Vertex AI Platform
Innova más rápido con una IA preparada para el ámbito empresarial, mejorada por los modelos de Gemini
Vertex AI es una plataforma de desarrollo de IA unificada y totalmente gestionada para desarrollar y usar IA generativa. Accede y usa Vertex AI Studio, Agent Builder y más de 200 modelos fundacionales.
Los nuevos clientes reciben hasta 300 USD en crédito gratis para probar Vertex AI y otros productos de Google Cloud.
Características
Gemini, los modelos multimodales más eficaces de Google
Vertex AI ofrece acceso a los últimos modelos de Gemini de Google. Gemini es capaz de comprender prácticamente cualquier entrada gracias a la combinación de diferentes tipos de información, y de generar casi cualquier salida. Prueba y realiza peticiones a Gemini en Vertex AI Studio con texto, imágenes, vídeo o código. Gracias al razonamiento avanzado y las funciones innovadoras de generación de Gemini, los desarrolladores pueden probar peticiones de ejemplo para extraer texto de imágenes, convertir texto de imagen a JSON e incluso generar respuestas sobre imágenes subidas para crear aplicaciones de IA de nueva generación.

Más de 200 modelos y herramientas de IA generativa
Elige entre la más amplia variedad de modelos propios (Gemini, Imagen, Chirp o Veo), de terceros (Anthropic's Claude Model Family) y abiertos (Gemmao Llama 3.2) disponibles en Model Garden. Usa extensiones para permitir que los modelos recuperen información en tiempo real y activen acciones. Personaliza los modelos para tu caso práctico con una variedad de opciones de afinamiento para los modelos de texto, imagen o código de Google.
Con los modelos de IA generativa y las herramientas totalmente gestionadas resulta fácil crear prototipos, personalizarlos, integrarlos y desplegarlos en aplicaciones.
Plataforma de IA abierta e integrada
Los científicos de datos pueden avanzar más rápido con las herramientas de Vertex AI Platform para entrenar, ajustar y desplegar modelos de aprendizaje automático.
Los cuadernos de Vertex AI, incluidos Colab Enterprise o Workbench, están integrados de forma nativa en BigQuery, lo que proporciona una única superficie para todas las cargas de trabajo de datos e IA.
Vertex AI Training y Prediction te ayudan a reducir el tiempo de entrenamiento y a desplegar modelos en producción fácilmente con los frameworks de código abierto que elijas y la infraestructura de IA optimizada.
MLOps para la IA predictiva y generativa
Vertex AI Platform ofrece herramientas de MLOps diseñadas específicamente para que los científicos de datos y los ingenieros de aprendizaje automático puedan automatizar, estandarizar y gestionar proyectos de aprendizaje automático.
Las herramientas modulares te ayudan a colaborar entre equipos y a mejorar modelos a lo largo de todo el ciclo de vida de desarrollo: identifica el modelo más adecuado para un caso práctico con Vertex AI Evaluation, orquesta los flujos de trabajo con Vertex AI Pipelines , gestionar cualquier modelo con Model Registry, servir, compartir y reutilizar las funciones de aprendizaje automático mediante Feature Store, y monitorizar los modelos para encontrar sesgos de entrada.
Agent Builder
Vertex AI Agent Builder permite a los desarrolladores crear y desplegar fácilmente experiencias de IA generativa preparadas para el ámbito empresarial. Ofrece la comodidad de una consola de creación de agentes sin código, además de potentes funciones de base, orquestación y personalización. Con Vertex AI Agent Builder, los desarrolladores pueden crear rápidamente una serie de agentes y aplicaciones de IA generativa basados en los datos de su organización.
Cómo funciona
Vertex AI ofrece varias opciones para el entrenamiento y el despliegue de modelos:
- La IA generativa te da acceso a grandes modelos de IA generativa, como Gemini 2.5, para que puedas evaluarlos, ajustarlos y desplegarlos para usarlos en tus aplicaciones basadas en IA.
