Vertex AI Platform
借助由 Gemini 模型增强的企业级 AI 技术,加快创新速度
Vertex AI 是一个全托管式统一 AI 开发平台,用于构建和使用生成式 AI。获取并使用 Vertex AI Studio、Agent Builder 和 200 多种基础模型。
新客户最高可获享 $300 赠金,用于试用 Vertex AI 和其他 Google Cloud 产品。
功能
Gemini - Google 强大的多模态模型
Vertex AI 支持使用 Google 的最新 Gemini 模型。Gemini 能够理解几乎任何输入、组合不同类型的信息,还能生成几乎任何输出。在 Vertex AI Studio 中使用文本、图片、视频或代码发出提示并测试 Gemini。利用 Gemini 的高级推理和先进的生成功能,开发者可以尝试使用示例提示,从而提取图片中的文本、将图片文本转换为 JSON,甚至可以针对上传的图片生成答案,以构建新一代 AI 应用。

200 多种生成式 AI 模型和工具
Model Garden 中提供了丰富的第一方模型(Gemini、Imagen、Chirp、Veo)、第三方模型(Anthropic 的 Claude 模型系列)和开放模型(Gemma、Llama 3.2)供您选择。使用扩展程序使模型能够检索实时信息和触发操作。您可以使用适用于 Google 的文本、图片或代码模型的各种调优选项,根据您自己的应用场景自定义模型。
借助生成式 AI 模型和全托管式工具,您可以轻松地设计模型原型、自定义模型,并将模型集成和部署到应用中。
开放的集成式 AI 平台
借助 Vertex AI Platform 中用于训练、调整和部署机器学习模型的工具,数据科学家可以提高工作效率。
Vertex AI 笔记本(包括您选择的 Colab Enterprise 或 Workbench)与 BigQuery 原生集成,提供了一个涵盖所有数据和 AI 工作负载的平台。
在 Vertex AI Training 和 Prediction 的帮助下,您使用自己选择的开源框架和经过优化的 AI 基础架构缩短训练时间并将模型轻松部署到生产环境中。
适用于预测式 AI 和生成式 AI 的 MLOps
Vertex AI Platform 为数据科学家和机器学习工程师提供专用的 MLOps 工具,可用于机器学习项目的自动化、标准化和管理。
利用模块化工具,您可以在整个开发生命周期中跨团队协作并优化模型,这包括通过 Vertex AI Evaluation 确定适合某个应用场景的最佳模型、使用 Vertex AI Pipelines 编排工作流、使用 Model Registry 管理任何模型、通过 Feature Store 提供、共享和重复使用机器学习功能,以及监控模型的输入偏差和偏移。
