Platform Vertex AI
Berinovasi lebih cepat dengan AI yang siap digunakan perusahaan, yang ditingkatkan dengan model Gemini
Vertex AI adalah platform pengembangan AI terpadu dan terkelola sepenuhnya untuk membangun dan menggunakan AI generatif. Akses dan manfaatkan Vertex AI Studio, Agent Builder, dan lebih dari 200 model dasar.
Pelanggan baru mendapatkan kredit gratis senilai hingga $300 untuk mencoba Vertex AI dan produk Google Cloud lainnya.
Fitur
Gemini, model multimodal tercanggih Google
Vertex AI menawarkan akses ke model Gemini terbaru dari Google. Gemini mampu memahami secara virtual hampir semua input, menggabungkan berbagai jenis informasi, dan menghasilkan hampir semua output. Buat perintah dan uji Gemini di Vertex AI Studio menggunakan teks, gambar, video, atau kode. Dengan menggunakan penalaran canggih dan kemampuan pembuatan yang canggih dari Gemini, developer dapat mencoba contoh prompt untuk mengekstrak teks dari gambar, mengonversi teks gambar menjadi JSON, dan bahkan menghasilkan jawaban tentang gambar yang diupload untuk membangun aplikasi AI generasi berikutnya.

Lebih dari 200 alat dan model AI generatif
Pilih dari beragam model yang mencakup model pihak pertama (Gemini, Imagen, Chirp, Veo), pihak ketiga (Anthropic Claude Model Family), dan model open source (Gemma, Llama 3.2) di Model Garden. Gunakan ekstensi untuk memungkinkan model mengambil informasi real-time dan memicu tindakan. Sesuaikan model dengan kasus penggunaan Anda menggunakan berbagai opsi penyesuaian untuk model, teks, gambar, atau kode Google.
Model AI generatif dan alat yang terkelola sepenuhnya memudahkan untuk membuat prototipe, menyesuaikan, serta mengintegrasikan dan men-deploy-nya ke dalam aplikasi.
Platform AI terbuka dan terintegrasi
Data scientist dapat bergerak lebih cepat dengan alat Vertex AI Platform untuk pelatihan, penyesuaian, dan deployment model ML.
Notebook Vertex AI, termasuk Colab Enterprise atau Workbench pilihan Anda, terintegrasi secara native dengan BigQuery yang menyediakan satu platform untuk semua workload data dan AI.
Vertex AI Training dan Prediction membantu Anda mengurangi waktu pelatihan dan men-deploy model ke produksi dengan mudah menggunakan framework open source dan infrastruktur AI yang dioptimalkan.
MLOps untuk AI prediktif dan generatif
Vertex AI Platform menyediakan alat MLOps yang dibuat khusus bagi data scientist dan engineer ML untuk mengotomatiskan, menstandarkan, dan mengelola project ML.
Alat modular membantu Anda berkolaborasi dengan berbagai tim dan meningkatkan kualitas model di sepanjang siklus proses pengembangan—mengidentifikasi model terbaik untuk kasus penggunaan dengan Vertex AI Evaluation, mengorkestrasi alur kerja dengan Vertex AI Pipelines, mengelola model apa pun dengan Model Registry, menyalurkan, berbagi, dan menggunakan kembali fitur ML dengan Feature Store, serta memantau model untuk skew dan penyimpangan input.
Agent Builder
Vertex AI Agent Builder memungkinkan developer untuk membangun dan men-deploy pengalaman AI generatif yang siap digunakan perusahaan dengan mudah. Layanan ini memberikan kemudahan konsol builder agen tanpa kode bersama dengan kemampuan grounding, orkestrasi, dan penyesuaian yang canggih. Dengan Vertex AI Agent Builder, developer dapat dengan cepat membuat berbagai agen dan aplikasi AI generatif yang didasarkan pada data organisasi mereka.
