Vertex AI Platform
Innova più rapidamente con l'IA di livello enterprise, ottimizzata dai modelli Gemini
Vertex AI è una piattaforma di sviluppo AI unificata e completamente gestita per creare e utilizzare l'AI generativa. Accedi e utilizza Vertex AI Studio, Agent Builder e oltre 200 foundation model.
I nuovi clienti ricevono fino a 300 $ di crediti gratuiti per provare Vertex AI e altri prodotti Google Cloud.
Funzionalità
Gemini, i modelli multimodali più avanzati di Google
Vertex AI offre l'accesso agli ultimi modelli Gemini di Google. Gemini è in grado di comprendere praticamente qualsiasi input, combinare diversi tipi di informazioni e generare qualsiasi output. Esegui prompt e test di Gemini in Vertex AI Studio utilizzando testo, immagini, video o codice. Utilizzando il ragionamento avanzato e le funzionalità di generazione all'avanguardia di Gemini, gli sviluppatori possono provare prompt di esempio per estrarre il testo dalle immagini, convertire il testo delle immagini in formato JSON e persino generare risposte sulle immagini caricate per creare applicazioni IA di nuova generazione.

Più di 200 modelli e strumenti di AI generativa
Scegli tra la vastissima gamma di modelli proprietari (Gemini, Imagen, Chirp, Veo), di terze parti (la famiglia di modelli Claude di Anthropic) e open (Gemma, Llama 3.2) in Model Garden. Utilizza le estensioni per consentire ai modelli di recuperare informazioni in tempo reale e attivare azioni. Personalizza i modelli in base al tuo caso d'uso con una serie di opzioni di ottimizzazione per i modelli di testo, immagine o codice di Google.
I modelli di IA generativa e gli strumenti completamente gestiti semplificano la prototipazione, la personalizzazione, l'integrazione e il deployment nelle applicazioni.
AI Platform open e integrata
I data scientist possono muoversi più velocemente con gli strumenti di Vertex AI Platform per l'addestramento, la regolazione e il deployment di modelli ML.
I notebook Vertex AI, che includono la tua scelta tra Colab Enterprise o Workbench, sono integrati in modo nativo con BigQuery e forniscono un'unica piattaforma per tutti i dati e gli workload AI.
Vertex AI Training e Previsione consentono di ridurre i tempi di addestramento e di eseguire facilmente il deployment dei modelli in produzione grazie alla scelta di framework open source e di infrastruttura AI ottimizzata.
MLOps per l'AI predittiva e generativa
Vertex AI Platform fornisce strumenti MLOps appositamente creati per data scientist e tecnici ML per automatizzare, standardizzare e gestire i progetti ML.
Gli strumenti modulari ti aiutano a collaborare tra i team e a migliorare i modelli durante l'intero ciclo di vita dello sviluppo: identifica il modello migliore per un caso d'uso con Vertex AI Evaluation, orchestra i flussi di lavoro con Vertex AI Pipelines , gestisci qualsiasi modello con Model Registry, gestisci, condividi e riutilizza le funzionalità ML con Feature Store e monitora i modelli per rilevare disallineamenti e deviazioni degli input.
Agent Builder
Vertex AI Agent Builder consente agli sviluppatori di creare ed eseguire facilmente il deployment di esperienze di AI generativa di livello enterprise. Offre la comodità di una console per la creazione di agenti no-code, oltre a potenti funzionalità di grounding, orchestrazione e personalizzazione. Con Vertex AI Agent Builder, gli sviluppatori possono creare rapidamente una gamma di agenti e applicazioni di AI generativa basata sui dati della loro organizzazione.
Come funziona
Vertex AI fornisce varie opzioni per addestrare un modello ed eseguire il deployment:
- L'AI generativa ti dà accesso a modelli di AI generativa di grandi dimensioni, tra cui Gemini 2.5, in modo da poterli valutare, ottimizzare ed eseguire il deployment per favorirne l'uso nelle tue applicazioni basate sull'AI.