- Model Garden te permite descubrir, probar, personalizar y desplegar Vertex AI, así como seleccionar modelos y recursos de código abierto.
- El entrenamiento personalizado te da un control absoluto sobre el proceso de entrenamiento, como usar el framework de aprendizaje automático que prefieras, escribir tu propio código de entrenamiento y elegir las opciones de ajuste de hiperparámetros.
Vertex AI ofrece varias opciones para el entrenamiento y el despliegue de modelos:
- La IA generativa te da acceso a grandes modelos de IA generativa, como Gemini 2.5, para que puedas evaluarlos, ajustarlos y desplegarlos para usarlos en tus aplicaciones basadas en IA.
- Model Garden te permite descubrir, probar, personalizar y desplegar Vertex AI, así como seleccionar modelos y recursos de código abierto.
- El entrenamiento personalizado te da un control absoluto sobre el proceso de entrenamiento, como usar el framework de aprendizaje automático que prefieras, escribir tu propio código de entrenamiento y elegir las opciones de ajuste de hiperparámetros.
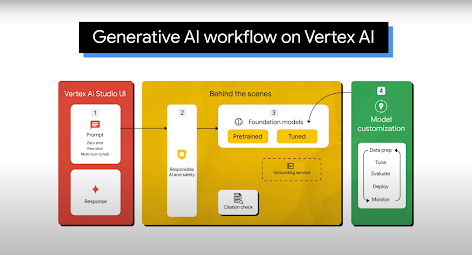
Usos habituales
Desarrolla con Gemini
Accede a modelos de Gemini a través de la API de Gemini en Vertex AI de Google Cloud
- Python
- JavaScript
- Java
- Go
- Curl
Código de ejemplo
Accede a modelos de Gemini a través de la API de Gemini en Vertex AI de Google Cloud
- Python
- JavaScript
- Java
- Go
- Curl
IA generativa en aplicaciones
Familiarízate con la IA generativa en Vertex AI
Generative AI Studio de Vertex AI ofrece una herramienta de la consola de Google Cloud para crear prototipos y probar modelos de IA generativa de forma rápida. Descubre cómo puedes usar Generative AI Studio para probar modelos usando muestras de solicitudes, diseñar y guardar peticiones, ajustar un modelo básico y completar conversiones entre voz y texto.
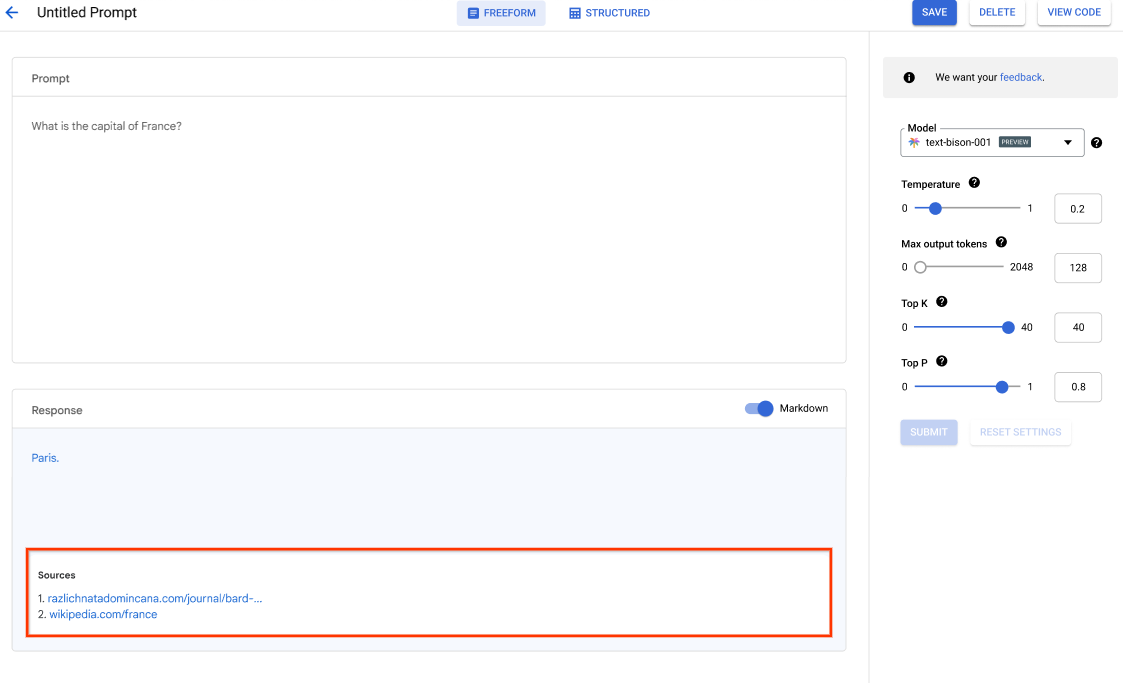
Cómo afinar los LLM en Generative AI Studio de Vertex AI.