Cara Kerjanya
Vertex AI menyediakan beberapa opsi untuk pelatihan dan deployment model:
- AI Generatif memberi Anda akses ke model AI generatif besar, termasuk Gemini 2.5, sehingga Anda dapat mengevaluasi, menyesuaikan, dan men-deploy model tersebut agar dapat digunakan dalam aplikasi yang didukung AI.
- Dengan Model Garden, Anda dapat menemukan, menguji, menyesuaikan, dan men-deploy Vertex AI serta memilih model dan aset open-source (OSS).
- Pelatihan kustom memberi Anda kontrol penuh atas proses pelatihan, termasuk menggunakan framework ML pilihan, menulis kode pelatihan Anda sendiri, dan memilih opsi penyesuaian hyperparameter.
Vertex AI menyediakan beberapa opsi untuk pelatihan dan deployment model:
- AI Generatif memberi Anda akses ke model AI generatif besar, termasuk Gemini 2.5, sehingga Anda dapat mengevaluasi, menyesuaikan, dan men-deploy model tersebut agar dapat digunakan dalam aplikasi yang didukung AI.
- Dengan Model Garden, Anda dapat menemukan, menguji, menyesuaikan, dan men-deploy Vertex AI serta memilih model dan aset open-source (OSS).
- Pelatihan kustom memberi Anda kontrol penuh atas proses pelatihan, termasuk menggunakan framework ML pilihan, menulis kode pelatihan Anda sendiri, dan memilih opsi penyesuaian hyperparameter.
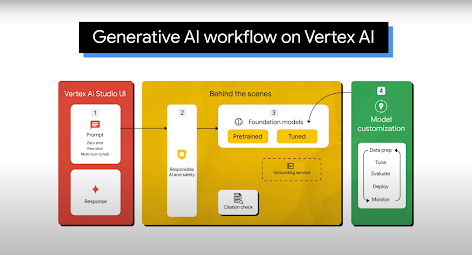
Penggunaan Umum
Membangun dengan Gemini
Mengakses model Gemini melalui Gemini API di Google Cloud Vertex AI
- Python
- JavaScript
- Java
- Go
- Curl
Contoh kode
Mengakses model Gemini melalui Gemini API di Google Cloud Vertex AI
- Python
- JavaScript
- Java
- Go
- Curl
AI generatif dalam aplikasi
Baca pengantar AI generatif di Vertex AI
Vertex AI Studio menawarkan alat konsol Google Cloud untuk membuat prototipe dan menguji model AI generatif dengan cepat. Pelajari cara menggunakan Generative AI Studio untuk menguji model menggunakan contoh prompt, mendesain dan menyimpan prompt, menyesuaikan model dasar, serta melakukan konversi antara ucapan dan teks.
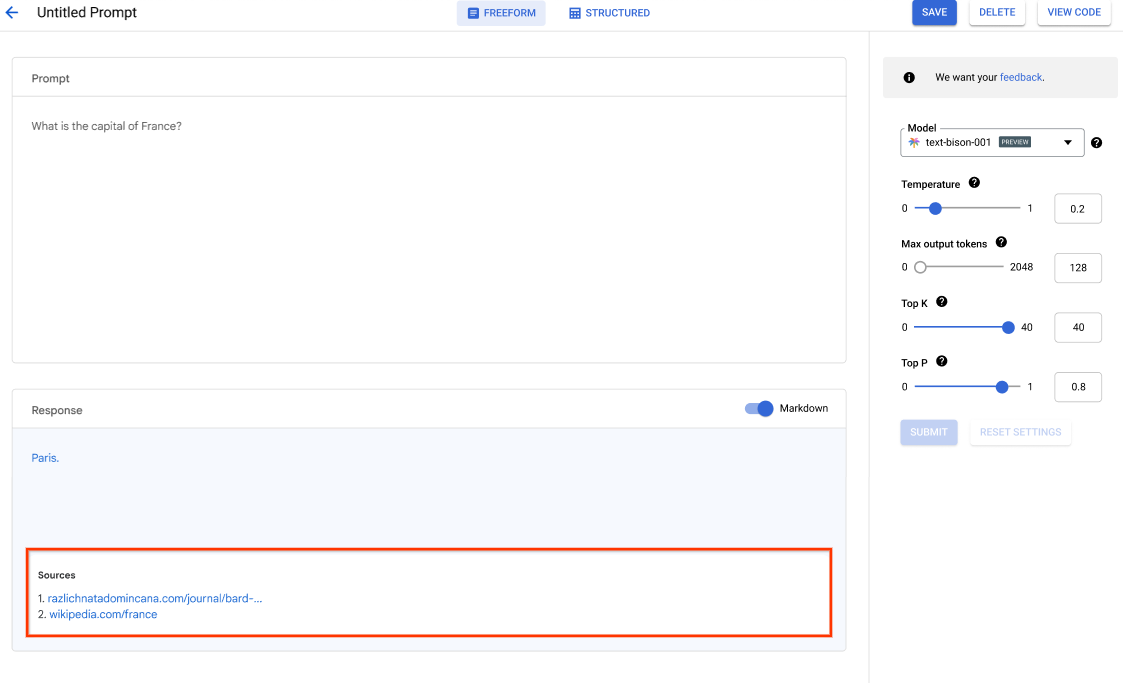
Lihat cara menyesuaikan LLM di Vertex AI Studio.