- Model Garden ti consente di scoprire, testare, personalizzare ed eseguire il deployment di Vertex AI e selezionare modelli e asset open source (OSS).
- L'addestramento personalizzato ti fornisce il controllo completo sul processo di addestramento, compresi l'utilizzo del framework ML preferito, la scrittura del codice di addestramento e la scelta delle opzioni di ottimizzazione degli iperparametri.
Vertex AI fornisce varie opzioni per addestrare un modello ed eseguire il deployment:
- L'AI generativa ti dà accesso a modelli di AI generativa di grandi dimensioni, tra cui Gemini 2.5, in modo da poterli valutare, ottimizzare ed eseguire il deployment per favorirne l'uso nelle tue applicazioni basate sull'AI.
- Model Garden ti consente di scoprire, testare, personalizzare ed eseguire il deployment di Vertex AI e selezionare modelli e asset open source (OSS).
- L'addestramento personalizzato ti fornisce il controllo completo sul processo di addestramento, compresi l'utilizzo del framework ML preferito, la scrittura del codice di addestramento e la scelta delle opzioni di ottimizzazione degli iperparametri.
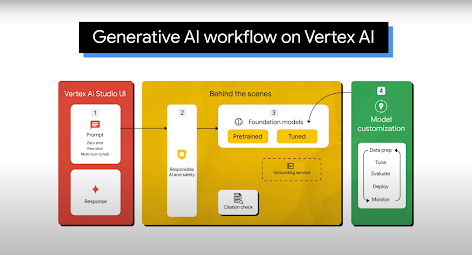
Utilizzi comuni
Crea con Gemini
Accedi ai modelli Gemini tramite l'API Gemini in Vertex AI di Google Cloud
- Python
- JavaScript
- Java
- Go
- Curl
Esempio di codice