Tutoriales, guías de inicio rápido y experimentos
Familiarízate con la IA generativa en Vertex AI
Generative AI Studio de Vertex AI ofrece una herramienta de la consola de Google Cloud para crear prototipos y probar modelos de IA generativa de forma rápida. Descubre cómo puedes usar Generative AI Studio para probar modelos usando muestras de solicitudes, diseñar y guardar peticiones, ajustar un modelo básico y completar conversiones entre voz y texto.
Cómo afinar los LLM en Generative AI Studio de Vertex AI.
Extraer, resumir y clasificar datos
Usa la IA generativa para el resumen, la clasificación y la extracción
Aprende a crear peticiones de texto para gestionar cualquier cantidad de tareas gracias a la compatibilidad con la IA generativa de Vertex AI. Algunas de las tareas más habituales son la clasificación, el resumen y la extracción. Gemini en Vertex AI te permite diseñar peticiones flexibles en cuanto a su estructura y formato.
Tutoriales, guías de inicio rápido y experimentos
Usa la IA generativa para el resumen, la clasificación y la extracción
Aprende a crear peticiones de texto para gestionar cualquier cantidad de tareas gracias a la compatibilidad con la IA generativa de Vertex AI. Algunas de las tareas más habituales son la clasificación, el resumen y la extracción. Gemini en Vertex AI te permite diseñar peticiones flexibles en cuanto a su estructura y formato.
Entrena modelos de aprendizaje automático personalizados
Descripción general y documentación de la preparación personalizada de aprendizaje automático
Consulta un videotutorial sobre los pasos necesarios para entrenar modelos personalizados en Vertex AI.
Tutoriales, guías de inicio rápido y experimentos
Descripción general y documentación de la preparación personalizada de aprendizaje automático
Consulta un videotutorial sobre los pasos necesarios para entrenar modelos personalizados en Vertex AI.
Desplegar un modelo para su uso en producción
Despliega para hacer predicciones online o por lotes
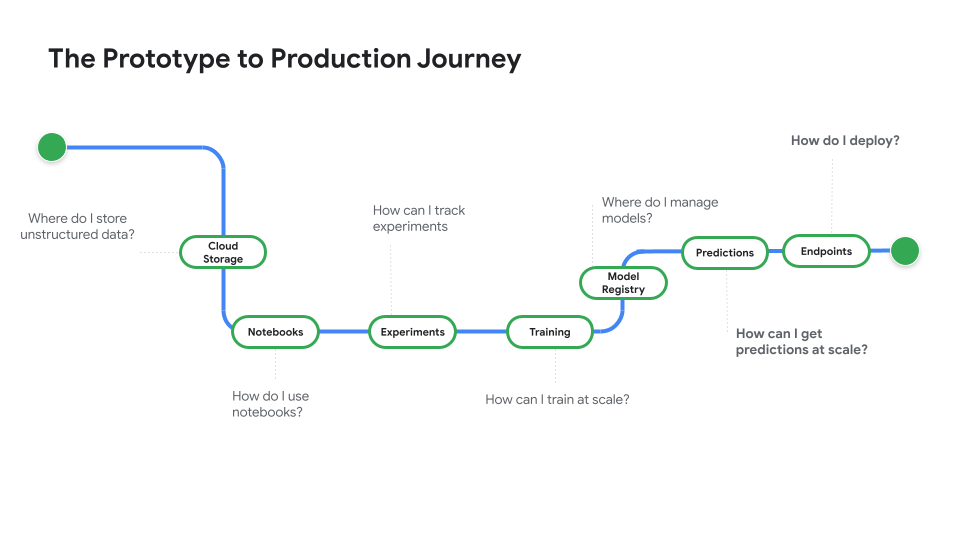
Echa un vistazo a Prototype to Production, una serie de vídeos que te traslada del código de un cuaderno a un modelo desplegado.