Agent Builder
Vertex AI Agent Builder 让开发者能够轻松构建和部署适合企业的生成式 AI 体验。它提供便利的无代码代理构建器控制台,以及强大的标准答案关联、编排和自定义功能。借助 Vertex AI Agent Builder,开发者可以基于其组织数据快速创建一系列生成式 AI 客服和应用。
工作方式
Vertex AI 提供了多种模型训练和部署选项:
- 生成式 AI 让您可以使用大型生成式 AI 模型(包括 Gemini 2.5),以便您可以评估、调优和部署这些模型,以用于 AI 赋能的应用。
- 借助 Model Garden,您可以发现、测试、自定义和部署 Vertex AI 及部分开源 (OSS) 模型和资源。
- 自定义训练使您能够完全控制训练过程,包括使用您偏好的机器学习框架、编写自己的训练代码以及选择超参数调节选项。
Vertex AI 提供了多种模型训练和部署选项:
- 生成式 AI 让您可以使用大型生成式 AI 模型(包括 Gemini 2.5),以便您可以评估、调优和部署这些模型,以用于 AI 赋能的应用。
- 借助 Model Garden,您可以发现、测试、自定义和部署 Vertex AI 及部分开源 (OSS) 模型和资源。
- 自定义训练使您能够完全控制训练过程,包括使用您偏好的机器学习框架、编写自己的训练代码以及选择超参数调节选项。
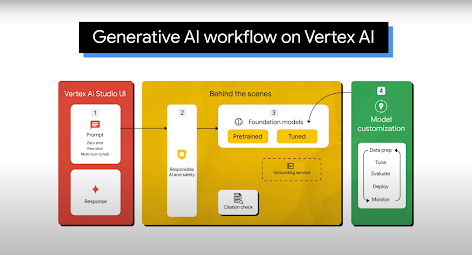
常见用途
使用 Gemini 进行构建
在 Google Cloud Vertex AI 中通过 Gemini API 访问 Gemini 模型
- Python
- JavaScript
- Java
- Go
- Curl
代码示例
在 Google Cloud Vertex AI 中通过 Gemini API 访问 Gemini 模型
- Python
- JavaScript
- Java
- Go
- Curl
生成式 AI 实际应用
获取 Vertex AI 上的生成式 AI 简介
Vertex AI Studio 提供 Google Cloud 控制台工具,用于对生成式 AI 模型快速进行原型设计和测试。了解如何使用 Generative AI Studio 执行以下任务:使用提示示例测试模型、设计和保存提示、对基础模型进行调优,以及在语音和文字之间转换。
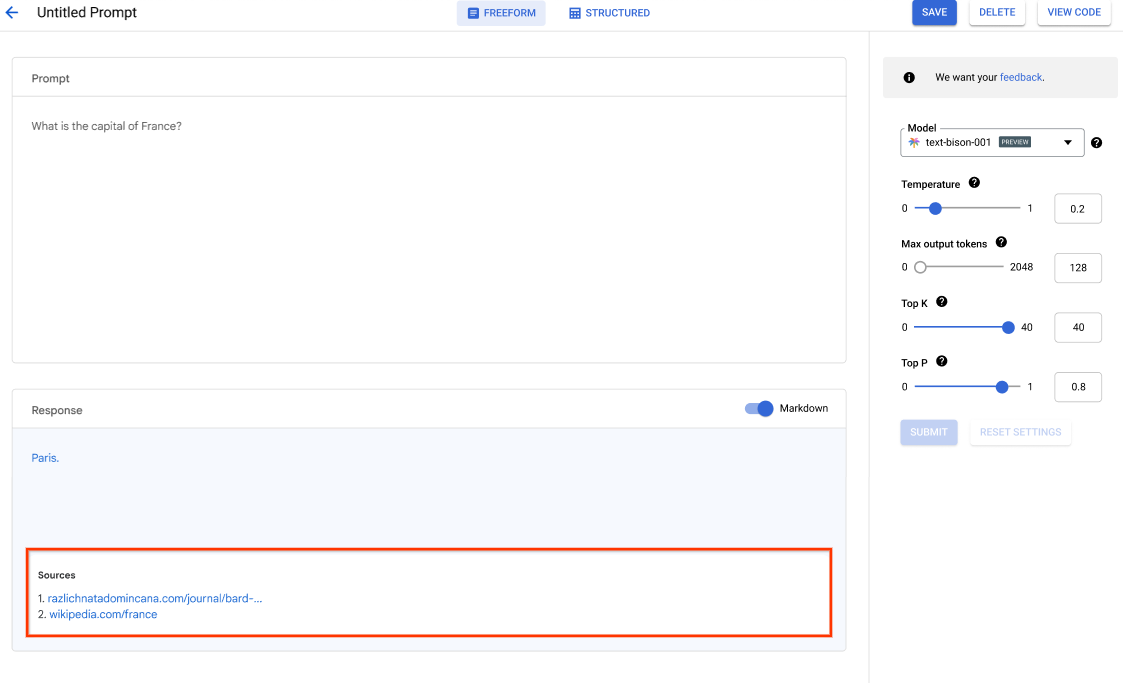
了解如何在 Vertex AI Studio 中调整 LLM。
教程、快速入门和实验