Accedi ai modelli Gemini tramite l'API Gemini in Vertex AI di Google Cloud
- Python
- JavaScript
- Java
- Go
- Curl
IA generativa nelle applicazioni
Introduzione all'AI generativa su Vertex AI
Vertex AI Studio offre uno strumento della console Google Cloud per la prototipazione e i test rapidi di modelli di IA generativa. Scopri come utilizzare Generative AI Studio per testare modelli utilizzando esempi di prompt, progettare e salvare prompt, regolare un modello di base e convertire tra voce e testo.
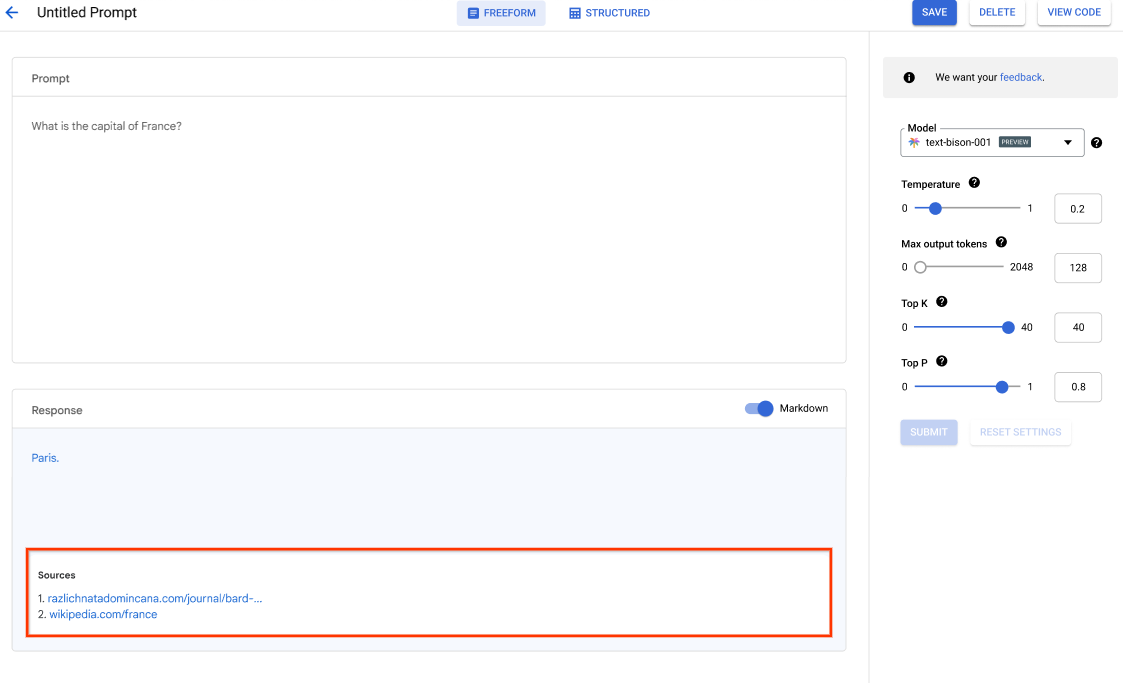
Vedi come regolare i modelli LLM in Generative AI Studio
Tutorial, guide rapide e lab
Introduzione all'AI generativa su Vertex AI
Vertex AI Studio offre uno strumento della console Google Cloud per la prototipazione e i test rapidi di modelli di IA generativa. Scopri come utilizzare Generative AI Studio per testare modelli utilizzando esempi di prompt, progettare e salvare prompt, regolare un modello di base e convertire tra voce e testo.
Vedi come regolare i modelli LLM in Generative AI Studio
Estrai, riepiloga e classifica i dati
Usa l'IA generativa per il riepilogo, la classificazione e l'estrazione
Scopri come creare prompt di testo per gestire un numero qualsiasi di attività con il supporto dell'IA generativa di Vertex AI. Alcune delle attività più comuni sono la classificazione, il riepilogo e l'estrazione. Gemini su Vertex AI ti consente di progettare prompt con flessibilità in termini di struttura e formato.