Tutorial, panduan memulai, dan lab
Baca pengantar AI generatif di Vertex AI
Vertex AI Studio menawarkan alat konsol Google Cloud untuk membuat prototipe dan menguji model AI generatif dengan cepat. Pelajari cara menggunakan Generative AI Studio untuk menguji model menggunakan contoh prompt, mendesain dan menyimpan prompt, menyesuaikan model dasar, serta melakukan konversi antara ucapan dan teks.
Lihat cara menyesuaikan LLM di Vertex AI Studio.
Mengekstrak, meringkas, dan mengklasifikasikan data
Menggunakan AI generatif untuk ringkasan, klasifikasi, dan ekstraksi
Pelajari cara membuat perintah teks untuk menangani sejumlah tugas dengan dukungan AI generatif Vertex AI. Beberapa tugas yang paling umum adalah mengklasifikasi, meringkas, dan mengekstrak. Gemini di Vertex AI memungkinkan Anda mendesain perintah yang fleksibel dalam hal struktur dan formatnya.
Tutorial, panduan memulai, dan lab
Menggunakan AI generatif untuk ringkasan, klasifikasi, dan ekstraksi
Pelajari cara membuat perintah teks untuk menangani sejumlah tugas dengan dukungan AI generatif Vertex AI. Beberapa tugas yang paling umum adalah mengklasifikasi, meringkas, dan mengekstrak. Gemini di Vertex AI memungkinkan Anda mendesain perintah yang fleksibel dalam hal struktur dan formatnya.
Melatih model ML kustom
Ringkasan dan dokumentasi pelatihan ML kustom
Dapatkan panduan video tentang langkah-langkah yang diperlukan untuk melatih model kustom di Vertex AI.
Tutorial, panduan memulai, dan lab
Ringkasan dan dokumentasi pelatihan ML kustom
Dapatkan panduan video tentang langkah-langkah yang diperlukan untuk melatih model kustom di Vertex AI.