获取 Vertex AI 上的生成式 AI 简介
Vertex AI Studio 提供 Google Cloud 控制台工具,用于对生成式 AI 模型快速进行原型设计和测试。了解如何使用 Generative AI Studio 执行以下任务:使用提示示例测试模型、设计和保存提示、对基础模型进行调优,以及在语音和文字之间转换。
了解如何在 Vertex AI Studio 中调整 LLM。
提取、汇总数据,以及对数据进行分类
使用生成式 AI 进行摘要、分类和提取
了解如何使用 Vertex AI 的生成式 AI 支持创建用于处理任意数量任务的文本提示。一些最常见的任务包括分类、摘要和提取。借助 Gemini on Vertex AI,您可以灵活地设计提示的结构和格式。
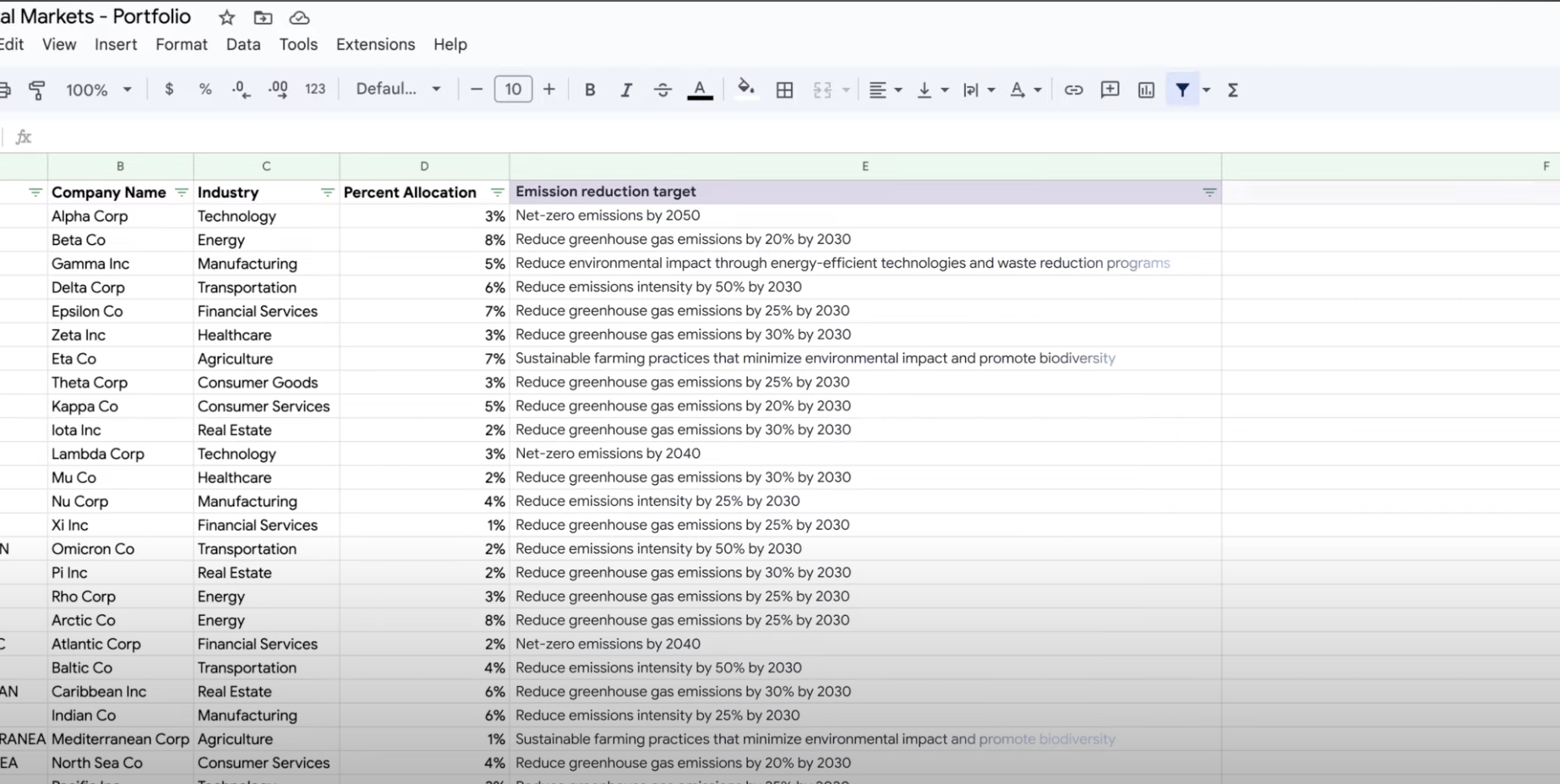
教程、快速入门和实验
使用生成式 AI 进行摘要、分类和提取
了解如何使用 Vertex AI 的生成式 AI 支持创建用于处理任意数量任务的文本提示。一些最常见的任务包括分类、摘要和提取。借助 Gemini on Vertex AI,您可以灵活地设计提示的结构和格式。
价格
| Vertex AI 定价方式 | 按所使用的 Vertex AI 工具、存储、计算和 Google Cloud 资源付费。新客户可获赠 $300 赠金,用于试用 Vertex AI 和 Google Cloud 产品。 | |
|---|---|---|
| 工具和用法 | 说明 | 价格 |
生成式 AI | 用于生成图片的 Imagen 模型 基于图片输入、字符输入或自定义训练价格。 | 起价 $0.0001 |
文本、聊天和代码生成 基于每 1,000 个输入字符(提示)和每 1,000 个输出字符(回复)。 | 起价 $0.0001 每 1,000 个字符 | |
AutoML 模型 | 图片数据训练、部署和预测 基于每节点时训练时间(反映了资源用量),以及用于分类还是对象检测。 | 起价 $1.375 每节点时 |
视频数据训练和预测 基于每节点时价格,以及是分类、对象跟踪还是动作识别。 | 起价 $0.462 每节点时 | |
表格数据训练和预测 基于每节点时价格,以及是分类/回归还是预测。与销售人员联系,了解可能的折扣和价格详情。 | 联系业务代表 | |
文本数据上传、训练、部署、预测 训练和预测按每小时费率结算,用于上传旧式数据(仅限 PDF)的页面,并可使用文本记录和页面来进行预测。 | 起价 $0.05 (每小时) | |
自定义训练模型 | 联系业务代表 | |
Vertex AI 笔记本 | 计算和存储资源 基于与 Compute Engine 和 Cloud Storage 相同的费率。 | 参阅产品 |