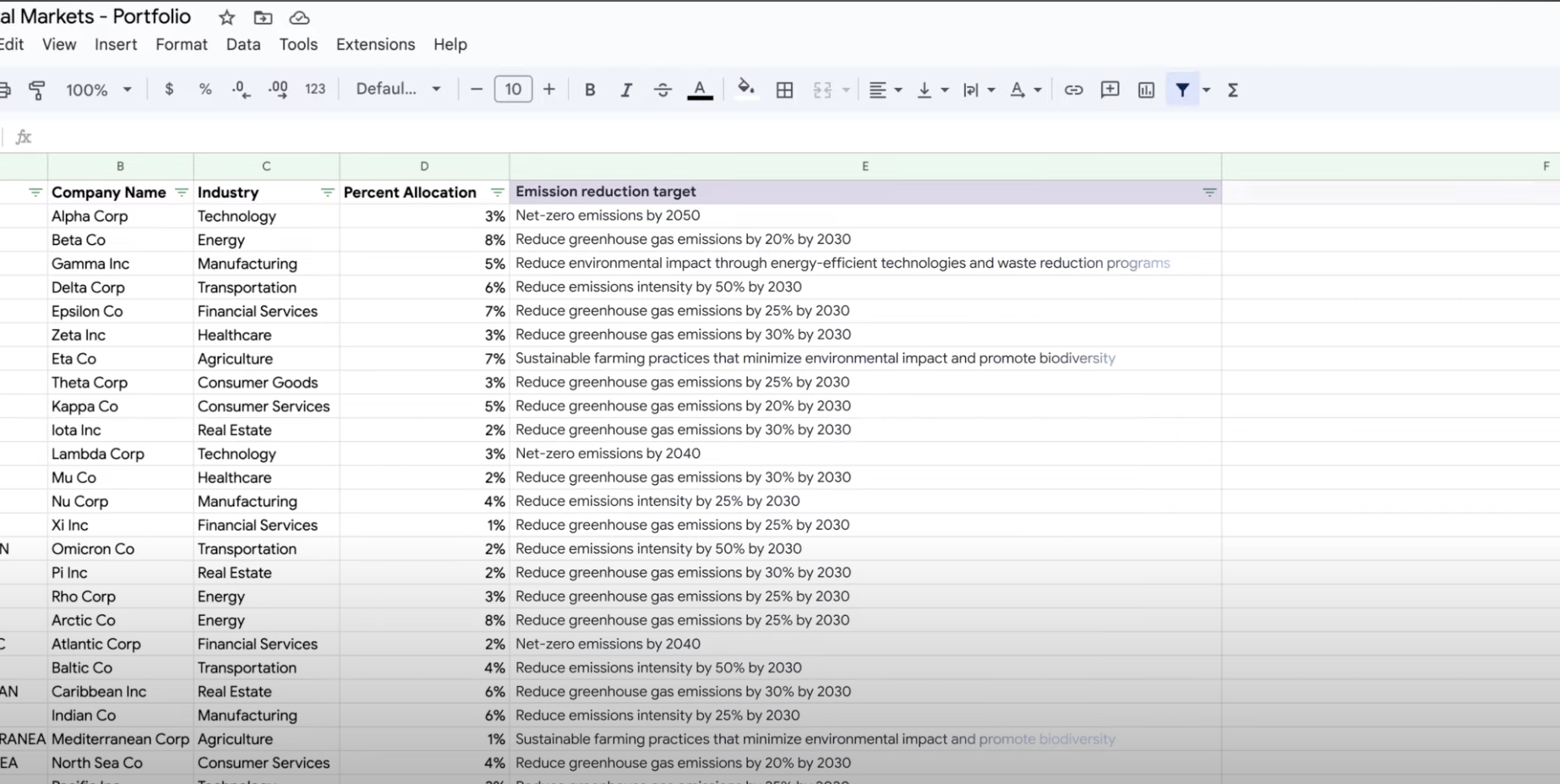
Tutorial, guide rapide e lab
Usa l'IA generativa per il riepilogo, la classificazione e l'estrazione
Scopri come creare prompt di testo per gestire un numero qualsiasi di attività con il supporto dell'IA generativa di Vertex AI. Alcune delle attività più comuni sono la classificazione, il riepilogo e l'estrazione. Gemini su Vertex AI ti consente di progettare prompt con flessibilità in termini di struttura e formato.
Addestra modelli ML personalizzati
Panoramica e documentazione sull'addestramento ML personalizzato
Guarda una procedura dettagliata video dei passaggi necessari per addestrare modelli personalizzati su Vertex AI.
Tutorial, guide rapide e lab
Panoramica e documentazione sull'addestramento ML personalizzato
Guarda una procedura dettagliata video dei passaggi necessari per addestrare modelli personalizzati su Vertex AI.
Esegui il deployment di un modello per l'uso in produzione
Deployment per previsioni batch o online
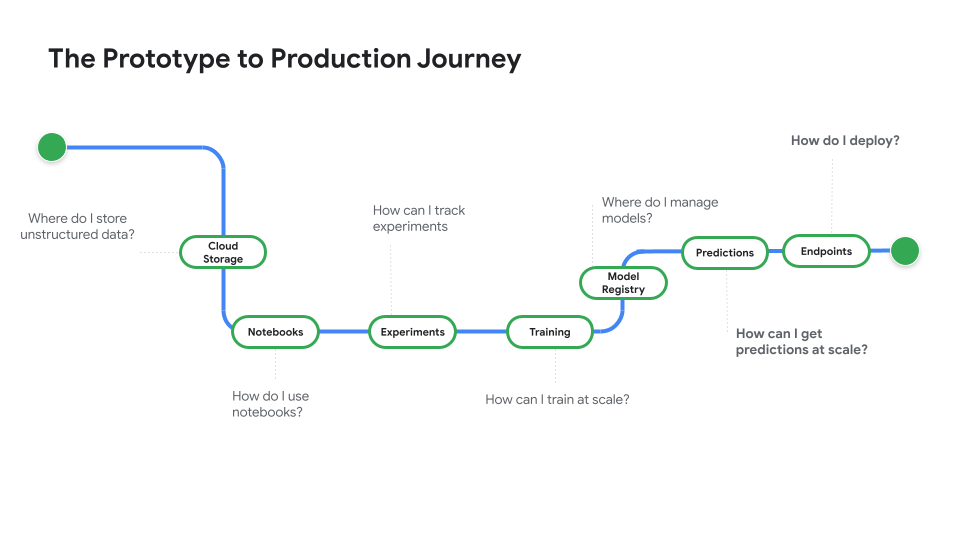
Guarda Prototype to Production (Dal prototipo alla produzione), una serie di video che ti guida dal codice del blocco note a un modello di cui è stato eseguito il deployment.