Tutoriales, guías de inicio rápido y experimentos
Despliega para hacer predicciones online o por lotes
Echa un vistazo a Prototype to Production, una serie de vídeos que te traslada del código de un cuaderno a un modelo desplegado.
Precios
| Cómo funcionan los precios de Vertex AI | Paga por las herramientas, el almacenamiento, los recursos de computación y los recursos de Cloud de Vertex AI que utilices. Los nuevos clientes reciben 300 USD en crédito gratis para probar Vertex AI y otros productos de Google Cloud. | |
|---|---|---|
| Herramientas y uso | Descripción | Precio |
IA generativa | Modelo de imagen para generar imágenes Se basa en la entrada de imágenes, la entrada de caracteres o los precios del entrenamiento personalizado. | Desde 0,0001 USD |
Generación de texto, chat y código Basado en cada 1000 caracteres de entrada (solicitud) y cada 1000 caracteres de salida (respuesta). | Desde 0,0001 USD por cada 1000 caracteres | |
Modelos de AutoML | Entrenamiento, despliegue y predicción de datos de imagen Se basa en el tiempo de entrenamiento por hora de nodo, que refleja el uso de los recursos y si se usa para clasificar o detectar objetos. | Desde 1,375 USD por hora de nodo |
Entrenamiento y predicción de datos de vídeo En función del precio por hora de nodo y de la clasificación, el seguimiento de objetos o el reconocimiento de acciones. | Desde 0,462 USD por hora de nodo | |
Predicción y entrenamiento de datos tabulares Se basan en el precio por hora de nodo y si se trata de una clasificación o regresión o de una previsión. Ponte en contacto con el equipo de Ventas para informarte sobre los posibles descuentos y los precios detallados. | Contactar con Ventas | |
Subida de datos de texto, entrenamiento, despliegue y predicción Se basan en las tarifas por hora de entrenamiento y predicción, páginas para subida de datos antiguos (solo en PDF) y registros de texto y páginas para predicciones. | Desde 0,05 USD por hora | |
Modelos con entrenamiento personalizado | Preparación de modelo personalizado Se basa en el tipo de máquina utilizado por hora, la región y los aceleradores utilizados. Obtén una estimación a través de las ventas o nuestra calculadora de precios. | Contactar con Ventas |
Cuadernos de Vertex AI | Recursos de computación y almacenamiento Está basado en las mismas tarifas que para Compute Engine y Cloud Storage. | Consulta los productos |
Comisiones de gestión Además de este uso de recursos, se aplican tarifas de gestión según la región, las instancias, los cuadernos y los cuadernos gestionados que se utilicen. Ver detalles. | Consultar detalles | |
Vertex AI Pipelines | Ejecución y tarifas adicionales Se basan en los cargos de ejecución, los recursos utilizados y las cuotas de servicio adicionales. | Desde 0,03 USD por ejecución de flujo de procesamiento |
Búsqueda de Vectores de Vertex AI | Costes de publicación y creación En función del tamaño de los datos, la cantidad de consultas por segundo (CPS) que quieras ejecutar y el número de nodos que uses. Ver ejemplo | Consulta el ejemplo |
Consulta los detalles de los precios de todas las funciones y servicios de Vertex AI.
