに移動します。
ワークフローをトリガーする
Workflows によって、Google Cloud と API サービスから、一連のサーバーレス タスクが同時にリンクされます。このワークフローの個々の手順は Cloud Run 関数として実行され、その状態は Firestore に保存されます。Cloud Run 関数への呼び出しはすべて、ワークフローのサービス アカウントを使用して認証されます。
Cloud Shell で、ワークフローを実行します。
gcloud workflows execute WORKFLOW_NAME
次の図に、このワークフローで使用される手順を示します。

ワークフローは、メイン ワークフローとサブ ワークフローの 2 つの部分にわかれています。メイン ワークフローはジョブの作成と条件付き実行を処理する一方で、サブワークフローは BigQuery ジョブを実行します。このワークフローでは、次の操作が行われます。
create_jobCloud Run 関数によって、新しいジョブ オブジェクトが作成され、Firestore ドキュメントから Cloud Storage に追加されたファイルのリストが取得され、そのファイルが読み込みジョブに関連付けられます。読み込み対象のファイルが存在しない場合、関数は新しいジョブを作成しません。create_queryCloud Run 関数では、実行する必要があるクエリと、そのクエリを実行する必要がある BigQuery リージョンが一緒に受け取られます。この関数では、Firestore でジョブが作成されてジョブ ID が返されます。run_bigquery_jobCloud Run 関数によって、実行する必要があるジョブの ID が取得され、BigQuery API が呼び出されてジョブが送信されます。- この Cloud Run 関数でジョブが完了するのを待機する代わりに、定期的にジョブのステータスをポーリングできます。
poll_bigquery_jobCloud Run 関数によって、ジョブのステータスが提供されます。ジョブが完了するまで繰り返し呼び出されます。poll_bigquery_jobCloud Run 関数への呼び出し間に遅延を追加するには、Workflows からsleepルーチンを呼び出します。
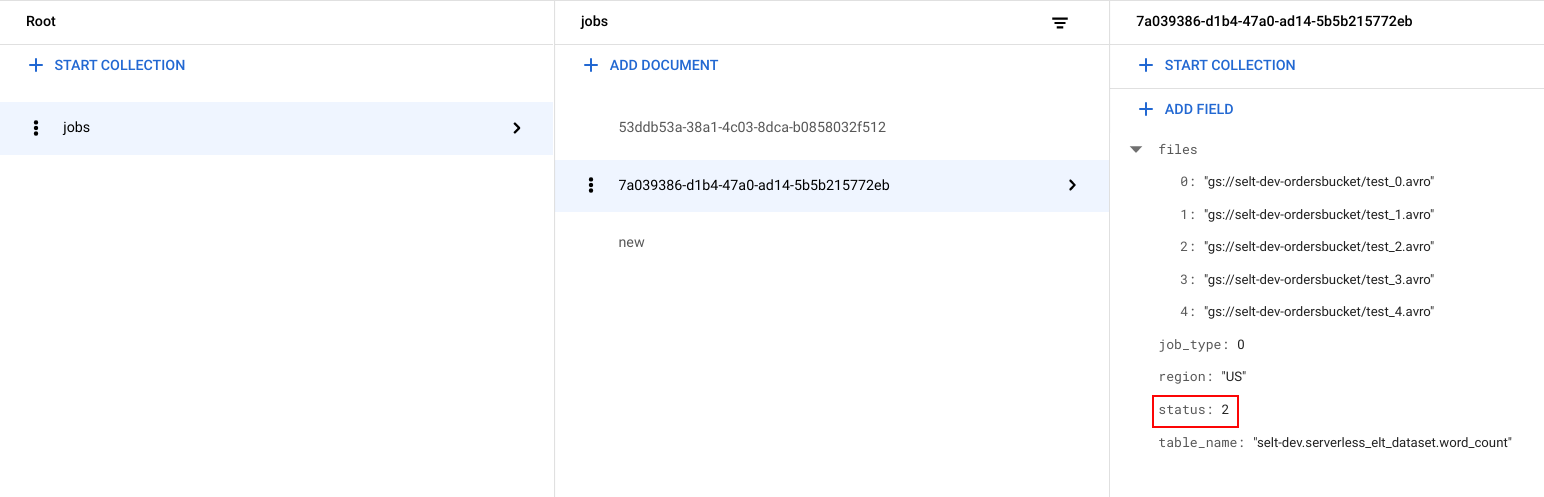
ジョブのステータスを確認する
ファイル リストとジョブのステータスを表示できます。
Google Cloud コンソールで、Firestore の [データ] ページに移動します。
ジョブごとに固有識別子(UUID)が生成されます。
job_typeとstatusを確認するには、ジョブ ID をクリックします。各ジョブには次のいずれかのタイプとステータスがあります。job_type: 次のいずれかの値があるワークフローによって実行されているジョブのタイプ。- 0: BigQuery へデータを読み込みます。