Tutorial, guide rapide e lab
Deployment per previsioni batch o online
Guarda Prototype to Production (Dal prototipo alla produzione), una serie di video che ti guida dal codice del blocco note a un modello di cui è stato eseguito il deployment.
Prezzi
| Come funzionano i prezzi di Vertex AI | Paga solo per gli strumenti Vertex AI, lo spazio di archiviazione, il computing e le risorse Google Cloud utilizzate. I nuovi clienti ricevono 300 $ di crediti gratuiti per provare Vertex AI e altri prodotti Google Cloud. | |
|---|---|---|
| Strumenti e utilizzo | Descrizione | Prezzo |
AI generativa | Modello Imagen per la generazione di immagini In base ai prezzi inseriti per immagini, caratteri o addestramento personalizzato. | A partire da $0,0001 |
Generazione di testi, chat e codice In base a ogni 1000 caratteri di input (prompt) e ogni 1000 caratteri di output (risposta). | A partire da $0,0001 per 1.000 caratteri | |
Modelli AutoML | Addestramento, deployment e previsione dei dati di immagine In base al tempo di addestramento per ora nodo, che riflette l'utilizzo delle risorse e se avviene per la classificazione o il rilevamento di oggetti. | A partire da 1,375 $ per ora nodo |
Previsione e addestramento dei dati video In base al prezzo per ora nodo e se per classificazione, monitoraggio oggetti o riconoscimento delle azioni. | A partire da 0,462 $ per ora nodo | |
Addestramento e previsione di dati tabulari In base al prezzo per ora nodo e se per classificazione/regressione o previsione. Contatta il team di vendita per informazioni su potenziali sconti e prezzi. | Contatta il team di vendita | |
Caricamento, addestramento, deployment, previsione dei dati di testo In base alle tariffe orarie per l'addestramento e la previsione, alle pagine per il caricamento di dati legacy (solo PDF) e a record di testo e pagine per la previsione. | A partire da 0,05 $ all'ora | |
Modelli addestrati personalizzati | Addestramento di modelli personalizzati In base al tipo di macchina utilizzata per ora, alla regione e a eventuali acceleratori utilizzati. Ottieni una stima tramite i team di vendite o il Calcolatore prezzi. | Contatta il team di vendita |
Vertex AI Notebooks | Risorse di calcolo e archiviazione In base alle stesse tariffe di Compute Engine e Cloud Storage. | Fai riferimento ai prodotti |
Commissioni di gestione Oltre all'utilizzo delle risorse sopra indicate, vengono applicate commissioni di gestione in base alla regione, alle istanze, ai blocchi note e ai blocchi note gestiti utilizzati. Mostra dettagli. | Consulta i dettagli | |
Pipeline Vertex AI | Esecuzione e costi aggiuntivi In base al costo di esecuzione, alle risorse utilizzate e a eventuali commissioni di servizio aggiuntive. | A partire da 0,03 $ per esecuzione della pipeline |
Vertex AI Vector Search | Costi di pubblicazione e creazione In base alle dimensioni dei dati, alla quantità di query al secondo (QPS) che vuoi eseguire e al numero di nodi utilizzati. Vedi esempio | Fai riferimento all'esempio |
Visualizza i dettagli dei prezzi per tutte le funzionalità e i servizi di Vertex AI.