管理费 除上述资源用量外,您还需要根据所使用的区域、实例、笔记本和代管式笔记本支付管理费用。查看详细信息。 | 参阅详细信息 | |
Vertex AI Pipelines | 执行费用和额外费用 基于执行费用、使用的资源和任何其他服务费。 | 起价 $0.03 每次流水线运行 |
Vertex AI Vector Search | 服务和构建费用 基于数据大小、您要运行的每秒查询次数 (QPS) 和使用的节点数。查看示例。 | 参考示例 |
查看所有 Vertex AI 功能和服务的价格详情。
Vertex AI 定价方式
按所使用的 Vertex AI 工具、存储、计算和 Google Cloud 资源付费。新客户可获赠 $300 赠金,用于试用 Vertex AI 和 Google Cloud 产品。
文本、聊天和代码生成
基于每 1,000 个输入字符(提示)和每 1,000 个输出字符(回复)。
Starting at
$0.0001
每 1,000 个字符
图片数据训练、部署和预测
基于每节点时训练时间(反映了资源用量),以及用于分类还是对象检测。
Starting at
$1.375
每节点时
视频数据训练和预测
基于每节点时价格,以及是分类、对象跟踪还是动作识别。
Starting at
$0.462
每节点时
文本数据上传、训练、部署、预测
训练和预测按每小时费率结算,用于上传旧式数据(仅限 PDF)的页面,并可使用文本记录和页面来进行预测。
Starting at
$0.05
(每小时)
执行费用和额外费用
基于执行费用、使用的资源和任何其他服务费。
Starting at
$0.03
每次流水线运行
查看所有 Vertex AI 功能和服务的价格详情。
业务用例
充分发挥生成式 AI 的潜力

“Google Cloud 的生成式 AI 解决方案的准确性和 Vertex AI Platform 的实用性让我们信心十足地在业务核心领域实施这项尖端技术,并实现了我们的零分钟响应时间这一长期目标。”
GA Telesis 首席执行官 Abdol Moabery
分析师报告
TKTKT
Google 在 2024 年第 1 季度的《Forrester Wave™:AI 基础设施解决方案》报告中被评为业界领导者,在“当前产品”和“战略”两项评估维度中,得分均高于其他所有供应商。
Google 在 2024 年第 2 季度的《Forrester Wave™:语言 AI 基础模型》报告中被评为业界领导者。阅读报告。
Google 在《Forrester Wave:AI/机器学习平台,2024 年第 3 季度》报告中被评为业界领导者。了解详情。