Men-deploy model untuk penggunaan produksi
Men-deploy untuk prediksi batch atau online
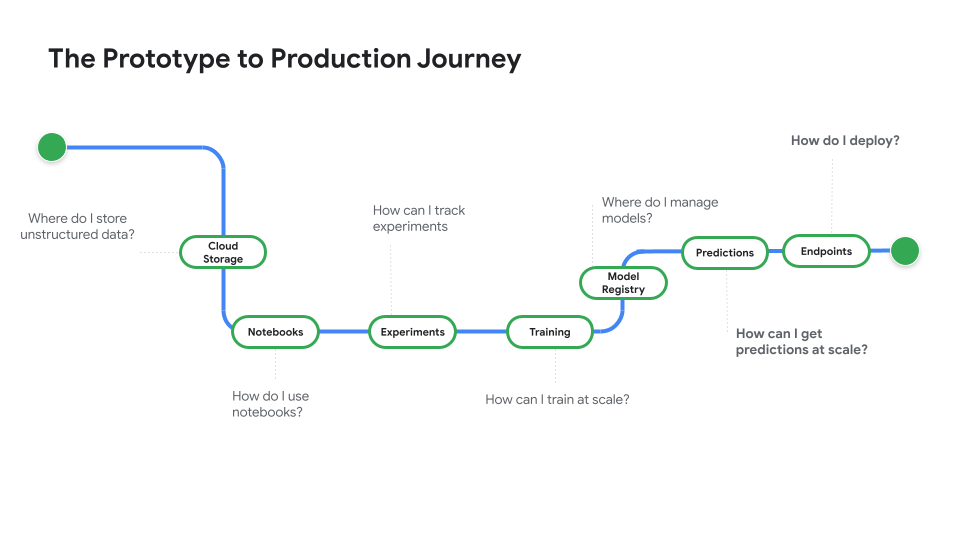
Tonton Dari Prototipe ke tahap Production, serial video yang membawa Anda dari kode notebook ke model yang di-deploy.
Tutorial, panduan memulai, dan lab
Men-deploy untuk prediksi batch atau online
Tonton Dari Prototipe ke tahap Production, serial video yang membawa Anda dari kode notebook ke model yang di-deploy.
Harga
| Cara kerja penetapan harga Vertex AI | Bayar untuk alat, penyimpanan, komputasi, dan resource Cloud Vertex AI yang digunakan. Pelanggan baru mendapatkan kredit gratis senilai $300 untuk mencoba produk Vertex AI & Google Cloud. | |
|---|---|---|
| Alat dan penggunaan | Deskripsi | Harga |
Generative AI | Model image untuk pembuatan image Berdasarkan input image, input karakter, atau harga pelatihan kustom. | Mulai dari $0,0001 |
Pembuatan teks, chat, dan kode Berdasarkan setiap 1.000 karakter input (prompt) dan setiap 1.000 karakter output (respons). | Mulai dari $0,0001 per 1.000 karakter | |
Model AutoML | Pelatihan, deployment, dan prediksi data image Berdasarkan waktu untuk melatih per jam kerja node, yang mencerminkan penggunaan resource, dan apakah untuk klasifikasi atau deteksi objek. | Mulai dari $1,375 per jam kerja node |
Pelatihan dan prediksi data video Berdasarkan harga per jam kerja node dan klasifikasi jika, pelacakan objek, atau pengenalan tindakan. | Mulai dari $0,462 per jam kerja node | |
Pelatihan dan prediksi data tabular Berdasarkan harga per jam kerja node dan regresi/klasifikasi jika atau perkiraan. Hubungi bagian penjualan untuk mengetahui detail harga dan kemungkinan diskon. | Hubungi bagian penjualan | |
Upload, pelatihan, deployment, prediksi data teks Berdasarkan tarif per jam untuk pelatihan dan prediksi, halaman untuk upload data lama (khusus PDF), serta data teks dan halaman untuk prediksi. | Mulai dari $0,05 per jam | |
Model yang dilatih khusus | Pelatihan model kustom Berdasarkan jenis mesin yang digunakan per jam, region, dan akselerator yang digunakan. Dapatkan perkiraan melalui penjualan atau kalkulator harga kami. | Hubungi bagian penjualan |
Notebook Vertex AI | Resource komputasi dan penyimpanan Berdasarkan tarif yang sama dengan Compute Engine dan Cloud Storage. | Lihat produk |
Biaya pengelolaan Selain penggunaan resource di atas, biaya pengelolaan berlaku berdasarkan region, instance, notebook, dan notebook terkelola yang digunakan. Lihat detail. | Lihat detail | |
Vertex AI Pipelines | Biaya eksekusi dan biaya tambahan Berdasarkan biaya eksekusi, resource yang digunakan, dan biaya layanan tambahan. | Mulai dari $0,03 per operasi pipeline |
Vector Search Vertex AI | Biaya penyajian dan pembuatan Berdasarkan ukuran data Anda, jumlah kueri per detik (QPS) yang ingin dijalankan, dan jumlah node yang Anda gunakan. Lihat contoh. | Lihat contoh |
Lihat detail harga untuk semua fitur dan layanan Vertex AI.