- 1: BigQuery でクエリを実行します。
status: 次のいずれかの値があるジョブの現在の状態。- 0: ジョブは作成されていますが、開始されていません。
- 1: ジョブが実行中。
- 2: ジョブの実行が正常に完了しました。
- 3: エラーが発生し、ジョブが正常に完了しませんでした。
ジョブ オブジェクトには、BigQuery データセットのリージョン、BigQuery テーブルの名前などのメタデータ属性も含まれます。そのジョブ オブジェクトがクエリジョブの場合は、実行中のクエリ文字列が含まれます。
BigQuery でデータを確認する
ELT ジョブが成功したことを確認するには、データがテーブルに表示されていることを確認します。
Google Cloud コンソールで、BigQuery の [エディタ] ページに移動します。
[
serverless_elt_dataset.word_count] テーブルをクリックします。[プレビュー] タブをクリックします。
![テーブルにデータを表示している [プレビュー] タブ。](https://cloud.google.com/static/workflows/images/serverless-orchestration-loading-data-from-cloud-storage-to-biquery-using-workflows-5-word-count.png?hl=ja)
ワークフローをスケジュールする
スケジュールに沿ってワークフローを定期的に実行するには、Cloud Scheduler を使用します。
クリーンアップ
課金をなくす最も簡単な方法は、チュートリアル用に作成した Google Cloud プロジェクトを削除することです。また、リソースを個別に削除することもできます。個々のリソースの削除
Cloud Shell で、Terraform を使用して作成したすべてのリソースを削除します。
cd $HOME/bigquery-workflows-load terraform destroy \ -var project_id=PROJECT_ID \ -var region=REGION \ -var zone=ZONE \ --auto-approve
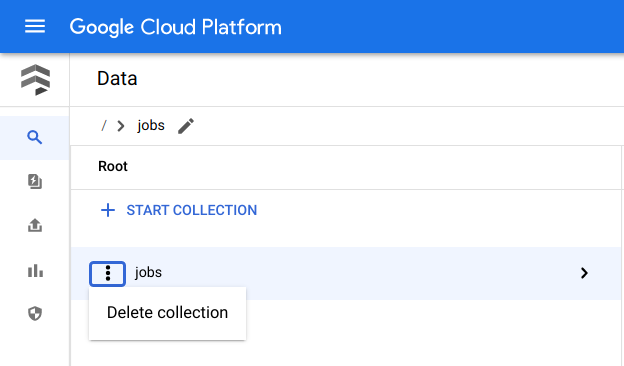
Google Cloud コンソールで、Firestore の [データ] ページに移動します。
[ジョブ] の横にある [メニュー] をクリックし、[削除] を選択します。
プロジェクトの削除
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
次のステップ
- BigQuery の詳細については、BigQuery のドキュメントをご覧ください。
- サーバーレスのカスタム機械学習パイプラインを構築する方法を確認する。
- Cloud アーキテクチャ センターで、リファレンス アーキテクチャ、図、ベスト プラクティスを確認する。