Come funzionano i prezzi di Vertex AI
Paga solo per gli strumenti Vertex AI, lo spazio di archiviazione, il computing e le risorse Google Cloud utilizzate. I nuovi clienti ricevono 300 $ di crediti gratuiti per provare Vertex AI e altri prodotti Google Cloud.
Modello Imagen per la generazione di immagini
In base ai prezzi inseriti per immagini, caratteri o addestramento personalizzato.
Starting at
$0,0001
Generazione di testi, chat e codice
In base a ogni 1000 caratteri di input (prompt) e ogni 1000 caratteri di output (risposta).
Starting at
$0,0001
per 1.000 caratteri
Addestramento, deployment e previsione dei dati di immagine
In base al tempo di addestramento per ora nodo, che riflette l'utilizzo delle risorse e se avviene per la classificazione o il rilevamento di oggetti.
Starting at
1,375 $
per ora nodo
Previsione e addestramento dei dati video
In base al prezzo per ora nodo e se per classificazione, monitoraggio oggetti o riconoscimento delle azioni.
Starting at
0,462 $
per ora nodo
Addestramento e previsione di dati tabulari
In base al prezzo per ora nodo e se per classificazione/regressione o previsione. Contatta il team di vendita per informazioni su potenziali sconti e prezzi.
Contatta il team di vendita
Caricamento, addestramento, deployment, previsione dei dati di testo
In base alle tariffe orarie per l'addestramento e la previsione, alle pagine per il caricamento di dati legacy (solo PDF) e a record di testo e pagine per la previsione.
Starting at
0,05 $
all'ora
Addestramento di modelli personalizzati
In base al tipo di macchina utilizzata per ora, alla regione e a eventuali acceleratori utilizzati. Ottieni una stima tramite i team di vendite o il Calcolatore prezzi.
Contatta il team di vendita
Risorse di calcolo e archiviazione
In base alle stesse tariffe di Compute Engine e Cloud Storage.
Fai riferimento ai prodotti
Commissioni di gestione
Oltre all'utilizzo delle risorse sopra indicate, vengono applicate commissioni di gestione in base alla regione, alle istanze, ai blocchi note e ai blocchi note gestiti utilizzati. Mostra dettagli.
Consulta i dettagli
Esecuzione e costi aggiuntivi
In base al costo di esecuzione, alle risorse utilizzate e a eventuali commissioni di servizio aggiuntive.
Starting at
0,03 $
per esecuzione della pipeline
Vertex AI Vector Search
Costi di pubblicazione e creazione
In base alle dimensioni dei dati, alla quantità di query al secondo (QPS) che vuoi eseguire e al numero di nodi utilizzati. Vedi esempio
Fai riferimento all'esempio
Visualizza i dettagli dei prezzi per tutte le funzionalità e i servizi di Vertex AI.
Inizia la tua proof of concept
Business case
Sblocca tutto il potenziale dell'AI generativa

"L'accuratezza della soluzione di AI generativa di Google Cloud e la praticità di Vertex AI Platform ci danno la fiducia di cui avevamo bisogno per implementare questa tecnologia all'avanguardia nel cuore della nostra attività e raggiungere il nostro obiettivo a lungo termine di un tempo di risposta di zero minuti."
Abdol Moabery, CEO di GA Telesis
Report degli analisti
TKTKT
Google ha ricevuto il titolo di Leader nel report The Forrester Wave™: AI Infrastructure Solutions, Q1 2024 e ha ottenuto i punteggi più alti tra tutti i fornitori valutati sia nella categoria relativa alle offerte attuali che in quella dedicata alla strategia.
Google ha ricevuto il titolo di Leader nel report The Forrester Wave™: AI Foundation Models For Language, Q2 2024 Leggi il rapporto.
Google ha ricevuto il titolo di Leader nel report The Forrester Wave™: AI/ML Platforms, Q3 2024. Scopri di più.