Cómo funcionan los precios de Vertex AI
Paga por las herramientas, el almacenamiento, los recursos de computación y los recursos de Cloud de Vertex AI que utilices. Los nuevos clientes reciben 300 USD en crédito gratis para probar Vertex AI y otros productos de Google Cloud.
Modelo de imagen para generar imágenes
Se basa en la entrada de imágenes, la entrada de caracteres o los precios del entrenamiento personalizado.
Starting at
0,0001 USD
Generación de texto, chat y código
Basado en cada 1000 caracteres de entrada (solicitud) y cada 1000 caracteres de salida (respuesta).
Starting at
0,0001 USD
por cada 1000 caracteres
Entrenamiento, despliegue y predicción de datos de imagen
Se basa en el tiempo de entrenamiento por hora de nodo, que refleja el uso de los recursos y si se usa para clasificar o detectar objetos.
Starting at
1,375 USD
por hora de nodo
Entrenamiento y predicción de datos de vídeo
En función del precio por hora de nodo y de la clasificación, el seguimiento de objetos o el reconocimiento de acciones.
Starting at
0,462 USD
por hora de nodo
Predicción y entrenamiento de datos tabulares
Se basan en el precio por hora de nodo y si se trata de una clasificación o regresión o de una previsión. Ponte en contacto con el equipo de Ventas para informarte sobre los posibles descuentos y los precios detallados.
Contactar con Ventas
Subida de datos de texto, entrenamiento, despliegue y predicción
Se basan en las tarifas por hora de entrenamiento y predicción, páginas para subida de datos antiguos (solo en PDF) y registros de texto y páginas para predicciones.
Starting at
0,05 USD
por hora
Preparación de modelo personalizado
Se basa en el tipo de máquina utilizado por hora, la región y los aceleradores utilizados. Obtén una estimación a través de las ventas o nuestra calculadora de precios.
Contactar con Ventas
Recursos de computación y almacenamiento
Está basado en las mismas tarifas que para Compute Engine y Cloud Storage.
Consulta los productos
Comisiones de gestión
Además de este uso de recursos, se aplican tarifas de gestión según la región, las instancias, los cuadernos y los cuadernos gestionados que se utilicen. Ver detalles.
Consultar detalles
Ejecución y tarifas adicionales
Se basan en los cargos de ejecución, los recursos utilizados y las cuotas de servicio adicionales.
Starting at
0,03 USD
por ejecución de flujo de procesamiento
Búsqueda de Vectores de Vertex AI
Costes de publicación y creación
En función del tamaño de los datos, la cantidad de consultas por segundo (CPS) que quieras ejecutar y el número de nodos que uses. Ver ejemplo
Consulta el ejemplo
Consulta los detalles de los precios de todas las funciones y servicios de Vertex AI.
Empieza tu prueba de concepto
Caso de negocio
Aprovecha todo el potencial de la IA generativa

"La precisión de la solución de IA generativa de Google Cloud y la utilidad práctica de Vertex AI Platform nos dan la confianza que necesitábamos para implementar esta tecnología vanguardista en los pilares de nuestro negocio y alcanzar el objetivo a largo plazo de reducir nuestro tiempo de respuesta a menos de 1 minuto".
Abdol Moabery, CEO de GA Telesis
Informes de analistas
TKTKT
Google ha recibido la designación de líder en The Forrester Wave™: AI Infrastructure Solutions (primer trimestre del 2024) y ha obtenido la puntuación más alta de todos los proveedores evaluados en las categorías de ofertas actuales y estrategia.
Google es líder en The Forrester Wave™: modelos fundacionales de IA para el lenguaje, segundo trimestre de 2024. Leer el informe
Google ha recibido la designación de líder en el informe Forrester Wave sobre plataformas de IA y aprendizaje automático del tercer trimestre del 2024. Más información.