Cara kerja penetapan harga Vertex AI
Bayar untuk alat, penyimpanan, komputasi, dan resource Cloud Vertex AI yang digunakan. Pelanggan baru mendapatkan kredit gratis senilai $300 untuk mencoba produk Vertex AI & Google Cloud.
Model image untuk pembuatan image
Berdasarkan input image, input karakter, atau harga pelatihan kustom.
Starting at
$0,0001
Pembuatan teks, chat, dan kode
Berdasarkan setiap 1.000 karakter input (prompt) dan setiap 1.000 karakter output (respons).
Starting at
$0,0001
per 1.000 karakter
Pelatihan, deployment, dan prediksi data image
Berdasarkan waktu untuk melatih per jam kerja node, yang mencerminkan penggunaan resource, dan apakah untuk klasifikasi atau deteksi objek.
Starting at
$1,375
per jam kerja node
Pelatihan dan prediksi data video
Berdasarkan harga per jam kerja node dan klasifikasi jika, pelacakan objek, atau pengenalan tindakan.
Starting at
$0,462
per jam kerja node
Pelatihan dan prediksi data tabular
Berdasarkan harga per jam kerja node dan regresi/klasifikasi jika atau perkiraan. Hubungi bagian penjualan untuk mengetahui detail harga dan kemungkinan diskon.
Hubungi bagian penjualan
Upload, pelatihan, deployment, prediksi data teks
Berdasarkan tarif per jam untuk pelatihan dan prediksi, halaman untuk upload data lama (khusus PDF), serta data teks dan halaman untuk prediksi.
Starting at
$0,05
per jam
Pelatihan model kustom
Berdasarkan jenis mesin yang digunakan per jam, region, dan akselerator yang digunakan. Dapatkan perkiraan melalui penjualan atau kalkulator harga kami.
Hubungi bagian penjualan
Resource komputasi dan penyimpanan
Berdasarkan tarif yang sama dengan Compute Engine dan Cloud Storage.
Lihat produk
Biaya pengelolaan
Selain penggunaan resource di atas, biaya pengelolaan berlaku berdasarkan region, instance, notebook, dan notebook terkelola yang digunakan. Lihat detail.
Lihat detail
Biaya eksekusi dan biaya tambahan
Berdasarkan biaya eksekusi, resource yang digunakan, dan biaya layanan tambahan.
Starting at
$0,03
per operasi pipeline
Vector Search Vertex AI
Biaya penyajian dan pembuatan
Berdasarkan ukuran data Anda, jumlah kueri per detik (QPS) yang ingin dijalankan, dan jumlah node yang Anda gunakan. Lihat contoh.
Lihat contoh
Lihat detail harga untuk semua fitur dan layanan Vertex AI.
Memulai bukti konsep Anda
Kasus Bisnis
Memaksimalkan potensi AI generatif

"Akurasi solusi AI generatif Google Cloud dan kepraktisan Vertex AI Platform memberi kami keyakinan yang dibutuhkan untuk menerapkan teknologi canggih ini ke dalam inti bisnis kami dan mencapai sasaran jangka panjang, yaitu waktu respons yang cepat."
Abdol Moabery, CEO GA Telesis
Laporan analis
TKTKT
Google dinobatkan sebagai Pemimpin dalam The Forrester Wave™: AI Infrastructure Solutions, Q1 2024, menerima skor tertinggi dari semua vendor yang dievaluasi dalam Current Offering dan Strategy.
Google dinobatkan sebagai Pemimpin dalam laporan Forrester Wave™: AI Foundation Models For Language, Q2 2024. Baca laporannya.
Google dinobatkan sebagai pemimpin dalam Forrester Wave: AI/ML Platforms, Q3 2024. Pelajari lebih lanjut.











